HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html
目录
一、环境选择
1,集群机器安装图
这次因为是集群搭建,所以在环境配置方面,我使用一张表格来大致描述。集群使用了3台机器,分别是master、slave1、slave2,通过名称命名就可以知道主从关系了。使用的操作系统是CentOS6.8,具体各个机器安装的配置如下表格:
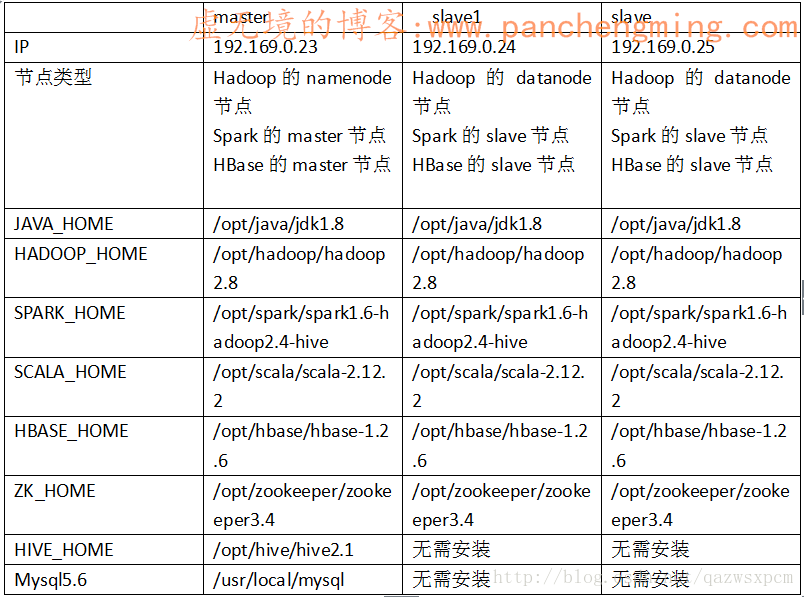
具体每个机器的配置就如上图了。需要补充的是,spark这块我没有使用官方自带的spark,而是使用的已经编译好的spark和hive的版本。因为后面在使用hive查询的时候,不想使用hive默认的mr,在hive2.x之后,官方也不建议了。因为使用mr效率实在太低,所以在后面我会将hive的引擎换成spark,而自己又不想重新编译spark ,所以就用这个版本了。如果各位想自行编译,或者出现更高的版本,就没必要一定按照上面的来。还有存放路径这块,没必要一定要使用上面的,可以先在机器上使用 df -h 查看相应的磁盘空间,再来进行部署。
2,配置说明
- JDK :Hadoop和Spark 依赖的配置,官方建议JDK版本在1.7以上!!!
- Scala:Spark依赖的配置,建议版本不低于spark的版本。
- Hadoop: 是一个分布式系统基础架构。
- Spark: 分布式存储的大数据进行处理的工具。
- zookeeper:分布式应用程序协调服务,HBase集群需要。
- HBase: 一个结构化数据的分布式存储系统。
- Hive: 基于Hadoop的一个数据仓库工具,目前的默认元数据库是mysql。
3,下载地址
官方地址:
Hadoop:
http://www.apache.org/dyn/closer.cgi/hadoop/common
Spark:
http://spark.apache.org/downloads.html
Spark Sql on Hive
http://mirror.bit.edu.cn/apache/spark
Scala:
http://www.scala-lang.org/download
JDK:
http://www.oracle.com/technetwork/java/javase/downloads
HBase
http://mirror.bit.edu.cn/apache/hbase/
Zookeeper
http://mirror.bit.edu.cn/apache/zookeeper/
Hive
http://mirror.bit.edu.cn/apache/hive/
百度云:
链接:https://pan.baidu.com/s/1kUYfDaf 密码:o1ov
二、集群的相关配置
1,主机名更改以及主机和IP做相关映射
1. 更改主机名
说明:更改主机名是为了方便集群管理,不然每个机器的名称都叫localhost也不太好吧! 集群所有的机器都要做这个操作。
输入
vim /etc/sysconfig/network 将localhost.localdomain修改为你要更改的名称,每台名称都不一样
例如:
HOSTNAME=master注: 名称更改了之后输入reboot重启才会生效。
2.做主机和IP的关系映射
修改hosts文件,做关系映射
说明:这个每台机器都做这个配置,具体ip和主机名称以自己的为准。
输入:
vim /etc/hosts添加
192.169.0.23 master
192.169.0.24 slave1
192.169.0.25 slave2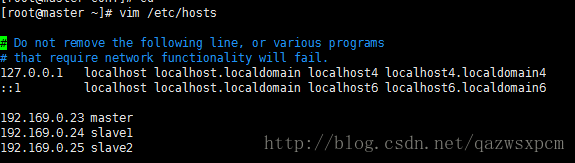
说明:可以在一台机器添加了之后可以使用scp 命令或使用ftp将这个文件copy到 其他机器中。
scp命令示例:
scp -r /etc/hosts root@192.169.0.24:/etc2,ssh免登录
设置ssh免密码登录是为了操作方便
生成秘钥文件
在每台机器上都执行一遍
首先输入:
ssh-keygen -t rsa -P ''生成秘钥之后,然后将每台机器/root/.ssh 都存入内容相同的文件,文件名称叫authorized_keys,文件内容是我们刚才为3台机器生成的公钥。可以在一台机器上生成,然后复制到其它的机器上。
新建authorized_keys文件
输入 :
touch /root/.ssh/authorized_keys编辑 authorized_keys 并将其他机器上的秘钥拷贝过来
cat /root/.ssh/id_rsa.pub
