elasticsearch http 搜索 测试
1.查询所有的documents
http://192.168.43.45:9200/_search

boost parameter 细粒度搜索条件权重控制
如:组装多个查询条件,其中一个匹配的想要优先查询显示出来,需要使用权重控制提升相似度排名
2.查看 elasticsearch的 健康状态
http://192.168.43.45:9200/_cat/health?v
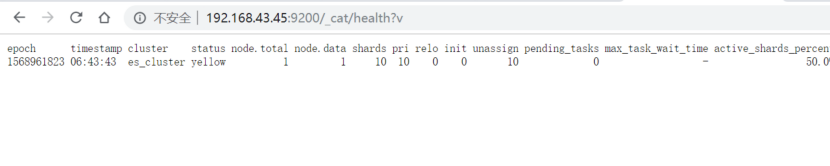
红:数据不可访问
绿:集群完全起作用
黄:一些数据不可访问
3. 查看集群中节点情况:
http://192.168.43.45:9200/_cat/nodes?v

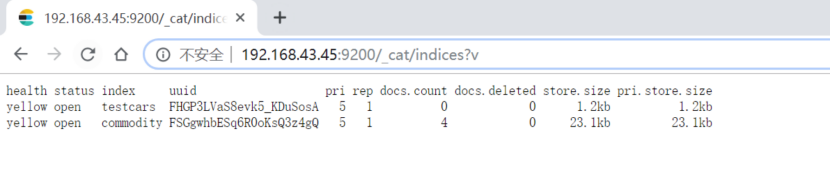
4.查看集群下所有索引
http://192.168.43.45:9200/_cat/indices?v
5.创建一个索引
从put请求可以看出es是rest 的api ,默认put就是增加
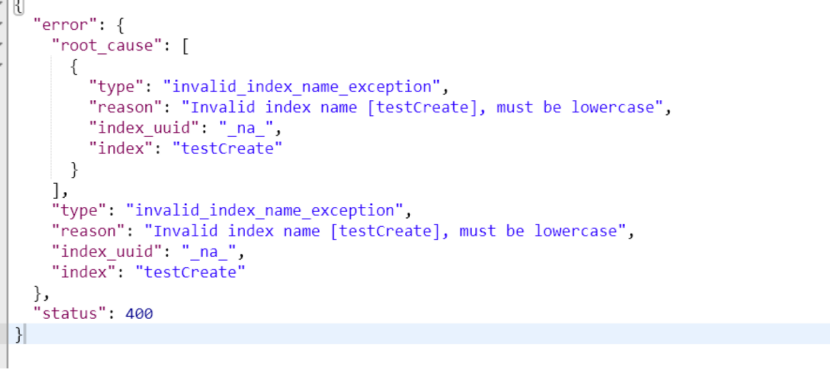
put http://192.168.43.45:9200/testcreate?pretty
索引的名称必须全部是小写
否则报错
修改索引为小写,必须使用put请求
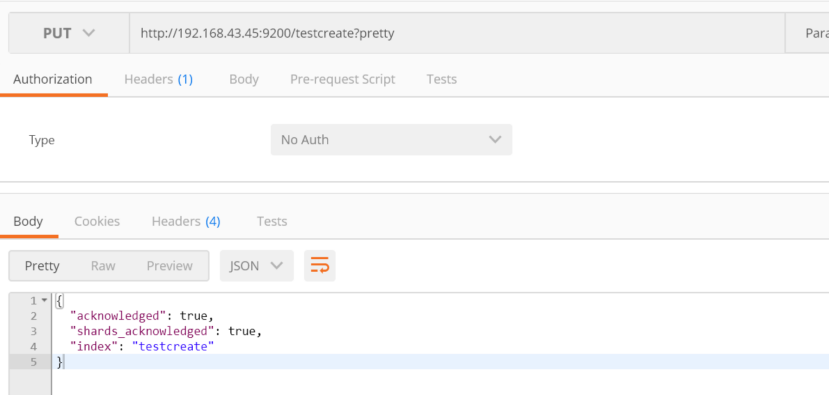
然后查看所有索引:
http://192.168.43.45:9200/_cat/indices?v

从图中可以看出有5个主分区和1个副本(5 primary shards and 1 replica)
目前看到的节点的颜色是黄色,是因为单节点的es和es默认的shard 10个分区不匹配,现在只有5个分区,只有当节点增加了es节点,才会在另一个节点进行副本复制,那么颜色才会变成绿色
6.向索引中添加文档
put http://192.168.43.45:9200/testcreate/doc/1?pretty
{
"name": "John Doe"
}
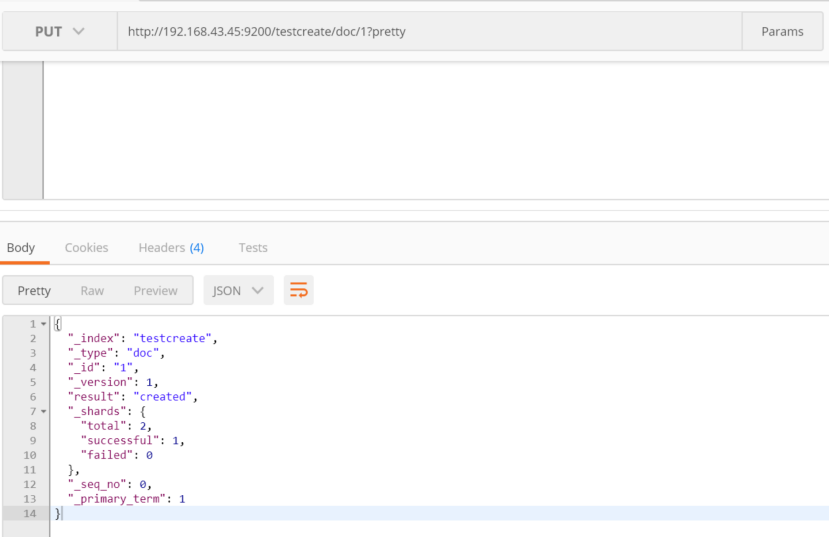
查询一下刚才放入的数据:
http://192.168.43.45:9200/testcreate/doc/1?pretty

