NLP中的数据增强
相关方法合集见:https://github.com/quincyliang/nlp-data-augmentation
较为简单的数据增强的方法见论文:https://arxiv.org/pdf/1901.11196.pdf
论文中所使用的方法如下:
1. 同义词替换(SR: Synonyms Replace):不考虑stopwords,在句子中随机抽取n个词,然后从同义词词典中随机抽取同义词,并进行替换。(同义词其词向量可能也更加接近,在使用词向量的模型中不一定有用)
2. 随机插入(RI: Randomly Insert):不考虑stopwords,随机抽取一个词,然后在该词的同义词集合中随机选择一个,插入原句子中的随机位置。该过程可以重复n次。
3. 随机交换(RS: Randomly Swap):句子中,随机选择两个词,位置交换。该过程可以重复n次。
4. 随机删除(RD: Randomly Delete):句子中的每个词,以概率p随机删除。(类似于神经网络中的dropout)
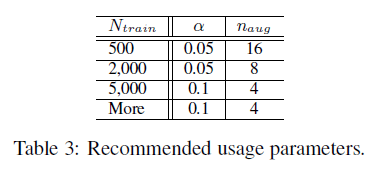
第一列是训练集的大小,第三列是每个句子生成的新句子数,第二列是每一条语料中改动的词所占的比例。
相关实现见:https://github.com/zhanlaoban/eda_nlp_for_Chinese
还有些如打乱句子的顺序,随机进行Mask,相比于直接复制能够加入一些噪声,以防止过拟合。
还有些通过神经网络进行数据增强的方法,但是代价相对较高,同时效果也不一定会好。
相关讨论见:https://www.zhihu.com/question/305256736?sort=created
不同的数据增强方式不能确切的说谁强谁弱,对于NLP任务而言,一切从数据出发,需要结合具体任务进行检验。
NLP中的数据增强的更多相关文章
- StartDT AI Lab | 数据增强技术如何实现场景落地与业务增值?
有人说,「深度学习“等于”深度卷积神经网络算法模型+大规模数据+云端分布式算力」.也有人说,「能够在业内叱咤风云的AI都曾“身经百战”,经历过无数次的训练与试错」.以上都需要海量数据做依托,对于那些数 ...
- YoloV4当中的Mosaic数据增强方法(附代码详细讲解)码农的后花园
上一期中讲解了图像分类和目标检测中的数据增强的区别和联系,这期讲解数据增强的进阶版- yolov4中的Mosaic数据增强方法以及CutMix. 前言 Yolov4的mosaic数据增强参考了CutM ...
- GAN︱GAN 在 NLP 中的尝试、困境、经验
GAN 自从被提出以来,就广受大家的关注,尤其是在计算机视觉领域引起了很大的反响,但是这么好的理论是否可以成功地被应用到自然语言处理(NLP)任务呢? Ian Goodfellow 博士 一年前,网友 ...
- TensorFlow之DNN(三):神经网络的正则化方法(Dropout、L2正则化、早停和数据增强)
这一篇博客整理用TensorFlow实现神经网络正则化的内容. 深层神经网络往往具有数十万乃至数百万的参数,可以进行非常复杂的特征变换,具有强大的学习能力,因此容易在训练集上过拟合.缓解神经网络的过拟 ...
- 中文NER的那些事儿4. 数据增强在NER的尝试
这一章我们不聊模型来聊聊数据,解决实际问题时90%的时间其实都是在和数据作斗争,于是无标注,弱标注,少标注,半标注对应的各类解决方案可谓是百花齐放.在第二章我们也尝试通过多目标对抗学习的方式引入额外的 ...
- 小样本利器4. 正则化+数据增强 Mixup Family代码实现
前三章我们陆续介绍了半监督和对抗训练的方案来提高模型在样本外的泛化能力,这一章我们介绍一种嵌入模型的数据增强方案.之前没太重视这种方案,实在是方法过于朴实...不过在最近用的几个数据集上mixup的表 ...
- pytorch识别CIFAR10:训练ResNet-34(数据增强,准确率提升到92.6%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前一篇中的ResNet-34残差网络,经过减小卷积核训练准确率提升到85%. 这里对训练数据集做数据 ...
- AI佳作解读系列(四)——数据增强篇
前言 在深度学习的应用过程中,数据的重要性不言而喻.继上篇介绍了数据合成(个人认为其在某种程度上可被看成一种数据增强方法)这个主题后,本篇聚焦于数据增强来介绍几篇杰作! (1)NanoNets : H ...
- 从0到1,了解NLP中的文本相似度
本文由云+社区发表 作者:netkiddy 导语 AI在2018年应该是互联网界最火的名词,没有之一.时间来到了9102年,也是项目相关,涉及到了一些AI写作相关的功能,为客户生成一些素材文章.但是, ...
随机推荐
- Redis和MongoDB区别
MongoDB 更类似 MySQL,支持字段索引.游标操作,其优势在于查询功能比较强大,擅长查询 JSON 数据,能存储海量数据,但是不支持事务.Redis 是一个开源(BSD许可)的,内存中的数据结 ...
- MySQL——my.cnf参数设置说明
以下为个人总结的MySQL配置文件参数说明,如有错误,烦请大佬们留言指正,本人将第一时间修改.2019-12-10 12:32:08 [mysqld] server- # Mysql唯一标识,一个集群 ...
- vue 脚手架
Vue 脚手架的基本用法 1. 基于 3.X 版本的脚手架 创建vue项目 命令行(CLI) 的方式创建 vue 项目 vue create my-project 图形化界面(GUI) 的方式创建 v ...
- GithubPages+Hexo博客搭建记录
目录 前言 安装Node.js 安装Git 安装Hexo 查看效果 建立Github Pages 注册Github帐户 建立托管博客的仓库 制作SSH密钥 添加公钥到Github 测试连接 把本地的博 ...
- 用Python代码写的计算器
1.极限压缩版 import re, functools def cal(formula): while re.search('(?:\d+\.?\d+|\d+)[+\-*/]', formula): ...
- Attention 和self-attention
1.Attention 最先出自于Bengio团队一篇论文:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE ...
- atom 在Ubuntu 18.04 上安装及基本使用
前记: Atom 是github专门为程序员推出的一个跨平台文本编辑器.具有简洁和直观的图形用户界面,并有很多有趣的特点:支持CSS,HTML,JavaScript等网页编程语言.它支持宏,自动完成分 ...
- LeetCode 652: 寻找重复的子树 Find Duplicate Subtrees
LeetCode 652: 寻找重复的子树 Find Duplicate Subtrees 题目: 给定一棵二叉树,返回所有重复的子树.对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可. 两 ...
- jQuery 源码解析(二十三) DOM操作模块 替换元素 详解
本节说一下DOM操作模块里的替换元素模块,该模块可将当前匹配的元素替换指定的DOM元素,有两个方法,如下: replaceWith(value) ;使用提供的新内容来替换匹配元素集合中的每个元 ...
- 谁说程序员不浪漫?Python导出微信聊天记录生成爱的词云图
明天又双叒叕是一年一度的七夕恋爱节了! 又是一波绝好的机会!恩爱秀起来! 购物车清空!礼物送起来!朋友圈晒起来! 等等! 什么?! 你还没准备好七夕礼物么? 但其实你不知道要送啥? 原来又双叒叕要 ...