高性能MySQL之事物
背景
当你手中抓住一件东西不放时,你只能拥有一件东西,如果你肯放手,你就有机会选择更多。与其在别人的生活里跑龙套,不如精彩做自己。人无所舍,必无所成。跌倒了,失去了,不要紧,爬起来继续风雨兼程,且歌且行。

一、概念
事务到底是什么东西呢?想必大家学习的时候也是对事务的概念很模糊的。接下来通过一个经典例子讲解事务。
银行在两个账户之间转账,从A账户转入B账户1000元,系统先减少A账户的1000元,然后再为B账号增加1000元。如果全部执行成功,数据库处于一致性;如果仅执行完A账户金额的修改,而没有增加B账户的金额,则数据库就处于不一致状态,这时就需要取消前面的操作。这过程中会有一系列的操作,比如余额查询,余额做加减法,更新余额等,这些操作必须保证是一个整体执行,要么全部成功,要么全部失败,不能让A账户钱扣了,但是中途某些操作失败了,导致B账户更新余额失败。这样用户就不乐意了,银行这不是坑我吗?因此简单来说,事务就是要保证一组数据库操作,要么全部成功,要么全部失败。在MySQL中,事务支持是在引擎层实现的。你现在知道,MySQL是一个支持多引擎的系统,但并不是所有的引擎都支持事务。比如MySQL原生的MyISAM引擎就不支持事务,这也是MyISAM被InnoDB取代的重要原因之一。
接下来会以InnoDB为例,抽丝剥茧MySQL在事务支持方面的特定实现。
二、隔离性与隔离级别
提到事务,你肯定会想到ACID(Atomicity、Consistency、Isolation、Durability,即原子性、一致性、隔离性、持久性),接下来我们就要讲解其中的I,也就是“隔离性”。
当数据库上存在多个事务同时执行的时候,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题,为了解决这些问题,就有了“隔离级别”的概念。
我们知道,隔离界别越高,效率就越低,因此我们很多情况下需要在二者之间找到一个平衡点。SQL标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )。下面我逐一为你解释:
读未提交:事务中的修改,即使没有提交,对其他事务也都是可见的,事务可以读取未提交的数据,也被称为脏读(Dirty Read)。这个级别会导致很多问题,从性能上来说也不会比其他隔离级别好很多,但却缺乏其他级别的很多好处,一般实际应用中很少用,甚至有些数据库内部根本就没有实现。
读已提交:事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的,这个级别有时候也叫做不可重复读(Nonrepeatable Read),因为同一事务中两次执行同样的查询,可能会得到不一样的结果
可重复度:同个事务中多次查询结果是一致的,解决了不可重复读的问题。此隔离级别下还是无法解决另外一个幻读(Phantom Read)的问题,幻读是指当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,之前的事务再次读取该范围的记录时,会产生幻行
串行化:顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
对于上面的概念中,可能 读已提交 和可重复读比较难理解,下面会用一个例子说明这种集中隔离级别。假设数据表T中只有一列,其中一行的值为1,下面是按照时间顺序执行两个事务的行为。
