同步与互斥_percpu变量
percpu变量的关键就是:要求根据CPU的个数,在内存中生成多份拷贝,并且能够根据变量名和CPU编号,正确的对各个CPU的变量进行寻址。
采用per-cpu变量有下列好处:所需数据很可能存在于处理器的缓存中,因此可以更快速地访问。如果在多处理器系统中多个CPU可能同时访问变量,会引发一些通信方面的问题,采用percpu变量恰好规避了这个问题。
这里读者只需要记住percpu变量每个CPU都有一个就行了,看完本篇文章后,再回来阅读前面加粗的话,相信会有更深刻的理解。
首先来看如何定义一个percpu变量:
DEFINE_PER_CPU(int, cpu_number); #define DEFINE_PER_CPU(type, name) \
__attribute__((__section__(".data.percpu"))) __typeof__(type) per_cpu__##name
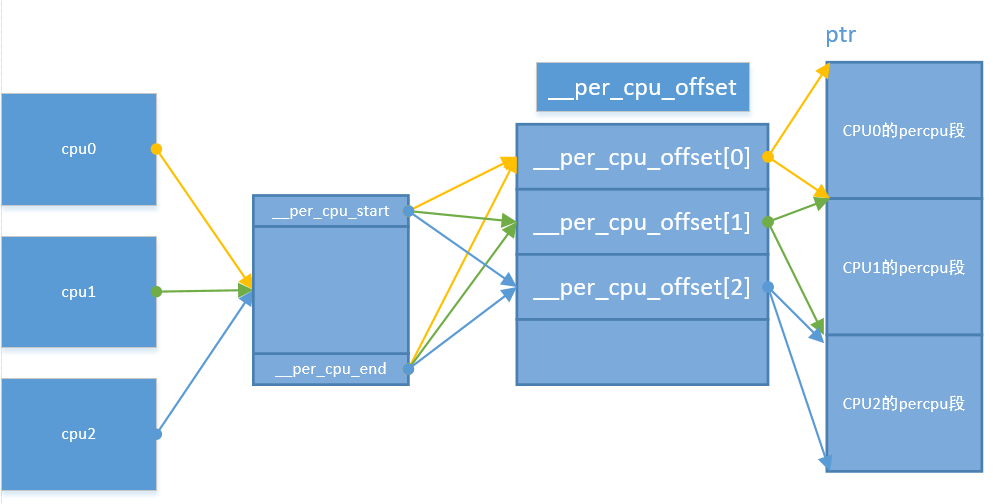
上面的代码定义了一个类型为int,名字为per_cpu_cpu_number的percpu变量。__typeof__(type)得到的就是int,而per_cpu__##name得到的就是per_cpu_cpu_number,并且通过__section__把这个变量放到名为.data.percpu的数据段。因此在编译时所有的percpu变量都会统一放到.data.percpu数据段,当内核启动后,会根据检测到的cpu个数从数据段.data.percpu为各个CPU单独复制一份。start_kernel函数调用setup_per_cpu_areas()来完成这个工作,setup_per_cpu_areas定义如下:
//__per_cpu_offset数组用来保存CPU对应 percpu段 相对ptr的偏移
unsigned long __per_cpu_offset[NR_CPUS] __read_mostly; static void __init setup_per_cpu_areas(void)
{
unsigned long size, i;
char *ptr;
//取CPU的数量
unsigned long nr_possible_cpus = num_possible_cpus(); /* Copy section for each CPU (we discard the original) */
/* 计算每个CPU所需要的percpu段大小。
*
* @PERCPU_ENOUGH_ROOM:__per_cpu_end - __per_cpu_start + PERCPU_MODULE_RESERVE
* @ALIGN():使percpu段大小向上对齐
*/
size = ALIGN(PERCPU_ENOUGH_ROOM, PAGE_SIZE);
//分配内存
ptr = alloc_bootmem_pages(size * nr_possible_cpus); for_each_possible_cpu(i) {
/* __per_cpu_start对于每个CPU来讲是个定值,它和__per_cpu_end都是由链接器生成的
* 计算每个CPU的__per_cpu_start相对于真实存放percpu段线性地址 的偏移
* 请参考代码下方的示意图
* memcpy拷贝所有percpu变量至每个CPU自己的percpu段
*/
