比hive快10倍的大数据查询利器presto部署
目前最流行的大数据查询引擎非hive莫属,它是基于MR的类SQL查询工具,会把输入的查询SQL解释为MapReduce,能极大的降低使用大数据查询的门槛, 让一般的业务人员也可以直接对大数据进行查询。但因其基于MR,运行速度是一个弊端,通常运行一个查询需等待很久才会有结果。对于此情况,创造了hive的facebook不负众望,创造了新神器---presto,其查询速度平均比hive快10倍,现在就来部署体验一下吧。
一、 准备工作
操作系统: centos7
JAVA: JDK8(155版本及以上),我使用的是jdk1.8.0_191
presto server:presto-server-0.221.tar.gz
presto client: presto-cli-0.221-executable.jar
注:
a)本次是基于hive来进行部署使用,因此相关节点已部署hadoop、hive;
b) presto官网地址为https://prestodb.github.io presto server、client及jdbc jar均可以从官网下载。
二、 部署阶段
1. 将jdk、 presto server presto client 上传至各服务器上
jdk包我上传至/usr/local 目录,并解压、配置软链接,配置环境变量,如不配置环境变量,也可在launcher里修改

presto server及client上传至 /opt/presto下,同时解压server包

2. 各节点信息如下
其中包含一个Coordinator节点及8个worker节点
| ip | 节点角色 | 节点名 |
| 192.168.11.22 | Coordinator | node22 |
| 192.168.11.50 | Worker | node50 |
| 192.168.11.51 | Worker | node51 |
| 192.168.11.52 | Worker | node52 |
| 192.168.11.53 | Worker | node53 |
| 192.168.11.54 | Worker | node54 |
| 192.168.11.55 | Worker | node55 |
| 192.168.11.56 | Worker | node56 |
| 192.168.11.57 | Worker | node57 |
3. 创建presto数据及日志目录
以下操作各节点均相同,只有配置文件处需根据各节点情况,对应修改
mkdir -p /data/presto
4. 创建etc目录
cd /opt/presto/presto-server-0.221
mkdir etc
5. 创建所需的配置文件

1)创建并配置 config.properties
如果是Coordinator节点,建议如下配置(内存大小根据实际情况修改)
vim config.properties
## 添加如下内容
coordinator=true
datasources=hive
node-scheduler.include-coordinator=false
http-server.http.port=
query.max-memory=80GB
query.max-memory-per-node=10GB
query.max-total-memory-per-node=10GB
discovery-server.enabled=true
discovery.uri=http://192.168.11.22:8080
如果是worker 节点:
vim config.properties ## 添加如下内容
coordinator=false
#datasources=hive
#node-scheduler.include-coordinator=false
http-server.http.port=
query.max-memory=80GB
query.max-memory-per-node=10GB
query.max-total-memory-per-node=10GB
#discovery-server.enabled=true
discovery.uri=http://192.168.11.22:8080
参数说明:
coordinator: 是否运行该实例为coordinator(接受client的查询和管理查询执行)。
node-scheduler.include-coordinator:coordinator是否也作为work。对于大型集群来说,在coordinator里做worker的工作会影响查询性能。
http-server.http.port:指定HTTP端口。Presto使用HTTP来与外部和内部进行交流。
query.max-memory: 查询能用到的最大总内存
query.max-memory-per-node: 查询能用到的最大单结点内存
discovery-server.enabled: Presto使用Discovery服务去找到集群中的所有结点。每个Presto实例在启动时都会在Discovery服务里注册。这样可以简化部署, 不需要额外的服务,Presto的coordinator内置一个Discovery服务。也是使用HTTP端口。
discovery.uri: Discovery服务的URI。将192.168.11.22:8080替换为coordinator的host和端口。这个URI不能以斜杠结尾,这个错误需特别注意,不然会报404错误。
另外还有以下属性:
jmx.rmiregistry.port: 指定JMX RMI的注册。JMX client可以连接此端口
jmx.rmiserver.port: 指定JXM RMI的服务器。可通过JMX监听。
2) 配置 jvm.config
vim jvm.config
# 添加如下内容
-server
-Xmx20G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill - %p
JVM配置文件包含启动Java虚拟机时的命令行选项。格式是每一行是一个命令行选项。此文件数据是由shell解析,所以选项中包含空格或特殊字符会被忽略。
3) 配置log.properties
vim log.properties
# 添加如下内容com.facebook.presto=INFO
日志级别有四种,DEBUG, INFO, WARN and ERROR
4) 配置node.properties
vim node.properties ## 添加如下内容
node.environment=presto_ocean
node.id=node22
node.data-dir=/data/presto
参数说明:
node.environment: 环境名字,Presto集群中的结点的环境名字都必须是一样的。 node.id: 唯一标识,每个结点的标识都必须是为一的。就算重启或升级Presto都必须还保持原来的标识。 node.data-dir: 数据目录,Presto用它来保存log和其他数据
5) 配置catalog及hive.properties
创建 catalog目录,因本次使用的hive,因此在此目录下创建hive.properties 并配置对应参数
mkdir catalog vim hive.properties
# 添加如下内容 connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.11.22:9083
hive.config.resources=/opt/hadoop/hadoop-3.2./etc/hadoop/core-site.xml,/opt/hadoop/hadoop-3.2./etc/hadoop/hdfs-site.xml
hive.allow-drop-table=true
至此 相关配置文件配置完成。
三、 启动presto-server并连接
进入/opt/presto/presto-server-0.221/bin,有launcher命令

