带你从头到尾捋一遍MySQL索引结构(2)
前言
Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结。索性这次把数据库中最核心的也是最难搞懂的内容,也就是索引,分享给大家。
这篇博客我会谈谈对于索引结构我自己的看法,以及分享如何从零开始一层一层向上最终理解索引结构,书接上文。
多页模式
在多页模式下,MySQL终于可以完成多数据的存储了,就是采用开辟新页的方式,将多条数据放在不同的页中,然后同样采用链表的数据结构,将每一页连接起来。那么可以思考第四个问题:多页情况下是否对查询效率有影响呢?
多页模式对于查询效率的影响
针对这个问题,既然问出来了,那么答案是肯定的,多页会对查询效率产生一定的影响,影响主要就体现在,多页其本质也是一个链表结构,只要是链表结构,查询效率一定不会高。
假设数据又非常多条,数据库就会开辟非常多的新页,而这些新页就会像链表一样连接在一起,当我们要在这么多页中查询某条数据时,它还是会从头节点遍历到存在我们要查找的那条数据所存在的页上,我们好不容易通过页目录优化了页中数据的查询效率,现在又出现了以页为单位的链表,这不是前功尽弃了吗?
如何优化多页模式
由于多页模式会影响查询的效率,那么肯定需要有一种方式来优化多页模式下的查询。相信有同学已经猜出来了,既然我们可以用页目录来优化页内的数据区,那么我们也可以采取类似的方式来优化这种多页的情况。
是的,页内数据区和多页模式本质上都是链表,那么的确可以采用相同的方式来对其进行优化,它就是目录页。
所以我们对比页内数据区,来分析如何优化多页结构。在单页时,我们采用了页目录的目录项来指向一行数据,这条数据就是存在于这个目录项中的最小数据,那么就可以通过页目录来查找所需数据。
所以对于多页结构也可以采用这种方式,使用一个目录项来指向某一页,而这个目录项存放的就是这一页中存放的最小数据的索引值。和页目录不同的地方在于,这种目录管理的级别是页,而页目录管理的级别是行。
那么分析到这里,我们多页模式的结构就会是下图所示的这样:
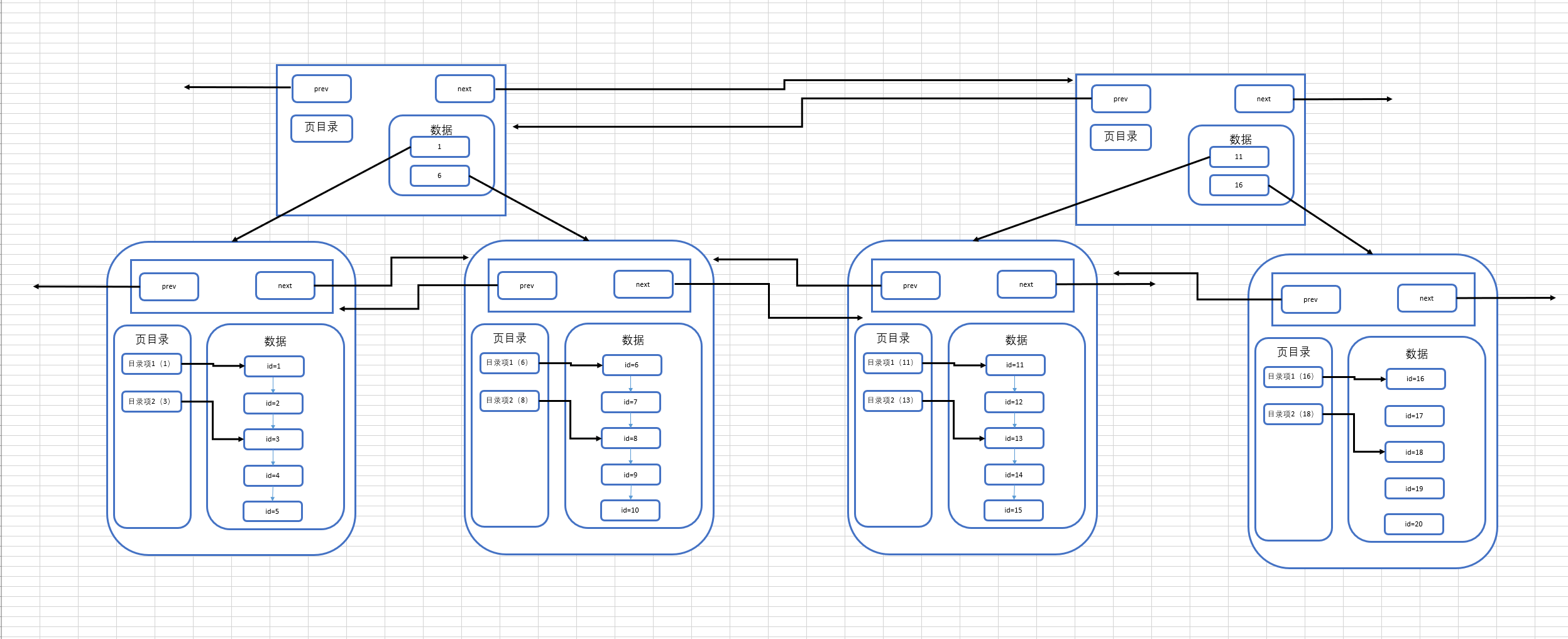
存在一个目录页来管理页目录,目录页中的数据存放的就是指向的那一页中最小的数据。
这里要注意的一点是:其实目录页的本质也是页,普通页中存的数据是项目数据,而目录页中存的数据是普通页的地址。
假设我们要查找id=19的数据,那么按照以前的查找方式,我们需要从第一页开始查找,发现不存在那么再到第二页查找,一直找到第四页才能找到id=19的数据,但是如果有了目录页,就可以使用id=19与目录页中存放的数据进行比较,发现19大于任何一条数据,于是进入id=16指向的页进行查找,直接然后再通过页内的页目录行级别的数据的查找,很快就可以找到id为19的数据了。随着数据越来越多,这种结构的效率相对于普通的多页模式,优势也就越来越明显。
回归正题,相信有对MySQL比较了解的同学已经发现了,我们画的最终的这幅图,就是MySQL中的一种索引结构——B+树。
B+树的引入
我们将我们画的存在目录页的多页模式图宏观化,可以形成下面的这张图:

这就是我们兜兜转转由简到繁形成的一颗B+树。和常规B+树有些许不同,这是一棵MySQL意义上的B+树,MySQL的一种索引结构,其中的每个节点就可以理解为是一个页,而叶子节点也就是数据页,除了叶子节点以外的节点就是目录页。
这一点在图中也可以看出来,非叶子节点只存放了索引,而只有叶子节点中存放了真实的数据,这也是符合B+树的特点的。
B+树的优势
由于叶子节点上存放了所有的数据,并且有指针相连,每个叶子节点在逻辑上是相连的,所以对于范围查找比较友好。
B+树的所有数据都在叶子节点上,所以B+树的查询效率稳定,一般都是查询3次。
B+树有利于数据库的扫描。
B+树有利于磁盘的IO,因为他的层高基本不会因为数据扩大而增高(三层树结构大概可以存放两千万数据量。
