Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: Eastmount
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
我们在编写Python爬虫时,有时会遇到网站拒绝访问等反爬手段,比如这么我们想爬取蚂蚁短租数据,它则会提示“当前访问疑似黑客攻击,已被网站管理员设置为拦截”提示,如下图所示。此时我们需要采用设置Cookie来进行爬取,下面我们进行详细介绍。非常感谢我的学生承峰提供的思想,后浪推前浪啊!
一. 网站分析与爬虫拦截
当我们打开蚂蚁短租搜索贵阳市,反馈如下图所示结果。 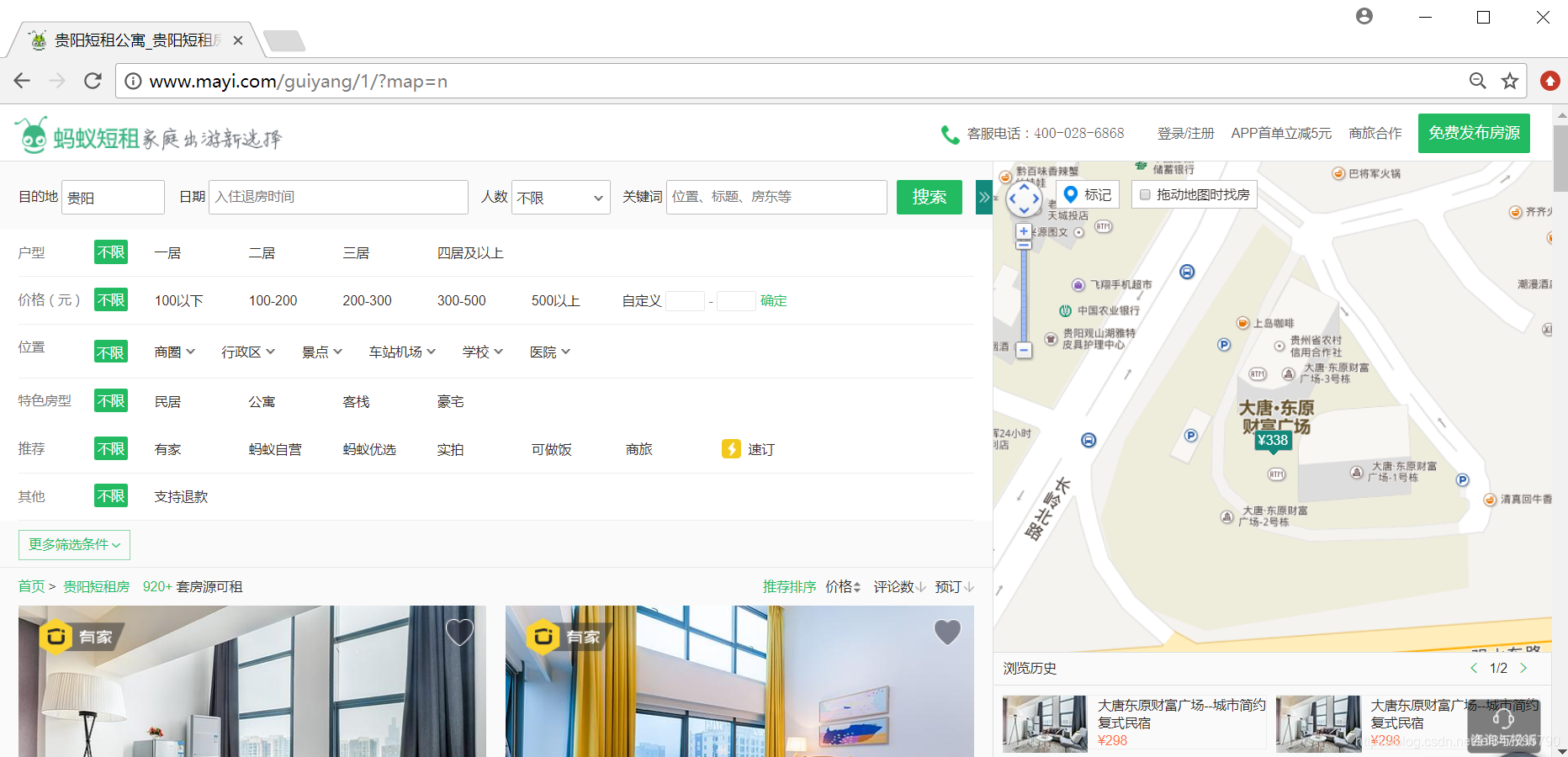 我们可以看到短租房信息呈现一定规律分布,如下图所示,这也是我们要爬取的信息。
我们可以看到短租房信息呈现一定规律分布,如下图所示,这也是我们要爬取的信息。 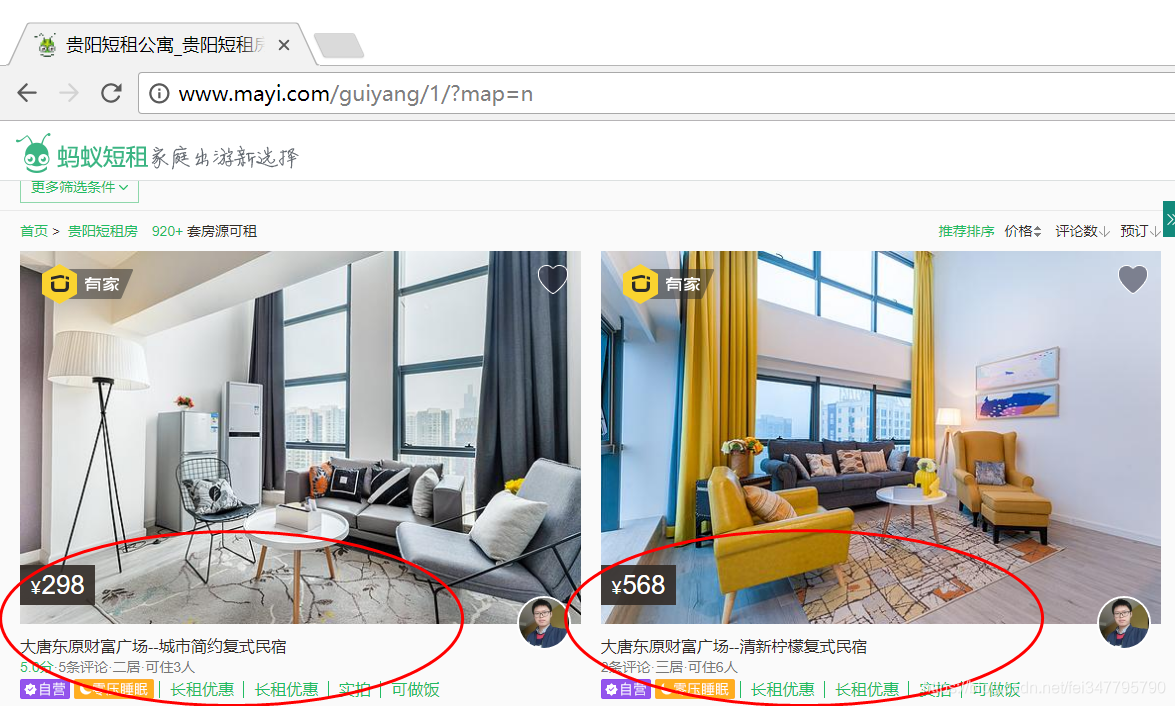
通过浏览器审查元素,我们可以看到需要爬取每条租房信息都位于<dd></dd>节点下。 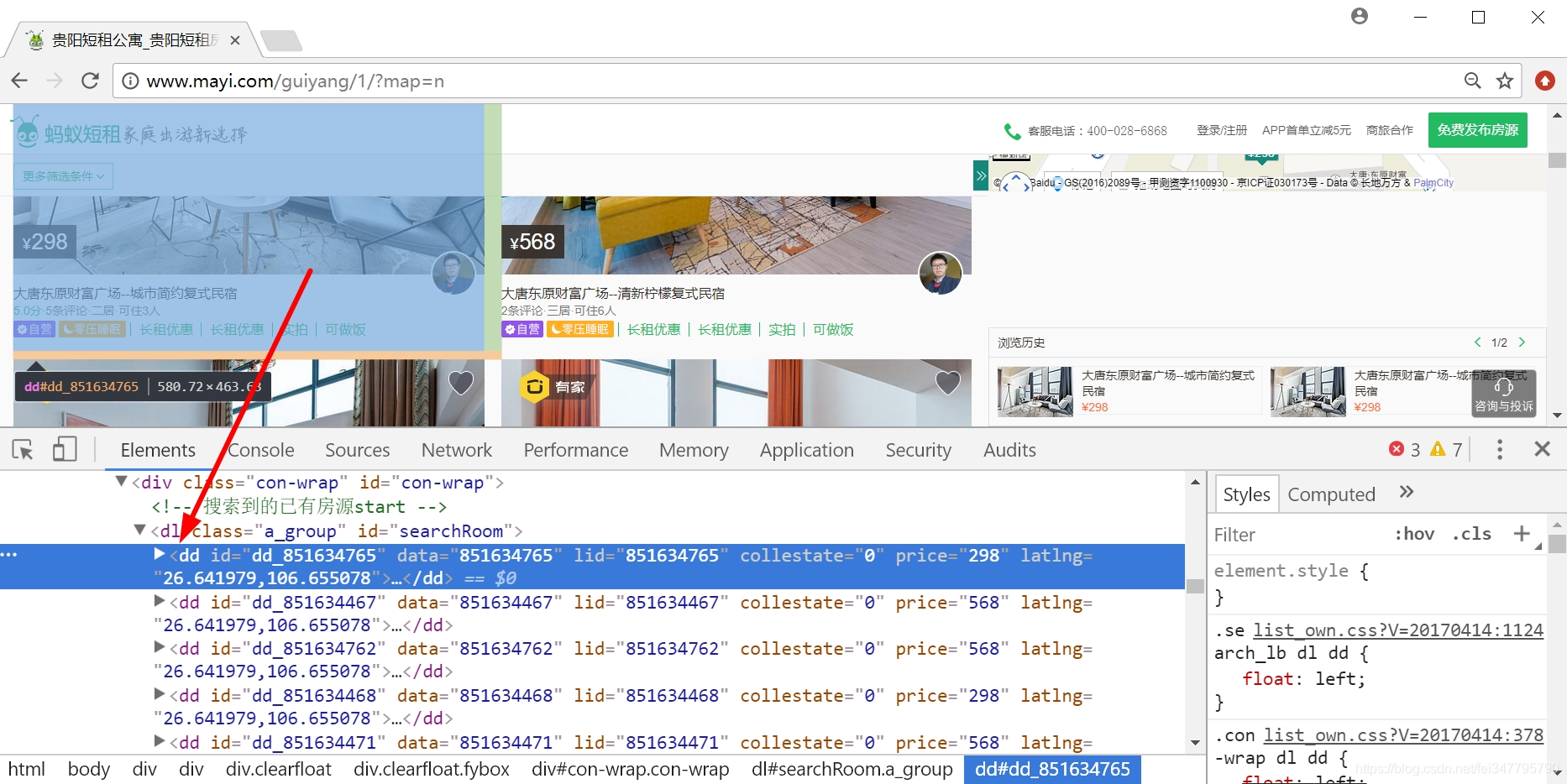 在定位房屋名称,如下图所示,位于<div class="room-detail clearfloat"></div>节点下。
在定位房屋名称,如下图所示,位于<div class="room-detail clearfloat"></div>节点下。 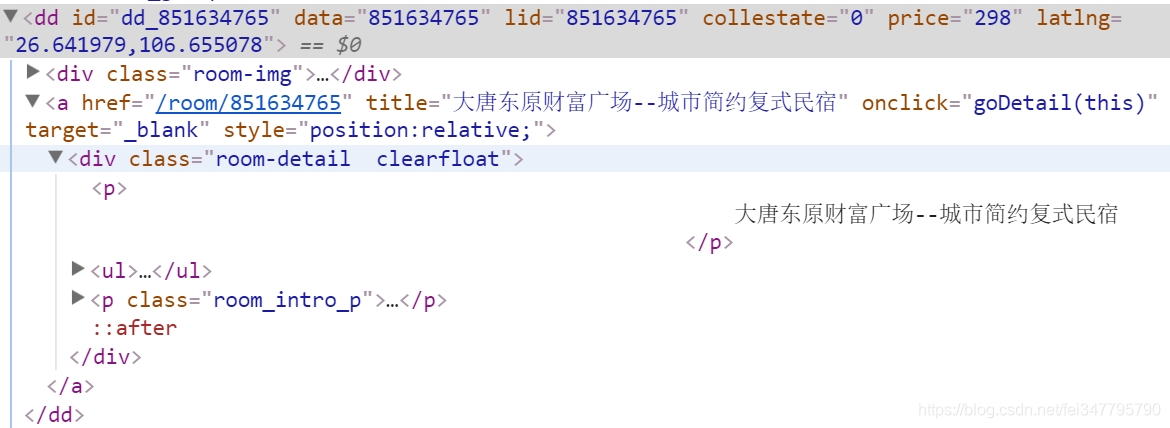
接下来我们写个简单的BeautifulSoup进行爬取。
# -*- coding: utf-8 -*-
import urllib
import re
from bs4 import BeautifulSoup
import codecs url = 'http://www.mayi.com/guiyang/?map=no'