如果需要配置JAVA等环境变量也可以在此文件里修改。在此处修改的好处在于可以与不同版本的jdk共存 而不影响原有业务。
1. 启动presto-server
./launcher start
此时如果/data/presto/var日志生成,且无报错信息,代表启动正常。
2. presto-cli 连接
把下载的jar包:presto-cli-0.221-executable.jar 重命名为:presto 并且赋予权限
ln -s presto-cli-0.221-executable.jar presto
chmod +x presto
./presto --server localhost:8080 --catalog hive --schema default
此时可以查看到hive里的库及表
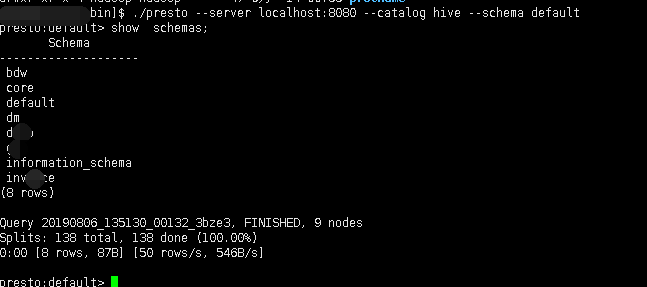
3. 查看web界面
登录http://192.168.11.22:8080/ui/可查看整体状态。

至此,presto部署就完成了。其与hive的性能对比及使用建议等后续有机会再介绍。
耿小厨已开通个人微信公众号,想进一步沟通或想了解其他文章的同学可以关注我

我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=33ja5r1x478ks
比hive快10倍的大数据查询利器presto部署的更多相关文章
- zw·10倍速大数据与全内存计算
zw·10倍速大数据与全内存计算 zw全内存10倍速计算blog,早就在博客园机器视觉栏目发过,大数据版的一直挂着,今天抽空补上. 在<零起点,python大数据与量化交易>目录中 htt ...
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- 大数据系列之分布式大数据查询引擎Presto
关于presto部署及详细介绍请参考官方链接 http://prestodb-china.com PRESTO是什么? Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持G ...
- Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性
Hadoop3.0新特性介绍,比Spark快10倍的Hadoop3.0新特性 Apache hadoop 项目组最新消息,hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+ ...
- [转帖]推荐一款比 Find 快 10 倍的搜索工具 FD
推荐一款比 Find 快 10 倍的搜索工具 FD https://www.hi-linux.com/posts/15017.html 试了下 很好用呢. Posted by Mike on 2018 ...
- 比传统事务快10倍?一张图读懂阿里云全局事务服务GTS
近日,阿里云全局事务服务GTS正式上线,为微服务架构中的分布式事务提供一站式解决方案.GTS的原理是将分布式事务与具体业务分离,在平台层面开发通用的事务中间件GTS,由事务中间件协调各服务的调用一致性 ...
- mysql 5.7 innodb count count(*) count(1) 大数据 查询慢 耗时多 优化
原文:mysql 5.7 innodb count count(*) count(1) 大数据 查询慢 耗时多 优化 问题描述 mysql 5.7 innodb 引擎 使用以下几种方法进行统计效率差不 ...
- SQL命令语句进行大数据查询如何进行优化
SQL 大数据查询如何进行优化? 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索 2.应尽量避免在 where 子句中对字段进行 null 值 ...
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
随机推荐
- 前vue.js+elementui,后koa2,nodejs搭建网站
1,安装 nodejs,npm 2,使用 npm 安装 vue,vue-cli 3,使用脚手架搭建项目,添加依赖:axios,vue-router,elementui,vuex 等 4,建立 rout ...
- 应用Tomcat进行多端口域名访问,并配置开启gzip压缩方法
1.除了默认的8080端口以外,我们尝试应用9090端口进行域名访问,打开server.xml 如图: 2.在代码里面进行添加如下9090下面的代码: 如图: 3.用9090端口进行访问 如图: 4. ...
- jeesite3环境部署时初始化数据库注意问题
---恢复内容开始--- 首先要修改jeesite.properties下数据库连接方式,注意选择自己的数据库 其次在pom.xml文件中修改对应的数据库连接方式 最后运行db文件夹下的init-db ...
- java 反编译工具 jd-gui
下载地址 http://java-decompiler.github.io/ 一般使用windows 版本 看你使用的操作系统了 解压 点击exe 进入 选择你编译后的cla ...
- 《Web Development with Go》实现一个简单的rest api
设计模式完了之后,应该实现具体的应用了. 设计模式还得没事就要复习. web应用,学习的是网上的一本书. <Web Development with Go> package main im ...
- Less(1)
1.先判断注入类型 (1)首先看到要求,要求传一个ID参数,并且要求是数字型的:?id=1 (2)再输入?id=1' 发现报错 (3)输入?id=1'' 单引号报错,双引号正常显示,判断是字符型注入: ...
- 扩展KMP笔记
KMP能计算一个字符串的每个位置前最长公共前缀后缀 扩展KMP可以用来计算两个字符串间的最长公共前缀后缀的…… 不过为了计算这个需要绕些弯路 已知字符串$S$和$P$,$S$的长度为$n$,$P$的长 ...
- git 代码管理
- js如何手写一个new
手写new 看一下正常使用new function Dog(name){ this.name = name } Dog.prototype.sayName = function(){ console. ...
- C# Stack 集合学习
Stack 集合学习 学习自:博客园相关文章 Stack<T>集合 这个集合的特点为:后进先出,简单来说就是新元素都放到第一位,而且顺序移除元素也是从第一位开始的. 方法一:Push(T ...