sklearn 第二篇:数据预处理
sklearn.preprocessing包提供了几个常用的转换函数,用于把原始特征向量转换为更适合估计器的表示。
转化器(Transformer)用于对数据的处理,例如标准化、降维以及特征选择等,提供的函数大致是:
- fit(x,y):该方法接受输入和标签,计算出数据变换的方式。
- transform(x):根据已经计算出的变换方式,返回对输入数据x变换后的结果(不改变x)
- fit_transform(x,y) :该方法在计算出数据变换方式之后对输入x就地转换。
在转化器中,fit_transform()函数等价于先执行fit()函数,后执行transform()函数。有如下的数据,使用preprocessing包对数据进行标准化和归一化处理:
from sklearn import preprocessing
import numpy as np X_train = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
一,数据标准化
数据标准化是指对数据经过处理后,使每个特征中的数值的均值变为0,标准差变为1。
1,标准正态分布
scale()是数据标准化的快捷方式:
X_scaled = preprocessing.scale(X_train)
对应的fit-transform组合是:
scaler = preprocessing.StandardScaler().fit(X_train)
scaler.transform(X_train)
2,把数据缩放到范围
把数据缩放到给定的范围内,通常在0和1之间,或者使用每个特征的最大绝对值按比例缩放到单位大小。
MinMaxScaler(feature_range=(0, 1), copy=True)
MaxAbsScaler(copy=True)
举个例子,MinMaxScaler() 用于把数据按照max和min缩放到0和1之间,其中max和min是缩放区间的最大值和最小值,缩放的公式如下:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min
使用MinMaxScaler()函数进行缩放:
scaler = preprocessing.MinMaxScaler(feature_range=(0, 1))
X_scaled=scaler.fit_transform(X_train)
二,数据归一化
通过对原始数据进行线性变换把数据映射到[0,1]或[-1,1]之间,常用的变换函数为:
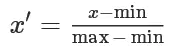
sklearn提供函数normalize或者fit-transform组合来实现数据的归一化。参数norm是用于标准化每个非0数据的范式,可用的值是 l1和l2 范式,默认值是l2范式。
#X_normalized = preprocessing.normalize(X, norm='l2')
normalizer = preprocessing.Normalizer( norm='l2').fit(X)
normalizer.transform(X) #out
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
三,对分类数据进行编码
把分类数据(标称数据)转换为数值编码,以整数的方式表示,对分类数据编码,有两种方式:顺序编码 和 OneHot编码。
1,顺序编码
顺序编码把每一个categorical 特征变换成有序的整数数字特征 (0 到 n_categories - 1),然而,这种整数表示不能直接用于所有scikit-learn估计器,因为估计器期望连续输入,并且把类别解释为有序的,但是,集合通常是无序的,无法实现顺序。
enc = preprocessing.OrdinalEncoder()
X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
enc.fit(X)
enc.transform([['female', 'from US', 'uses Safari']])
array([[0., 1., 1.]])
有序编码对象中包含 categories_ 属性,用于查看分类数据:
>>> enc.categories_
[array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object), array(['uses Firefox', 'uses Safari'], dtype=object)]
把转换的结果 [0., 1., 1.],代入到categories_ 属性中,数组的第一个元素是0,对应categories_ 属性中female类别;数组的第二个元素是1,对应categories_ 属性中from US类别,以此类推。
2,OneHot编码
另外一种将标称型特征转换为能够被scikit-learn中模型使用的编码是OneHot(独热码)、one-out-of-N(N取一编码)或dummy encoding(虚拟编码),这种编码类型已经在类OneHotEncoder中实现,该类把每一个具有n个可能取值的categorical特征变换为长度为n的特征向量,里面只有一个地方是1,其余位置都是0。
>>> from sklearn import preprocessing
>>> enc = preprocessing.OneHotEncoder()
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
>>> enc.transform([['female', 'from US', 'uses Safari']]).toarray()
[[1., 0., 0., 1., 0., 1.]]
>>> enc.categories_
[array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object), array(['uses Firefox', 'uses Safari'], dtype=object)]
如何理解OneHot编码的结果?原始数据中,有三个特征,分别是Gender、From 和 Browser,每个特征有2个取值,OneHot编码在原始数据中新增6个特征,分别是female、male、from Europe、from US、uses Firefox和uses Safari。
对于数据点 ['female', 'from US', 'uses Safari']的取值,对分类数据的编码结果是:[1., 0., 0., 1., 0., 1.],这对应着新增特征(female, male, from Europe, from US, uses Firefox, uses Safari)的取值:

属性categories_ 是长度为n的特征向量,代表新增特征(female, male, from Europe, from US, uses Firefox, uses Safari)。
三,离散化
离散化 (Discretization) 也叫 分箱(binning),用于把连续特征划分为离散特征值。
sklearn.preprocessing.KBinsDiscretizer(n_bins=5, encode=’onehot’, strategy=’quantile’)
参数注释:
n_bins:分箱的数量,默认值是5,也可以是列表,指定各个特征的分箱数量,例如,[feature1_bins,feature2_bins,...]