vim /root/.ssh/authorized_keys将其它机器上的 id_rsa.pub 的内容拷贝到 authorized_keys这个文件中。
第一个机器:

第二个机器:

第三个机器:

最终authorized_keys文件的内容
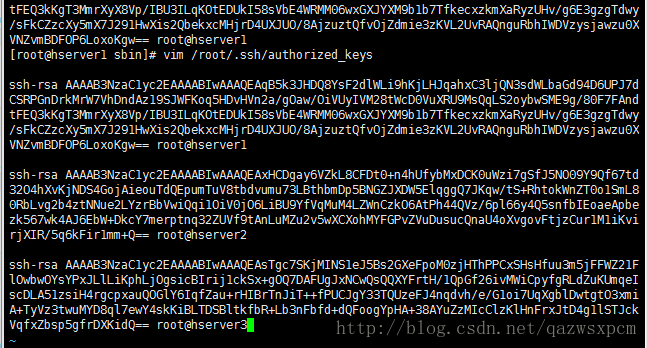
将这个最终的authorized_keys文件copy到其他机器的 /root/.ssh 目录下。使用scp或者ftp都可以。
scp命令示例:
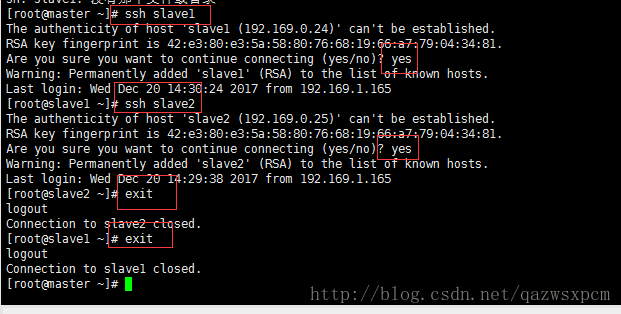
scp -r /root/.ssh/authorized_keys root@192.169.0.24:/root/.ssh测试免密码登录
输入:
ssh slave1
ssh slave2输入 exit 退出
3,防火墙关闭
说明:其实可以不关闭防火墙,进行权限设置,但是为了方便访问,于是便关闭了防火墙。每个机器都做!!!
关闭防火墙的命令
停止防火墙:
service iptables stop
启动防火墙:
service iptables start
重启防火墙:
service iptables restart
永久关闭防火墙:
chkconfig iptables off
4,时间配置
集群上的机器时间要同步,因为我这边的是虚拟机,所以就不用了。
设置集群时间同步可以使用NTP服务。
具体可以参考: http://blog.csdn.net/to_baidu/article/details/52562574
5,快捷键设置(可选)
说明:因为要经常切换各个目录之间,所以为了偷懒,就设置别名了。只需要在linux输入别名,就可以执行别名后面的命令,相当的方便。 例如:我们常用的ll就是 ls -l 的别名。关于别名这块各位可以自行摸索。
输入:
vim ~/.bashrc添加下面的内容
# Some more ailases
alias chd='cd /opt/hadoop/hadoop2.8'
alias chb='cd /opt/hbase/hbase1.2'
alias chi='cd /opt/hive/hive2.1'
alias czk='cd /opt/zookeeper/zookeeper3.4'
alias csp='cd /opt/spark/spark2.0-hadoop2.4-hive'
alias fhadoop='/opt/hadoop/hadoop2.8/bin/hdfs namenode -format'
alias starthadoop='/opt/hadoop/hadoop2.8/sbin/start-all.sh'
alias stophadoop='/opt/hadoop/hadoop2.8/sbin/stop-all.sh'
alias starthbase='/opt/hbase/hbase1.2/bin/start-hbase.sh'
alias stophbase='/opt/hbase/hbase1.2/bin/stop-hbase.sh'
alias startzk='/opt/zookeeper/zookeeper3.4/bin/zkServer.sh start'
alias stopzk='/opt/zookeeper/zookeeper3.4/bin/zkServer.sh stop'
alias statuszk='/opt/zookeeper/zookeeper3.4/bin/zkServer.sh status'
alias startsp='/opt/spark/spark1.6-hadoop2.4-hive/sbin/start-all.sh'
alias stopsp='/opt/spark/spark1.6-hadoop2.4-hive/sbin/stop-all.sh'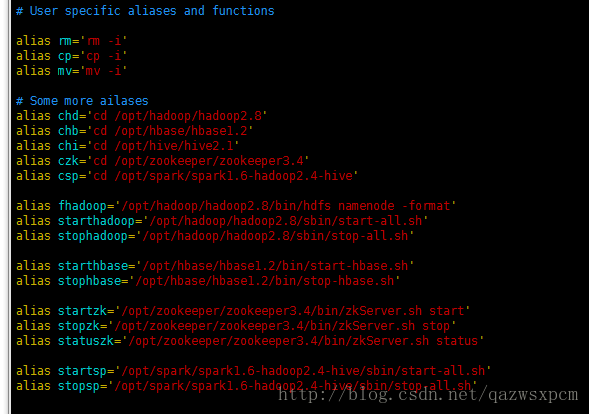
成功添加之后输入
source ~/.bashrc然后输入设置的别名就可以执行你所设置的内容了。别名的设置不一定非要按照上面的,如果有更好方式就请使用
6,整体环境变量设置
在 /etc/profile 这个配置文件要添加很多的环境配置,这里就先将整体的环境配置列举出来,各位在配置环境变量的以自己的为准!!! 可以先配置好环境变量之后,在传输到其他机器上去。
我这里先将这些配置都传输到其他的机器上了,并且都source了,所以下文中这个配置文件的操作实际是没做的。具体情况以自己的为准。
#Java Config
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