mysql> create table T(c int) engine=InnoDB;
insert into T(c) values();

接下来讲解不同的隔离级别下,事务A会有哪些不同的返回结果,也就是图里面V1、V2、V3的返回值分别是什么。
1.若隔离级别是“读未提交”, 则V1的值就是2。这时候事务B虽然还没有提交,但是结果已经被A看到了。因此,V2、V3也都是2。
2.若隔离级别是“读提交”,则V1是1,V2的值是2。事务B的更新在提交后才能被A看到。所以, V3的值也是2。
3.若隔离级别是“可重复读”,则V1、V2是1,V3是2。之所以V2还是1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
4.若隔离级别是“串行化”,则在事务B执行“将1改成2”的时候,会被锁住。直到事务A提交后,事务B才可以继续执行。所以从A的角度看, V1、V2值是1,V3的值是2。
在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。在“读提交”隔离级别下,这个视图是在每个SQL语句开始执行的时候创建的。这里需要注意的是,“读未提交”隔离级别下直接返回记录上的最新值,没有视图概念;而“串行化”隔离级别下直接用加锁的方式来避免并行访问。
注意一下,每种数据库的行为会有所不一样,Oracle数据库的默认隔离界别是“读提交”,因此,当我们需要进行不同数据库种类之间迁移的时候,为了保证数据库隔离级别的一致,切记将MYSQL的隔离级别涉及为 “读提交”。配置的方式是,将启动参数transaction-isolation的值设置成READ-COMMITTED。你可以用show variables来查看当前的值。

每种隔离级别都有它自己的使用场景,你要根据自己的业务情况来定。我想你可能会问那什么时候需要“可重复读”的场景呢?我们来看一个数据校对逻辑的案例。
假设你在管理一个个人银行账户表。一个表存了每个月月底的余额,一个表存了账单明细。这时候你要做数据校对,也就是判断上个月的余额和当前余额的差额,是否与本月的账单明细一致。你一定希望在校对过程中,即使有用户发生了一笔新的交易,也不影响你的校对结果。
这时候使用“可重复读”隔离级别就很方便。事务启动时的视图可以认为是静态的,不受其他事务更新的影响。
三、事务隔离的实现
接下来以可重复度来展开事务隔离具体是怎么实现的。
在MySQL中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。
假设一个值从1被按顺序改成了2、3、4,在回滚日志里面就会有类似下面的记录。
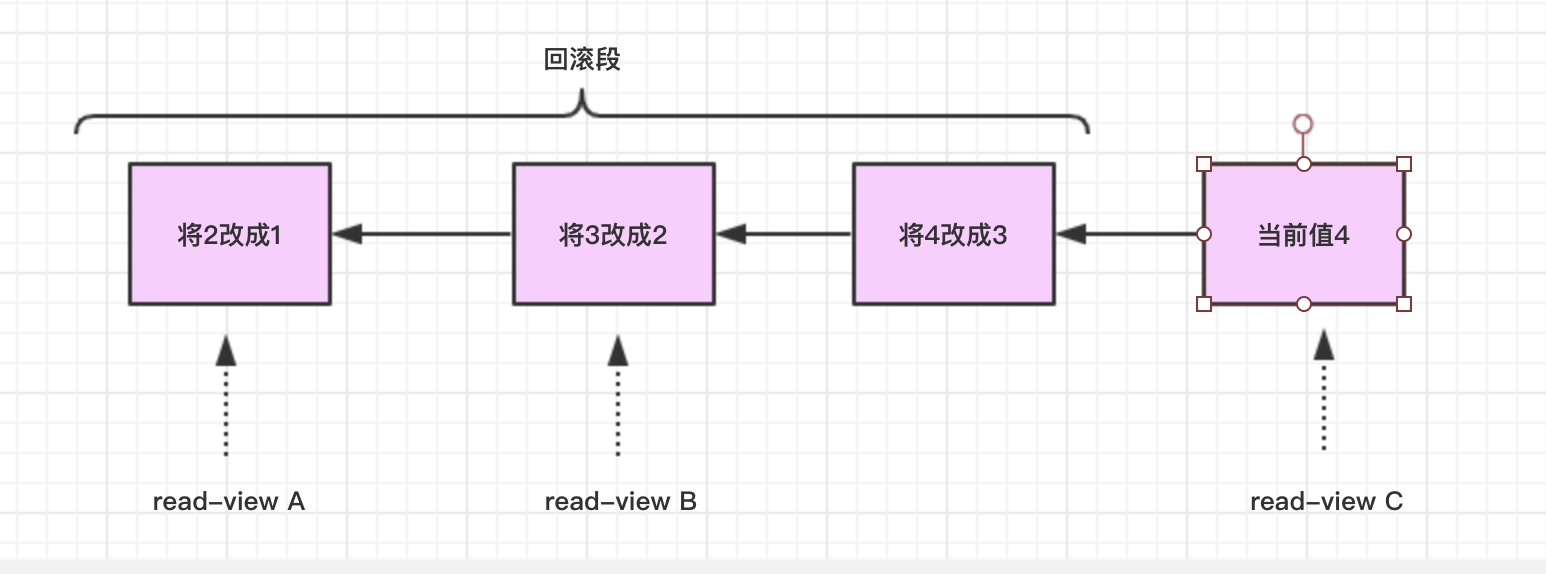
可以看到当前值是4,从图中可以看到在查询的时候,不同时刻启动的事务会有不同的read-view。如图中看到的,在视图A、B、C里面,这一个记录的值分别是1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于read-view A,要得到1,就必须将当前值依次执行图中所有的回滚操作得到。同时你会发现,即使现在有另外一个事务正在将4改成5,这个事务跟read-view A、B、C对应的事务是不会冲突的。
你一定会问,回滚日志总不能一直保留吧,什么时候删除呢?
