数据分析--pandas的基本使用
一、pandas概述
1.pandas是一个强大的Python数据分析的工具包,是基于NumPy构建的。
2.pandas的主要功能
- 具备对其功能的数据结构DataFrame、Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
3.python中操作方式:
- 安装方法:pip install pandas
- 引用方法:import pandas as pd
4.也可以通过安装anaconda软件操作,里面包含(numpy,pandas以及Matplotlib多个库),本片文章是在anaconda3中运行!!!
- anaconda下载地址请戳:https://www.anaconda.com/download/
- anaconda安装及创建项目教程:https://jingyan.baidu.com/article/3f16e0031e87522591c10320.html
二、pandas:Series(一维)
1.Series是一种类似于一位数组的对象,由一组数据和一组与之相关的数据标签(索引)组成。
2.创建方式:
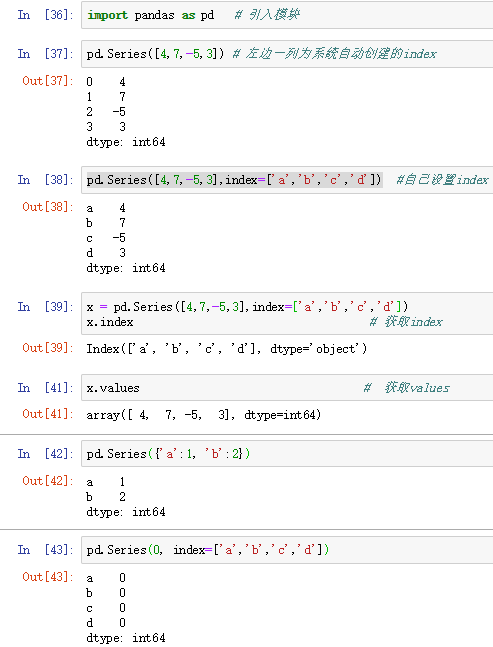
3.从上面操作可以知道:
- 获取值数组和索引数组:values属性和index属性。
- Series比较像列表(数组)和字典的组合体。
三、pandas:Series特性
1.Series支持NumPy模块的特性(下标):
- 从ndarray创建Series:Series(arr)
- 与标量运算:sr*2
- 两个Series运算:sr1+sr2
- 索引:sr[0], sr[[1,2,4]]
- 切片:sr[0:2]
- 通用函数:np.abs(sr)
- 布尔值过滤:sr[sr>0]
- 统计函数:mean()sum()cumsum()
Numpy连接:https://www.cnblogs.com/dalyday/p/9295459.html
2.Series支持字典的特性(标签):
- 从字典创建Series:Series(dic),
- in运算:’a’ in sr、for i in sr
- 键索引:sr['a'], sr[['a', 'b', 'd']]
- 键切片:sr['a':'c']
- 其他函数:get('a',default = 0)等
标签示例:

四、pandas:整数索引
1.整数索引存在标签索引与下标索引,新手在这需注意下。
2.输入下面的列子会出什么结果:
- sr2[3]
- sr2[-1]
