01-spark基础
1、定义
Spark是一个由scala语言编写的实时计算系统
Spark支持的API包括Scala、Python、Java 、R
2、功能
Spark Core: 将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
是Spark核心编程,类似Hadoop中的MR编程框架,但比MR拥有更丰富的算子,
且几乎所有对数据的处理都放置在内存中,所以比MR更高效。
Spark SQL: 类似Hive,但是Spark的SQL可以和SparkCore无缝集合,使用起来非常方便。对应的,MR和Hive并不能无缝集合。
Spark Streaming: 类似Storm,用来进行流式处理。
Spark MLlib: 用于机器学习,
Graphx: 用于图计算。
3、Spark部署方式
①YARN : 采用Yarn模式的话,其实就是把spark作为一个客户端提交作业给YARN,实际运行程序的是YARN。所以安装部署只需要在其中一台机器上安装spark就行。
②standalone: 使用spark内置的资源管理与调度器。
注:还有其他的部署方式,比如Apache Mesos等。但是最常见的Spark on Yarn
4、Spark运行方式
Spark程序,无论是Spark core、Spark Sql、Spark Streaming,都可以通过以下两种形式运行:
①Spark-shell
类似于scala的控制台,spark会自动帮我们做以下几件事情:
1.会在启动spark-shell的机器的4040端口上绑定spark的web监控页面
2.将SparkContext类的对象命名为sc
3.将SparkSession类的对象命名为spark
Spark-shell分为两种运行类型:
①spark-shell on StandaLone //可以使用shell连接内置的资源管理(standalone),进行任务提交,这里不研究
②spark-shell on YARN //可以使用shell连接yarn,进行任务提交。分为客户端、集群模式
1、spark on YARN 之 cluster 集群模式
我们提交的spark应用程序对于YARN来说,也只不过是一个分布式应用程序而已,
在YARN看来,一个MR程序和一个spark程序是没有区别的。所以spark程序提交后,
同样要跟YARN申请一个Continer来启动当前spark程序的Application Master,
YARN会选择一个空闲的Datanode启动AM,其实这种情况下,Spark的Driver程序运行在AM内。
提交程序之后,客户端连接可以断开。
2、spark on YARN 之 client 客户端模式
同样会跟YARN申请Continer用以执行AM程序,但是这个AM的作用就只有向YARN申请资源这么一个功能了。
在这种情况下,Spark的Driver程序在提交程序的客户端执行,也就是说Driver程序没有在AM内运行。
这个时候我们可以利用spark-shell进行交互,连接不能断开,也就不能多用户操作
注:在实际开发中我们都使用cluster模式。
eg: sc.textFile("/spark/all").flatMap(line => line.split(" ")). map(word => (word, 1)).reduceByKey(_ + _). saveAsTextFile("/spark/wcall")
//在spark-shell中输入上述wordcount语句就行,因为自动构建了SparkContext对象
②spark-submit
将程序打包成jar包,进行运行。
自己创建SparkContext类的对象,自己确定什么时候程序终止退出等相关所有操作。
命令:spark-submit --master yarn --deploy-mode cluster bigdata-spark-test.jar
5、粗粒度和细粒度(调度模式)
①粗粒度模式:
每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task。
应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源(即使不用),
最后程序运行结束后,回收这些资源。
②细粒度模式:
与粗粒度模式一样,应用程序启动时,先会启动executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,
之后,cluster manager会为每个task根据自身需要动态分配资源,单个Task运行完之后可以马上释放对应的资源。每个Task完全独立,
优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大(重新分配task的资源)。
注:yarn目前只支持粗粒度模式
注:ResourceManager:负责将集群的资源分配给各个应用使用,而资源分配和调度的基本单位是Container,其中封装了集群资源(CPU、内存、磁盘等),
每个任务只能在Container中运行,并且只使用Container中的资源。那么就算spark的Executor用不了这么资源,也会占用这么多,这就是粗粒度
6、整体架构
了解基本概念、部署、运行方式之后。了解下整体架构图。