页的完整结构
说完了页的概念和页是如何一步一步地组合称为B+树的结构之后,相信大家对于页都有了一个比较清楚的认知,所以这里就要开始说说官方概念了,基于我们上文所说的,给出一个完整的页结构,也算是对上文中自己理解页结构的一种补充。

上图为 Page 数据结构,File Header 字段用于记录 Page 的头信息,其中比较重要的是 FIL_PAGE_PREV 和 FIL_PAGE_NEXT 字段,通过这两个字段,我们可以找到该页的上一页和下一页,实际上所有页通过两个字段可以形成一条双向链表。
Page Header 字段用于记录 Page 的状态信息。接下来的 Infimum 和 Supremum 是两个伪行记录,Infimum(下确界)记录比该页中任何主键值都要小的值,Supremum (上确界)记录比该页中任何主键值都要大的值,这个伪记录分别构成了页中记录的边界。
User Records 中存放的是实际的数据行记录,具体的行记录结构将在本文的第二节中详细介绍。Free Space 中存放的是空闲空间,被删除的行记录会被记录成空闲空间。Page Directory 记录着与二叉查找相关的信息。File Trailer 存储用于检测数据完整性的校验和等数据。
引用来源:https://www.cnblogs.com/bdsir/p/8745553.html
基于B+树聊聊MySQL的其它知识点
看到这里,我们已经了解了MySQL从单条数据开始,到通过页来减少磁盘IO次数,并且在页中实现了页目录来优化页中的查询效率,然后使用多页模式来存储大量的数据,最终使用目录页来实现多页模式的查询效率并形成我们口中的索引结构——B+树。既然说到这里了,那我们就来聊聊MySQL的其他知识点。
聚簇索引和非聚簇索引
所谓聚簇索引,就是将索引和数据放到一起,找到索引也就找到了数据,我们刚才看到的B+树索引就是一种聚簇索引,而非聚簇索引就是将数据和索引分开,查找时需要先查找到索引,然后通过索引回表找到相应的数据。InnoDB有且只有一个聚簇索引,而MyISAM中都是非聚簇索引。
联合索引的最左前缀匹配原则
在MySQL数据库中不仅可以对某一列建立索引,还可以对多列建立一个联合索引,而联合索引存在一个最左前缀匹配原则的概念,如果基于B+树来理解这个最左前缀匹配原则,相对来说就会容易很很多了。
首先我们基于文首的这张表建立一个联合索引:
create index idx_obj on user(age asc,height asc,weight asc)
我们已经了解了索引的数据结构是一颗B+树,也了解了B+树优化查询效率的其中一个因素就是对数据进行了排序,那么我们在创建idx_obj这个索引的时候,也就相当于创建了一颗B+树索引,而这个索引就是依据联合索引的成员来进行排序,这里是age,height,weight。
看过我之前那篇博客的同学知道,InnoDB中只要有主键被定义,那么主键列被作为一个聚簇索引,而其它索引都将被作为非聚簇索引,所以自然而然的,这个索引就会是一个非聚簇索引。
所以根据这些我们可以得出结论:
idx_obj这个索引会根据age,height,weight进行排序
idx_obj这个索引是一个非聚簇索引,查询时需要回表
根据这两个结论,首先需要了解的就是,如何排序?
单列排序很简单,比大小嘛,谁都会,但是多列排序是基于什么原则的呢(重点)?
实际上在MySQL中,联合索引的排序有这么一个原则,从左往右依次比较大小,就拿刚才建立的索引举例子,他会先去比较age的大小,如果age的大小相同,那么比较height的大小,如果height也无法比较大小, 那么就比较weight的大小,最终对这个索引进行排序。
那么根据这个排序我们也可以画出一个B+树,这里就不像上文画的那么详细了,简化一下:
数据:
B+树:

注意:此时由于是非聚簇索引,所以叶子节点不在有数据,而是存了一个主键索引,最终会通过主键索引来回表查询数据。
B+树的结构有了,就可以通过这个来理解最左前缀匹配原则了。
我们先写一个查询语句
SELECT * FROM user WHERE age=1 and height = 2 and weight = 7
毋庸置疑,这条语句一定会走idx_obj这个索引。
那么我们再看一个语句:
SELECT * FROM user WHERE height=2 and weight = 7
思考一下,这条SQL会走索引吗?
答案是否定的,那么我们分析的方向就是,为什么这条语句不会走索引。
上文中我们提到了一个多列的排序原则,是从左到右进行比较然后排序的,而我们的idx_obj这个索引从左到右依次是age,height,weight,所以当我们使用height和weight来作为查询条件时,由于age的缺失,那么就无法从age来进行比较了。
看到这里可能有小伙伴会有疑问,那如果直接用height和weight来进行比较不可以吗?显然是不可以的,可以举个例子,我们把缺失的这一列写作一个问号,那么这条语句的查询条件就变成了?27,那么我们从这课B+树的根节点开始,根节点上有127和365,那么以height和weight来进行比较的话,走的一定是127这一边,但是如果缺失的列数字是大于3的呢?比如427,527,627,那么如果走索引来查询数据,将会丢失数据,错误查询。所以这种情况下是绝对不会走索引进行查询的。这就是最左前缀匹配原则的成因。
- 最左前缀匹配原则,MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如 a=3 and b=4 and c>5 and d=6,如果建立(a,b,c,d)顺序的索引,d是无法使用索引的,如果建立(a,b,d,c)的索引则都可以使用到,a、b、d的顺序可以任意调整。
- =和in可以乱序,比如 a=1 and b=2 and c=3 建立(a,b,c)索引可以任意顺序,MySQL的查询优化器会帮你优化成索引可以识别的形式。
根据我们了解的可以得出结论:
只要无法进行排序比较大小的,就无法走联合索引。
可以再看几个语句:
SELECT * FROM user WHERE age=1 and height = 2
这条语句是可以走idx_obj索引的,因为它可以通过比较 (12?<365)。
SELECT * FROM user WHERE age=1 and weight=7
这条语句也是可以走ind_obj索引的,因为它也可以通过比较(1?7<365),走左子树,但是实际上weight并没有用到索引,因为根据最左匹配原则,如果有两页的age都等于1,那么会去比较height,但是height在这里并不作为查询条件,所以MySQL会将这两页全都加载到内存中进行最后的weight字段的比较,进行扫描查询。
SELECT * FROM user where age>1
这条语句不会走索引,但是可以走索引。这句话是什么意思呢?这条SQL很特殊,由于其存在可以比较的索引,所以它走索引也可以查询出结果,但是由于这种情况是范围查询并且是全字段查询,如果走索引,还需要进行回表,MySQL查询优化器就会认为走索引的效率比全表扫描还要低,所以MySQL会去优化它,让他直接进行全表扫描。
SELECT * FROM user WEHRE age=1 and height>2 and weight=7
这条语句是可以走索引的,因为它可以通过age进行比较,但是weight不会用到索引,因为height是范围查找,与第二条语句类似,如果有两页的height都大于2,那么MySQL会将两页的数据都加载进内存,然后再来通过weight匹配正确的数据。
为什么InnoDB只有一个聚簇索引,而不将所有索引都使用聚簇索引?