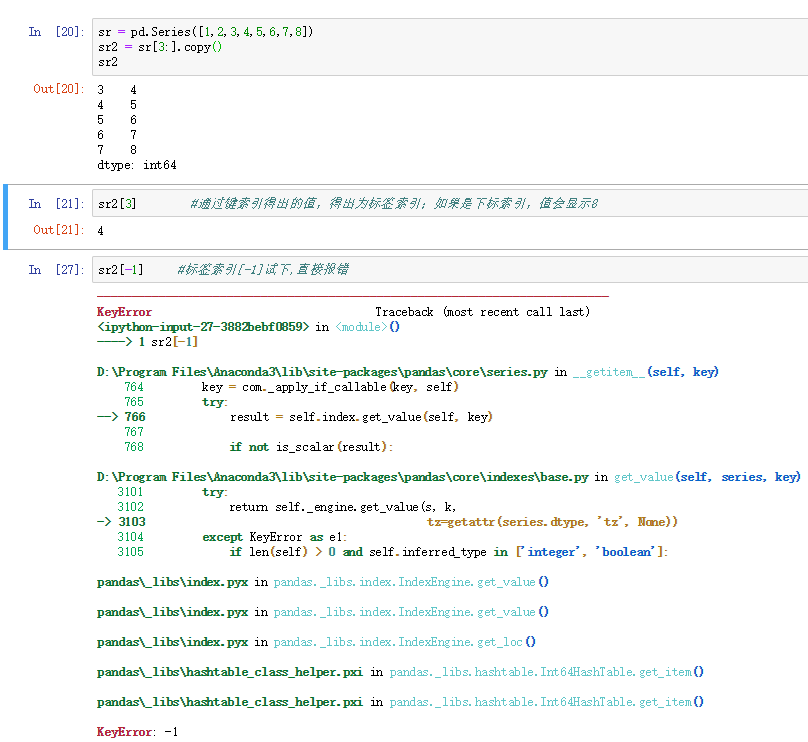
3.从上面可知索引是整数类型,则根据整数进行数据操作时总是面向标签的。
引入:
- --loc属性 以标签解释
- --iloc属性 以下标解释

五、pandas:Series数据对齐
1.pandas在运算时,会按索引进行对齐然后计算。如果存在不同的索引,则结果的索引是两个操作数索引的并集。
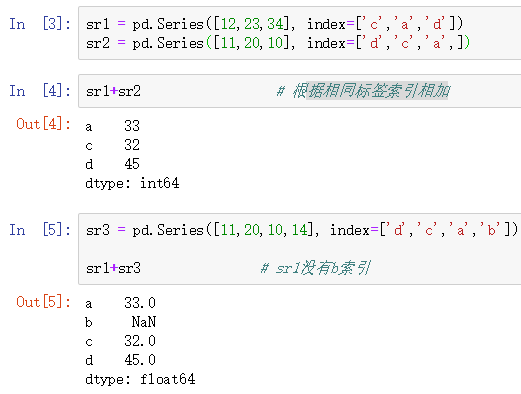
例:
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr2 = pd.Series([11,20,10], index=['d','c','a',])
sr1+sr2
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1+sr3
图例展示:
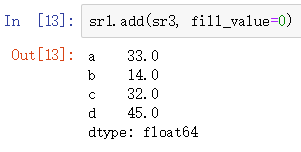
2.如何在两个Series对象相加时将缺失值设为0?
sr1.add(sr3, fill_value=0)
灵活的算术方法:add, sub, div, mul
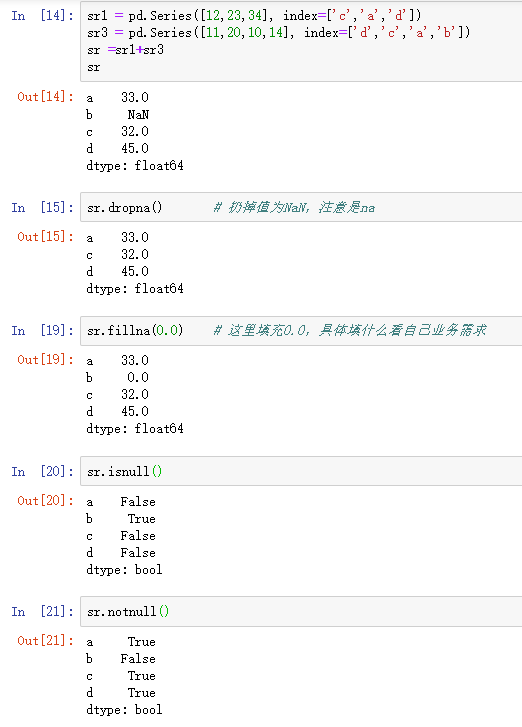
六、pandas:Series缺失数据
1.缺失数据:使用NaN(Not a Number)来表示缺失数据。其值等于np.nan。内置的None值也会被当做NaN处理。
2.处理缺失数据的相关方法:
- dropna() 过滤掉值为NaN的行
- fillna() 填充缺失数据
- isnull() 返回布尔数组,缺失值对应为True
- notnull() 返回布尔数组,缺失值对应为False
3.过滤缺失数据:sr.dropna() 或 sr[data.notnull()]
4.填充缺失数据:fillna(0)
七、pandas:DataFrame
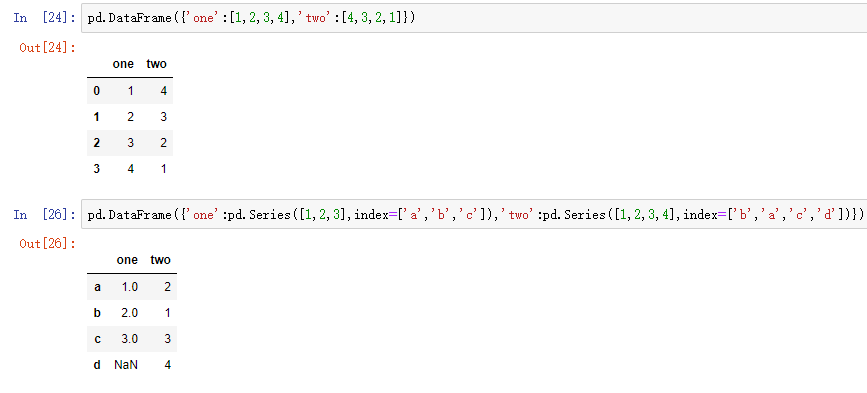
1.概要描述:DataFrame是一个表格型的数据结构,含有一组有序的列;可以被看做是由Series组成的字典,并且共用一个索引。
2.创建方式:
pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([1,2,3,4],index=['b','a','c','d'])})
3.csv文件读取与写入:
- pd.read_csv('filename.csv')
- pd.to_csv()

八、pandas:DataFrame查看数据
