.30-浅析webpack源码之doResolve事件流(2)
这里所有的插件都对应着一个小功能,画个图整理下目前流程:
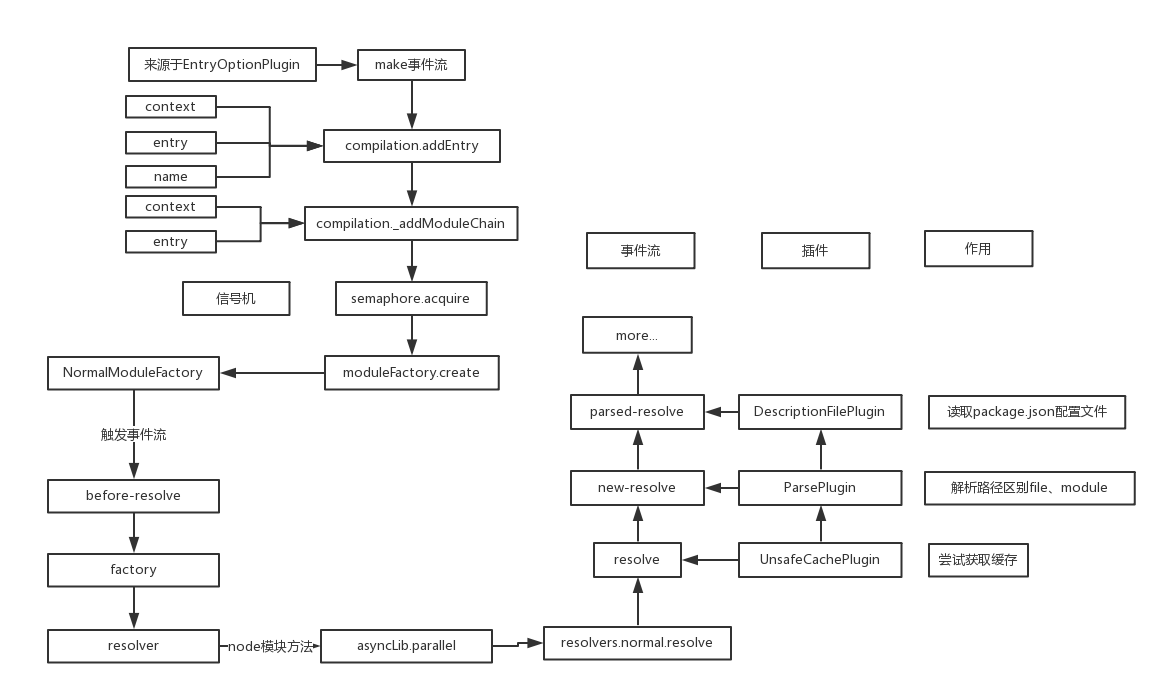
上节是从ParsePlugin中出来,对'./input.js'入口文件的路径做了处理,返回如下:
ParsePlugin.prototype.apply = function(resolver) {
var target = this.target;
resolver.plugin(this.source, function(request, callback) {
// 分析request是否为模块或文件夹
var parsed = resolver.parse(request.request);
var obj = Object.assign({}, request, parsed);
if (request.query && !parsed.query) {
obj.query = request.query;
}
if (parsed && callback.log) {
if (parsed.module)
callback.log("Parsed request is a module");
if (parsed.directory)
callback.log("Parsed request is a directory");
}
// 拼接后的obj如下
/*
{
context: { issuer: '', compiler: undefined },
path: 'd:\\workspace\\doc',
request: './input.js',
query: '',
module: false,
directory: false,
file: false
}
*/
// target => parsed-resolve
resolver.doResolve(target, obj, null, callback);
});
};
该插件调用完后,进入下一个事件流,开始跑跑parsed-resolve相关的了。
回头看了一眼28节的大流程图,发现基本上这些事件流都是串联起来挨个注入的,还好不用自己去找在哪了。
createInnerCallback
这里先讲一下之前跳过的回调函数生成器,在Resolver中调用如下:
// before-callback
createInnerCallback(beforeInnerCallback, {
log: callback.log,
missing: callback.missing,
stack: newStack
}, message && ("before " + message), true);
// normal-callback
createInnerCallback(innerCallback, {
log: callback.log,
missing: callback.missing,
stack: newStack
}, message);
// after-callback
createInnerCallback(afterInnerCallback, {
log: callback.log,
missing: callback.missing,
stack: newStack
}, message && ("after " + message), true);
方法的第一个参数都大同小异,取第一个为例:
function beforeInnerCallback(err, result) {
// 根据调用callback时是否有参数决定调用回调函数还是进入下一阶段
if (arguments.length > 0) {
if (err) return callback(err);
if (result) return callback(null, result);
return callback();
}
runNormal();
}
剩下的两个也只是把runNormal变成了runAfter与callback而已。
有了参数,接下来看一下生成器的内部实现:
module.exports = function createInnerCallback(callback, options, message, messageOptional) {
var log = options.log;
// 无log时
if (!log) {
// 基本上也是返回callback
// 只是把options的两个方法挂载上去了
if (options.stack !== callback.stack) {
var callbackWrapper = function callbackWrapper() {
return callback.apply(this, arguments);
};
callbackWrapper.stack = options.stack;
callbackWrapper.missing = options.missing;
return callbackWrapper;
}
return callback;
}
// 这个方法是批量取出本地log数组的内容然后调用options的log方法
function loggingCallbackWrapper() {
var i;
if (message) {
if (!messageOptional || theLog.length > 0) {
log(message);
for (i = 0; i < theLog.length; i++)
log(" " + theLog[i]);
}
} else {
for (i = 0; i < theLog.length; i++)
log(theLog[i]);
}
return callback.apply(this, arguments);
}
// 有log时
var theLog = [];
loggingCallbackWrapper.log = function writeLog(msg) {
theLog.push(msg);
};
loggingCallbackWrapper.stack = options.stack;
loggingCallbackWrapper.missing = options.missing;
return loggingCallbackWrapper;
};
这里的log大部分情况下都是undefined,所以暂时可以认为返回的基本上是第一个参数callback本身。
有log时也不复杂,等传入的options自带有效log时再看。
DescriptionFilePlugin
