利用Python爬虫刷店铺微博等访问量最简单有效教程
一、安装必要插件
测试环境:Windows 10 + Python 3.7.0
(1)安装Selenium
pip install selenium
pip install requests
每个版本支持的 Chrome版本是不一样的,必须要对应的版本才能驱动浏览器。
官方网站被墙,可以下载全版本的:http://npm.taobao.org/mirrors/chromedriver
比如我的Chrome浏览器和Webdriver版本对应都用V75的:
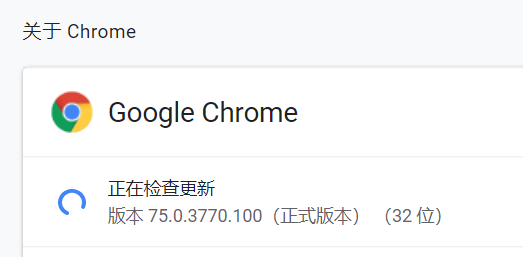

(4)Chrome WebDriver安装
1. Windows 安装方法:
下载压缩包解压,chromedriver.exe 和python.exe 都放到python根目录下即可。
2. Linux 安装方法:
把解压的文件放到 /usr/bin 目录下,并且修改好权限。
二、代码模板
目标:使用代码控制浏览器访问指定的链接,并且每次访问使用不同的代理。
代理:使用的是大象代理的api接口提取代理IP。
这段代码稳定性还不错,超时等错误就会重启脚本继续获取新的代理IP,保证脚本能够长时间运行。
import random
import requests
import time
from selenium import webdriver
import sys
import os # 随机获取浏览器标识
def get_UA():
UA_list = [
"Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19",
"Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30",
"Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0",
"Mozilla/5.0 (Android; Mobile; rv:14.0) Gecko/14.0 Firefox/14.0",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36"
]
randnum = random.randint(0, len(UA_list)-1)
h_list = UA_list[randnum]
return h_list # 获取代理IP
def get_ip():
# 这里填写大象代理api地址,num参数必须为1,每次只请求一个IP地址
url = 'http://www.baidu.com'
response = requests.get(url)
response.close()
ip = response.text
print(ip)
return ip if __name__ == '__main__':
url = "https://www.hao123.com/"
# 无限循环,每次都要打开一个浏览器窗口,不是标签
while 1:
# 调用函数获取浏览器标识, 字符串
headers = get_UA()
# 调用函数获取IP代理地址,这里获取是字符串,而不是像前两个教程获得的是数组
proxy = get_ip()
# 使用chrome自定义
chrome_options = webdriver.ChromeOptions()
# 设置代理
chrome_options.add_argument('--proxy-server=http://'+proxy)
# 设置UA
chrome_options.add_argument('--user-agent="'+headers+'"')
# 使用设置初始化webdriver
driver = webdriver.Chrome(chrome_options=chrome_options) try:
# 访问超时30秒
driver.set_page_load_timeout(30)
# 访问网页
driver.get(url)
# 退出当前浏览器
driver.close()
# 延迟1~3秒继续
time_delay = random.randint(1, 3)
while time_delay > 0:
print(str(time_delay) + " seconds left!!")
time.sleep(1)
time_delay = time_delay - 1
pass
except:
print("timeout")
# 退出浏览器
driver.quit()
time.sleep(1)
# 重启脚本, 之所以选择重启脚本是因为,长时间运行该脚本会出现一些莫名其妙的问题,不如重启解决
python = sys.executable
os.execl(python, python, *sys.argv)
finally:
pass
利用Python爬虫刷店铺微博等访问量最简单有效教程的更多相关文章
- 利用Python爬虫刷新某网站访问量
前言:前一段时间看到有博友写了爬虫去刷新博客访问量一篇文章,当时还觉得蛮有意思的,就保存了一下,但是当我昨天准备复现的时候居然发现文章404了.所以本篇文章仅供学习交流,严禁用于商业用途 很多人学习p ...
- 如何科学地蹭热点:用python爬虫获取热门微博评论并进行情感分析
前言:本文主要涉及知识点包括新浪微博爬虫.python对数据库的简单读写.简单的列表数据去重.简单的自然语言处理(snowNLP模块.机器学习).适合有一定编程基础,并对python有所了解的盆友阅读 ...
- 如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7 思路: 1.先选取你要爬取的电影 2.用vip解析工具解析,获取地址 3.写好脚本,下载片断 4.将片断利用电脑合成 需要的python模块: ##第一 ...
