Percona Xtradb Cluster的设计与实现
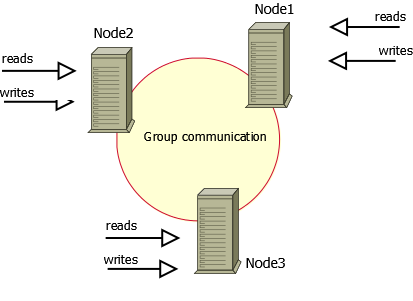
Percona Xtradb Cluster的实现是在原mysql代码上通过Galera包将不同的mysql实例连接起来,实现了multi-master的集群架构,如下图所示:
- 在这个函数中首先做的是wsrep_init,这里初始化很多变量,从变量wsrep_provider中找到对应的Galera动态链接包,找到它的接口(包括上面介绍的7个),最主要的是下面结构的初始化:
- mysql与galera是分层的,上层可以调用galera的接口来复制数据库的,但是对于galera,它是不知道如何提交一个事务,如何判断写入结果集是不是冲突,也不知道如何做sst,更不知道如何解析binlog来做复制。所以上层必须要向galera下层说明如何去解析,如何去执行等。
- 框架的一般实现方式,这属于废话。
- wsrep_log_cb:用来做日志的,因为galera产生一些日志后,需要告诉mysql,转换为mysql的日志,所以它需要这个接口告诉mysql,让mysql记录底层产生的日志。
- wsrep_view_handler_cb:这是Galera启动之后,第一个需要执行的回调函数,在新节点的Galera加入到并且已经连接到集群中时,新node会拿自己的local_state_uuid和集群的cluster_state_uuid对比,如果这两者有区别时,就需要做sst或者ist,此时这个回调函数所做的工作是,根据不同的同步方式,准备不同的同步命令:
- 对于mysqldump,这里只需要将数据接收地址及执行方式告诉集群即可。因为对于这种的实现方式是,doner直接在远程连接新加入的mysql实例,将它自己的所有数据dump出来直接用mysql执行了,所以新加入的节点不需要做任何操作,因为doner在导入的时候,如果新节点已经启动完成,也是可以做操作的。
- 对于rsync,这里需要做的是告诉集群同步方式及执行命令,因为这与mysqldump不同,对于rsync与xtrabackup,它们用到的同步方式分别是脚本wsrep_sst_rsync,wsrep_sst_xtrabackup,这2个脚本都放在安装目录的bin下面,在这里会把相应的命令生成出来,对于rsync,类似是这样的命令:
wsrep_sst_rsync --role 'joiner' --address '192.168.236.231' --auth 'pxc_sst:txsimIj3eSb8fttz' --datadir '/home/q/zhufeng.wang/pxcdata2/' --defaults-file '/home/q/zhufeng.wang/pxcdata2/my.cnf' --parent '11048',
在这个命令中,--role指明当前节点是joiner还是doner,因为在脚本中会做不同处理,--address表示向什么地址同步,--auth是在配置文件中指定的权限信息,--datadir表示当前新加入的库的数据目录,--defaults-file表示新加入节点的配置文件,--parent表示加入者的进程id号。
这里生成的命令的作用是,以joiner的角色执行脚本wsrep_sst_rsync,从脚本中可以看到,它会给mysql返回一个“ready 192.168.236.231:4444/rsync_sst”的字符串,地址和ip表示的是加入节点上面用来传数据的RSYNC(具体说应该是NC)的地址和端口,4444是脚本中已经写好的值,如果这个端口已经在用了,则会失败。而后面的rsync_sst是用来检查是不是已经有人在做了,如果文件rsync_sst.pid已经存在,则说明正在执行,此时执行会失败。如果正常的话则会创建另一个文件rsync_sst.conf,这是一个配置文件,用来让加入节点做rsync操作的,里面指定了path,read only,timeout等信息。
上面的问题解释清楚之后,脚本需要执行的就是等待donor给它传数据了,它会被阻塞,直到数据成功传送完成。