response=urllib.urlopen(url)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
print soup.title
print soup
#短租房名称
for tag in soup.find_all('dd'):
for name in tag.find_all(attrs={"class":"room-detail clearfloat"}):
fname = name.find('p').get_text()
print u'[短租房名称]', fname.replace('\n','').strip()
但很遗憾,报错了,说明蚂蚁金服防范措施还是挺到位的。 
二. 设置Cookie的BeautifulSoup爬虫
添加消息头的代码如下所示,这里先给出代码和结果,再教大家如何获取Cookie。
# -*- coding: utf-8 -*-
import urllib2
import re
from bs4 import BeautifulSoup #爬虫函数
def gydzf(url):
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
headers={"User-Agent":user_agent}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
for tag in soup.find_all('dd'):
#短租房名称
for name in tag.find_all(attrs={"class":"room-detail clearfloat"}):
fname = name.find('p').get_text()
print u'[短租房名称]', fname.replace('\n','').strip()
#短租房价格
for price in tag.find_all(attrs={"class":"moy-b"}):
string = price.find('p').get_text()
fprice = re.sub("[¥]+".decode("utf8"), "".decode("utf8"),string)
fprice = fprice[0:5]
print u'[短租房价格]', fprice.replace('\n','').strip()
#评分及评论人数
for score in name.find('ul'):
fscore = name.find('ul').get_text()
print u'[短租房评分/评论/居住人数]', fscore.replace('\n','').strip()
#网页链接url
url_dzf = tag.find(attrs={"target":"_blank"})
urls = url_dzf.attrs['href']
print u'[网页链接]', urls.replace('\n','').strip()
urlss = 'http://www.mayi.com' + urls + ''
print urlss #主函数
if __name__ == '__main__':
i = 1
while i<10:
print u'页码', i
url = 'http://www.mayi.com/guiyang/' + str(i) + '/?map=no'
gydzf(url)
i = i+1
else:
print u"结束"
输出结果如下图所示:
页码 1
[短租房名称] 大唐东原财富广场--城市简约复式民宿
[短租房价格] 298
[短租房评分/评论/居住人数] 5.0分·5条评论·二居·可住3人
[网页链接] /room/851634765
http://www.mayi.com/room/851634765
[短租房名称] 大唐东原财富广场--清新柠檬复式民宿
[短租房价格] 568
[短租房评分/评论/居住人数] 2条评论·三居·可住6人
[网页链接] /room/851634467
http://www.mayi.com/room/851634467 ... 页码 9
[短租房名称] 【高铁北站公园旁】美式风情+超大舒适安逸
[短租房价格] 366
