编写hadoop程序,并打包jar到hadoop集群运行
windows环境下编写hadoop程序
- 新建:File->new->Project->Maven->next
GroupId 和ArtifactId 随便写(还是建议规范点)->finfsh

会生成pom.xml,文件内容如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hadoopbook</groupId>
<artifactId>hadoop-demo</artifactId>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
- 可以网上找个wordCount(单词计数)源码进行测试,复制进去会发现以下的那些包都是报红,因为许多类都是无法识别的。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
接下来打开File->project Structure->Modules->右侧+->JARs or directories
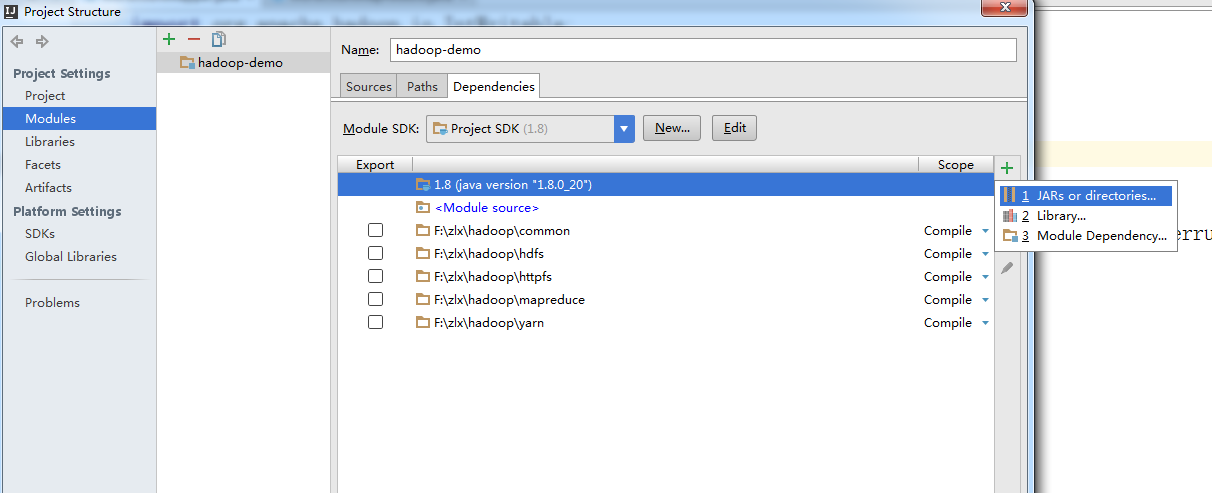
将你hadoop集群里面下载的jar包全部导入进去
点击左侧Arifacts ->+->JAR->empty
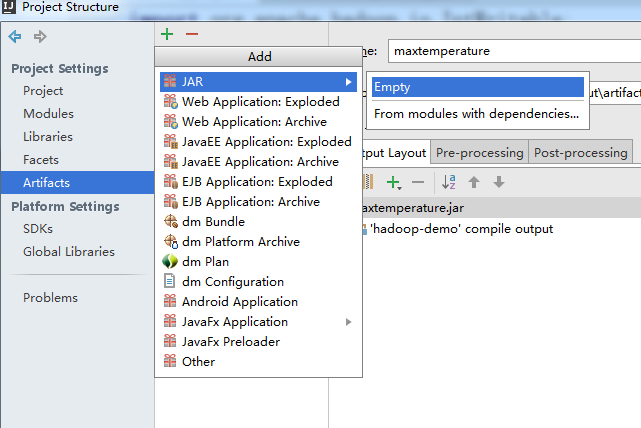
点击output layout下方的+,选择module output,然后勾选我们的项目,点击确定,这时报错的信息就没有了
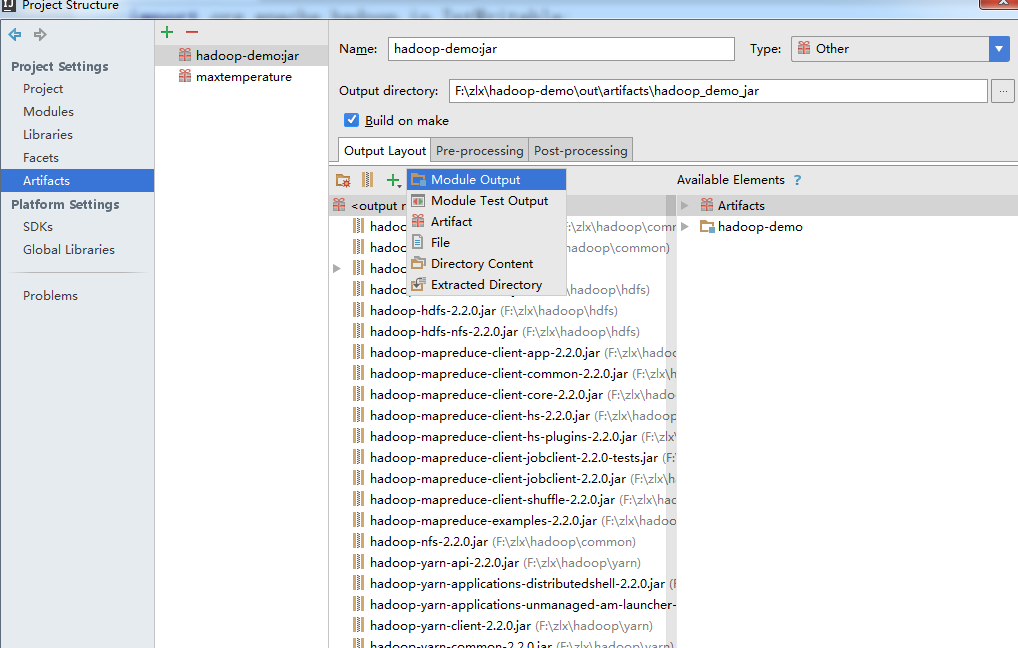
idea打包成jar
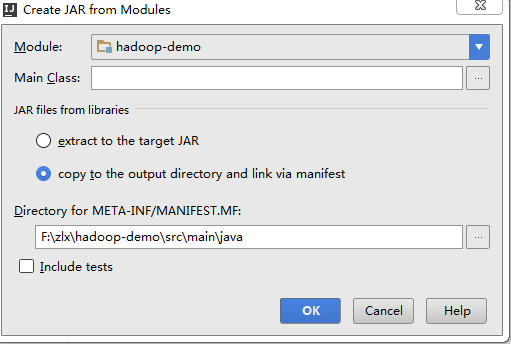
- File->project Structure->点击左侧Arifacts->+->JAR->From modules with dependenciestu,Build on make打上勾