此时加入节点已经将信息“执行方式+192.168.236.231:4444/rsync_sst“传给了Galera,Galera在得到这个信息,并且等到选择一个合适的donor出来之后,这个donor会给端口4444传数据。脚本等待并且接收数据完成之后,就说明恢复完成了,因为rsync是直接复制文件的。那么此时脚本会返回一个UUID:seqno信息给加入节点,加入节点在这之前一直处于等待状态,如果收到这些信息之后说明恢复完成,则继续启动数据库。 - 对于xtrabackup,前面信息都是一样的,只是用到的脚本不同,脚本是wsrep_sst_xtrabackup,也同样会先执行一个参数角色为joiner的脚本wsrep_sst_xtrabackup,这个部分也会给加入节点返回一个字符串信息:ready 192.168.236.231:4444/xtrabackup_sst,返回之后,脚本就在等待NC将所有donor备份的数据传过来直到完成。还是同样地,Galera得到192.168.236.231:4444/xtrabackup_sst信息之后,集群会选择一个donor出来给这个地址发送备份数据。等待传送完成之后,脚本会继续执行,此时执行的就是xtrabackup的数据恢复操作,恢复完成之后,脚本会给加入节点输出UUID:seqno信息,而此时加入节点一直在等待的,如果发现脚本给它这些信息之后,说明已经做完sst,那么加入完成,数据库正常继续启动。
- wsrep_apply_cb:这个函数其实很容易明白,从名字即可看出是apply,因为在Galera层,上面已经讲过了,它是不知道binlog是什么东西的,它只知道key是什么东西,同时它判断是不是冲突也就是根据key来实现的,根本不会用到binlog,那么在Galera中,如果已经判断到一个节点上面的一个事务操作没有出现冲突,那Galera怎么知道如何去做复制呢?让其它节点也产生同样的修改呢?那么这个函数就是告诉Galera怎么去做复制,在下层,如果判断出不冲突,则Galera直接执行这个回调函数即可,因为这个函数处理的直接就是binlog的恢复操作。它拿到的数据就是一个完成的binlog数据。
- wsrep_commit_cb:同样的道理,对于Galera,也是有事务的,它在完成一个操作之后,如果本地执行成功,则需要执行提交,如果失败了,则要回滚,那么Galera也还是不知道如何去提交,或者回滚,或者回滚提交需要做什么事情,那么这里也是要告诉Galera这些东西。
- wsrep_unordered_cb:什么都不做
- wsrep_sst_donate_cb:这个回调函数很重要,从名字看出,它是用来提供donate的,确实是的,在上面wsrep_view_handler_cb中介绍的做SST的时候已经介绍了一点这方面的信息,那这个函数是什么时候用呢?
它是在wsrep_view_handler_cb函数告诉加入节点的地址端口及执行方式之后,这个是告诉pxc集群了,那么集群会选择一个合适的节点去做donor,那么选择出来之后,它怎么知道如何去做?那么这里就是要告诉它如何去做,把数据发送到哪里等等,因为wsrep_view_handler_cb告诉集群的信息只是一个地址、端口及执行方式,是一个字符串而已,那么wsrep_sst_donate_cb拿到的东西就是这个信息,而此时加入节点正处于等待donor传数据给它的状态,应该是阻塞的。
那么这个回调函数做的是什么呢?首先它会根据传给它的执行方式判断是如何去做,现在有几种情况:- 对于mysqldump方式,这里做的事情是执行下面的命令: "wsrep_sst_mysqldump "
WSREP_SST_OPT_USER " '%s' "WSREP_SST_OPT_PSWD " '%s' "WSREP_SST_OPT_HOST " '%s' "WSREP_SST_OPT_PORT " '%s' "WSREP_SST_OPT_LPORT " '%u' "WSREP_SST_OPT_SOCKET " '%s' "WSREP_SST_OPT_DATA " '%s' "WSREP_SST_OPT_GTID " '%s:%lld'"很明显,它现在执行的是脚本 wsrep_sst_mysqldump ,后面是它的参数,其实里面用到的就是mysqldump命令,脚本中主要的操作是mysqldump $AUTH -S$WSREP_SST_OPT_SOCKET --add-drop-database --add-drop-table --skip-add-locks --create-options --disable-keys --extended-insert --skip-lock-tables --quick --set-charset --skip-comments --flush-privileges --all-databases可以看出它是将全库导出的,导出之后直接在远程将导出的sql文件通过mysql命令直接执行了,简单说就是远程执行了一堆的sql语句,将所有的信息复制到(远程执行sql)新加入节点中。而这也正是mysqldump不像其它2种执行方式一样在新加入节点还需要做些操作,包括恢复,等待等操作,mysqldump方式在新加入节点也是不需要等待