这是肯定不能一直保留的,在不需要的时候才删除。系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除。
那么什么时候才不需要了呢?就是当系统里没有比这个回滚日志更早的read-view的时候。
基于上面的说明,我们来讨论一下为什么建议你尽量不要使用长事务。
长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间。
在MySQL 5.5及以前的版本,回滚日志是跟数据字典一起放在ibdata文件里的,即使长事务最终提交,回滚段被清理,文件也不会变小。我见过数据只有20GB,而回滚段有200GB的库。最终只好为了清理回滚段,重建整个库。
除了对回滚段的影响,长事务还占用锁资源,也可能拖垮整个库,这个我们会在后面讲锁的时候展开。
四、事务启动方式
MySQL的事务启动方式有以下几种:
显式启动事务语句, begin 或 start transaction。配套的提交语句是commit,回滚语句是rollback。
set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个select语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行commit 或 rollback 语句,或者断开连接。
有些客户端连接框架会默认连接成功后先执行一个set autocommit=0的命令。这就导致接下来的查询都在事务中,如果是长连接,就导致了意外的长事务。
因此,我会建议你总是使用set autocommit=1, 通过显式语句的方式来启动事务。
但是有的开发同学会纠结“多一次交互”的问题。对于一个需要频繁使用事务的业务,第二种方式每个事务在开始时都不需要主动执行一次 “begin”,减少了语句的交互次数。如果你也有这个顾虑,我建议你使用commit work and chain语法。
在autocommit为1的情况下,用begin显式启动的事务,如果执行commit则提交事务。如果执行 commit work and chain,则是提交事务并自动启动下一个事务,这样也省去了再次执行begin语句的开销。同时带来的好处是从程序开发的角度明确地知道每个语句是否处于事务中。
你可以在information_schema库的innodb_trx这个表中查询长事务,比如下面这个语句,用于查找持续时间超过60s的事务。
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>
五、MVCC工作原理
可重复读隔离级别下,事务在启动的时候就“拍了个快照”。请注意,这个快照是基于整个库的,这时候你肯定觉得不可思议,如果一个库上百G的数据,那么我启动一个事务,那MYSQL岂不是要将上百G的数据拷贝出来,这个过程不是非常慢吗?但是为什么我们平时并没有感觉到它
高性能MySQL之事物的更多相关文章
- 高性能mysql的事物隔离级别
数据库事务的隔离级别有4种,由低到高分别为Read uncommitted .Read committed .Repeatable read .Serializable .而且,在事务的并发操作中可能 ...
- 1121高性能MySQL之运行机制
本文来自于拜读<高性能MySQL(第三版)>时的读书笔记作者:安明哲转载时请注明部分内容来自<高性能MySQL(第三版)> MySQL的逻辑构架 MySQL服务器逻辑架构 最上 ...
- 《高性能MySQL》读书笔记--锁、事务、隔离级别 转
1.锁 为什么需要锁?因为数据库要解决并发控制问题.在同一时刻,可能会有多个客户端对表中同一行记录进行操作,比如有的在读取该行数据,其他的尝试去删除它.为了保证数据的一致性,数据库就要对这种并发操作进 ...