继续跑流程,这个插件就是对package.json配置文件进行解析,源码简化如下:
// request => 之前的obj
// callback => createInnerCallback(...)
(request, callback) => {
const directory = request.path;
/*
resolver => 大对象
directory => 'd:\\workspace\\doc'
filenames => ['package.json']
*/
DescriptionFileUtils.loadDescriptionFile(resolver, directory, filenames, ((err, result) => { /**/ }));
};
这里直接在内部调用了另外一个工具类的实例方法,源码如下:
var forEachBail = require("./forEachBail");
function loadDescriptionFile(resolver, directory, filenames, callback) {
(function findDescriptionFile() {
forEachBail(filenames, function(filename, callback) { /**/ }, function(err, result) { /**/ });
}());
}
forEachBail
内部引用了一个工具方法做迭代,继续看:
// 参数名字说明一切
module.exports = function forEachBail(array, iterator, callback) {
if (array.length === 0) return callback();
var currentPos = array.length;
var currentResult;
var done = [];
for (var i = 0; i < array.length; i++) {
var itCb = createIteratorCallback(i);
// 传入数组元素与生成的迭代器回调函数
iterator(array[i], itCb);
if (currentPos === 0) break;
} function createIteratorCallback(i) {
return function() {
if (i >= currentPos) return; // ignore
var args = Array.prototype.slice.call(arguments);
done.push(i);
if (args.length > 0) {
currentPos = i + 1;
done = done.filter(function(item) {
return item <= i;
});
// 将该回调的参数赋值到外部变量
currentResult = args;
}
// 遍历完调用callback
if (done.length === currentPos) {
callback.apply(null, currentResult);
currentPos = 0;
}
};
}
};
由于本例中array只有一个数组元素,所以这个看似复杂的函数也比较简单了,需要关注的只有一行代码:
iterator(array[i], itCb);
第一个参数为package.json字符串,第二个为内部生成的一个回调,回到调用方法上,对应的iterator方法如下:
(filename, callback) => {
// 路径拼接
var descriptionFilePath = resolver.join(directory, filename);
// 这个readJson我是翻回去找了老久
// 来源于CachedInputFileSystem模块的191行
/*
this._readJson = function(path, callback) {
this.readFile(path, function(err, buffer) {
if (err) return callback(err);
try {
var data = JSON.parse(buffer.toString("utf-8"));
} catch (e) {
return callback(e);
}
callback(null, data);
});
}.bind(this);
*/
// 这两个方法根本没有什么卵区别
if (resolver.fileSystem.readJson) {
resolver.fileSystem.readJson(descriptionFilePath, function(err, content) {
if (err) {
if (typeof err.code !== "undefined") return callback();
return onJson(err);
}
onJson(null, content);
});
} else {
resolver.fileSystem.readFile(descriptionFilePath, function(err, content) {
if (err) return callback();
try {
var json = JSON.parse(content);
} catch (e) {
onJson(e);
}
onJson(null, json);
});
}
// 在不出错的情况下传入null与读取到的json字符串
function onJson(err, content) {
if (err) {
if (callback.log)
callback.log(descriptionFilePath + " (directory description file): " + err);
else
err.message = descriptionFilePath + " (directory description file): " + err;
return callback(err);
}
callback(null, {
content: content,
directory: directory,
path: descriptionFilePath
});
}
}
这里首先进行路径拼接,然后调用readFile方法读取对应路径的package.json文件,如果没有出错,将读取到的字符串与路径包装成对象传入callback。
Resolver.prototype.join
简单看一下路径的拼接函数。