7.删除索引
delete http://192.168.43.45:9200/testcreate?pretty

再次查看所有索引:
http://192.168.43.45:9200/_cat/indices?v

8.更新文档
如果在删除了索引之后,又进行了向索引中添加doc,那么默认会把索引创建
如果继续在添加的基础上面,修改添加的数据内容,则会对当前文档进行修改

put http://192.168.43.45:9200/testcreate/doc/2?pretty
{
"name": "John CCC"
}
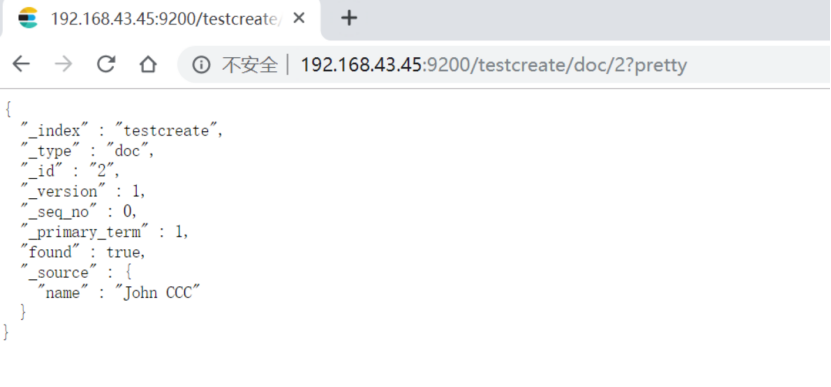
查询id=2的文档
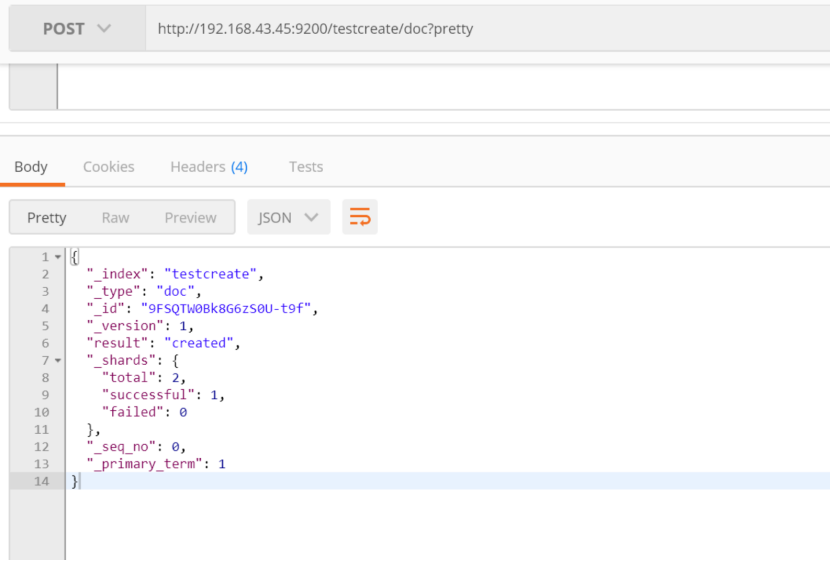
如果不指定id向分区中插入数据,es会随机生成id
post http://192.168.43.45:9200/testcreate/doc?pretty
{
"name": "John DDD"
}
查询该测试索引下的所有文档:
http://192.168.43.45:9200/testcreate/_search

es 更新文档,本质就是删除旧的文档,然后放入新的文档
下面是插入,更新看下下一个:因为少了id
post http://192.168.43.45:9200/testcreate/doc/_update?pretty
{
"doc": {"name" : "test update doc"}
}

更新:
post http://192.168.43.45:9200/testcreate/doc/1/_update?pretty
{
"doc": {"name" : "test update doc"}
}

查看索引下更新的文档:
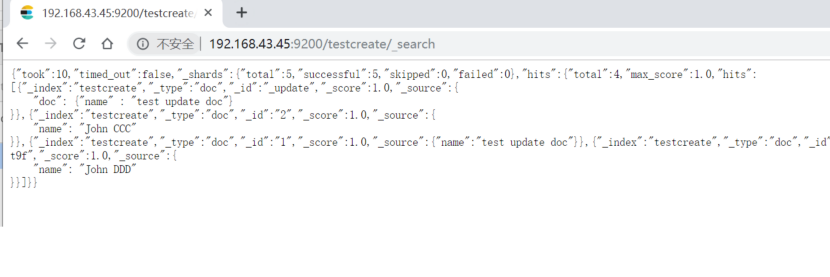
更新的时候多增加1个字段
post http://192.168.43.45:9200/testcreate/doc/1/_update?pretty
{
"doc": {"name" : "test update doc", "age": 20}
}
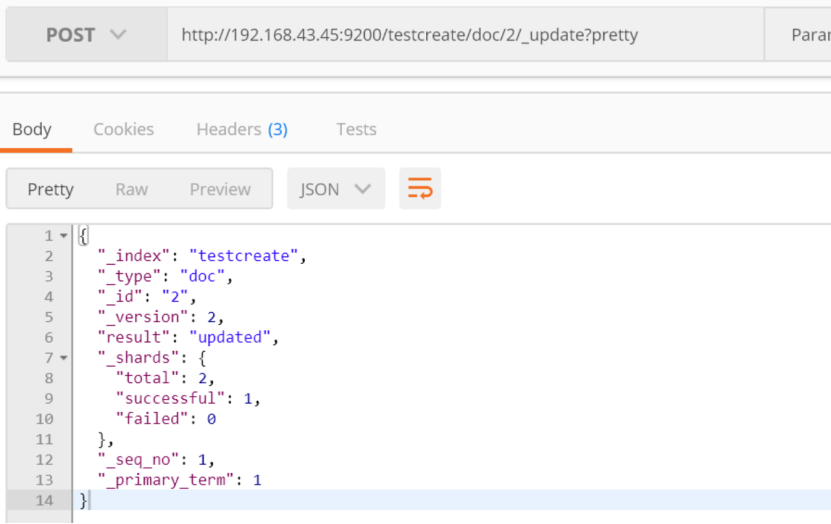
使用脚本对字段值进行更新
post http://192.168.43.45:9200/testcreate/doc/1/_update?pretty
{
"script": "ctx._source.age += 100"
}
即当前上下文context,当前上下文中doc的source字段的属性
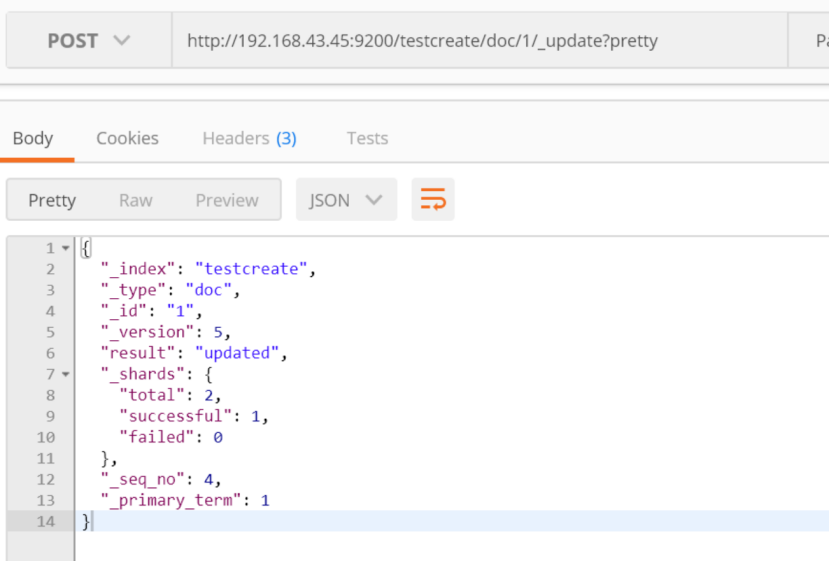
查看结果:
http://192.168.43.45:9200/testcreate/_search