查看数据常用属性及方法:
index 获取索引
T 转置
columns 获取列索引
values 获取值数组
describe() 获取快速统
九、pandas:DataFrame索引和切片
1、DataFrame有行索引和列索引。
2、DataFrame同样可以通过标签和位置两种方法进行索引和切片。
3、DataFrame使用索引切片:
- 方法1.两个中括号,先取列再取行。 df['A'][0]
- 方法2(推荐):使用loc/iloc属性,一个中括号,逗号隔开,先取行再取列。
loc属性:解释为标签
iloc属性:解释为下标
- 向DataFrame对象中写入值时只使用方法2
- 行/列索引部分可以是常规索引、切片、布尔值索引、花式索引任意搭配。(注意:两部分都是花式索引时结果可能与预料的不同)
通过标签获取:
df['A']
df[['A', 'B']]
df['A'][0]
df.loc[:,['A','B']]
df.loc[:,'A':'C']
df.loc[0,'A']
df.loc[0:10,['A','C']]
通过位置获取:
df.iloc[3]
df.iloc[3,3]
df.iloc[0:3,4:6]
df.iloc[1:5,:]
通过布尔值过滤:
df[df['A']>0]
df[df['A'].isin([1,3,5])]
df[df<0] = 0
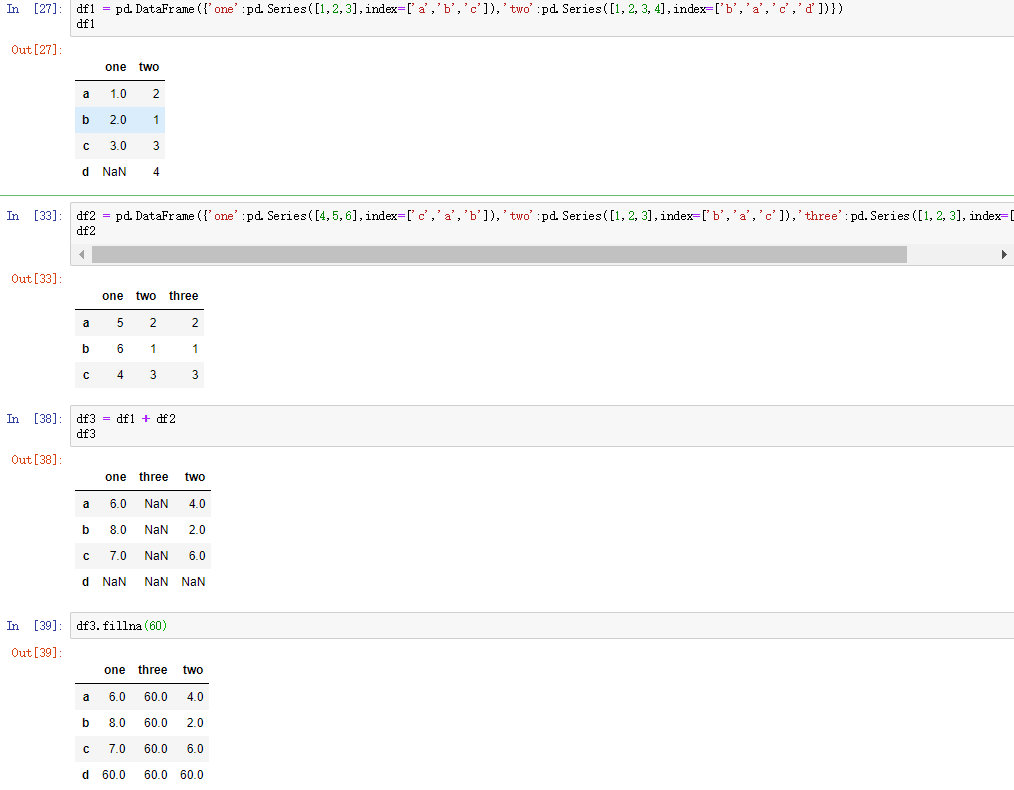
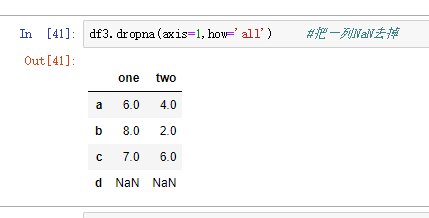
十、pandas:DataFrame数据对齐与缺失数据
1.DataFrame对象在运算时,同样会进行数据对其,结果的行索引与列索引分别为两个操作数的行索引与列索引的并集
2.DataFrame处理缺失数据的方法:
- dropna(axis=0,where='any',…)
- fillna()
- isnull()
- notnull()
十一、pandas:其他常用方法
pandas常用方法(适用Series和DataFrame):
mean(axis=0,skipna=False) #求平均值
sum(axis=1) #求和
sort_index(axis, …, ascending) #按行或列索引排序
sort_values(by, axis, ascending) #按值排序
NumPy的通用函数同样适用于pandas
apply(func, axis=0) #将自定义函数应用在各行或者各列上 ,func可返回标量或者Series
applymap(func) #将函数应用在DataFrame各个元素上