# Scala Config
export SCALA_HOME=/opt/scala/scala2.12
# Spark Config
export SPARK_HOME=/opt/spark/spark1.6-hadoop2.4-hive
# Zookeeper Config
export ZK_HOME=/opt/zookeeper/zookeeper3.4
# HBase Config
export HBASE_HOME=/opt/hbase/hbase1.2
# Hadoop Config
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
# Hive Config
export HIVE_HOME=/opt/hive/hive2.1
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:$PATH二、Hadoop的环境搭建
事先说明,这些配置可以在一台机器上配置,然后复制到其他机器上就行了。复制之后注意使这些配置文件生效。
1,JDK配置
说明: 一般CentOS自带了openjdk,但是hadoop集群使用的是oracle官方的jdk,所以先行卸载CentOS的jdk,然后再安装在oracle下载好的JDK。
首先输入 java -version
查看是否安装了JDK,如果安装了,但版本不适合的话,就卸载

输入
rpm -qa | grep java
查看信息 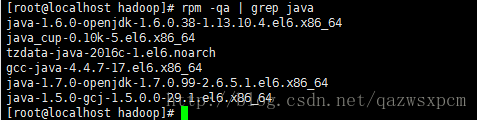
然后输入:
rpm -e –nodeps “你要卸载JDK的信息”
如: rpm -e –nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64

确认没有了之后,解压下载下来的JDK
tar -xvf jdk-8u144-linux-x64.tar.gz移动到opt/java文件夹中,没有就新建,然后将文件夹重命名为jdk1.8。
mv jdk1.8.0_144 /opt/java
mv jdk1.8.0_144 jdk1.8然后编辑 profile 文件,添加如下配置
输入:
vim /etc/profile添加:
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH添加成功之后,输入
source /etc/profile
java -version 查看是否配置成功
2,hadoop配置
3.2.1 文件准备
将下载下来的Hadoop的配置文件进行解压
在linux上输入:
tar -xvf hadoop-2.8.2.tar.gz然后将解压之后的文件夹移动到opt/hadoop文件夹下,没有该文件夹就新建,然后将文件夹重命名为hadoop2.8。
在linux上输入移动文件夹命令:
mv hadoop-2.8.2 /opt/hadoop
mv hadoop-2.8.2 hadoop2.83.2.2 环境配置
编辑 /etc/profile 文件
输入:
vim /etc/profile添加:
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH输入:
source /etc/profile使配置生效
3.2.3 修改配置文件
修改 core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml 等这些配置文件
在linux输入进入该目录的命令:
cd /opt/hadoop/hadoop2.8/etc/hadoop3.2.3.1 修改 core-site.xml
hadoop的存放路径可以自行更改。开始我以为这些文件夹需要手动创建,后来实践了,如果不手动创建,会自动创建的,所以就去掉了手动创建目录的步骤。
输入:
vim core-site.xml在<configuration>节点内加入配置:
<configuration>
<property>
<name>hadoop.temp.dir</name>
<value>file:/root/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- eclipse连接hive 的配置-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>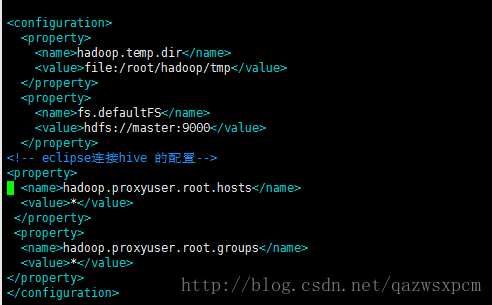