9.批量处理
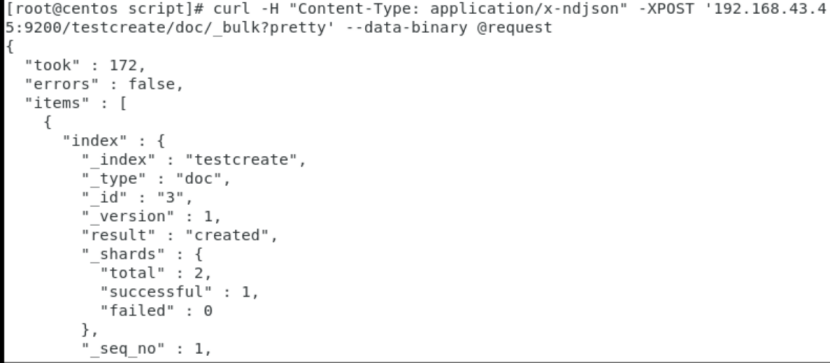
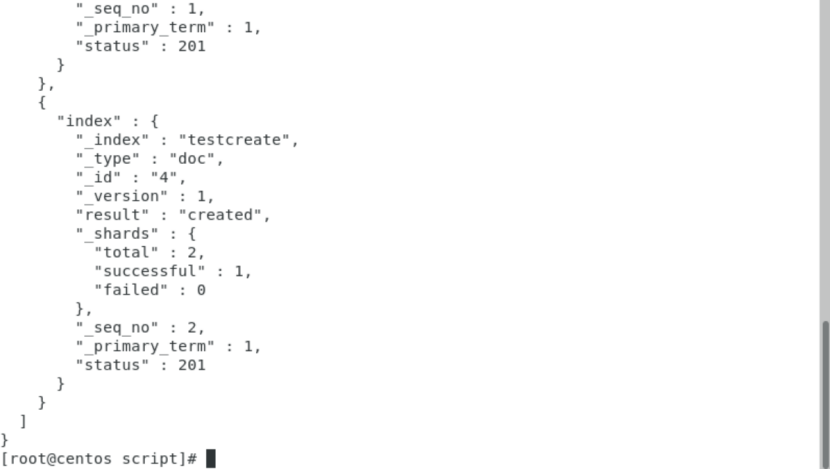
①、批量插入多个doc,目前只能在命令行中写脚本执行
curl -H "Content-Type: application/x-ndjson" -XPOST '192.168.43.45:9200/testcreate/doc/_bulk?pretty' --data-binary @request
request脚本:
{"index":{"_id":"3"}}
{"name":"test batch insert 3"}
{"index":{"_id":"4"}}
{"name":"test batch insert 4"}
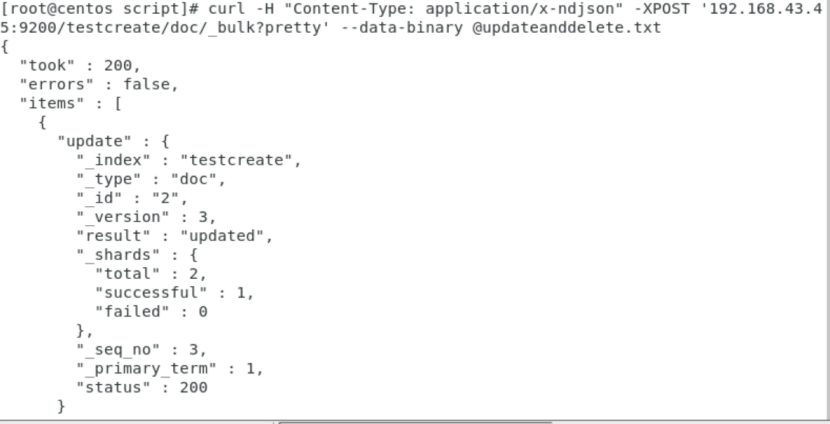
②、批量进行更新、删除、
curl -H "Content-Type: application/x-ndjson" -XPOST '192.168.43.45:9200/testcreate/doc/_bulk?pretty' --data-binary @updateanddelete.txt
多个操作,每一个操作不影响别的操作,当一个动作执行失败,其他操作仍然继续执行,批处理的返回结果,可以看到所有的处理结果