map(func) #将函数应用在Series各个元素上
十二、pandas:其他常用方法
时间类型:
时间戳:特定时刻
固定时期:如2017年7月
时间间隔:起始时间-结束时间
Python标准库:datetime
datetime.datetime.timedelta # 表示 时间间隔
dt.strftime() #f:format吧时间对象格式化成字符串
strptime() #把字符串解析成时间对象p:parse
灵活处理时间对象:dateutil包
dateutil.parser.parse('2018/1/29')
成组处理时间对象:pandas
pd.to_datetime(['2001-01-01', '2002-02-02']) 产生时间对象数组:date_range
start 开始时间
end 结束时间
periods 时间长度
freq 时间频率,默认为'D',可选H(our),W(eek),B(usiness),S(emi-)M(onth),(min)T(es), S(econd), A(year),…
十三、pandas:从文件读取
1.读取文件:从文件名、URL、文件对象中加载数据
read_csv 默认分隔符为csv
read_table 默认分隔符为\t
read_excel 读取Excel文件
2.读取文件函数主要参数:
sep 指定分隔符,可用正则表达式如'\s+'
header=None 指定文件无列名
name 指定列名 index_col 指定某列作为索引
skip_row 指定跳过某些行
na_values 指定某些字符串表示缺失值
parse_dates 指定某些列是否被解析为日期,布尔值或列表
nrows 指定读取几行文件 chunksize 分块读取文件,指定块大小
十四、pandas:写入到文件
1.写入到文件:
to_csv
2.写入文件函数的主要参数:
sep
na_rep 指定缺失值转换的字符串,默认为空字符串
header=False 不输出列名一行
index=False 不输出行索引一列
cols 指定输出的列,传入列表
3.其他文件类型:json, XML, HTML, 数据库
4.pandas转换为二进制文件格式(pickle):
save
load
数据分析--pandas的基本使用的更多相关文章
- 利用Python进行数据分析——pandas入门
利用Python进行数据分析--pandas入门 基于NumPy建立的 from pandas importSeries,DataFrame,import pandas as pd 一.两种数据结构 ...