var memoryFsJoin = require("memory-fs/lib/join");
var memoizedJoin = new Map();
// path => 目录
// request => 文件名
Resolver.prototype.join = function(path, request) {
var cacheEntry;
// 获取缓存目录
var pathCache = memoizedJoin.get(path);
if (typeof pathCache === "undefined") {
memoizedJoin.set(path, pathCache = new Map());
} else {
// 获取目录缓存中对应的文件缓存
cacheEntry = pathCache.get(request);
if (typeof cacheEntry !== "undefined")
return cacheEntry;
}
// 初次获取文件
cacheEntry = memoryFsJoin(path, request);
// 设置缓存
pathCache.set(request, cacheEntry);
return cacheEntry;
};
非常的简单明了,用了一个map缓存一个目录,目录的值也是一个map,缓存该目录下的文件。
这里看一下是第一次时,memoryFsJoin是如何处理路径的:
var normalize = require("./normalize");
// windows与linux系统绝对路径正则
var absoluteWinRegExp = /^[A-Z]:([\\\/]|$)/i;
var absoluteNixRegExp = /^\//i;
// path => 'd:\\workspace\\doc'
// request => 'package.json'
module.exports = function join(path, request) {
if (!request) return normalize(path);
// 检测是否绝对路径
if (absoluteWinRegExp.test(request)) return normalize(request.replace(/\//g, "\\"));
if (absoluteNixRegExp.test(request)) return normalize(request);
// 目录为/时
if (path == "/") return normalize(path + request);
// 命中这里 注意正则后面的i
// 替换拼接后 => d:\\workspace\\doc\\package.json
if (absoluteWinRegExp.test(path)) return normalize(path.replace(/\//g, "\\") + "\\" + request.replace(/\//g, "\\"));
if (absoluteNixRegExp.test(path)) return normalize(path + "/" + request);
return normalize(path + "/" + request);
};
果然还没完,在进行两个平台路径间的判断后,将两个参数拼接后传入normalize方法,参数已经在注释给出。
以该字符串为例,看一下normalize方法:
// path => d:\\workspace\\doc\\package.json
module.exports = function normalize(path) {
// parts => [ 'd:', '\\', 'workspace', '\\', 'doc', '\\', 'package.json' ]
var parts = path.split(/(\\+|\/+)/);
if (parts.length === 1)
return path;
var result = [];
var absolutePathStart = 0;
// sep主要用来标记切割数组中\\这种路径符号
for (var i = 0, sep = false; i < parts.length; i++, sep = !sep) {
var part = parts[i];
//第一次弹入磁盘名 => result = ['d:']
if (i === 0 && /^([A-Z]:)?$/i.test(part)) {
result.push(part);
absolutePathStart = 2;
} else if (sep) {
// 如果是路径符号 直接弹入
// result = ['d:','\\']
result.push(part[0]);
}
// 接下来是对'..'与'.'符号进行处理
// 看一下注释就懂了 列举了各种情况
else if (part === "..") {
switch (result.length) {
case 0:
// i. e. ".." => ".."
// i. e. "../a/b/c" => "../a/b/c"
result.push(part);
break;
case 2:
// i. e. "a/.." => ""
// i. e. "/.." => "/"
// i. e. "C:\.." => "C:\"
// i. e. "a/../b/c" => "b/c"
// i. e. "/../b/c" => "/b/c"
// i. e. "C:\..\a\b\c" => "C:\a\b\c"
i++;
sep = !sep;
result.length = absolutePathStart;
break;
case 4:
// i. e. "a/b/.." => "a"
// i. e. "/a/.." => "/"
// i. e. "C:\a\.." => "C:\"
// i. e. "/a/../b/c" => "/b/c"
if (absolutePathStart === 0) {
result.length -= 3;
} else {
i++;
sep = !sep;
result.length = 2;
}
break;
default:
// i. e. "/a/b/.." => "/a"
// i. e. "/a/b/../c" => "/a/c"
result.length -= 3;
break;
}
} else if (part === ".") {
switch (result.length) {
case 0:
// i. e. "." => "."