[短租房评分/评论/居住人数] 3条评论·二居·可住5人
[网页链接] /room/851018852
http://www.mayi.com/room/851018852
[短租房名称] 大营坡(中大国际购物中心附近)北欧小清新三室
[短租房价格] 298
[短租房评分/评论/居住人数] 三居·可住6人
[网页链接] /room/851647045
http://www.mayi.com/room/851647045

接下来我们想获取详细信息 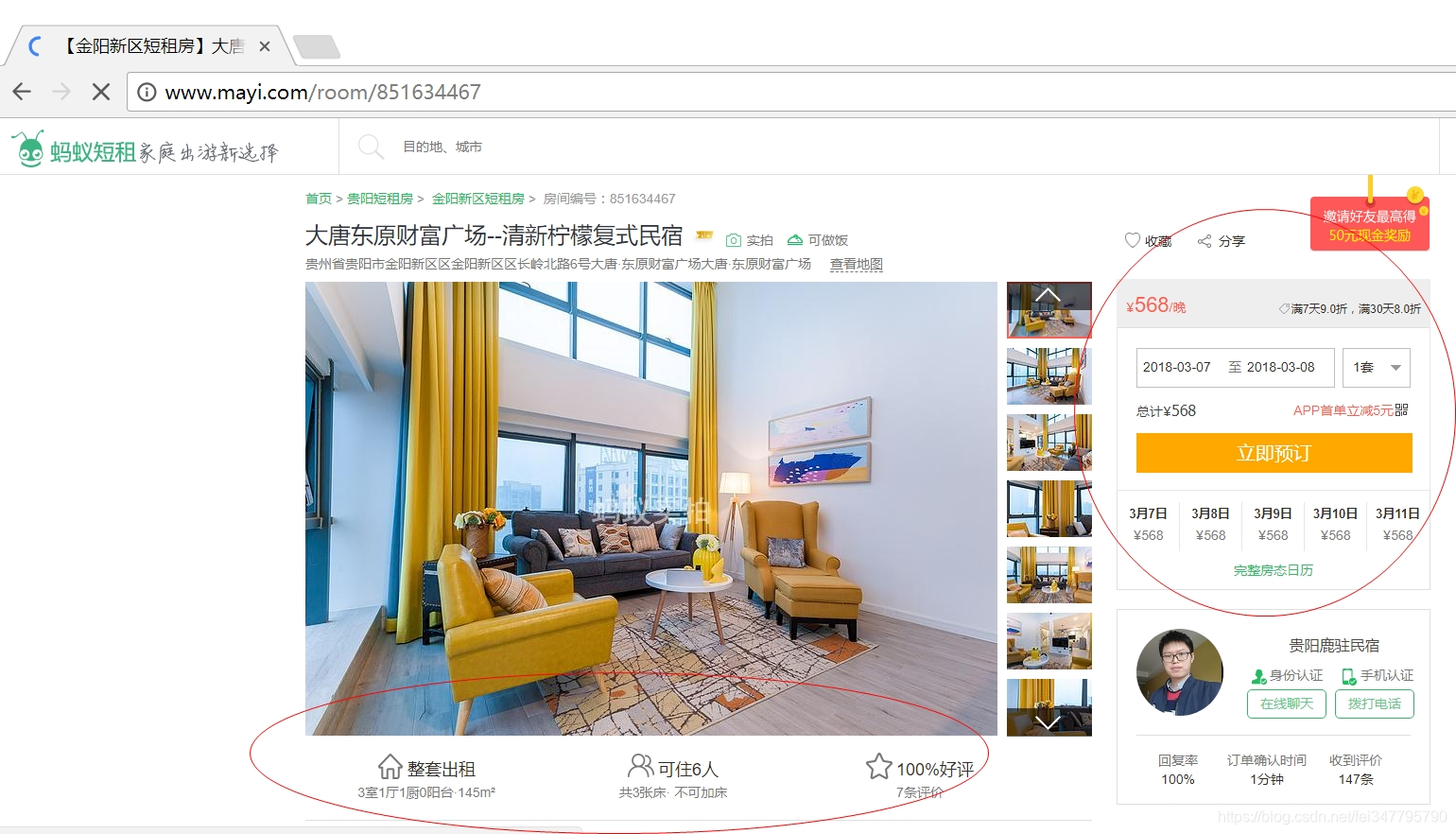
这里作者主要是提供分析Cookie的方法,使用浏览器打开网页,右键“检查”,然后再刷新网页。在“NetWork”中找到网页并点击,在弹出来的Headers中就隐藏这这些信息。 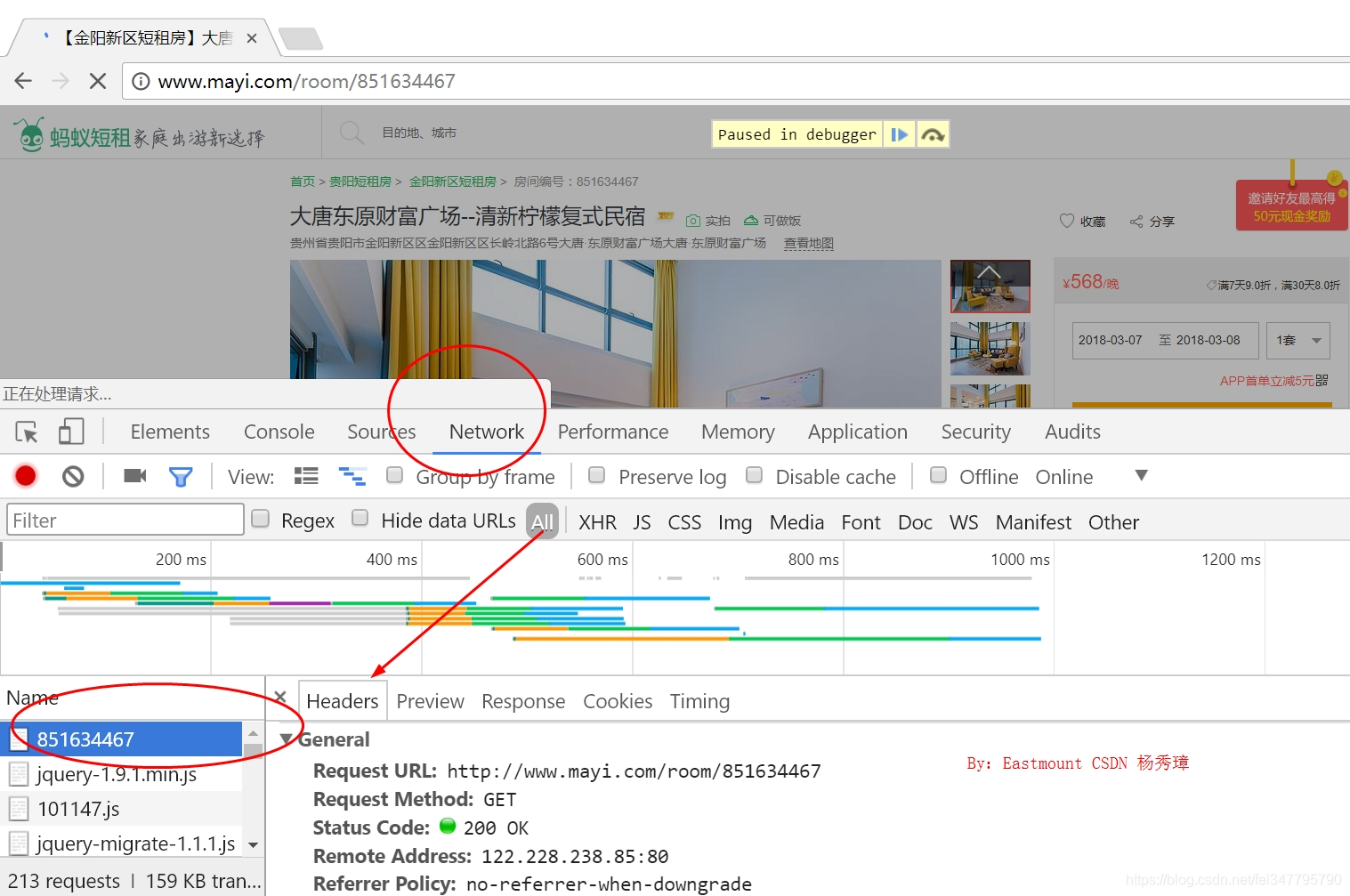
最常见的两个参数是Cookie和User-Agent,如下图所示:
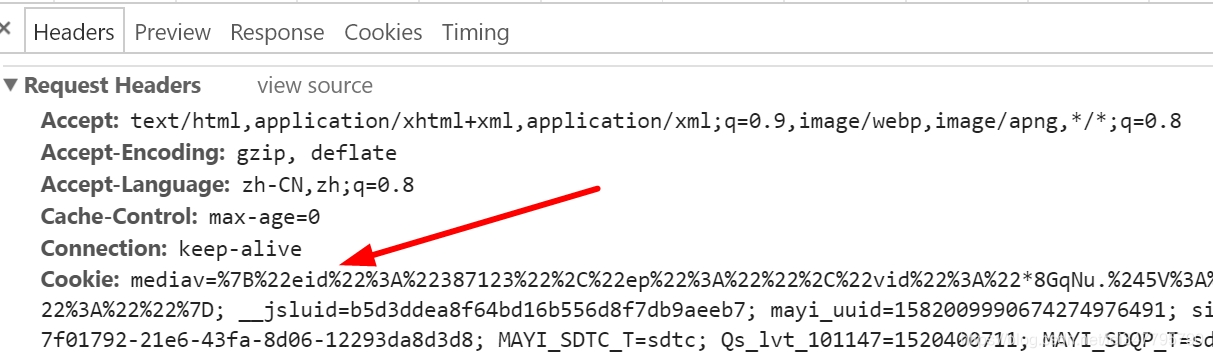
然后在Python代码中设置这些参数,再调用Urllib2.Request()提交请求即可,核心代码如下:
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) ... Chrome/61.0.3163.100 Safari/537.36"
cookie="mediav=%7B%22eid%22%3A%22387123...b3574ef2-21b9-11e8-b39c-1bc4029c43b8"
headers={"User-Agent":user_agent,"Cookie":cookie}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
for tag1 in soup.find_all(attrs={"class":"main"}):
注意,每小时Cookie会更新一次,我们需要手动修改Cookie值即可,就是上面代码的cookie变量和user_agent变量。完整代码如下所示:
import urllib2
import re
from bs4 import BeautifulSoup
import codecs
import csv c = open("ycf.csv","wb") #write 写
c.write(codecs.BOM_UTF8)
writer = csv.writer(c)
writer.writerow(["短租房名称","地址","价格","评分","可住人数","人均价格"]) #爬取详细信息
def getInfo(url,fname,fprice,fscore,users):
#通过浏览器开发者模式查看访问使用的user_agent及cookie设置访问头(headers)避免反爬虫,且每隔一段时间运行要根据开发者中的cookie更改代码中的cookie
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
cookie="mediav=%7B%22eid%22%3A%22387123%22eb7; mayi_uuid=1582009990674274976491; sid=42200298656434922.85.130.130"
headers={"User-Agent":user_agent,"Cookie":cookie}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
#短租房地址
for tag1 in soup.find_all(attrs={"class":"main"}):
print u'短租房地址:'
for tag2 in tag1.find_all(attrs={"class":"desWord"}):
address = tag2.find('p').get_text()
print address
#可住人数
print u'可住人数:'
for tag4 in tag1.find_all(attrs={"class":"w258"}):
yy = tag4.find('span').get_text()
print yy
fname = fname.encode("utf-8")
address = address.encode("utf-8")
fprice = fprice.encode("utf-8")
fscore = fscore.encode("utf-8")
fpeople = yy[2:3].encode("utf-8")
ones = int(float(fprice))/int(float(fpeople))
#存储至本地
writer.writerow([fname,address,fprice,fscore,fpeople,ones]) #爬虫函数
def gydzf(url):
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
headers={"User-Agent":user_agent}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, "html.parser")
for tag in soup.find_all('dd'):
#短租房名称
for name in tag.find_all(attrs={"class":"room-detail clearfloat"}):
fname = name.find('p').get_text()
print u'[短租房名称]', fname.replace('\n','').strip()
#短租房价格
for price in tag.find_all(attrs={"class":"moy-b"}):
string = price.find('p').get_text()
fprice = re.sub("[¥]+".decode("utf8"), "".decode("utf8"),string)
fprice = fprice[0:5]
print u'[短租房价格]', fprice.replace('\n','').strip()
#评分及评论人数
for score in name.find('ul'):