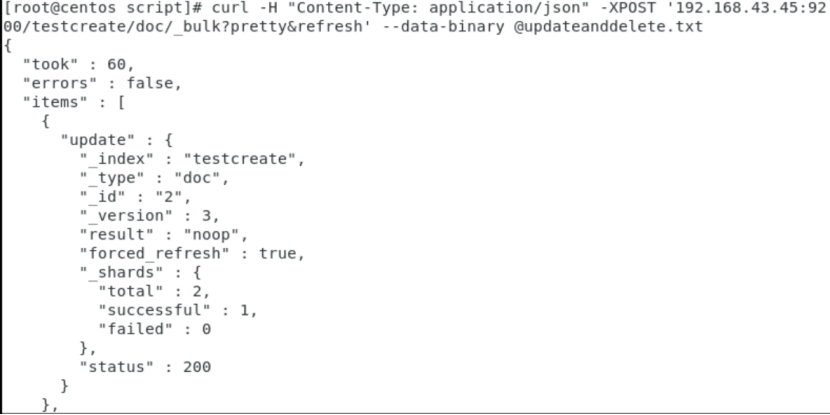
10.导入数据集
curl -H "Content-Type: application/json" -XPOST '192.168.43.45:9200/testcreate/doc/_bulk?pretty&refresh' --data-binary @updateanddelete.txt
curl "192.168.43.45:9200/_cat/indices?v"
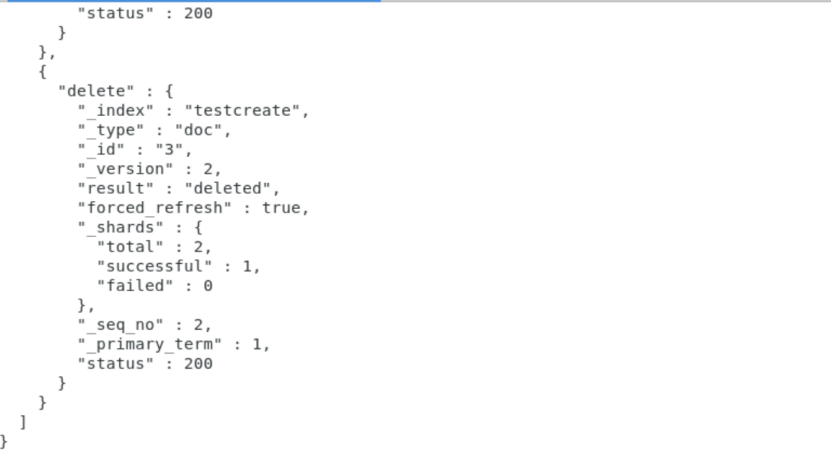
updateanddelete.txt:
{"update":{"_id":"2"}}
{"doc":{"name":"test update and test delete"}}
{"delete":{"_id":"3"}}
批处理数据,最优数目可以是1000 - 5000,大小为5M-15M
查看删除后剩余的doc:
http://192.168.43.45:9200/testcreate/_search

查看某一个具体的doc:
get http://192.168.43.45:9200/testcreate/doc/2
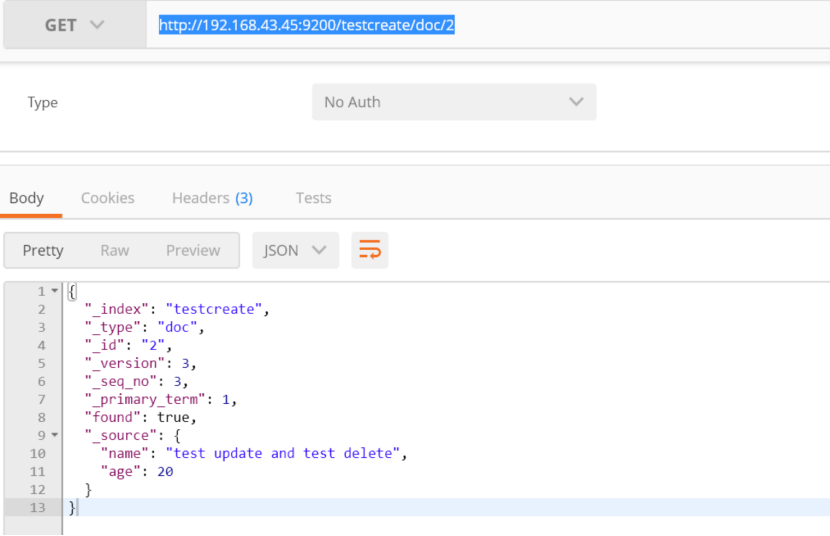
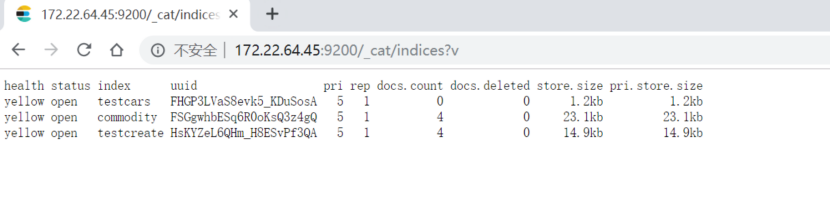
查看索引中文档个数:
http://172.22.64.45:9200/_cat/indices?v
11.查询 es 中所有的 文档, 并按照某一个条件排序
get http://172.22.64.45:9200/testcreate/_search?q=*&sort=_id:asc&pretty
查询索引库 testcreate 中所有数据,并按照_id 升序排序

参考:https://segmentfault.com/a/1190000017136282?utm_source=tag-newest
get http://172.22.64.45:9200/testcreate/_search?q=*&sort=_id:asc&pretty
解释:所有结果(q=*)按照_id升序排序
下面的查询与上面的含义一致:
GET /testcreate/_search { "query": { "match_all": {} }, "sort": [ { "_id": "asc" } ] }
按条件查询 es 中的 文档, 并按照某一个条件排序:
(如果es官方文档中url是get请求,但是postman又模拟不出来,可以使用post来,参考文章:es 的 http请求中携带参数问题 解释)
http://172.22.64.45:9200/testcreate/_search
{
"query": { "match": { "name": "test" } },
"sort": {"_id" : "desc"}
}
解释:查询索引testcreate中name 中包含 test ,且按照 _id排序
①、其中match是匹配test或者别的name , 如果match 写成 “match”:{"name":"test hello"},则表示匹配name是 test 或者 hello 的数据
②、其中match_phrase是精确匹配,即只匹配