__per_cpu_offset[i] = ptr - __per_cpu_start;
memcpy(ptr, __per_cpu_start, __per_cpu_end - __per_cpu_start);
ptr += size;
}
}
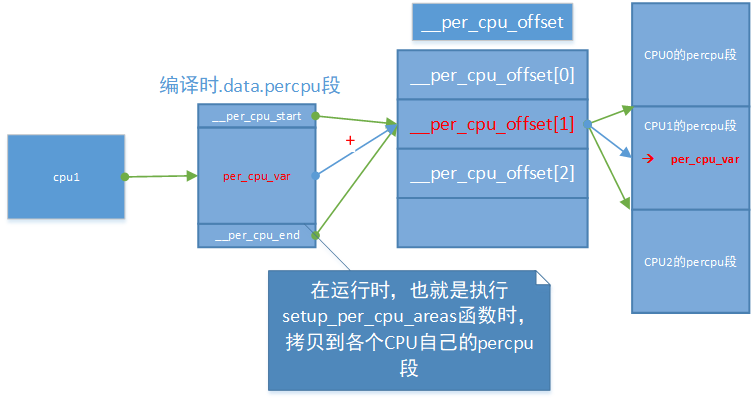
那么在编译期源程序如何访问percpu变量呢?内核定义了几个宏来实现对percpu变量的访问:
//smp_processor_id()可以返回当前活动处理器的ID,用作下面的cpu参数。
#define per_cpu(var, cpu) (*({ \
extern int simple_identifier_##var(void); \
RELOC_HIDE(&per_cpu__##var, __per_cpu_offset(cpu)); }))
这里我们举一个例子进行说明:假设访问per_cpu(var,1),由于percpu变量在定义时由DEFINE_PER_CPU展开成per_cpu_var,因此RELOC_HIDE的第一个参数就是编译时per_cpu_var的地址,第二个参数__per_cpu_offset(cpu)为前面setup_per_cpu_areas计算出来的,它表示运行时复制的percpu数据区首地址与编译期确定的首地址的差值,这两个值相加就是实际存储percpu变量的地址。示意图如下:
在更(geng)新的内核(2.6.32)中,percpu变量的定义(DEFINE_PER_CPU)和存取(per_cpu(var, cpu))方式没有发生改变,主要是__per_cpu_offset数组的初始化方式发生了改变,见arch\x86\kernel\setup_percpu.c中函数:setup_per_cpu_areas()。
同步与互斥_percpu变量的更多相关文章
- UNIX环境高级编程——线程同步之互斥锁、读写锁和条件变量(小结)
一.使用互斥锁 1.初始化互斥量 pthread_mutex_t mutex =PTHREAD_MUTEX_INITIALIZER;//静态初始化互斥量 int pthread_mutex_init( ...
- 【转载】同步和互斥的POSIX支持(互斥锁,条件变量,自旋锁)
上篇文章也蛮好,线程同步之条件变量与互斥锁的结合: http://www.cnblogs.com/charlesblc/p/6143397.html 现在有这篇文章: http://blog.cs ...
- 转载自~浮云比翼:Step by Step:Linux C多线程编程入门(基本API及多线程的同步与互斥)
Step by Step:Linux C多线程编程入门(基本API及多线程的同步与互斥) 介绍:什么是线程,线程的优点是什么 线程在Unix系统下,通常被称为轻量级的进程,线程虽然不是进程,但却可 ...
- Step by Step:Linux C多线程编程入门(基本API及多线程的同步与互斥)
介绍:什么是线程,线程的优点是什么 线程在Unix系统下,通常被称为轻量级的进程,线程虽然不是进程,但却可以看作是Unix进程的表亲,同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间, ...
- Linux驱动之同步、互斥、阻塞的应用
同步.互斥.阻塞的概念: 同步:在并发程序设计中,各进程对公共变量的访问必须加以制约,这种制约称为同步. 互斥机制:访问共享资源的代码区叫做临界区,这里的共享资源可能被多个线程需要,但这些共享资源又不 ...