- Python数据分析--Pandas知识点(三)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) Python数据分析--Pandas知识点(二) 下面将是在知识点一, ...
- Python数据分析--Pandas知识点(二)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) 下面将是在知识点一的基础上继续总结. 13. 简单计算 新建一个数据表 ...
- 利用Python进行数据分析-Pandas(第一部分)
利用Python进行数据分析-Pandas: 在Pandas库中最重要的两个数据类型,分别是Series和DataFrame.如下的内容主要围绕这两个方面展开叙述! 在进行数据分析时,我们知道有两个基 ...
- 数据分析——pandas
简介 import pandas as pd # 在数据挖掘前一个数据分析.筛选.清理的多功能工具 ''' pandas 可以读入excel.csv等文件:可以创建Series序列,DataFrame ...
- python 数据分析--pandas
接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利用pandas的DataFrames进行统计分析 ...
- Python数据分析Pandas库方法简介
Pandas 入门 Pandas简介 背景:pandas是一个Python包,提供快速,灵活和富有表现力的数据结构,旨在使“关系”或“标记”数据的使用既简单又直观.它旨在成为在Python中进行实际, ...
- Python数据分析-Pandas(Series与DataFrame)
Pandas介绍: pandas是一个强大的Python数据分析的工具包,是基于NumPy构建的. Pandas的主要功能: 1)具备对其功能的数据结构DataFrame.Series 2)集成时间序 ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- python之数据分析pandas
做数据分析的同学大部分入门都是从excel开始的,excel也是微软office系列评价最高的一种工具. 但当数据量超过百万行的时候,excel就无能无力了,python第三方包pandas极大的扩展 ...
随机推荐
- Worker Service in ASP .NET Core
介绍 提到 ASP.NET Core,我们多半会想到 ASP.NET MVC.ASP.NET Web API.Razor page 及 Blazor.随着 .NET Core 3.0 的推出,今天会介 ...
- Oracle大量数据更新策略
生产上要修改某个产品的产品代号, 而我们系统是以产品为中心的, 牵一发而动全身, 涉及表几乎覆盖全部, 有些表数据量是相当大的, 达到千万, 亿级别. 单纯的维护产品代号的 SQL 是不难的, 但是性 ...
- 选择排序、快速排序、归并排序、堆排序、快速排序实现及Sort()函数使用
1.问题来源 在刷题是遇到字符串相关问题中使用 strcmp()函数. 在函数比较过程中有使用 排序函数 Sort(beg,end,comp),其中comp这一项理解不是很彻底. #include & ...
- light 1205 - Palindromic Numbers(数位dp)
题目链接:http://www.lightoj.com/volume_showproblem.php?problem=1205 题解:这题作为一个数位dp,是需要咚咚脑子想想的.这个数位dp方程可能不 ...
- poj2528 Mayor's posters(线段树区间修改+特殊离散化)
Description The citizens of Bytetown, AB, could not stand that the candidates in the mayoral electio ...
- 天梯杯 PAT L2-001. 紧急救援 最短路变形
作为一个城市的应急救援队伍的负责人,你有一张特殊的全国地图.在地图上显示有多个分散的城市和一些连接城市的快速道路.每个城市的救援队数量和每一条连接两个城市的快速道路长度都标在地图上.当其他城市有紧急求 ...
- nvm 管理多个活动的node.js版本
前序:最近在使用taro框架开发小程序,因为安装taro时遇到一些问题,后来重新安装了node版本——v10.16.3,却影响了我本地开发的项目,故此使用nvm来管理node的版本,更加灵活的切换以支 ...
- 使用FlameGraph火焰图分析JAVA应用性能
开源项目推荐 Pepper Metrics是我与同事开发的一个开源工具(https://github.com/zrbcool/pepper-metrics),其通过收集jedis/mybatis/ht ...
- MySQL和mybatis查询相关
0.mybatis的xml文件头 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapp ...
- Docker详解(二)
目录 1.Docker常用命令 1.1 镜像命令 1.2 容器命令 1.2.1 常用的容器命令 1.2.2 重要的容器命令 序言:上一章我们初步介绍了一下Docker的概念,那么这次我们着手于Dock ...