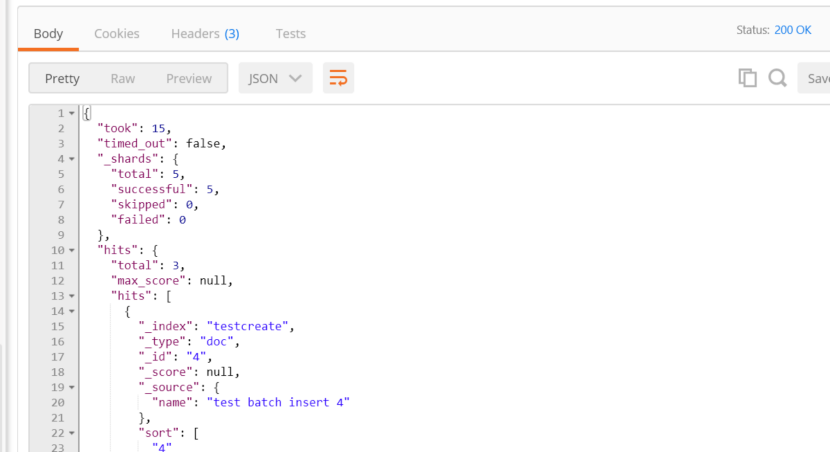
http://172.22.64.45:9200/testcreate/_search
{
"query": { "match_phrase": { "name": "test update" } },
"sort": {"_id" : "desc"}
}

组合查询:通过使用pool
解释:查询索引testcreate中文档,匹配name中带有test,且不匹配 id是9FSQTW0Bk8G6zS0U的文档
http://172.22.64.45:9200/testcreate/_search
{
"query": {
"bool":{
"must":[{
"match":{"name":"test"}
}],
"must_not":[{
"match":{"_id":"9FSQTW0Bk8G6zS0U"}
}]
}
}
}
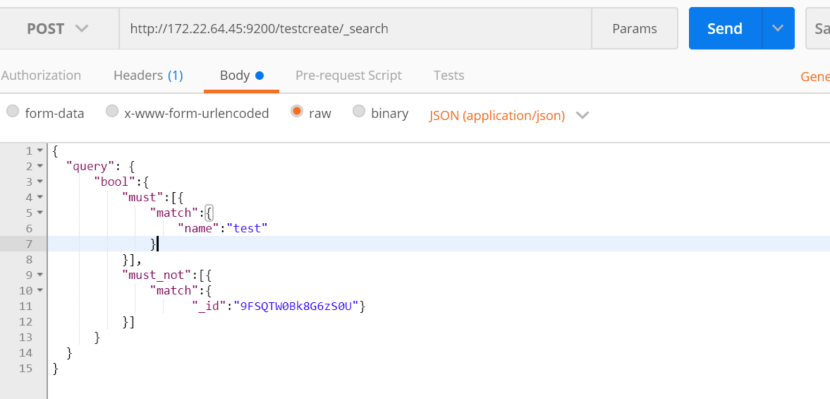

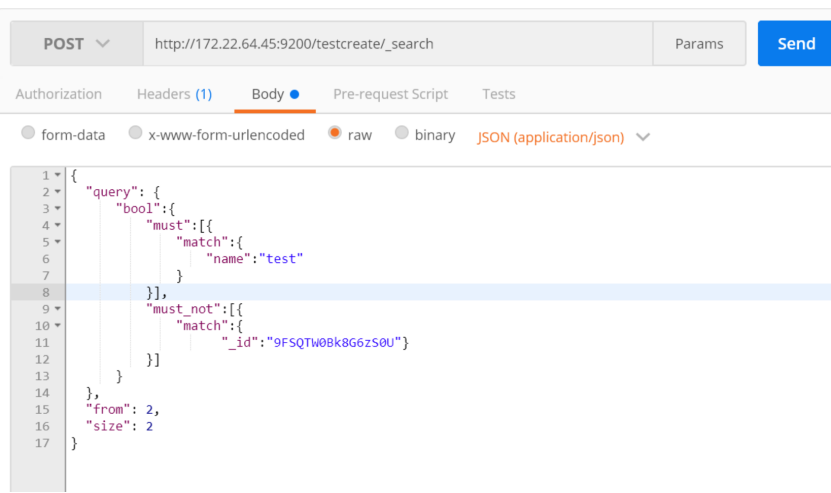
按照分页进行获取数据:
解释:查询索引testcreate中文档,匹配name中带有test,且不匹配 id是9FSQTW0Bk8G6zS0U的文档,按照2条数据分页,获取第二页的数据
http://172.22.64.45:9200/testcreate/_search
list数据默认是从0开始
比如匹配特殊的属性字段:
http://172.22.64.45:9200/testcreate/_search
解释:匹配属性列 name 是 test 的文档
{
"query":{
"match": { "name": "test" }
}
}