fscore = name.find('ul').get_text()
print u'[短租房评分/评论/居住人数]', fscore.replace('\n','').strip()
#网页链接url
url_dzf = tag.find(attrs={"target":"_blank"})
urls = url_dzf.attrs['href']
print u'[网页链接]', urls.replace('\n','').strip()
urlss = 'http://www.mayi.com' + urls + ''
print urlss
getInfo(urlss,fname,fprice,fscore,user_agent) #主函数
if __name__ == '__main__':
i = 0
while i<33:
print u'页码', (i+1)
if(i==0):
url = 'http://www.mayi.com/guiyang/?map=no'
if(i>0):
num = i+2 #除了第一页是空的,第二页开始按2顺序递增
url = 'http://www.mayi.com/guiyang/' + str(num) + '/?map=no'
gydzf(url)
i=i+1 c.close()
输出结果如下,存储本地CSV文件:
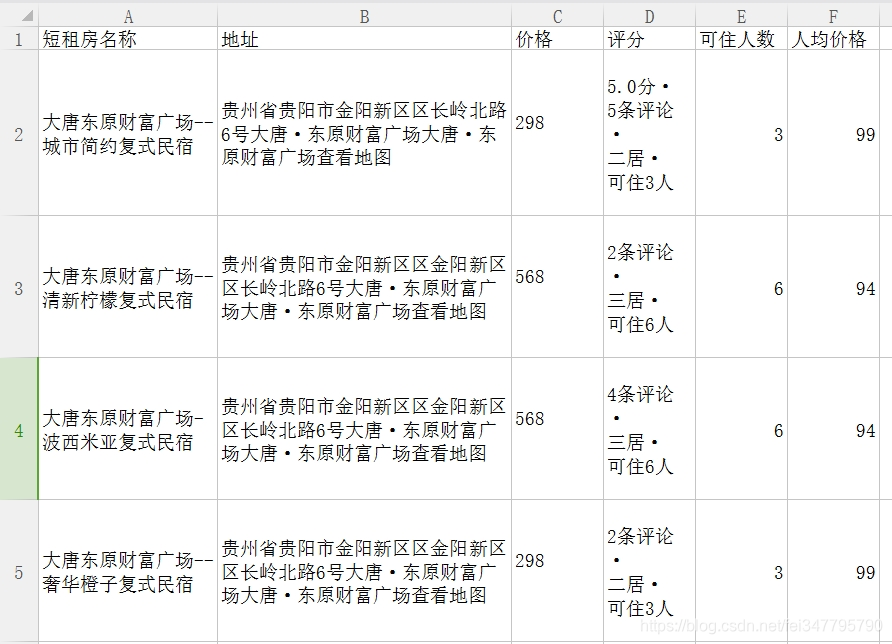
同时,大家可以尝试Selenium爬取蚂蚁短租,应该也是可行的方法。最后希望文章对您有所帮助,如果存在不足之处,请海涵~
Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租的更多相关文章
- python爬虫11 | 这次,将带你爬取b站上的NBA形象大使蔡徐坤和他的球友们
在上一篇中 python爬虫10 | 网站维护人员:真的求求你们了,不要再来爬取了!! 小帅b给大家透露了我们这篇要说的牛逼利器 selenium + phantomjs 如果你看了 python爬虫 ...