Application: 用户编写的Spark应用程序。
Application jar:一个包含用户 Spark 应用的 Jar。
Driver: 负责执行main函数,创建SparkContext上下文(DAGScheduler 、TaskScheduler运行在SparkContext中)
sparkContext:它负责与程序、spark集群进行交互,包括创建RDD、accumulators及广播变量等。如sc.makeRDD()等方法
SparkContext是Spark的入口,相当于应用程序的main函数。
Cluster manager:一个外部的用于获取集群上资源的服务。(例如,Standlone Manager,Mesos,YARN)
Worker node:任何在集群中可以运行应用代码的节点,yarn上是DataNode。
Executor :一个为了在 worker 节点上的应用而启动的进程,它运行 task 并且将数据保持在内存中或者硬盘存储。
不同的Spark应用程序(Application)对应不同的Executor,这些Executor在整个应用程序执行期间都存在并且Executor中可以采用多线程的方式执行Task。
这样做的好处是,各个Spark应用程序的执行是相互隔离的。
Job :有一个RDD Action生成的一个或多个调度阶段所组成的一次计算作业。(可以理解为一个action算子触发一个Job,比方说count,first等)
(action触发的这次计算被划分为多个Stage)
Stage :每个 Job 被拆分成几个 stage(阶段) ,每个stage(阶段)划分为 很多task(任务),stage 彼此之间是相互依赖的,可以并行运行
Task :一个将要被发送到 Executor 中的工作单元,运行结果要么存储在内存中,要么存储在磁盘上。
DAG : 即 Directed Acyclic Graph,有向无环图,这是一个图论中的概念。如果一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是一个有向无环图。
DAGScheduler :把Job划分stage,然后把stage转化为相应的Tasks,并将Task以TaskSet的形式发送给TaskScheduler //其划分Stage的依据是遇见宽依赖就划分Stage
TaskScheduler:将Tasks添加到任务队列当中,并且负责将Task往Executor发送
注:DAGScheduler 、TaskScheduler运行在SparkContext中
注:一旦worker宕机,master会重新调度任务,而如果只是进程Executor出现问题,只会重启一个新的Executor
7、Spark任务提交流程
1、Cient向YARN的ResourceManager提交应用程序(包括启动ApplicationMaster的命令、提交给ApplicationMaster的程序和需要在Executor中运行的程序等。)
2、ResourceManager接收到请求后,在集群中选择一个NodeManager,为该应用程序分配Container,
3、然后Container中启动此应用的ApplicationMaster,ApplicationMaster负责运行driver,进行SparkContext等的初始化。(Spark的Driver的功能其实被ApplicationMaster做了,并不存在这一概念)
4、然后ApplicationMaster向ResourceManager注册,然后申请资源,运行Executor,并且启动CoarseGrainedExecutorBackend(即Spark的粗粒度执行器后台程序)
然后对其进行监控直到运行结束。
5、同时SparkContext创建DAGScheduler、Task Scheduler ,DAGScheduler将Action算子触发的job构建成DAG图,将DAG图根据依赖关系分解成Stage,并把TaskSet发送给Task Scheduler。
6、CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请任务集。
Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
7、剩余的事情就是等待Executor中的Task执行完成了,ApplicationMaster注销资源。
8、spark任务生成和提交的四个阶段
DAG的生成、stage切分、task的生成、任务提交
1、构建DAG
用户提交的job将首先被转换成一系列RDD并通过RDD之间的依赖关系构建DAG,然后将DAG提交到调度系统;
2、DAGScheduler将DAG切分stage(切分依据是shuffle),将stage中生成的task以taskset的形式发送给TaskScheduler
3、Scheduler 调度task(根据资源情况将task调度到Executors)
4、Executors接收task,然后将task交给线程池执行。
9、stage、pipeline(管道计算模式)
stage概念:Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,