因为聚簇索引是将索引和数据都存放在叶子节点中,如果所有的索引都用聚簇索引,则每一个索引都将保存一份数据,会造成数据的冗余,在数据量很大的情况下,这种数据冗余是很消耗资源的。
补充两个关于索引的点
这两个点也是上次写关于索引的博客时漏下的,这里补上。
1.什么情况下会发生明明创建了索引,但是执行的时候并没有通过索引呢?
科普时间:查询优化器 一条SQL语句的查询,可以有不同的执行方案,至于最终选择哪种方案,需要通过优化器进行选择,选择执行成本最低的方案。
在一条单表查询语句真正执行之前,MySQL的查询优化器会找出执行该语句所有可能使用的方案,对比之后找出成本最低的方案。这个成本最低的方案就是所谓的执行计划。
优化过程大致如下:
1、根据搜索条件,找出所有可能使用的索引
2、计算全表扫描的代价
3、计算使用不同索引执行查询的代价
4、对比各种执行方案的代价,找出成本最低的那一个 。
参考:https://juejin.im/post/5d23ef4ce51d45572c0600bc
根据我们刚才的那张表的非聚簇索引,这条语句就是由于查询优化器的作用,造成没有走索引:
SELECT * FROM user where age>1
2.在稀疏索引情况下通常需要通过叶子节点的指针回表查询数据,什么情况下不需要回表?
科普时间:覆盖索引 覆盖索引(covering index)指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。也可以称之为实现了索引覆盖。
当一条查询语句符合覆盖索引条件时,MySQL只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作,减少I/O提高效率。
如,表covering_index_sample中有一个普通索引 idx_key1_key2(key1,key2)。当我们通过SQL语句:select key2 from covering_index_sample where key1 = 'keytest';的时候,就可以通过覆盖索引查询,无需回表。
参考:https://juejin.im/post/5d23ef4ce51d45572c0600bc
例如:
SELECT age FROM user where age = 1
这句话就不需要进行回表查询。
结语
本篇文章着重聊了一下关于MySQL的索引结构,从零开始慢慢构建了一个B+树索引,并且根据这个过程谈了B+树是如何一步一步去优化查询效率的。
简单地归纳一下就是:
排序:优化查询的根本,插入时进行排序实际上就是为了优化查询的效率。
页:用于减少IO次数,还可以利用程序局部性原理,来稍微提高查询效率。
页目录:用于规避链表的软肋,避免在查询时进行链表的扫描。
多页:数据量增加的情况下开辟新页来保存数据。
目录页:“特殊的页目录”,其中保存的数据是页的地址。查询时可以通过目录页快速定位到页,避免多页的扫描。
END
带你从头到尾捋一遍MySQL索引结构(2)的更多相关文章
- 索引很难么?带你从头到尾捋一遍MySQL索引结构,不信你学不会!
前言 Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结.自上上篇写了手动搭建Redis集群和MySQL主从同步(非Docker)和上篇写了动手实现MySQL读写分离and故 ...
- 带你从头到尾捋一遍MySQL索引结构(1)
从一个简单的表开始 create table user( id int primary key, age int, height int, weight int, name varchar(32) ) ...