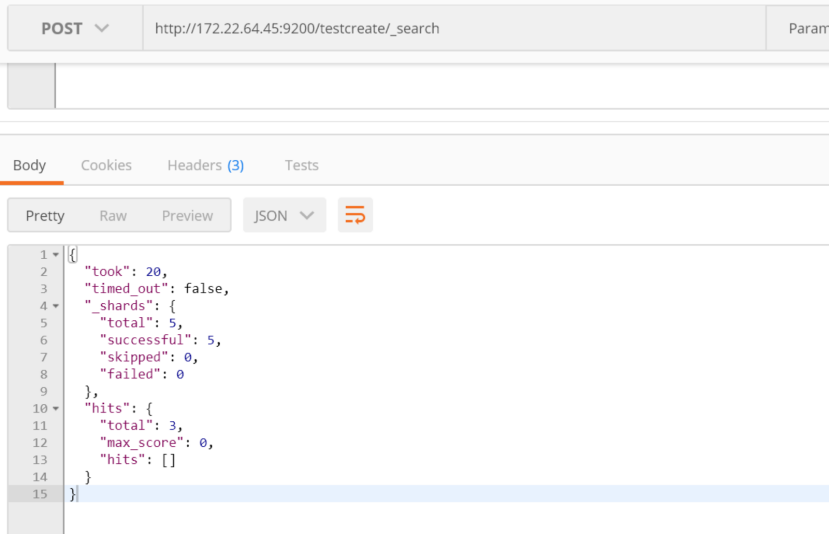
当指定返回的文档是空的,只需要得到总数,则使用size=0
http://172.22.64.45:9200/testcreate/_search
{
"query":{
"match": { "name": "test" }
},
"size":0
}
12.聚合查询
对某一个field属性列进行统计
http://172.22.64.45:9200/testcreate/_search
{
"size": 0,
"aggs": {
"group_by_name": {
"terms": {"field": "name.keyword"}
}
}
}
解释:对索引testcreate中的字段name进行分组操作,并统计name关键字的个数,使默认的全部数据不显示(size=0),只返回聚合的结果
{
"took": 1045,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_name": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{"key": "John DDD","doc_count": 1},
{"key": "test batch insert 4","doc_count": 1},
{"key": "test update and test delete","doc_count": 1},
{"key": "test update doc","doc_count": 1}]}
}
}

目前看到的统计的都是1条数据,没有相同的数据,现在添加文档
http://172.22.64.45:9200/testcreate/doc/5?pretty
{
"name": "test batch insert 4"
}

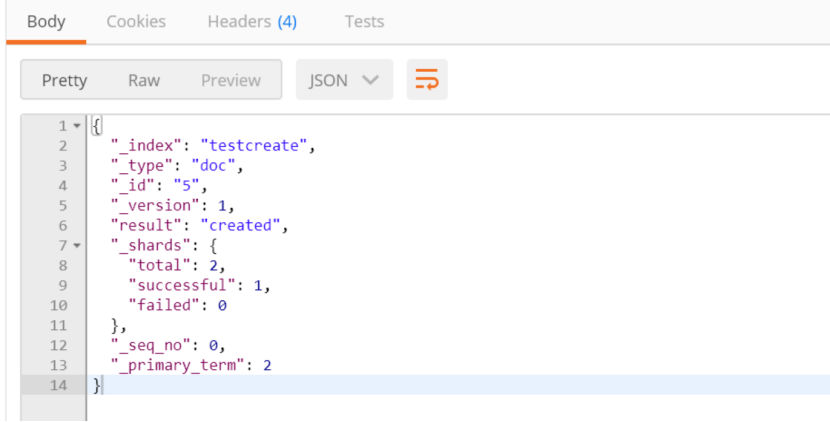
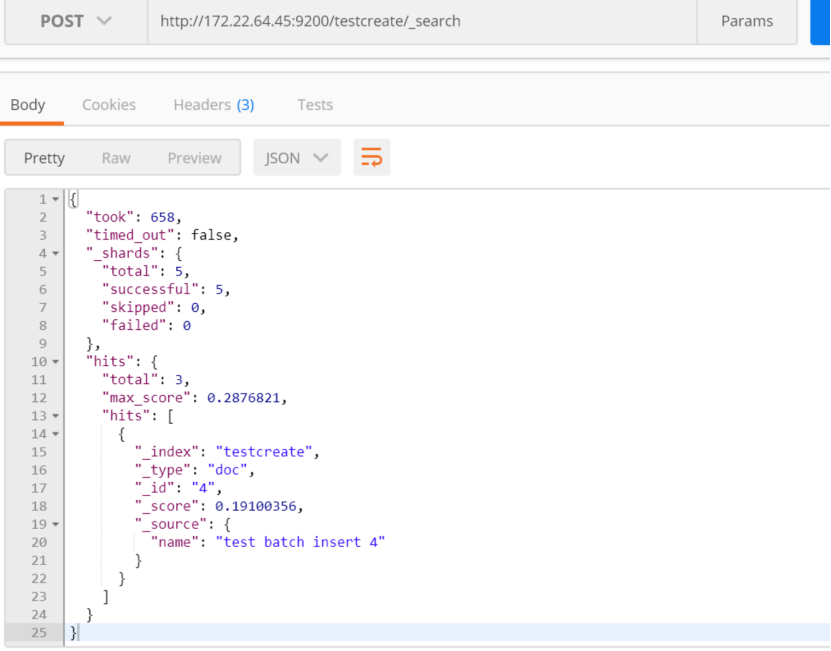
再进行查询:name为test batch insert 4 有两条数据
首先去掉id不是 数字的 文档
http://172.22.64.45:9200/testcreate/_search
{
"query" : {
"bool": {
"must_not": [{
"match":{"_id":"9FSQTW0Bk8G6zS0U"}
}]
}
},
"aggs": {
"group_by_name": {"terms": {"field": "name.keyword"}}
}
}