每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。stage是由一组并行的task组成。
stage切割规则:从后往前,遇到宽依赖就切割stage。
stage计算模式:pipeline
pipeline:也就是来一条数据然后计算一条数据,把所有的逻辑走完,然后落地。
eg:sc.TextFile("\").map().flatmap().reduce()
一行数据读取出来之后,就进行map()、flatmap(),中间不会停歇,中间的map()计算结果不会保存、像流水线一样。
而MapReduce是 1+1=2,2+1=3的模式,也就是计算完落地,然后在计算,然后再落地到磁盘或内存。
注:这也是比Mapreduce快的原因,完全基于内存计算。
pipeline中数据何时落地:
①shuffle write、(Spark 也会自动缓存shuffle的部分数据)
②对RDD进行持久化的时候。
Stage的task并行度:
①Spark默认一个块对应一个分区,一个分区代表一个Task,如果都是窄依赖算子,可以流水线工作,那么task并行度为块个数
②由于宽依赖算子可以手动改变numTask,也就是分区数,即改变了并行度。如reduceByKey(XXX,3),GroupByKey(4),
但是根据Stage的划分,每个Stage都可以并行执行,也就是说reduceByKey(_ + _)等算子并不需要前面所有分区都执行完毕,
但凡有一个分区执行完毕,那么reduce就进行读取这个分区的结果文件,所以并行度为前后分区数相加
注:Task被执行的并发度 = Executor数目 * 每个Executor核数(=core总个数) //实际并发度
注:一个块的数据map().flatmap()这些流水线Task都在同一节点、同一分区执行。
注:core和cpu核不同,cpu有4核,那么分配到不同Executor的核可能只有两个,这两个称为Executor核数 <==>core
注:MR和Spark一样,其实并不一定等MapTask全部执行完才执行ReducceTask。可以设置,MapTask是执行完一个就执行,还是执行一定比例才执行ReducceTask
10、Spark Shuffle过程
hadoop中的shuffle存在map任务和reduce任务之间,而spark中的shuffle过程存在stage之间。
shuffle过程:由ShuffleManager负责,计算引擎HashShuffleManager(Spark 1.2)—>SortShuffleManager(现在用的)
shuffle过程参考网址:https://blog.csdn.net/quitozang/article/details/80904040
①HashShuffleManager:

shuffle write:
①stage结束之后,每个task处理的数据按key进行“分类”
②数据先写入内存缓冲区
③缓冲区满,溢出到磁盘文件
④最终,相同key被写入同一个磁盘文件
注:这种处理每个分区都会产生下一个stage的task数量的文件。
创建的磁盘文件数量 = 当前stagetask数量 * 下一个stage的task数量
read:
①从上游stage的所有task节点上拉取属于自己的磁盘文件
②每个read task会有自己的buffer缓冲,每次只能拉取与buffer缓冲相同大小的数据,然后聚合,聚合完一批后拉取下一批
③该拉取过程,边拉取边聚合
②优化后的HashShuffleManager
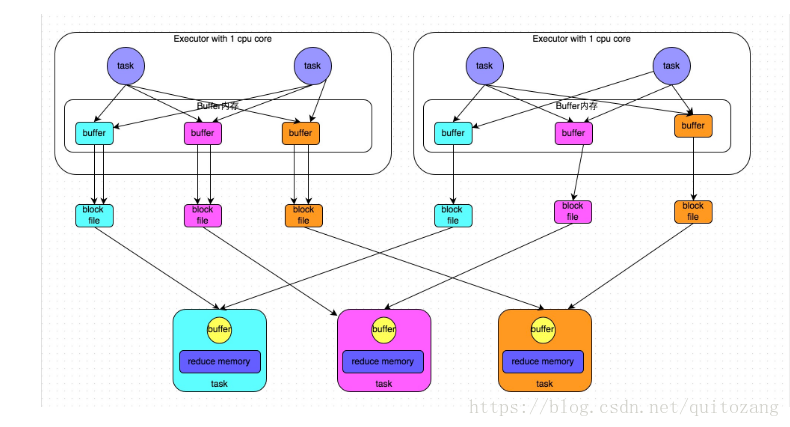
①一个Executor上有多少个core(线程),就可并行执行多少个task
②第一批并行执行的每个task会创建shuffleFileGroup,数据写入对应磁盘文件中
③第一批task执行完后,下一批task复用已有的shuffleFileGroup
磁盘文件数量 = core数量 * 下一个stage的task数量
③SortShuffleManager
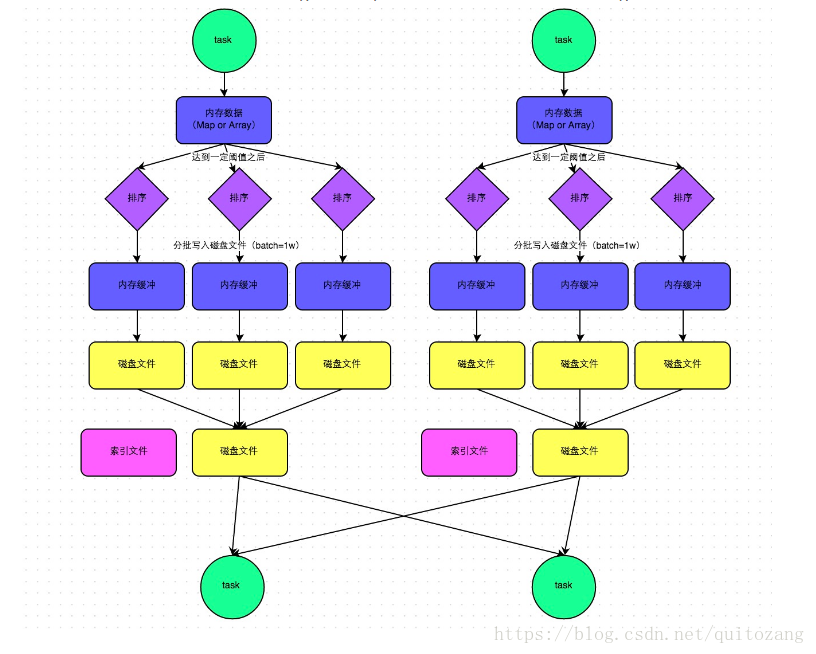
①数据先写入内存缓冲区
②每写一条数据,判断是否达到某个临界值,达到则根据key对数据排序,再溢出到磁盘
③合并所有临时磁盘文件(merge),归并排序,依次写入同一个磁盘文件
④单独写一份索引文件,标识下游各个task的数据在文件中的start and end
磁盘文件数量 = 上游stage的task数量
④Bypass
reducer的task数量 < spark.sort.bypassMergeThreshold(默认为200),shuffle write过程不排序,其余的和SortShuffleManager一样
注:现在的Spark在reduce<200,默认使用bypass,其余时候使用SortShuffleManager
01-spark基础的更多相关文章
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- 01: tornado基础篇
目录:Tornado其他篇 01: tornado基础篇 02: tornado进阶篇 03: 自定义异步非阻塞tornado框架 04: 打开tornado源码剖析处理过程 目录: 1.1 Torn ...
