ElasticSearch 中文分词插件ik 的使用

下载
IK 的版本要与 Elasticsearch 的版本一致,因此下载 7.1.0 版本。
安装
1、中文分词插件下载地址:https://github.com/medcl/elasticsearch-analysis-ik
2、拼音分词插件下载地址:https://github.com/medcl/elasticsearch-analysis-pinyin
下载你对应的版本

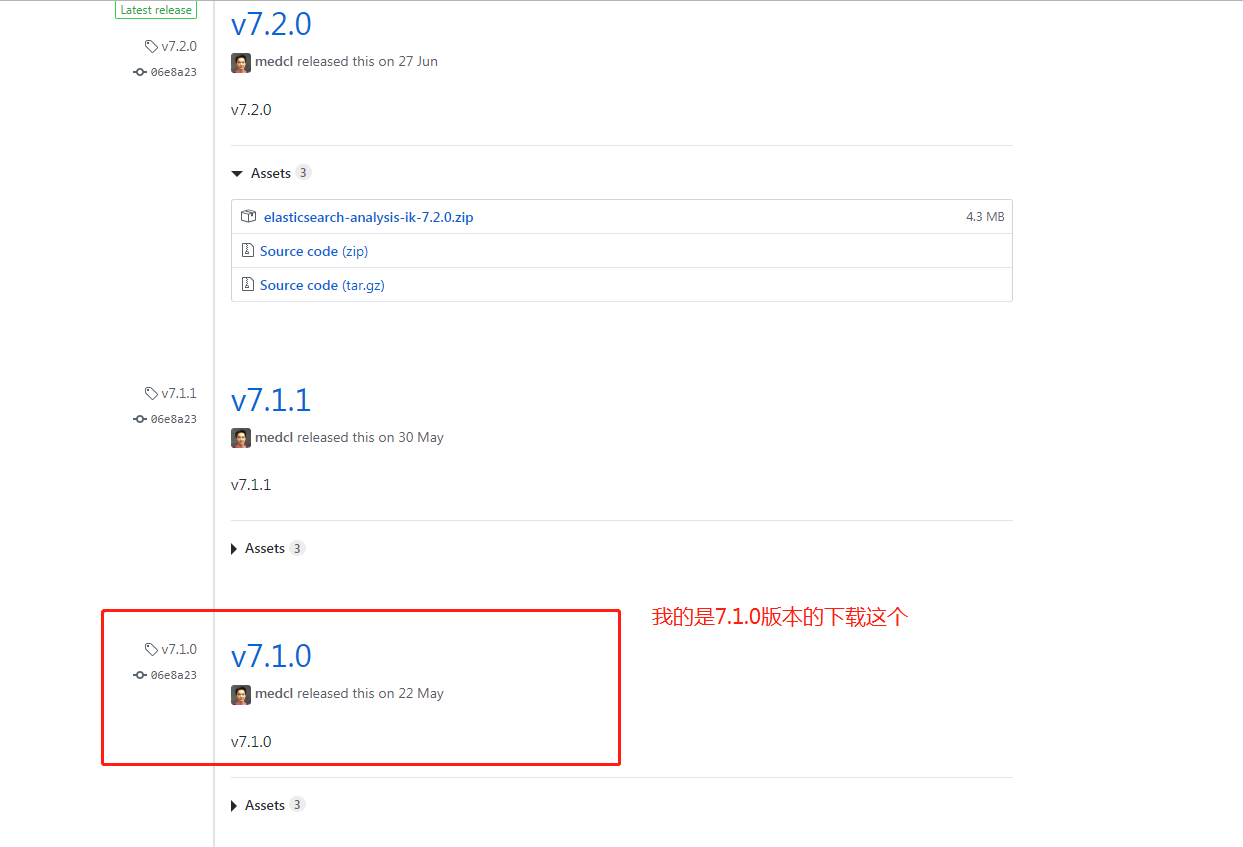
将解压后的 IK 文件夹,放入 elasticsearch 文件夹下的 plugins/ik 目录下。
启动 Elasticsearch 后,看到下图,表示启动成功。

扩展本地词库
在 plugins\ik\config\custom 目录下新增文件 hotwords.dic。如添加 洪荒之力 。每一个词语一行。
在 plugins\ik\config 文件夹下的 IKAnalyzer.cfg.xml 文件配置本地词库。
<!--用户可以在这里配置自己的扩展字典,如果多个字典,则用分号分隔 custom/mydict.dic;custom/single_word_low_freq.dic-->
<entry key="ext_dict">custom/hotwords.dic</entry>
重新启动 Elasticsearch 显示如下图,表示启动成功。