再插入age数据
http://172.22.64.45:9200/testcreate/doc/6?pretty
{
"name": "test update doc",
"age": 150
}
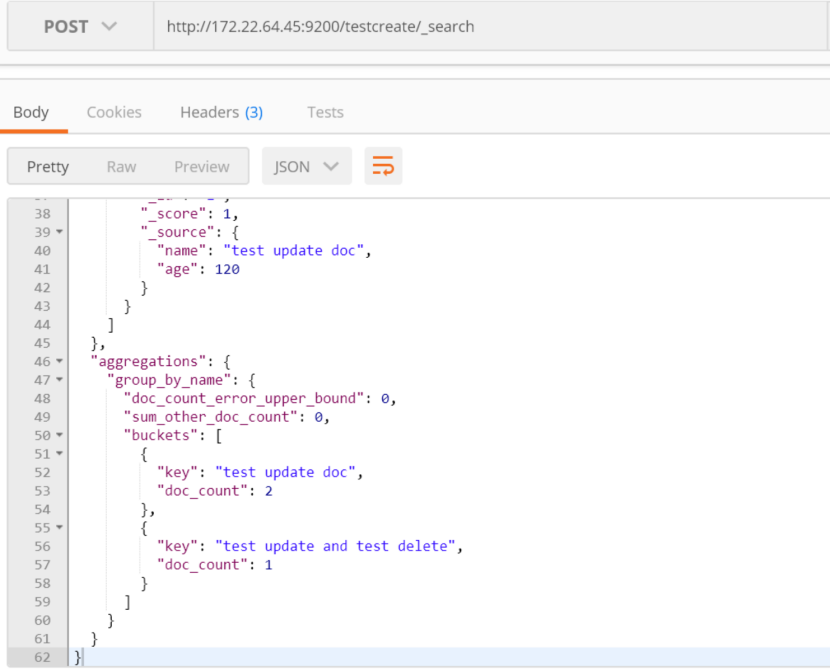
复合聚合,嵌套聚合:
http://172.22.64.45:9200/testcreate/_search
{
"query" : {
"bool": {
"must_not": [
{ "match":{"_id":"9FSQTW0Bk8G6zS0U"}},
{ "match":{"_id":"4"}},
{ "match":{"_id":"5"}},
{ "match":{"_id":"9FSQTW0Bk8G6zS0U-t9f"}}
]}
},
"aggs": {
"group_by_name": {
"terms": {"field": "name.keyword"},
"aggs": {
"average_age": {
"avg": {"field": "age"}
}
}
}
}
}
解释:过滤掉_id中的文档没有包含age属性的字段,如果不过滤掉,则会出现统计是null的数据
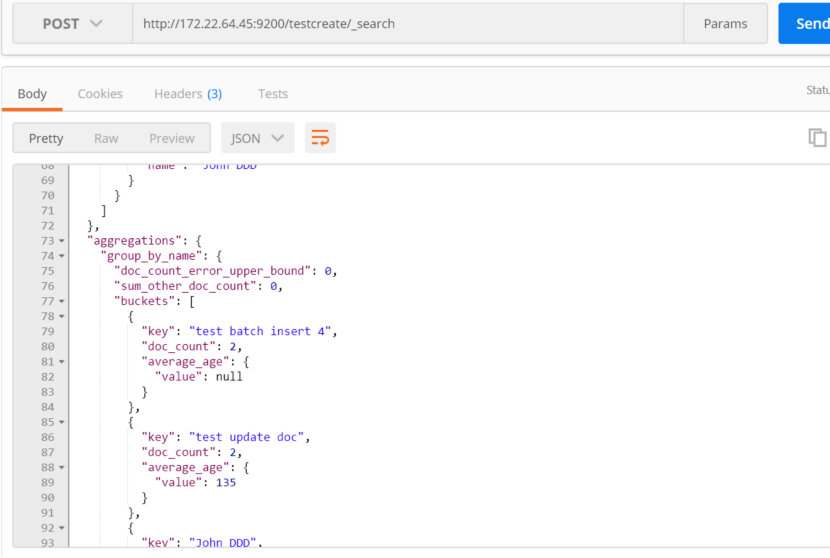
按照文档中属性的name进行分组,然后在分组的结果上面进行求平均值

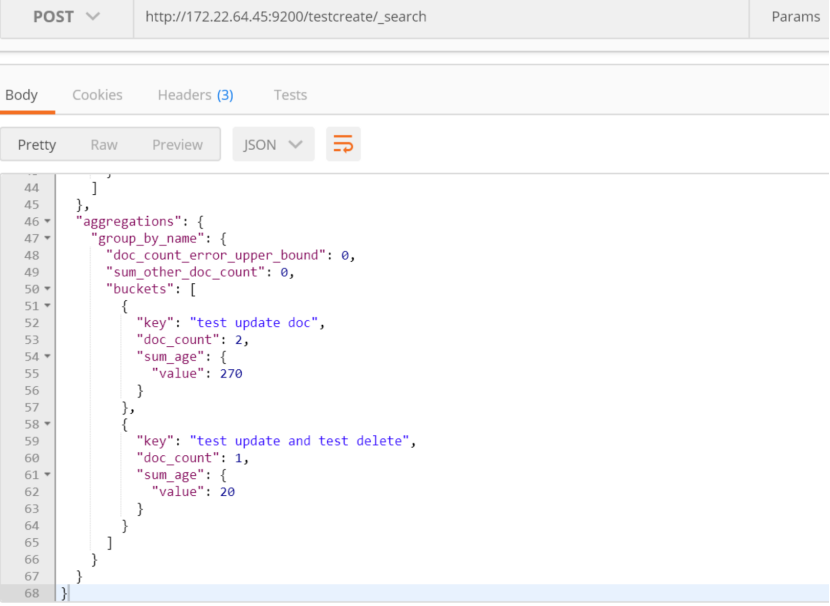
聚合进行求和:
{
"query" : {
"bool": {
"must_not": [
{ "match":{"_id":"9FSQTW0Bk8G6zS0U"}},
{ "match":{"_id":"4"}},
{ "match":{"_id":"5"}},
{ "match":{"_id":"9FSQTW0Bk8G6zS0U-t9f"}}
]
}
},
"aggs": {
"group_by_name": {
"terms": {"field": "name.keyword"},
"aggs": {
"sum_age": {"sum": {"field": "age"}}
}
}
}
}
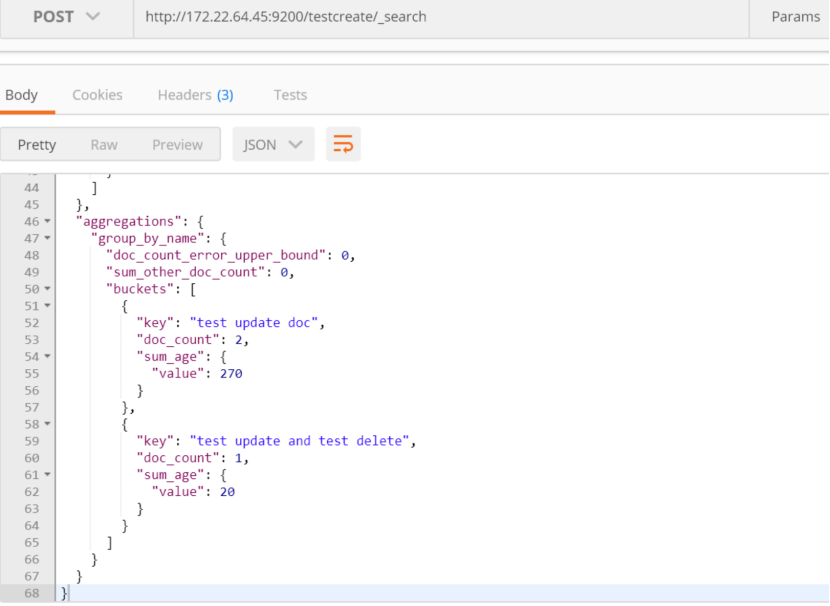
按照年龄大小排序:
{
"query" : {
"bool": {
"must_not": [
{ "match":{"_id":"9FSQTW0Bk8G6zS0U"}},
{ "match":{"_id":"4"}},
{ "match":{"_id":"5"}},
{ "match":{"_id":"9FSQTW0Bk8G6zS0U-t9f"}}]
}
},
"aggs": {
"group_by_name": {
"terms": {
"field": "name.keyword",
"order":{"sum_age": "asc"}
},
"aggs": {
"sum_age": {"sum": {"field": "age"}}
}
}
}
}