- 对于rsync方式,执行的命令是:wsrep_sst_rsync "
WSREP_SST_OPT_ROLE " 'donor' "WSREP_SST_OPT_ADDR " '%s' "WSREP_SST_OPT_AUTH " '%s' "WSREP_SST_OPT_SOCKET " '%s' "WSREP_SST_OPT_DATA " '%s' "WSREP_SST_OPT_CONF " '%s' "WSREP_SST_OPT_GTID " '%s:%lld'"可以看出,它执行的还是脚本wsrep_sst_rsync ,不过现在的角色是donor,在脚本中,它就是把库下面所有的有用的文件都一起用rsync传给加入节点的NC,这又与上面说的接起来了,这边传数据,那么收数据,这边完成之后,那么收数据完成了,则SST也就做完了。
- 对于Xtrabackup方式,执行的命令是一样的,只是用到的脚本是wsrep_sst_xtrabackup,道理与上面完全相同,这边做备份,那么接收数据,等各自完成之后,也就完成了SST。
- 对于mysqldump方式,这里做的事情是执行下面的命令: "wsrep_sst_mysqldump "
- wsrep_synced_cb:这个回调函数的作用是,在mysql启动的时候,会有一些状态不一致的情况,那么当状态不一致的时候,系统会将当前的状态设置为不可用,也就是wsrep_ready这个状态变量为OFF,那么为了保证数据的一致性,或者由于复制启动的时候会影响到数据的一致性,那么在这个状态的时候,从库的复制线程会等待这个状态变为ON的时候才会继续执行,否则一直等待,那么这个回调函数做的事情就是告诉新加入节点或者donor节点,现在的同步已经完成了,状态已经是一致的了,可以继续做下面的操作了。所以此时复制会继续开始。
- 语句分析:对于这个阶段,执行的都是本地操作,不会涉及到集群的操作,所以和普通的mysql执行分析操作没有区别。
- 本地执行:对于第2阶段,这里会做一个很重要的操作,那就是在插入、更新、删除记录时会调用一个wsrep_append_keys函数,它的作用就是将当前被修改的记录的关键字(其实就是当前表的关键字在这行记录中对应的列的值,如果没有关键字,则就是rowid,因为pxc只支持innodb)提取出来,再按照Galera接口需要要的格式组装起来,然后再通过Galera的接口append_key(上面已经详细介绍过了)传给集群。
对于不同操作,其实KEY的最终数据是不同的,如果是插入,KEY当然只有新记录的键值,对于更新,包括了旧数据及新数据的键值,对于删除,则只有老数据的键值。同时如果键值具有多个列,则它们的组合方式是以列优先,其次才是新旧值,也就是说,对于更新记录,它的顺序应该是下面这样的:
旧键第一个值 新键第一个值 旧键第二个值 新键第二个值 ...... ...... 旧键第n个值 新键第n个值 当然对于插入行,只是简单的下面的格式:新键第一个值 新键第二个值 ...... 新键第n个值 还是上面说的,galera完全是靠这些KEY来判断是不是已经和其它客户端的操作造成了冲突的。 - 事务提交:在这个阶段,首先会做一个两阶段提交的wsrep_prepare,这里面会执行一个核心操作,对应的函数是wsrep_run_wsrep_commit,在这个函数中做了2个重要的操作,首先将这个事务产生的binlog通过接口append_data传给集群,这部分data是与上面的key对应的,组成了key-value结构,key是用来判断是不是冲突的,value是用来复制的,它是完完整整的binlog,在做复制的时候其它节点直接拿来做apply。另一件事就是调用接口pre_commit,这在上面已经说过了,其实就里请求集群对当前key-value进行验证,如果验证通过,则地本继续执行提交,将数据固化,而如果验证失败,则回滚即可。
- 如果出现不一致,节点如何被集群踢出
到现在为止,所有的关于pxc实现方式已经基本搞清楚,其它问题均是mysql本身的问题
总结:pxc架构上面可谓是实现了真正的集群,最主要的特点是多主的,并且基本没有延时,这样就解决了mysql主从复制的很多问题,但其中还是存在一些问题的,比如2个节点容易出现脑裂现象,这必须要通过另一个工具去做一个监控及评判,而官方推荐最好是搞三个节点,但可能会造成一定程度的空间及机器的浪费,但在实际使用时可以适当的在一个实例上面多放置几个库,来提高使用效率。
Percona Xtradb Cluster的设计与实现的更多相关文章
- 如何搭建Percona XtraDB Cluster集群
一.环境准备 主机IP 主机名 操作系统版本 PXC 192.168.244.146 node1 ...