说明: fs.defaultFS 是缺省文件的名称, 最早使用的是 fs.default.name,后来在最新官方文档中查到该方法已经弃用了。于是边改成这个了。ps:感觉也没啥区别。
3.2.3.2 修改 hadoop-env.sh
这个要做,不知道为什么相对路径不识别,于是就使用绝对路径。
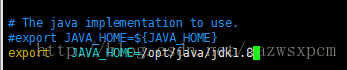
将
export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/opt/java/jdk1.8注:修改为自己JDK的路径
3.2.2.3 修改 hdfs-site.xml
下面的hdfs的存放路径,可以根据自己机器更改。
在<configuration>节点内加入配置:
<property>
<name>dfs:replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/data</value>
</property> 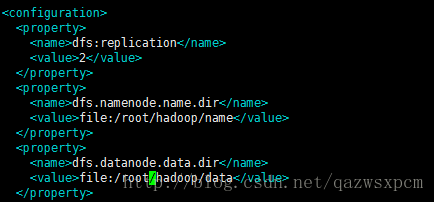
3.5.2.4 修改mapred-site.xml
执行mapreduce的运行框架配置。ps:感觉这个配置没啥用,可能我没用mr吧。
如果没有 mapred-site.xml 该文件,就复制mapred-site.xml.template文件并重命名为mapred-site.xml。
修改这个新建的mapred-site.xml文件,在<configuration>节点内加入配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>3.5.2.5 修改yarn-site.xml文件
yarn 资源调度的配置,集群的话这个配置是必须的。
修改/opt/hadoop/hadoop2.8/etc/hadoop/yarn-site.xml文件,
在<configuration>节点内加入配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8182</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>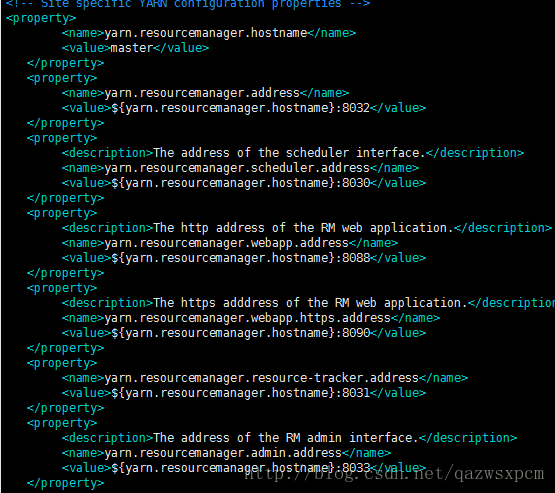
说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
3.5.2.6 修改slaves
设置主从的配置。如果不设置这个,集群就无法得知主从了。如果是单机模式,就没必要配置了。
修改/opt/hadoop/hadoop2.8/etc/hadoop/slaves文件
更改为
slave1
slave2这些配置参考Hadoop官方文档。
Hadoop官方配置文件具体说明: http://hadoop.apache.org/docs/r2.8.3/
在一台机器上(最好是master)做完这些配置之后,我们使用scp命令将这些配置传输到其他机器上。
输入:
jdk环境传输
scp -r /opt/java root@slave1:/opt
scp -r /opt/java root@slave2:/opthadoop环境传输
scp -r /opt/hadoop root@slave1:/opt
scp -r /opt/hadoop root@slave2:/opt传输之后,便在主节点启动集群。
在启动hadoop之前,需要初始化,这个只需要在master上初始化就可以了。
3,hadoop启动
注:启动hadoop之前确保防火墙关闭,各个机器时间通过,ssh免登录都没问题。
初始化hadoop
切换到/opt/hadoop/hadoop2.8/bin目录下输入
./hdfs namenode -format初始化成功之后,切换到/opt/hadoop/hadoop2.8/sbin
启动hadoop 的hdfs和yarn
输入:
start-dfs.sh
start-yarn.sh第一次登录会询问是否连接,输入yes ,然后输入密码就可以了
启动成功之后,可以使用jps命令在各个机器上查看是否成功
可以在浏览器输入: ip+50070 和8088端口查看
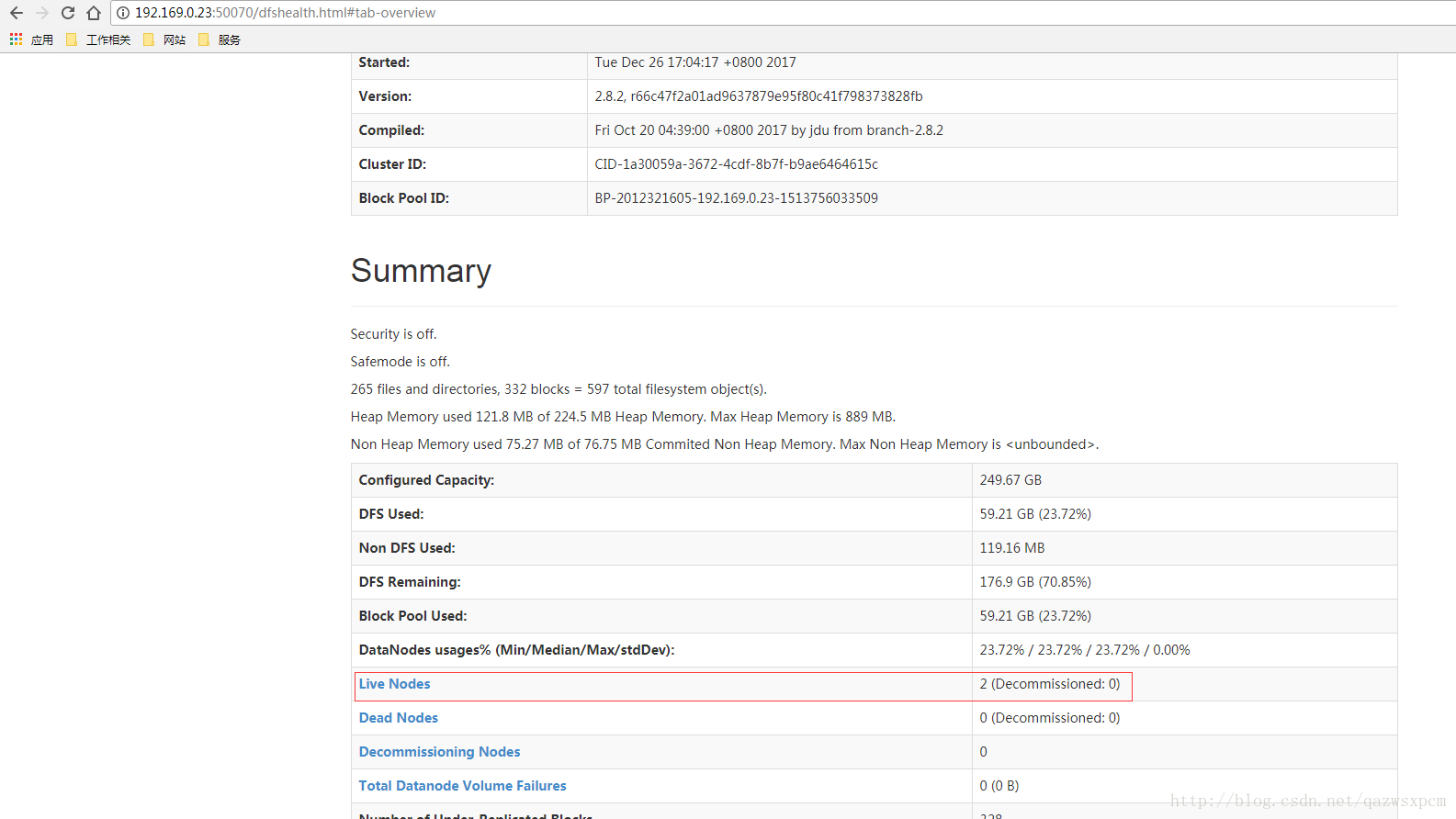
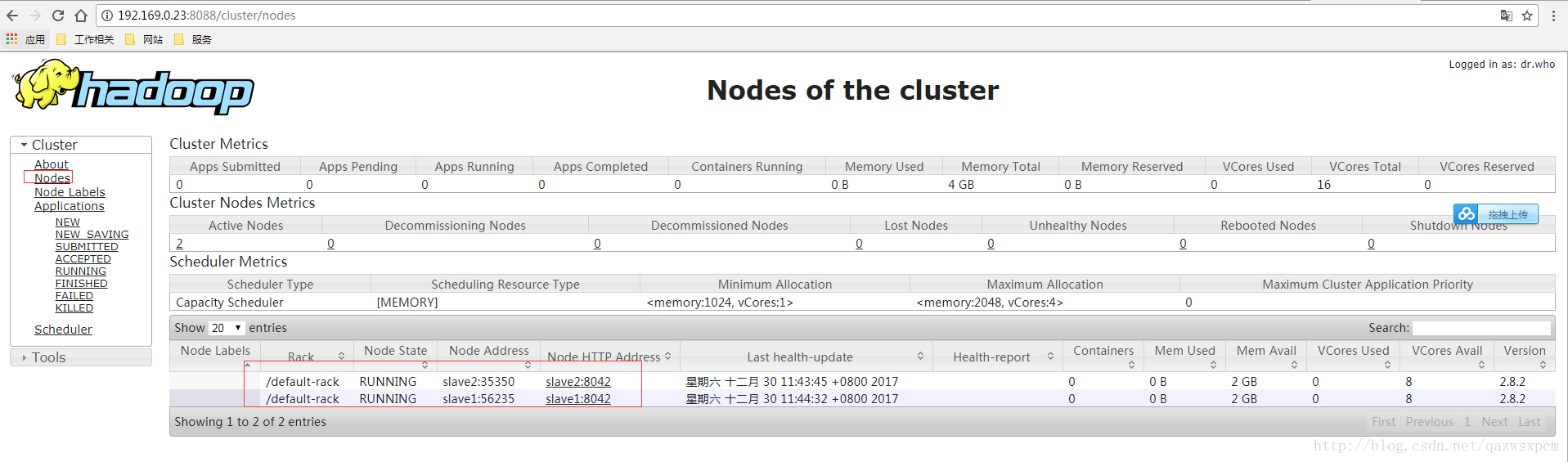
若如图显示,则启动成功。
若失败,检查jps是否成功启动,防火墙是否都关闭。都确认没问题之后,还是无法打开界面,请查看日志,再来找原因。
四、Spark的环境配置