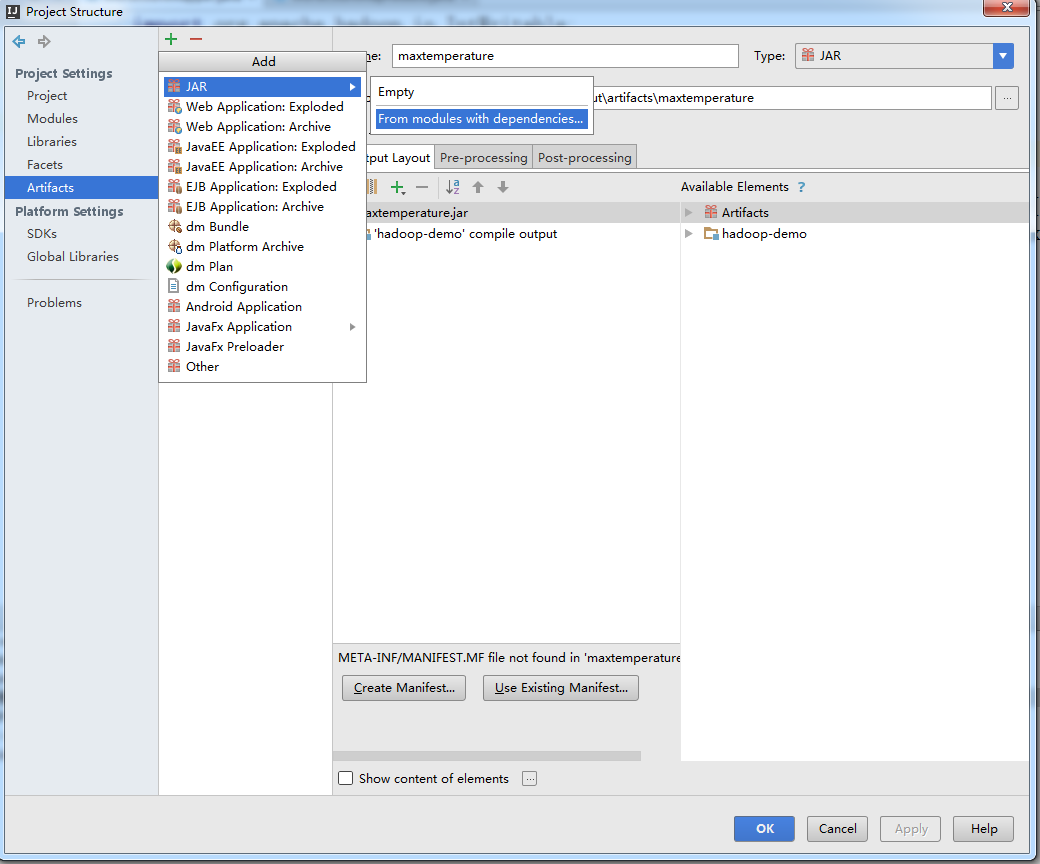
MAain.class为程序的主方法,相当于程序的入口
JAR files from libraries选第二个,选定输出路径->ok
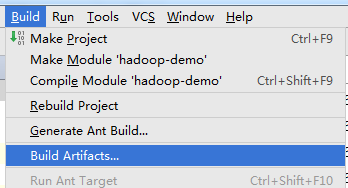
- Build->Build Arifacts->项目的jar->build->到输出路径查看即可。
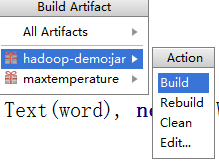
上传jar包到hadoop集群并运行
- 利用远程工具将生成的.jar上传到hadoop主节点的目录下(/app/hadoop/hadoop-2.2.0)目录根据自己的情况而定
- 创建input目录
hadoop fs -mkdir -p /usr/hadoop/input
- 复制本地文件到hdfs文件系统
hadoop fs -put test.txt /usr/hadoop/input
- 现在.jar有了,输入文件有了,执行.jar。切记不要自己手动提前新建输出文件
hadoop jar hadoop_demo_jar/hadoop-demo.jar workCount /usr/hadoop/input /usr/hadoop/output
- 执行成功

- 查看输出结果
hadoop fs -cat /usr/hadoop/output/*

HDFS常用命令可以参考这篇博客写得不错:https://blog.csdn.net/sunshingheavy/article/details/53227581
编写hadoop程序,并打包jar到hadoop集群运行的更多相关文章
- flink idea 打包jar 并放到集群上运行
flink idea 打包jar 并放到集群上运行 在开始之前注意前提,当前项目的scala的版本要和集群上的scala一致 我已经创建好一个wordCount的flink项目 注意项目的po ...