- linux下的同步与互斥
linux下的同步与互斥 谈到linux的并发,必然涉及到线程之间的同步和互斥,linux主要为我们提供了几种实现线程间同步互斥的 机制,本文主要介绍互斥锁,条件变量和信号量.互斥锁和条件变量包含在p ...
- linux内核同步之每CPU变量、原子操作、内存屏障、自旋锁【转】
转自:http://blog.csdn.net/goodluckwhh/article/details/9005585 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 一每 ...
- 【Java并发基础】并发编程领域的三个问题:分工、同步和互斥
前言 可以将Java并发编程抽象为三个核心问题:分工.同步和互斥. 这三个问题的产生源自对性能的需求.最初时,为提高计算机的效率,当IO在等待时不让CPU空闲,于是就出现了分时操作系统也就出现了并发. ...
- 线程同步 - POSIX互斥锁
线程同步 - POSIX互斥锁 概括 本文讲解POSIX中互斥量的基本用法,从而能达到简单的线程同步.互斥量是一种特殊的变量,它有两种状态:锁定以及解锁.如果互斥量是锁定的,就有一个特定的线程持有或者 ...
随机推荐
- Spring Cloud Alibaba | Sentinel:分布式系统的流量防卫兵动态限流规则
Spring Cloud Alibaba | Sentinel:分布式系统的流量防卫兵动态限流规则 前面几篇文章较为详细的介绍了Sentinel的使用姿势,还没看过的小伙伴可以访问以下链接查看: &l ...
- spring boot 配置文件加密数据库用户名/密码
这篇文章为大家分享spring boot的配置文件properties文件里面使用经过加密的数据库用户名+密码,因为在自己做过的项目中,有这样的需求,尤其是一些大公司,或者说上市公司,是不会把这些敏感 ...
- xml文档的解析并通过工具类实现java实体类的映射:XML工具-XmlUtil
若有疑问,可以联系我本人微信:Y1141100952 声明:本文章为原稿,转载必须说明 本文章地址,否则一旦发现,必追究法律责任 1:本文章显示通过 XML工具-XmlUtil工具实现解析soap报文 ...
- 使用python合并excel
当工作碰到需要将几个excel合并时,比如一个表,收集每个人的个人信息,陆续收回来就是十几张甚至几十张表,少了还好解决,但是很多的话就不能一个一个去复制了,这时候就想到了python,Python大法 ...
- 疑难杂症----Windows10
现在大多数个人电脑所用的操作系统都是win10,而我们使用win10时总是会碰上各种各样的问题,所以专门写一篇博客来记录我碰上的各种问题,便于以后更快的解决问题. 一.小娜搜索不到应用问题解决方案 小 ...
- 三、SpringBoot 整合mybatis 多数据源以及分库分表
前言 说实话,这章本来不打算讲的,因为配置多数据源的网上有很多类似的教程.但是最近因为项目要用到分库分表,所以让我研究一下看怎么实现.我想着上一篇博客讲了多环境的配置,不同的环境调用不同的数据库,那接 ...
- .netCore+Vue 搭建的简捷开发框架 (2)--仓储层实现和EFCore 的使用
书接上文,继续搭建我们基于.netCore 的开发框架.首先是我们的项目分层结构. 这个分层结构,是参考张老师的分层结构,但是实际项目中,我没有去实现仓储模型.因为我使用的是EFCore ,最近也一直 ...
- 年年有余之java求余的技巧集合
背景 传说里玉皇大帝派龙王马上降雨到共光一带,龙王接到玉皇大帝命令,立马从海上调水,跑去共光施云布雨,但粗心又着急的龙王不小心把海里的鲸鱼随着雨水一起降落在了共光,龙王怕玉皇大帝责怪,灵机一动便声称他 ...
- 搭建数据库galera集群
galera集群 galera简介 galera集群又叫多主集群,用于数据库的同步,保证数据安全 最少3台,最好是奇数台数,当一台机器宕掉时,因为仲裁机制,这台机器就会被踢出集群. 通过wsrep协议 ...
- 基于vue实现搜索高亮关键字
有一个需求是在已有列表中搜索关键词,然后在列表中展示含有相关关键字的数据项并且对关键字进行高亮显示,所以该需求需要解决的就两个问题: 1.搜索关键词过滤列表数据 2.每个列表高亮关键字 ps: 此问题 ...