说明:其实spark的相关配置,我在大数据学习系列之六 —– Hadoop+Spark环境搭建http://www.panchengming.com/2017/12/19/pancm63/ 应该已经说的很详细了,虽然是单机环境。其实集群也就增加个slave配置,其他的暂时好像没什么了。所以就简单的贴下配置。
1,Scala配置
和JDK配置几乎一样
4.1.1 文件准备
将下载好的Scala文件解压
输入
tar -xvf scala-2.12.2.tgz然后移动到/opt/scala 里面
并且重命名为scala2.1
输入
mv scala-2.12.2 /opt/scala
mv scala-2.12.2 scala2.124.1.2 环境配置
编辑 /etc/profile 文件
输入:
export SCALA_HOME=/opt/scala/scala2.12
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:$PATH输入:
source /etc/profile使配置生效
输入 scala -version 查看是否安装成功
2,Spark配置
4.2.1,文件准备
将下载好的Spark文件解压
输入
tar -xvf spark-1.6.3-bin-hadoop2.4-without-hive.tgz然后移动到/opt/spark 里面,并重命名
输入
mv spark-1.6.3-bin-hadoop2.4-without-hive /opt/spark
mv spark-1.6.3-bin-hadoop2.4-without-hive spark1.6-hadoop2.4-hive4.2.2,环境配置
编辑 /etc/profile 文件
输入:
export SPARK_HOME=/opt/spark/spark1.6-hadoop2.4-hive
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$PATH输入:
source /etc/profile使配置生效
4.2.3,更改配置文件
切换目录
输入:
cd /opt/spark/spark1.6-hadoop2.4-hive/conf4.2.3.1 修改 spark-env.sh
在conf目录下,修改spark-env.sh文件,如果没有 spark-env.sh 该文件,就复制spark-env.sh.template文件并重命名为spark-env.sh。
修改这个新建的spark-env.sh文件,加入配置:
export SCALA_HOME=/opt/scala/scala2.1
export JAVA_HOME=/opt/java/jdk1.8
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark/spark1.6-hadoop2.4-hive
export SPARK_MASTER_IP=master
export SPARK_EXECUTOR_MEMORY=4G注:上面的路径以自己的为准,SPARK_MASTER_IP为主机,SPARK_EXECUTOR_MEMORY为设置的运行内存。
4.2.3.2 修改slaves
slaves 分布式文件
在conf目录下,修改slaves文件,如果没有 slaves 该文件,就复制slaves .template文件并重命名为slaves 。
修改这个新建的slaves 文件,加入配置:
slave1
slave2在一台机器上(最好是master)做完这些配置之后,我们使用scp命令将这些配置传输到其他机器上。
输入:
scala环境传输
scp -r /opt/scala root@slave1:/opt
scp -r /opt/scala root@slave2:/optspark环境传输
scp -r /opt/spark root@slave1:/opt
scp -r /opt/spark root@slave2:/opt传输之后,便在主节点启动集群。
3,spark启动
说明:要先启动Hadoop
切换到Spark目录下
输入:
cd /opt/spark/spark2.2/sbin然后启动Spark
输入:
start-all.sh启动成功之后,可以使用jps命令在各个机器上查看是否成功。
可以在浏览器输入: ip+8080 端口查看
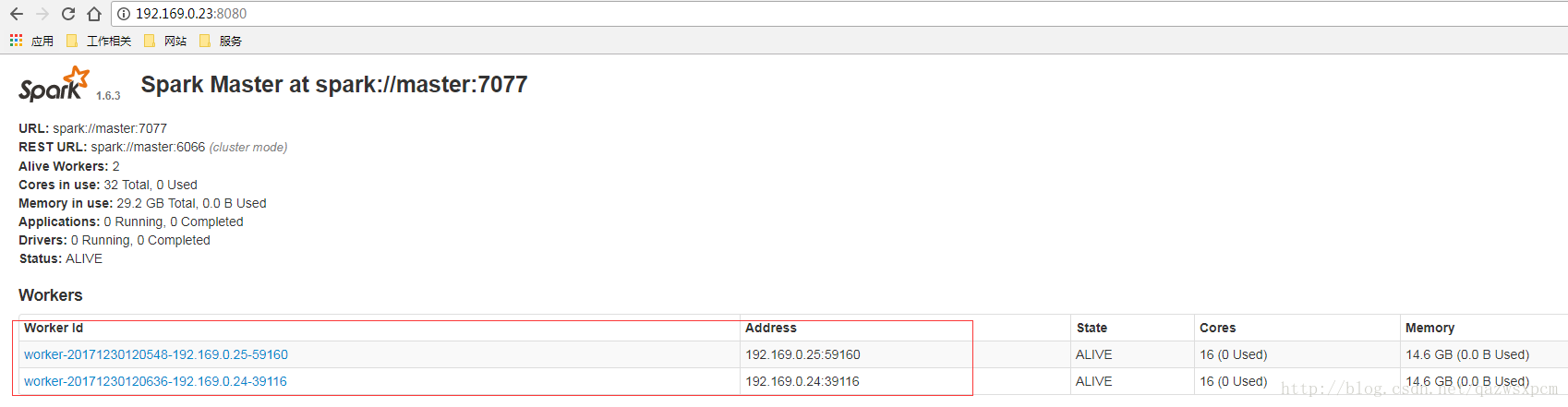
若成功显示这个界面,则表示Spark成功启动。
五、Zookeeper的环境配置
因为HBase做集群,所以就需要zookeeper了。
zookeeper 在很多环境搭建上,都会有他的身影,如kafka、storm等,这里就不多说了。