- MR程序本地调试,提交到集群运行
在本地调试,提交到集群上运行. 在本地程序中的Configuration中添加如下配置: Configuration conf = new Configuration(); conf.set(&quo ...
- 编写hadoop程序并打成jar包上传到hadoop集群运行
准备工作: 1. hadoop集群(我用的是hadoop-2.7.3版本),这里hadoop有两种:1是编译好的hadoop-2.7.3:2是源代码hadoop-2.7.3-src: 2. 自己的机器 ...
- Hadoop集群运行JNI程序
要在Hadoop集群运行上运行JNI程序,首先要在单机上调试程序直到可以正确运行JNI程序,之后移植到Hadoop集群就是水到渠成的事情. Hadoop运行程序的方式是通过jar包,所以我们需要将所有 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- hadoop本地运行与集群运行
开发环境: windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件) 介绍: 本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn 需要准备什么: 1/配置w ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- 简单说明hadoop集群运行三种模式和配置文件
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下: 1.独立模式即本地运行模式(standalone或local mode)无需运行任何守护进程(daemon) ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:安装zookeeper集群
实验目的 了解zookeeper的概念和原理 学会安装zookeeper集群并验证 掌握zookeeper命令使用 实验原理 1.Zookeeper介绍 ZooKeeper是一个分布式的,开放源码的分 ...
- hadoop一代集群运行代码案例
hadoop一代集群运行代码案例 集群 一个 master,两个slave,IP分别是192.168.1.2.192.168.1.3.192.168.1.4 hadoop版 ...
随机推荐
- Shell - 简明Shell入门03 - 字符串(String)
示例脚本及注释 #!/bin/bash str="Shell" str2="Hello $str !" str3="Hello ${str} !&qu ...
- Apache JMeter的基本使用
安装 安装地址:http://jmeter.apache.org/download_jmeter.cgi 解压后运行jmeter.bat的批处理文件就可以了 JMeter测试脚本编写: 1,创建线程组 ...
- 用AOP思想改造一个服务器的数据存储
背景是有一个游戏服务器一直以来都是写SQL的, 后来改过一段时间的redis, 用的是别的员工写的类orm方式将实体类型映射成各种key-value对进行写入, 但是仍有一个缺点就是需要在增\删\改的 ...
- (转) lsof 一切皆文件
原文:https://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/lsof.html lsof(list open files)是一个查看当前系统文 ...
- 抓包和测试Api类工具
1.PostMan 测试api 2.Fiddler4抓包工具使用教程一
- mysql基础知识(2)
十 一.计算字段 计算字段通常需要使用 AS 来取别名,否则输出的时候字段名为计算表达式 select col1*col2 as col12 from mytable concat() 用于连接两个字 ...
- VS2013编译的exe独立运行在XP中方案
转载知乎 现在,我们深入探讨一下:<如何使用VS 2013发布一个可以在Windows XP中独立运行的可执行文件>. 这个问题是比较常见且容易造成初学者困惑的,作为曾经撞了无数次南墙的初 ...
- 【奔走相告】- Github送福利:用户可免费创建私有代码库啦
最新消息 PingWest品玩1月8日讯,据TheNextWeb消息,据美国科技媒体The Next Web报道,被微软收购的代码平台GitHub最近调整政策,用户免费创建无限空间私有代码库(priv ...
- jmeter接口自动化部署jenkins教程
首先,保证本地安装并部署了jenkins,jmeter,xslproc 我搭建的自动化测试框架是jmeter+jenkins+xslproc ---注意:原理是,jmeter自生成的报告jtl文件,通 ...
- manjaro 添加当前用户到kvm
原贴 https://askubuntu.com/questions/1050621/kvm-is-required-to-run-this-avd Check the ownership of /d ...