- PXC(Percona XtraDB Cluster)集群的安装与配置
Percona XtraDB Cluster是针对MySQL用户的高可用性和扩展性解决方案,基于Percona Server .其包括了Write Set REPlication补丁,使用Galera ...
- Percona XtraDB Cluster(转)
Percona XtraDB Cluster是针对MySQL用户的高可用性和扩展性解决方案,基于Percona Server .其包括了Write Set REPlication补丁,使用Galera ...
- 使用percona xtradb cluster的IST方式添加新节点
使用percona xtradb cluster的IST(Incremental State Transfer)特性添加新节点,防止新节点加入时使用SST(State SnapShop Transfe ...
- mysql高可用之PXC(Percona XtraDB Cluster)
简介 Percona XtraDB Cluster是MySQL高可用性和可扩展性的解决方案,Percona XtraDB Cluster提供的特性如下: 1).同步复制,事务要么在所有节点提交或不提交 ...
- docker1.12 安装pxc(Percona XtraDB Cluster )测试
docker1.12 安装pxc(Percona XtraDB Cluster )测试
- 1.1 About Percona XtraDB Cluster
摘要: 出处:kelvin19840813 的博客 http://www.cnblogs.com/kelvin19840813/ 您的支持是对博主最大的鼓励,感谢您的认真阅读.本文版权归作者所有,欢迎 ...
- PXC5.7(Percona XtraDB Cluster)+HAproxy+Keepalived 集群部署
Percona-XtraDB-Cluster+Haproxy 搭建集群环境 环境准备及服务器信息: 配置防火墙 firewall-cmd --add-port=3306/tcp --permanent ...
- MySQL高可用方案-PXC(Percona XtraDB Cluster)环境部署详解
MySQL高可用方案-PXC(Percona XtraDB Cluster)环境部署详解 Percona XtraDB Cluster简称PXC.Percona Xtradb Cluster的实现是在 ...
随机推荐
- Spring的JavaMail实现异步发送邮件
具体背景就不说了,可以网上搜索相关知识,或者直接看Sping MailSender的官坊网页.这里就直接实战了(Java实现异步发送电子邮件,包含中文无乱码). Maven: <dependen ...
- 使用java调用fastDFS客户端进行静态资源文件上传
一.背景 上篇博客我介绍了FastDFS的概念.原理以及安装步骤,这篇文章我们来聊一聊如何在java中使用FastDFSClient进行静态资源的上传. 二.使用步骤 1.开发环境 spring+sp ...
- php -- 特殊变量的三种输出
----- 020-3outputs.php ----- <!DOCTYPE html> <html> <head> <meta http-equiv=&qu ...
- Shellexecute头文件
调用ShellExecute所需要头文件 #include "windows.h " #include "shellapi.h "
- sql-DDL, DML 常用语句
mysql的安装可见: http://www.cnblogs.com/wenbronk/p/6840484.html 很久不用mysql, 今天建表都不会了, , , 慢慢补充 sql语言分为3种: ...
- SpringBoot入门 (十三) WebSocket使用
本文记录在SpringBoot中使用WebSocket. 一 什么是WebSocket WebSocket是基于TCP协议的一种网络协议,它实现了浏览器与服务器全双工通信,支持客户端和服务端之间相互发 ...
- SOA,Webservice,SOAP,REST,RPC,RMI的区别与联系
SOA,Webservice,SOAP,REST,RPC,RMI的区别与联系 SOA面向服务的软件架构(Service Oriented Architecture) 是一种计算机软件的设计模式,主要应 ...
- <context:component-scan>子标签:<context:include-filter>和<context:exclude-filter>使用时要注意的地方
在Spring MVC中的配置中一般会遇到这两个标签,作为<context:component-scan>的子标签出现. 但在使用时要注意一下几点: 1.在很多配置中一般都会吧Spring ...
- Java Web 项目简单配置 Spring MVC进行访问
所需要的 jar 包下载地址: https://download.csdn.net/download/qq_35318576/10275163 配置一: 新建 springmvc.xml 并编辑如下内 ...
- Quartz2D简单图形
这些天一直准备学绘图和核心动画这块,可一直找不到合适系统的教材,没有大纲,比较纠结,在网上搜了又搜,看着其他的博文写的 第一遍来学习绘制简单的图形 // 若想利用Quartz 2D在View上绘制信息 ...