1,文件准备
将下载下来的Zookeeper 的配置文件进行解压
在linux上输入:
tar -xvf zookeeper-3.4.10.tar.gz然后移动到/opt/zookeeper里面,没有就新建,然后将文件夹重命名为zookeeper3.4
输入
mv zookeeper-3.4.10 /opt/zookeeper
mv zookeeper-3.4.10 zookeeper3.42,环境配置
编辑 /etc/profile 文件
输入:
export ZK_HOME=/opt/zookeeper/zookeeper3.4
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${ZK_HOME}/bin:$PATH输入:
source /etc/profile使配置生效
3,修改配置文件
5.3.1 创建文件和目录
在集群的服务器上都创建这些目录
mkdir /opt/zookeeper/data
mkdir /opt/zookeeper/dataLog并且在/opt/zookeeper/data目录下创建myid文件
输入:
touch myid创建成功之后,更改myid文件。
我这边为了方便,将master、slave1、slave2的myid文件内容改为1,2,3
5.3.2 新建zoo.cfg
切换到/opt/zookeeper/zookeeper3.4/conf 目录下
如果没有 zoo.cfg 该文件,就复制zoo_sample.cfg文件并重命名为zoo.cfg。
修改这个新建的zoo.cfg文件
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/dataLog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888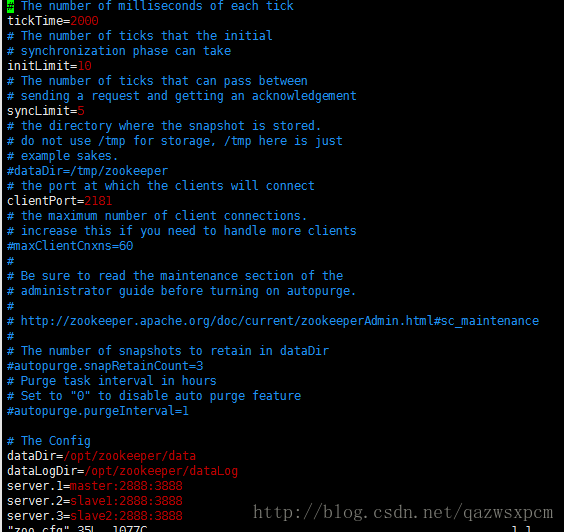
说明:client port,顾名思义,就是客户端连接zookeeper服务的端口。这是一个TCP port。dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性。dataDir和dataLogDir需要自己创建,目录可以自己制定,对应即可。server.1中的这个1需要和master这个机器上的dataDir目录中的myid文件中的数值对应。server.2中的这个2需要和slave1这个机器上的dataDir目录中的myid文件中的数值对应。server.3中的这个3需要和slave2这个机器上的dataDir目录中的myid文件中的数值对应。当然,数值你可以随便用,只要对应即可。2888和3888的端口号也可以随便用,因为在不同机器上,用成一样也无所谓。
1.tickTime:CS通信心跳数
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000
2.initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=10
3.syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=5
依旧将zookeeper传输到其他的机器上,记得更改 /opt/zookeeper/data 下的myid,这个不能一致。
输入:
scp -r /opt/zookeeper root@slave1:/opt
scp -r /opt/zookeeper root@slave2:/opt4,启动zookeeper
因为zookeeper是选举制,它的主从关系并不是像hadoop那样指定的,具体可以看官方的文档说明。
成功配置zookeeper之后,在每台机器上启动zookeeper。
切换到zookeeper目录下
cd /opt/zookeeper/zookeeper3.4/bin输入:
zkServer.sh start成功启动之后
查看状态输入:
zkServer.sh status可以查看各个机器上zookeeper的leader和follower
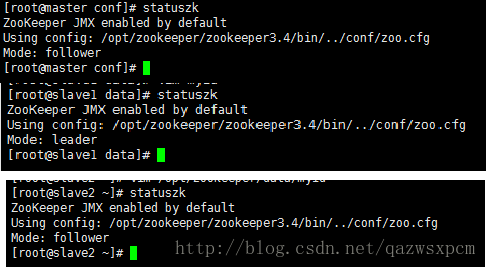
六、HBase的环境配置
1,文件准备
将下载下来的HBase的配置文件进行解压
在linux上输入:
tar -xvf hbase-1.2.6-bin.tar.gz然后移动到/opt/hbase 文件夹里面,并重命名为 hbase1.2
输入
mv hbase-1.2.6 /opt/hbase