- 如何利用 Python 爬虫实现给微信群发新闻早报?(详细)
1. 场景 经常有小伙伴在交流群问我,每天的早报新闻是怎么获取的? 其实,早期使用的方案,是利用爬虫获取到一些新闻网站的标题,然后做了一些简单的数据清洗,最后利用 itchat 发送到指定的社群中. ...
- 利用python爬虫关键词批量下载高清大图
前言 在上一篇写文章没高质量配图?python爬虫绕过限制一键搜索下载图虫创意图片!中,我们在未登录的情况下实现了图虫创意无水印高清小图的批量下载.虽然小图能够在一些移动端可能展示的还行,但是放到pc ...
- 利用python爬虫爬取图片并且制作马赛克拼图
想在妹子生日送妹子一张用零食(或者食物类好看的图片)拼成的马赛克拼图,因此探索了一番= =. 首先需要一个软件来制作马赛克拼图,这里使用Foto-Mosaik-Edda(网上也有在线制作的网站,但是我 ...
- python爬虫起步...开发环境搭建,最简单的方式
研究一门编程语言,一般第一步就是配置安装部署相关的编程环境.我认为啊,在学习的初期,大家不是十分了解相关的环境,或者是jar包,python模块等的相关内容,就不需要花费大量的时间去研究如何去安装它. ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 利用Python爬虫爬取指定天猫店铺全店商品信息
本编博客是关于爬取天猫店铺中指定店铺的所有商品基础信息的爬虫,爬虫运行只需要输入相应店铺的域名名称即可,信息将以csv表格的形式保存,可以单店爬取也可以增加一个循环进行同时爬取. 源码展示 首先还是完 ...
随机推荐
- 史上最全的Java命名规范[转]
每个公司都有不同的标准,目的是为了保持统一,减少沟通成本,提升团队研发效能.所以本文中是笔者结合阿里巴巴开发规范,以及工作中的见闻针对Java领域相关命名进行整理和总结,仅供参考. 一.Java中的命 ...
- laravel中使用FormRequest进行表单验证,验证异常返回JSON
通常在项目中,我们会对大量的前端提交过来的表单进行验证,如果不通过,则返回错误信息. 前端为了更好的体验,都使用ajax进行表单提交,虽然 validate() 方法能够根据前端的不同请求方式,返回不 ...
- 对RESTful Api的简单记录
1.五个动词 ①GET:读取(Read)--->查询操作 ②POST:新建(Create)--->添加操作 ③PUT:更新(Update)--->修改操作 ④PATCH:更新(Upd ...
- 13. 罗马数字转整数(C#)
看到这道题,存在键值对,所以先建个泛型字典,把键值填进去. 由于这道题存在两个字符表示一个数字的情况,所以在for循环的时候判断一下,看看当前字符串中循环到的字符是否和下一个字符能够组成存在在字典里的 ...
- 深入理解JVM,虚拟机类加载机制
类加载过程概览 类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括以下7个阶段: 加载(Loading) 验证(Verification) 准备(Preparation) 解析(Re ...
- MySQL学习——操作自定义函数
MySQL学习——操作自定义函数 摘要:本文主要学习了使用DDL语句操作自定义函数的方法. 了解自定义函数 是什么 自定义函数是一种与存储过程十分相似的过程式数据库对象.它与存储过程一样,都是由SQL ...
- MySQL学习——操作数据库
MySQL学习——操作数据库 摘要:本文主要学习了使用DDL语句操作数据库的方法. 创建数据库 语法 create database [if not exists] 数据库名 [default] ch ...
- Javase之object类的概述
object类的概述 object类是类层次结构的根类,每个类都使用object作为超类. 即每个类都直接或间接的继承object类. object类中方法介绍 hashCode public int ...
- opencv::DNN介绍
DNN模块介绍: Tiny-dnn模块 支持深度学习框架 - Caffe - TensorFlow - Torch/PyTorch DNN运用 图像分类 对象检测 实时对象检测 图像分割 预测 视频对 ...
- 《Python自动化测试九章经》
Python是当前非常流行的一门编程语言,它除了在人工智能.数据处理.Web开发.网络爬虫等领域得到广泛使用之外,他也非常适合软件测试人员使用,但是,对于刚入行的测试小白来说,并不知道学习Python ...