- Hadoop Spark 基础教程
0x01 Hadoop 慕课网 https://www.imooc.com/learn/391 Hadoop基础 慕课网 https://www.imooc.com/learn/890 Hadoop ...
- 【一】Spark基础
Spark基础 什么是spark 也是一个分布式的并行计算框架 spark是下一代的map-reduce,扩展了mr的数据处理流程. Spark架构原理图解 RDD[Resilient Distrib ...
- 后端 - Lession 01 PHP 基础
目录 Lession 01 php 基础 1. php 基础 2. php 变量 3. php 单引号 和 双引号区别 4. 数据类型 5. 数据类型转换 6. 常量 7. 运算符 8. 为 fals ...
- Spark 基础操作
1. Spark 基础 2. Spark Core 3. Spark SQL 4. Spark Streaming 5. Spark 内核机制 6. Spark 性能调优 1. Spark 基础 1. ...
- Jam's balance HDU - 5616 (01背包基础题)
Jim has a balance and N weights. (1≤N≤20) The balance can only tell whether things on different side ...
- Spark基础学习精髓——第一篇
Spark基础学习精髓 1 Spark与大数据 1.1 大数据基础 1.1.1 大数据特点 存储空间大 数据量大 计算量大 1.1.2 大数据开发通用步骤及其对应的技术 大数据采集->大数据预处 ...
- 086 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 03 面向对象基础总结 01 面向对象基础(类和对象)总结
086 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 03 面向对象基础总结 01 面向对象基础(类和对象)总结 本文知识点:面向对象基础(类和对象)总结 说明 ...
随机推荐
- virtualBox 虚拟机下nginx设置不缓存静态文件不起作用解决办法
最近开发的时候,调整js时会一直使用缓存文件,无法显示改动!nginx配置静态文件add_header Cache-Control no-cache;也不起作用,很苦恼! nginx配置代码:even ...
- Linux vi文本编辑器
vi文本编辑器 1.最基本用法 vi somefile.4 1/ 首先会进入“一般模式”,此模式只接受各种命令快捷键,不能编辑文件内容 2/ 按i键,就会从一般模式进入编辑模式,此模式下,敲入的都是 ...
- Linux中chown和chmod的区别和用法
转载自:http://www.cnblogs.com/EasonJim/p/6525242.html chmod修改第一列内容,chown修改第3.4列内容: chown用法: 用来更改某个目录或文件 ...
- 解决web项目存在多个log4j.properties配置文件,导致日志级别配置不生效问题
java开启log4j的debug模式 -Dlog4j.debug=true tomcat启动debug模式: linux打开catalina.sh导入: export JAVA_OPTS=" ...
- [Windows Hook] 屏蔽键盘按键
//该例程为在系统级屏蔽一些系统键.如WIN.TAB.CAP.POWER.SLEEP.HOME等! //屏蔽组合键下面例程不适用!(比如CTRL+ESC需要在钩子函数中用(p.vkCode = VK_ ...
- oracle--分组后获取每组数据第一条数据
SELECT * FROM (SELECT ROW_NUMBER() OVER(PARTITION BY cc.queuename ORDER BY cc.enroldate DESC) rn, cc ...
- %cd% 与 %~dp0% 区别
@echo off echo path:%~dpnx0% ipconfig /all|findstr "\<IPv4 适配器\>" %cd% 在批处理和命令窗口都能使 ...
- T-SQL select语句连接两个表
当一个表中按条件出现多个记录时,会按照匹配条件生成多个结果记录.left out 和right out 是对不能匹配的记录发生作用.
- Ubuntu 14.10 下安装rabbitvcs-版本控制
在Windows下用惯了TortoiseSVN这只小乌龟,到了Ubuntu下很不习惯命令行的SVN,于是经过一番寻找安装了RabbitVCS这款SVN图形化前端工具(官方网站:http://rabbi ...
- http系列(一)
一.关于Url URI由URL和URN组成,URI即统一资源标识符,URL即统一资源定位符,URN即统一资源名称. 现在最常用的是URL. 二.http请求/响应报文 请求报文:请求行.请求头部.空行 ...