// i. e. "./a/b/c" => "./a/b/c"
result.push(part);
break;
case 2:
// i. e. "a/." => "a"
// i. e. "/." => "/"
// i. e. "C:\." => "C:\"
// i. e. "C:\.\a\b\c" => "C:\a\b\c"
if (absolutePathStart === 0) {
result.length--;
} else {
i++;
sep = !sep;
}
break;
default:
// i. e. "a/b/." => "a/b"
// i. e. "/a/." => "/"
// i. e. "C:\a\." => "C:\"
// i. e. "a/./b/c" => "a/b/c"
// i. e. "/a/./b/c" => "/a/b/c"
result.length--;
break;
}
}
// 无意外直接弹入
else if (part) {
result.push(part);
}
}
// 给磁盘名后面拼接上路径符号
if (result.length === 1 && /^[A-Za-z]:$/.test(result))
return result[0] + "\\";
// 这是正常返回
return result.join("");
};
讲道理,只有不是乱写路径,这里都会普通的返回传进去的路径(后面会出现特殊情况)。
返回的路径,会被readFile作为参数调用,最终返回读取到的json字符串作为对应的content传入回调函数中。
/*
callback(null, {
content: content,
directory: directory,
path: descriptionFilePath
})
*/
function loadDescriptionFile(resolver, directory, filenames, callback) {
(function findDescriptionFile() {
forEachBail(filenames, function(filename, callback) { /**/ },
// 这里的callback为最外部的callback
// 被这里的回调绕死了
// result为之前传进来的对象 注释有写
function(err, result) {
if (err) return callback(err);
if (result) {
return callback(null, result);
} else {
directory = cdUp(directory);
if (!directory) {
return callback();
} else {
return findDescriptionFile();
}
}
});
}());
}
这个callback一层一层的往外执行,最后回到了DescriptionFilePlugin中:
DescriptionFileUtils.loadDescriptionFile(resolver, directory, filenames, ((err, result) => {
if (err) return callback(err);
// 找不到package.json文件时
if (!result) {
// 第一次也没有这两个属性
if (callback.missing) {
filenames.forEach((filename) => {
callback.missing.push(resolver.join(directory, filename));
});
}
if (callback.log) callback.log("No description file found");
// 直接调用callback
return callback();
}
// 如果读取到了就会将描述文件的路径、目录、内容拼接到request对象上
// 路径转换为相对路径
const relativePath = "." + request.path.substr(result.directory.length).replace(/\\/g, "/");
const obj = Object.assign({}, request, {
descriptionFilePath: result.path,
descriptionFileData: result.content,
descriptionFileRoot: result.directory,
relativePath: relativePath
});
// 触发下一个事件流
// 带有message
resolver.doResolve(target, obj, "using description file: " + result.path + " (relative path: " + relativePath + ")", createInnerCallback((err, result) => {
if (err) return callback(err);
if (result) return callback(null, result);
// Don't allow other description files or none at all
callback(null, null);
}, callback));
}));
如果没有package.json文件,就会直接调用callback并且不传任何参数,知道这个callback是哪个callback吗????
是这个:
function innerCallback(err, result) {
if (arguments.length > 0) {
if (err) return callback(err);
if (result) return callback(null, result);
return callback();
}
runAfter();
}
什么是回调地狱?无限ajax内嵌?nonono,太单纯,来看webpack源码吧,一个callback可以传入地心,搞得我现在看到callback就头大。
很明显,这里没有传任何参数,直接进入runAfter,下节讲吧,还好已经跑出来了,不然隔两天回来看根本不知道飞哪去了。
.30-浅析webpack源码之doResolve事件流(2)的更多相关文章
- .30-浅析webpack源码之doResolve事件流(1)
这里所有的插件都对应着一个小功能,画个图整理下目前流程: 上节是从ParsePlugin中出来,对'./input.js'入口文件的路径做了处理,返回如下: ParsePlugin.prototype ...
- .29-浅析webpack源码之doResolve事件流(1)
在上一节中,最后返回了一个resolver,本质上就是一个Resolver对象: resolver = new Resolver(fileSystem); 这个对象的构造函数非常简单,只是简单的继承了 ...