- 高性能Mysql主从架构的复制原理及配置详解
温习<高性能MySQL>的复制篇. 1 复制概述 Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台 ...
- 高性能MySQL --- 读书笔记(1) - 2016/8/2
此书不但帮助MySQL初学者提高使用技巧,更为有经验的MySQL DBA指出了开发高性能MySQL应用的途径.全书包括14章,内容覆盖MySQL系统架构.设计应用技巧.SQL语句优化.服务器性能调优. ...
- 《高性能MySQL》
<高性能MySQL>(第3版)讲解MySQL如何工作,为什么如此工作? MySQL系统架构.设计应用技巧.SQL语句优化.服务器性能调优.系统配置管理和安全设置.监控分析,以及复制.扩展和 ...
- 转:高性能Mysql主从架构的复制原理及配置详解
温习<高性能MySQL>的复制篇. 1 复制概述 Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台 ...
- 高性能MySql进化论【转】
高性能MySql进化论(十二):Mysql中分区表的使用总结 http://binary.duapp.com/category/sql 当数据量非常大时(表的容量到达GB或者是TB),如果仍然采用索引 ...
- 高性能Mysql主从架构的复制原理及配置详解(转)
温习<高性能MySQL>的复制篇. 1 复制概述 Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台 ...
随机推荐
- WebLogic 任意文件上传远程代码执行_CVE-2018-2894漏洞复现
WebLogic 任意文件上传远程代码执行_CVE-2018-2894漏洞复现 一.漏洞描述 Weblogic管理端未授权的两个页面存在任意上传getshell漏洞,可直接获取权限.Oracle 7月 ...
- C++学习书籍推荐《C++ Concurrency in Action》下载
百度云及其他网盘下载地址:点我 目录 Hello, world of concurrency in C++! Managing threads Sharing data between threads ...
- 奇袭(单调栈+分治+桶排)(20190716 NOIP模拟测试4)
C. 奇袭 题目类型:传统 评测方式:文本比较 内存限制:256 MiB 时间限制:1000 ms 标准输入输出 题目描述 由于各种原因,桐人现在被困在Under World(以下简称UW)中,而 ...
- [转载] 管Q某犇借的手写堆
跟gxy大神还有yzh大神学了学手写的堆,应该比stl的优先队列快很多. 其实就是维护了一个二叉堆,写进结构体里,就没啥了... 据说达哥去年NOIP靠这个暴力多骗了分 合并果子... templat ...
- 9.22考试 crf的视察 题解
这道题当时第一反应就是一道典型的NOIP第一题的难度,绝对要A掉,不然分数一定会被拉开. 然后就开始分析,暴力是一开始想的是用二维树状数组打加上暴力枚举长度,然而这道题满足二分性质,所以时间复杂度就是 ...
- [USACO09OCT]Invasion of the Milkweed】乳草的侵占-C++
Farmer John一直努力让他的草地充满鲜美多汁的而又健康的牧草.可惜天不从人愿,他在植物大战人类中败下阵来.邪恶的乳草已经在他的农场的西北部份占领了一片立足之地. 草地像往常一样,被分割成一个高 ...
- dbo是默认用户也是架构
dbo是默认用户也是架构 dbo作为架构是为了更好的与2000兼容, 在2000中DataBaseName.dbo.TableName解释为:数据库名.用户名.表名, 在2005中DataBaseNa ...
- 关于使用 AJax 生成Form表单,且表单提交需要验证,验证实效的解决方法
@Ajax.ActionLink("添加", "AddUser",new AjaxOptions() {InsertionMode = InsertionMod ...
- vs2010 安装项目完成桌面快捷方式无法定位程序文件夹 解决方法
本文转载自http://www.cnblogs.com/jasonxuvip/archive/2012/07/13/2589952.html 软件打包工具有很多种,让人不知道选那个方便自己使用,Tig ...
- [剑指offer] 1. 二维数组中的的查找
题目描述 在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数 ...