encode:编码方式,{‘onehot’, ‘onehot-dense’, ‘ordinal’}, (default=’onehot’)
- onehot:以onehot方式编码,返回稀疏矩阵
- onehot-dense:以onehot方式编码,返回密集矩阵
- ordinal:以ordinal方式编码,返回分箱的序号
strategy:定义分箱宽度的策略,{‘uniform’, ‘quantile’, ‘kmeans’}, (default=’quantile’)
- uniform:每个分箱等宽
- quantile:每个分箱中拥有相同数量的数据点
- kmeans:每个箱中的值具有与1D k均值簇最近的中心
举个例子,对于以下二维数组,有三个特征,可以创建分箱数组,为每个维度指定分箱的数量:
from sklearn import preprocessing
X = np.array([[ -3., 5., 15 ],
[ 0., 6., 14 ],
[ 6., 3., 11 ]])
est = preprocessing.KBinsDiscretizer(n_bins=[3, 2, 2], encode='ordinal').fit(X)
est.transform(X)
#out
array([[ 0., 1., 1.],
[ 1., 1., 1.],
[ 2., 0., 0.]])
参考文档:
sklearn 第二篇:数据预处理的更多相关文章
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(八):sklearn中的数据预处理和特征工程(一)简介
1 简介 数据挖掘的五大流程: 1. 获取数据 2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字 ...
- matlab、sklearn 中的数据预处理
数据预处理(normalize.scale) 0. 使用 PCA 降维 matlab: [coeff, score] = pca(A); reducedDimension = coeff(:,1:5) ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- Python初探——sklearn库中数据预处理函数fit_transform()和transform()的区别
敲<Python机器学习及实践>上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下: ...
- 机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介
当数据预处理完成后,我们就要开始进行特征工程了. 在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人, ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
随机推荐
- hgoi#20190513
T1-Felicity is Coming! 神奇宝贝的进化方案是一个全排列,假设有三种宝可梦,那么对应就可以有: (1,2,3)(1,3,2)(2,1,3)(2,3,1)(3,1,2)(3,2,1) ...
- IOS 数据存储(NSKeyedArchiver 归档篇)
什么是归档 当遇到有结构有组织的数据时,比如字典,数组,自定义的对象等在存储时需要转换为字节流NSData类型数据,再通过写入文件来进行存储. 归档的作用 之前将数据存储到本地,只能是字符串.数组.字 ...
- js与原生进行交互
由于最近做的项目我作为web前端要和原生开发者合作,所以就去踩了踩坑. 这个功能是在h5页面上点击按钮关闭当前页面. function click_fn() { var u = navigator.u ...
- 编译php扩展
在php编译安装好的情况下php扩展编译 php的很多模块都是以php的扩展形式来进行的.所以在php安装好的环境下需要用到之前安装时没有编译安装的php扩展的时候,这个时候编译安装php扩展就显得尤 ...
- appcan 多按钮提示框
使用 appcan.window.alert EG: var btnList=new Array(); btnList[0]="确认"; btnList[1]="取消& ...
- Java基础篇01
01. 面向对象 --> 什么是面向对象 面向对象 面向对象程序设计,简称OOP(Object Oriented Programming). 对象: 指人们要研究的任何事物,不管是物理上具体的事 ...
- 用ASP.NET Core重写了一款网络考试培训的免费软件
在IT圈混迹了近十年,今已正当而立之年却仍一事无成,心中倍感惶恐惭愧.面对竟争如此激列的环境,该如何应对?却也知不能让自已闲着,得转起来,动起来.于是,便想着利用最新技术栈将自已原来的收费产品重写一次 ...
- 仿写一个简陋的 IOC/AOP 框架 mini-spring
讲道理,感觉自己有点菜.Spring 源码看不懂,不想强行解释,等多积累些项目经验之后再看吧,但是 Spring 中的控制反转(IOC)和面向切面编程(AOP)思想很重要,为了更好的使用 Spring ...
- 法国神器"mimikatz"简化版,一键导出结果
神器之所以称之为神器.那是闹着玩的? 法国神器"mimikatz",那是相当的好使!!! GitHub:https://github.com/gentilkiwi/mimikatz ...
- Minimum Spanning Tree
前言 说到最小生成树(Minimum Spanning Tree),首先要对以下的图论概念有所了解. 图 图(Graph)是表示物件与物件之间的关系的数学对象,是图论的基本研究对象.图的定义方式有两种 ...