mv hbase1.2 /opt/hbase2,环境配置
编辑 /etc/profile 文件
输入:
export HBASE_HOME=/opt/hbase/hbase1.2
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$PATH输入:
source /etc/profile使配置生效
输入
hbase version
查看版本

3,修改配置文件
切换到 /opt/hbase/hbase-1.2.6/conf 下
6.3.1 修改hbase-env.sh
编辑 hbase-env.sh 文件,添加以下配置
export JAVA_HOME=/opt/java/jdk1.8
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HBASE_HOME=/opt/hbase/hbase1.2
export HBASE_CLASSPATH=/opt/hadoop/hadoop2.8/etc/hadoop
export HBASE_PID_DIR=/root/hbase/pids
export HBASE_MANAGES_ZK=false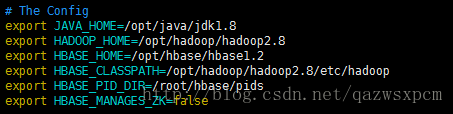
说明:配置的路径以自己的为准。HBASE_MANAGES_ZK=false 是不启用HBase自带的Zookeeper集群。
6.3.2 修改 hbase-site.xml
编辑hbase-site.xml 文件,在<configuration>添加如下配置
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
<description>The directory shared byregion servers.</description>
</property>
<!-- hbase端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!-- 超时时间 -->
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<!--防止服务器时间不同步出错 -->
<property>
<name>hbase.master.maxclockskew</name>
<value>150000</value>
</property>
<!-- 集群主机配置 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<!-- 路径存放 -->
<property>
<name>hbase.tmp.dir</name>
<value>/root/hbase/tmp</value>
</property>
<!-- true表示分布式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定master -->
<property>
<name>hbase.master</name>
<value>master:60000</value>
</property>
</configuration>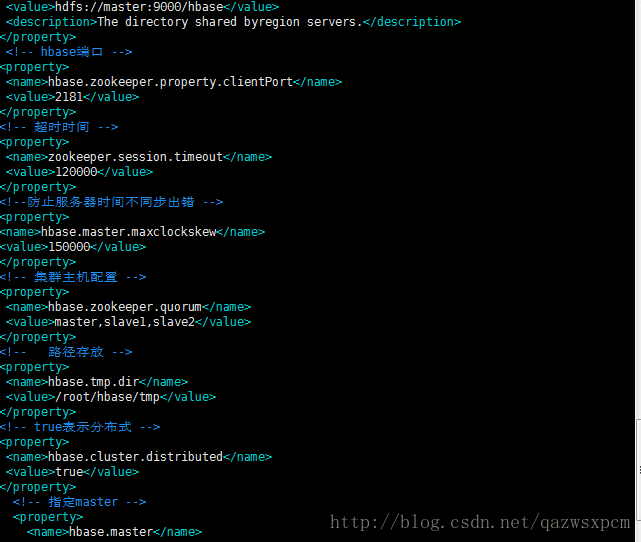
说明:hbase.rootdir:这个目录是region server的共享目录,用来持久化Hbase 。hbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面。
6.3.3 修改regionservers
指定hbase的主从,和hadoop的slaves文件配置一样
将文件修改为
slave1
slave2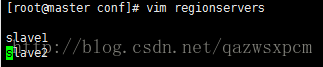
注:上面的为集群的主机名称
在一台机器上(最好是master)做完这些配置之后,我们使用scp命令将这些配置传输到其他机器上。
输入:
hbase环境传输
scp -r /opt/hbaseroot@slave1:/opt
scp -r /opt/hbase root@slave2:/opt传输之后,便在主节点启动集群。
4,启动hbase
在成功启动Hadoop、zookeeper之后
切换到HBase目录下
cd /opt/hbase/hbase1.2/bin输入:
start-hbase.sh启动成功之后,可以使用jps命令在各个机器上查看是否成功
可以在浏览器输入: ip+16010 端口查看
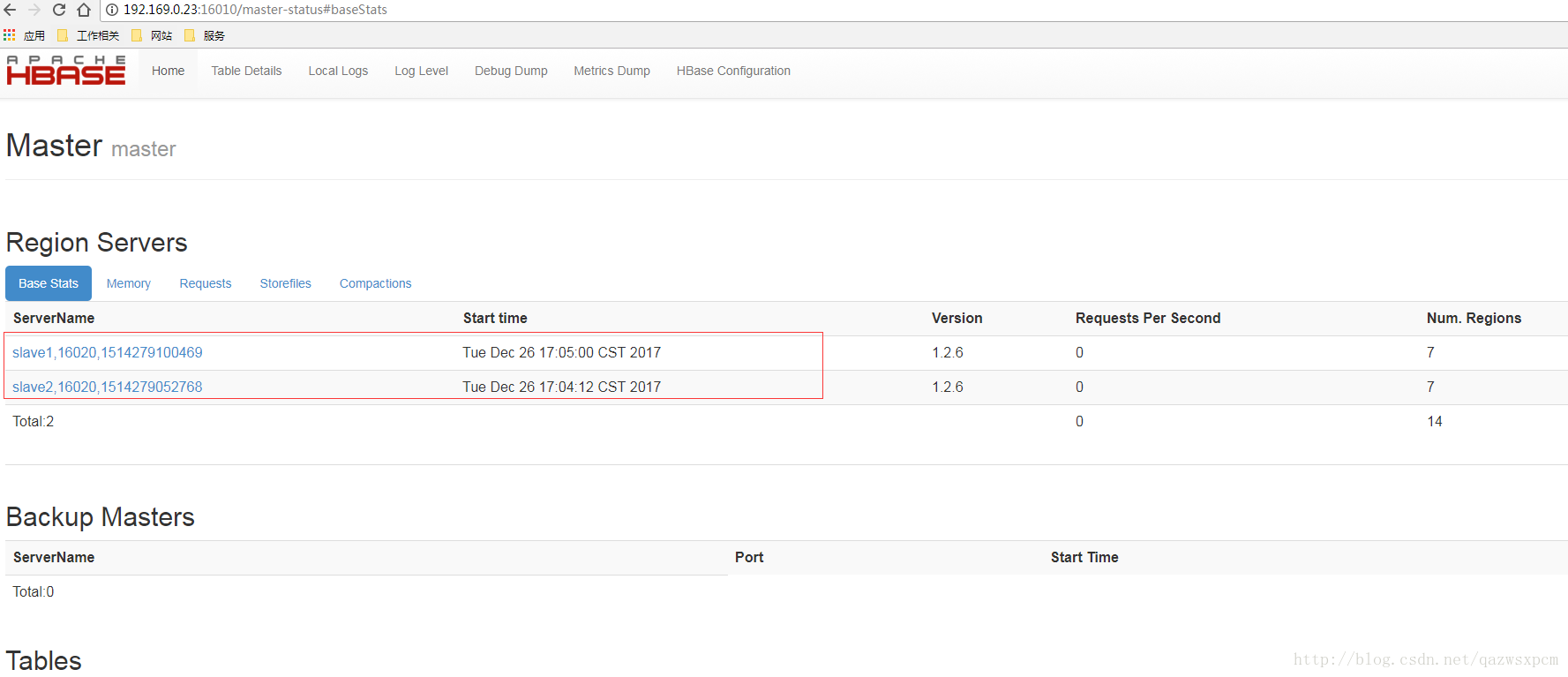
若成功显示该界面,则启动成功。