13. 安装时候自动创建索引
action.auto_create_index in elasticsearch.yml 配置为:
action.auto_create_index: .monitoring*,.watches,.triggered_watches,.watcher-history*,.ml*
杀死进程:pkill -F pid
es本身是用Java编译的
elasticsearch http 搜索 测试的更多相关文章
- Elasticsearch实现搜索推荐词
本篇介绍的是基于Elasticsearch实现搜索推荐词,其中需要用到Elasticsearch的pinyin插件以及ik分词插件,代码的实现这里提供了java跟C#的版本方便大家参考. 1.实现的结 ...
- Elasticsearch分布式搜索和数据分析引擎-ElasticStack(上)v7.14.0
Elasticsearch概述 **本人博客网站 **IT小神 www.itxiaoshen.com Elasticsearch官网地址 https://www.elastic.co/cn/elast ...
- web功能测试之表单、搜索测试
初入职场接触功能测试老是碰到以下情况不知道怎么写测试用例: 一个界面很多搜索条件怎么写用例?下拉框测试如何考虑测试点?上传要考虑哪些验证点?...... 所以这篇主要是整理关于web测试之表单.搜索测 ...
- loli的搜索测试-我真不知道是第多少次了
搜索测试 又到了....并不激动人心的搜索测试时间. 今天和以前还是有一点不一样的,新高二的学长们也参加了(也就是说我们又要被吊打了) 话不多说,看题: fz:填一个5*5的质数方阵,要求每行,每列, ...
- loli的搜索测试-4
其实这已经是第四次搜索测试了...只不过上两次测试时我不在学校,扔两个链接吧: 测试-2:https://www.luogu.org/blog/user35178/loli-di-sou-suo-ce ...
- ElasticSearch位置搜索
ElasticSearch位置搜索 学习了:https://blog.csdn.net/bingduanlbd/article/details/52253542 学习了:https://blog.cs ...
- ElasticSearch入门-搜索(java api)
ElasticSearch入门-搜索(java api) package com.qlyd.searchhelper; import java.util.Map; import net.sf.json ...
- PHP使用ElasticSearch做搜索
PHP 使用 ElasticSearch 做搜索 https://blog.csdn.net/zhanghao143lina/article/details/80280321 https://www. ...
- 十九种Elasticsearch字符串搜索方式终极介绍
前言 刚开始接触Elasticsearch的时候被Elasticsearch的搜索功能搞得晕头转向,每次想在Kibana里面查询某个字段的时候,查出来的结果经常不是自己想要的,然而又不知道问题出在了哪 ...
随机推荐
- 小米 OJ 编程比赛 02 月常规赛 3 Logic Gatekeeper CDQ分治
link:https://code.mi.com/problem/list/view?id=139 题意: 有一个1e6 * 1e6 大的格子,现在有两种操作:1,给一个子矩阵中的每个格子加上k.2, ...
- codeforces 816 E. Karen and Supermarket(树形dp)
题目链接:http://codeforces.com/contest/816/problem/E 题意:有n件商品,每件有价格ci,优惠券di,对于i>=2,使用di的条件为:xi的优惠券需要被 ...
- css 元素实际宽高
首先定义一个div. 然后稍微装修一下 下面开始区分 一.clientWidth和clientHeigh . clientTop和clientLeft 1,clientWidth的实际宽度 clien ...
- Go语言获取系统性能数据gopsutil库
psutil是一个跨平台进程和系统监控的Python库,而gopsutil是其Go语言版本的实现.本文介绍了它的基本使用. Go语言部署简单.性能好的特点非常适合做一些诸如采集系统信息和监控的服务,本 ...
- Qt之键盘事件监听-实时响应大小写Capslock按键
目录 一.开篇 二.效果展示 三.实现思路 1.重写QLlinEdit 2.全局应用程序事件 3.windows钩子 四.相关文章 原文链接:Qt之键盘事件监听-实时响应大小写Capslock按键 一 ...
- 【原创】(四)Linux内存模型之Sparse Memory Model
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- android 滚动时间选择器
一.概述 滚动时间选择现在貌似很常用,所以就总结一下,显示效果一般般 , 做个参考吧! 以上就是效果图,可以滚动选择 日期时间, 由于是在 5.0系统运行的,貌似5.0系统做了什么变动,下面的 &qu ...
- 【转载】pandas中的循环
原始文章链接: https://towardsdatascience.com/how-to-make-your-pandas-loop-71-803-times-faster-805030df4f06 ...
- OpenGl读取导入3D模型并且添加鼠标移动旋转显示
原文作者:aircraft 原文链接:https://www.cnblogs.com/DOMLX/p/11543828.html 最近实习要用到opengl库就是跟opencv 有点像的那个,然后下了 ...
- Nancy获取Request.Form的所有参数
Nancy是一个轻量级的webapi框架,在用Nancy框架的时候,我们经常要获取到接口的所有动态参数值, 但是Nancy的Request.Form不能够直接转成NameValueCollection ...