- 带你从头到尾捋一遍MySQL索引结构
索性这次把数据库中最核心的也是最难搞懂的内容,也就是索引,分享给大家. 这篇博客我会谈谈对于索引结构我自己的看法,以及分享如何从零开始一层一层向上最终理解索引结构. 从一个简单的表开始 create ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- Mysql索引结构及常见索引的区别
一.Mysql索引主要有两种结构:B+Tree索引和Hash索引 Hash索引 mysql中,只有Memory(Memory表只存在内存中,断电会消失,适用于临时表)存储引擎显示支持Hash索引,是M ...
- 【转】由浅入深探究mysql索引结构原理、性能分析与优化
摘要: 第一部分:基础知识 第二部分:MYISAM和INNODB索引结构 1.简单介绍B-tree B+ tree树 2.MyisAM索引结构 3.Annode索引结构 4.MyisAM索引与Inno ...
- B-/B+树 MySQL索引结构
索引 索引的简介 简单来说,索引是一种数据结构 其目的在于提高查询效率 可以简单理解为“排好序的快速查找结构” 一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在中磁 ...
- MySQL 索引结构 hash 有序数组
MySQL 索引结构 hash 有序数组 除了最常见的树形索引结构,Hash索引也有它的独到之处. Hash算法 Hash本身是一种函数,又被称为散列函数. 它的思路很简单:将key放在数组里,用 ...
- 一天五道Java面试题----第七天(mysql索引结构,各自的优劣--------->事务的基本特性和隔离级别)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1 .mysql索引结构,各自的优劣 2 .索引的设计原则 3 .mysql锁的类型有哪些 4 .mysql执行计划怎么看 ...
随机推荐
- phpexcel导出数字带E的解决方法
phpexcel导出数字带E的解决方法 excel之所以带E 是因为按照数字格式来显示了(数字过长的时候) 数字左边或者右边加空格就变成字符串了 那么excel就会按照字符串格式来显示了 就不会带E了
- Java程序线上故障排查
目录 一.Linux 内存和cpu 网络 磁盘 /proc文件系统 二.JVM Java堆和垃圾收集器 gc日志分析 JVMTI介绍 Attach机制 java自带工具 三.三方工具 jprofile ...
- 前端Leader你应该知道的NPM包管理机制
npm install 命令 首先总结下npm 安装一个模块包的常用命令. /* 模块依赖会写入 dependencies 节点 */ npm install moduleName npm insta ...
- JavaScript中BOM与DOM的使用
BOM: 概念:Browser Object Model 浏览器对象模型 将浏览器的各个组成部分封装成对象. 组成: Window:窗口对象 Navigator:浏览器对象 Screen:显示器屏幕对 ...
- 微信 AES 解密报错 Illegal key size 三种解决办法
微信 AES 解密报错 Illegal key size Java 环境 java version "1.8.0_151" Java(TM) SE Runtime Environm ...
- beyong Compare4解决30天的评估期结束
刚开始是删掉注册表的CacheId(无效) 1.在搜索栏中输入 regedit ,打开注册表2.删除项目CacheId :HKEY_CURRENT_USER\Software\Scooter Soft ...
- nyoj 82-迷宫寻宝(一) (多重BFS)
82-迷宫寻宝(一) 内存限制:64MB 时间限制:1000ms 特判: No 通过数:3 提交数:5 难度:4 题目描述: 一个叫ACM的寻宝者找到了一个藏宝图,它根据藏宝图找到了一个迷宫,这是一个 ...
- 构思一个在windows下仿objc基于动画层ui编程的ui引擎
用c/c++编程有些年了,十个指头可以数齐,在涉入iOS objc开发后,有种无比舒服的感觉,尤其在UI开发上. 在QuartzCore.framework下动画和透明窗口等许多效果的事都变得那么方便 ...
- 一 linuk系统简介
开源软件 使用的自由,绝大多数开源软件免费 研究的自由,可以获得软件源代码 散播及改良的自由,可以自由传播 改良甚至销售 linuk应用领域 基于linuk的企业服务器 扫描踩点网站www.netcr ...
- js 关于apply和call的理解使用
关于call和apply,以前也思考良久,很多时候都以为记住了,但是,我太难了.今天我特地写下笔记,希望可以完全掌握这个东西,也希望可以帮助到任何想对学习这个东西的同学. 一.apply函数定义与理解 ...