七、Hive的环境安装配置
因为hive安装使用不需要集群,只需在一台机器上安装使用就可以了,之前在我的
大数据学习系列之四 —– Hadoop+Hive环境搭建图文详解(单机)http://www.panchengming.com/2017/12/16/pancm61/ 里面已经讲解的很详细,所以本文就不在描述了。
八、其他
环境搭建参考: http://blog.csdn.net/pucao_cug/article/details/72773564
环境配置参考的官方文档。
HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Zookeeper简介与集群搭建【转】
Zookeeper简介 Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理.命名.分布式同步.集群管理.数据库切换等服务.它不适合用来存储大量信息,可以用来存储一些配置.发布与订阅等少 ...
- 基于zookeeper的Swarm集群搭建
简介 Swarm:docker原生的集群管理工具,将一组docker主机作为一个虚拟的docker主机来管理. 对客户端而言,Swarm集群就像是另一台普通的docker主机. Swarm集群中的每台 ...
- zookeeper及kafka集群搭建
zookeeper及kafka集群搭建 1.有关zookeeper的介绍可参考:http://www.cnblogs.com/wuxl360/p/5817471.html 2.zookeeper安装 ...
- 【运维技术】Zookeeper单机以及集群搭建教程
Zookeeper单机以及集群搭建教程 单机搭建 单机安装以及启动 安装zookeeper的前提是必须有java环境 # 选择目录进行下载安装 cd /app # 下载zk,可以去官方网站下载,自己上 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- hbase分布式集群搭建
hbase和hadoop一样也分为单机版.伪分布式版和完全分布式集群版本,这篇文件介绍如何搭建完全分布式集群环境搭建. hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop ...
随机推荐
- Pycharm乱码解决
现象:输出栏出现乱码 解决方案: 结果:
- MEMS 硅麦资料收集
MEMS 硅麦资料收集 PCM 和 I2S 协议的 MEMS Microphone PCM 协议在蓝牙方面比较多,一般都有 PCM 的接口. MEMS Microphone 更加的省电,更方便用于语音 ...
- pri 知识点
pri github:https://github.com/prijs/pri 添加路由后动态导入,使用的是 react-loadable:https://github.com/jamiebuilds ...
- openstack常见问题
openstack通过kolla-ansible添加一个计算节点,并部署后,发现控制节点上无法发现新加的计算节点, 在控制节点的 nova_scheduler.nova_api容器上执行发现计算节点 ...
- Fixed-point multiplication (C166 A*B/B)
I want to multiply two fixed point numbers. After the multiplication I have to shift the result so t ...
- php调用c#的dll(转)
这几天,一直在做DES ecb模式的加解密,刚用.net实现了加解密,完了由于需要又要转型成PHP代码,费了九牛二虎之力单独用PHP没能实现,结构看到一篇php直接调用c#里生成的.dll文件的方法, ...
- jmeter --- 监控器 Plugins (&jconsole)
jmeter --- 监控器 Plugins (&jconsole) Jmeter本身没有监控服务器资源的功能,需要添加额外插件 一.监控原理图 二.Jmeter-Plugs下载和安装 官网上 ...
- NPC问题及证明
致谢:http://www.docin.com/p-1902790324.html
- Centos 6.3 安装教程
如果创建虚拟机,加载镜像之前都报错,可能是virtualbox 的版本问题,建议使用virtualbox 4.3.12 版本 1. 按回车 2.Skip 跳过 3.next 4.选择中文简体 n ...
- PHP localhost和127.0.0.1 的区别