- Python爬虫入门教程:豆瓣Top电影爬取
基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一. ...
- python爬虫实战(六)--------新浪微博(爬取微博帐号所发内容,不爬取历史内容)
相关代码已经修改调试成功----2017-4-13 详情代码请移步我的github:https://github.com/pujinxiao/sina_spider 一.说明 1.目标网址:新浪微博 ...
- python爬虫中文乱码问题(request方式爬取)
https://blog.csdn.net/guoxinian/article/details/83047746 req = requests.get(url)返回的是类对象 其包括的属性有: r ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
- Python爬虫与一汽项目【二】爬取中国东方电气集中采购平台
网站地址:https://srm.dongfang.com/bid_detail.screen 东方电气采购的页面看似很友好,实际上并不好爬取 在观察网页的审查元素之后发现,1处的网页响应只是单纯的一 ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
随机推荐
- python-16-初识函数
前言 以前写的python代码都是像记流水账一样,那么函数时什么额?它可以在任何需要它的地方进行调用,函数分为: 内置函数,print(),len() 自定义函数 一.自定义函数 1.我们都知道内置函 ...
- 使用DEV C++调试代码
0.序言 本片博客旨在记录通过DEV C++工具调试C/C++代码,在这之前需要对以下知识了解或掌握. C/C++代码的完整编译过程,可参考文章 GCC,gcc,g++,gdb的区别和联系,可参考文章 ...
- 压测 swoole_websocket_server 性能
概述 这是关于 Swoole 入门学习的第十篇文章:压测 swoole_websocket_server 性能. 第九篇:Swoole Redis 连接池的实现 第八篇:Swoole MySQL 连接 ...
- PlayJava Day012
今日所学: /* 2019.08.19开始学习,此为补档. */ JPanel和JFrame 1.JFrame是最底层,JPanel是置于其面上,同一个界面只有一个JFrame,一个JFrame可以放 ...
- JavaWeb问题记录——SessionIdGeneratorBase.createSecureRandom
JavaWeb问题记录——SessionIdGeneratorBase.createSecureRandom 摘要:本文主要记录了在启动Tomcat时,出现的一个警告以及解决办法. 部分内容来自以下博 ...
- C#中在多个地方调用同一个触发器从而触发同一个自定义委托的事件
场景 在Winfom中可以在页面上多个按钮或者右键的点击事件中触发同一个自定义的委托事件. 实现 在位置一按钮点击事件中触发 string parentPath = System.IO.Directo ...
- php 7.1.32 +Apache 2.4 配置 (x64)
最近phpstudy 后门事件一出,吓得小编瑟瑟发抖,决心自己配置环境不再用集成环境. 一.apache 配置 首先我们先去apache 官网下载apache apache2.4地址:https:// ...
- [转载] Java 遍历 Map 的 5 种方式
目录 1 通过 keySet() 或 values() 方法遍历 2 通过 keySet 的 get(key) 获取值 3 通过 entrySet 遍历 4 通过迭代器 Iterator 遍历 5 通 ...
- python类属性 静态方法
实例 实例就是由对象创建出来的实实在在的存在 创建出来的对象叫做类的实例 创建对象的动作叫做实例化 对象的属性叫做实例的属性 对象调用的方法叫做实例方法 类是一个特殊的对象 类属性 类属性 ...
- day88_11_8,事务的隔离级别celery定时订单与项目整合。
一.事务的隔离级别. mysql的默认数据库级别是可重复读,一般的应用使用的是读已提交 http://www.zsythink.net/archives/1233/ 1. Read UnCommitt ...