- .31-浅析webpack源码之doResolve事件流(2)
放个流程图: 这里也放一下request对象内容,这节完事后如下(把vue-cli的package.json也复制过来了): /* { context: { issuer: '', compiler: ...
- .32-浅析webpack源码之doResolve事件流(4)
流程图如下: 重回DescriptionFilePlugin 上一节最后进入relative事件流,注入地点如下: // relative plugins.push(new DescriptionFi ...
- .33-浅析webpack源码之doResolve事件流(5)
file => FileExistsPlugin 这个事件流快接近尾声了,接下来是FileExistsPlugin,很奇怪的是在最后才来检验路径文件是否存在. 源码如下: FileExistsP ...
- .34-浅析webpack源码之事件流make(3)
新年好呀~过个年光打游戏,function都写不顺溜了. 上一节的代码到这里了: // NormalModuleFactory的resolver事件流 this.plugin("resolv ...
- 浅析libuv源码-node事件轮询解析(3)
好像博客有观众,那每一篇都画个图吧! 本节简图如下. 上一篇其实啥也没讲,不过node本身就是这么复杂,走流程就要走全套.就像曾经看webpack源码,读了300行代码最后就为了取package.js ...
- .27-浅析webpack源码之事件流make(2)
上一节跑到了NormalModuleFactory模块,调用了原型方法create后,依次触发了before-rsolve.factory.resolver事件流,这节从resolver事件流开始讲. ...
- .3-浅析webpack源码之预编译总览
写在前面: 本来一开始想沿用之前vue源码的标题:webpack源码之***,但是这个工具比较巨大,所以为防止有人觉得我装逼跑来喷我(或者随时鸽),加上浅析二字,以示怂. 既然是浅析,那么案例就不必太 ...
随机推荐
- Android TV 开发(5)
本文来自网易云社区 作者:孙有军 问题3:TV launcher中没有入口图标 如果需要出现入口图标,你必须要在AndroidManifest中配置action为android.intent.acti ...
- Android开发教程 - 使用Data Binding(五)数据绑定
本系列目录 使用Data Binding(一)介绍 使用Data Binding(二)集成与配置 使用Data Binding(三)在Activity中的使用 使用Data Binding(四)在Fr ...
- Java虚拟机7:垃圾收集(GC)-2(并行和并发的区别)
1.并发编程下 这两个名词都是并发编程中的概念,在并发编程的模型下的定义: 并发:是在同一个cpu上同时(不是真正的同时,而是看来是同时,因为cpu要在多个程序间切换)运行多个程序. 并行:是多个或同 ...
- 我的AI之路 —— OCR文字识别快速体验版
OCR的全称是Optical Character Recoginition,光学字符识别技术.目前应用于各个领域方向,甚至这些应用就在我们的身边,比如身份证的识别.交通路牌的识别.车牌的自动识别等等. ...
- Spring Boot log4j多环境日志级别的控制
之前介绍了在<Spring boot中使用log4j>,仅通过log4j.properties对日志级别进行控制,对于需要多环境部署的环境不是很方便,可能我们在开发环境大部分模块需要采用D ...
- 微信小程序 - 实战小案例 - 简易记事本
多项技能,好像也不错.学习一下微信小程序. 教程:https://mp.weixin.qq.com/debug/wxadoc/dev/ 简介:一套用来开发在手机微信上运行的app框架,不用安装 组成: ...
- iOS 数据持久化-- FMDB
一.简介 1.什么是FMDB FMDB是iOS平台的SQLite数据库框架 FMDB以OC的方式封装了SQLite的C语言API 2.FMDB的优点 使用起来更加面向对象,省去了很多麻烦.冗余的C语言 ...
- 【learning】 扩展欧几里得算法(扩展gcd)和乘法逆元
有这样的问题: 给你两个整数数$(a,b)$,问你整数$x$和$y$分别取多少时,有$ax+by=gcd(x,y)$,其中$gcd(x,y)$表示$x$和$y$的最大公约数. 数据范围$a,b≤10^ ...
- Wilcoxon-Mann-Whitney rank sum test
Wilcoxon-Mann-Whitney ranksum test 无节点状况,假定为样本服从类似形状,如果不是类似形状的话,秩的比较没有过多意义. X有m个数,Y有n个数 \(H_0:\mu_1= ...
- editplus来编写html
本来写这篇文章,我可以有很多废话,但是很多都过去了,言而总之下:我暂且给这个方法起个名字,叫做“为之法”,因为有了这篇文章,很多人的想法会豁然开朗,那样有了个名字交流传阅起来就方便多了. 本方法依托于 ...