文档的中文分词使用
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
下面我们分别测试下。
先测试ik_max_word,输入命令如下:
POST http://localhost:9200/_analyze
{
"analyzer": "ik_max_word",
"text": "世界如此之大"
}
响应结果如下:
{
"tokens": [
{
"token": "世界",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "如此之",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "如此",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "之大",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
再测试ik_smart,输入命令如下:
POST http://localhost:9200/_analyze
{
"analyzer": "ik_smart",
"text": "世界如此之大"
}
响应结果如下:
{
"tokens": [
{
"token": "世界",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "如此",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "之大",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
通过Docker 安装elasticsearch-analysis-ik-6.4.5插件
FROM docker.elastic.co/elasticsearch/elasticsearch:6.4.5
ADD elasticsearch-analysis-ik-6.4.5 /usr/share/elasticsearch/plugins/elasticsearch-analysis-ik-6.4.5
ElasticSearch 中文分词插件ik 的使用的更多相关文章
- ElasticSearch(三) ElasticSearch中文分词插件IK的安装
正因为Elasticsearch 内置的分词器对中文不友好,会把中文分成单个字来进行全文检索,所以我们需要借助中文分词插件来解决这个问题. 一.安装maven管理工具 Elasticsearch 要使 ...
- ElasticSearch(四) ElasticSearch中文分词插件IK的简单测试
先来一个简单的测试 # curl -XPOST "http://192.168.9.155:9200/_analyze?analyzer=standard&pretty" ...
- Elasticsearch安装中文分词插件ik
Elasticsearch默认提供的分词器,会把每一个汉字分开,而不是我们想要的依据关键词来分词.比如: curl -XPOST "http://localhost:9200/userinf ...
- Elasticsearch如何安装中文分词插件ik
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库. 安装步骤: 1.到github网站下载源代码,网站地址为:https://github.com/medcl/ ...
- ElasticSearch中文分词(IK)
ElasticSearch常用的很受欢迎的是IK,这里稍微介绍下安装过程及测试过程. 1.ElasticSearch官方分词 自带的中文分词器很弱,可以体检下: [zsz@VS-zsz ~]$ c ...
- ElasticSearch-5.0.0安装中文分词插件IK
Install IK 源码地址:https://github.com/medcl/elasticsearch-analysis-ik,git clone下来. 1.compile mvn packag ...
- ElasticSearch中文分词器-IK分词器的使用
IK分词器的使用 首先我们通过Postman发送GET请求查询分词效果 GET http://localhost:9200/_analyze { "text":"农业银行 ...
- Elasticsearch 中文分词器IK
1.安装说明 https://github.com/medcl/elasticsearch-analysis-ik 2.release版本 https://github.com/medcl/elast ...
- ElasticSearch搜索引擎安装配置中文分词器IK插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
随机推荐
- ps查看图层大小快捷键
1.图层大小尺寸的: ctrl+alt+c 2.图片大小尺寸.像素大小: ctrl+alt+i
- 转 Oracle中关于处理小数点位数的几个函数,取小数位数,Oracle查询函数
关于处理小数点位数的几个oracle函数() 1. 取四舍五入的几位小数 select round(1.2345, 3) from dual; 结果:1.235 2. 保留两位小数,只舍 select ...
- CSS技巧 (1) · 结构和布局
前言 这一篇主要是总结关于结构和布局的一些技巧,不管什么,一个网页上来,最重要的是先确定他的结构和布局,实现基本的布局之后,我们再进行局部的优化和交互特效. 这一篇主要讲 关于 自适应内部元素 的内 ...
- ABP vNext 不使用工作单元为什么会抛出异常
一.问题 该问题经常出现在 ABP vNext 框架当中,要复现该问题十分简单,只需要你注入一个 IRepository<T,TKey> 仓储,在任意一个地方调用 IRepository& ...
- node.js操作数据库之MongoDB+mongoose篇
前言 node.js的出现,使得用前端语法(javascript)开发后台服务成为可能,越来越多的前端因此因此接触后端,甚至转向全栈发展.后端开发少不了数据库的操作.MongoDB是一个基于分布式文件 ...
- CocosCreator 快速开发推箱子游戏,附代码
游戏总共分为4个功能模块: - 开始游戏(menuLayer) - 关卡选择(levelLayer) - 游戏(gameLayer) - 游戏结算(gameOverLayer) Creator内组件效 ...
- 美化你的IDEA—背景图片
IDEA设置背景图片 很多人都不知道IDEA可以像桌面一样设置背景图片,下面我们来美化我们的开发工具. 有的IDEA版本是搜不到的,我这个就是,现在搜的是已经装好的. 没有的我们可以去http://p ...
- 机器学习中梯度下降法原理及用其解决线性回归问题的C语言实现
本文讲梯度下降(Gradient Descent)前先看看利用梯度下降法进行监督学习(例如分类.回归等)的一般步骤: 1, 定义损失函数(Loss Function) 2, 信息流forward pr ...
- Mac安装Command Line Tools
从App Store上下载的Xcode,默认是不会安装Command Line Tools的,Command Line Tools是在Xcode中的一款工具,可以在命令行中运行C程序. 在终端中输入命 ...
- linux 防火墙基本使用
写在最前面 由于工作后,使用的Linux就是centos7 所以,本文记录是是centos7的防火墙使用. 从 centos7 开始,系统使用 firewall 进行防火墙的默认管理工具. 基本使用 ...