吴裕雄 python 爬虫(3)
import hashlib md5 = hashlib.md5()
md5.update(b'Test String')
print(md5.hexdigest())
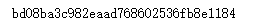
import hashlib md5 = hashlib.md5(b'Test String').hexdigest()
print(md5)
import os
import hashlib
import requests # url = "http://opendata.epa.gov.tw/ws/Data/REWXQA/?$orderby=SiteName&$skip=0&$top=1000&format=json"
url = "https://www.baidu.com" # 读取网页原始码
html=requests.get(url).text.encode('utf-8-sig')
# 判断网页是否更新
md5 = hashlib.md5(html).hexdigest()
if os.path.exists('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt'):
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt', 'r') as f:
old_md5 = f.read()
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt', 'w') as f:
f.write(md5)
else:
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt', 'w') as f:
f.write(md5) if md5 != old_md5:
print('数据已更新...')
else:
print('数据未更新,从数据库读取...')

import os
import ast
import hashlib
import sqlite3
import requests from bs4 import BeautifulSoup conn = sqlite3.connect('F:\\pythonBase\\pythonex\\DataBasePM25.sqlite') # 建立数据库连接
cursor = conn.cursor() # 建立 cursor 对象 # 建立一个数据表
sqlstr='''
CREATE TABLE IF NOT EXISTS TablePM25 ("no" INTEGER PRIMARY KEY AUTOINCREMENT
NOT NULL UNIQUE ,"SiteName" TEXT NOT NULL ,"PM25" INTEGER)
'''
cursor.execute(sqlstr) url = "http://api.help.bj.cn/apis/aqilist/"
#html=requests.get(url).text.encode('utf-8-sig') # 读取网页原始码
html=requests.get(url).text.encode('iso-8859-1').decode('utf-8-sig')
# print(html)
html = html.encode('utf-8-sig')
# 判断网页是否更新
md5 = hashlib.md5(html).hexdigest()
old_md5 = "" if os.path.exists('F:\\pythonBase\\pythonex\\ch06\\old_md5-.txt'):
with open('F:\\pythonBase\\pythonex\ch06\\old_md5-.txt', 'r') as f:
old_md5 = f.read()
with open('F:\\pythonBase\\pythonex\ch06\\old_md5-.txt', 'w') as f:
f.write(md5)
print("old_md5="+old_md5+";"+"md5="+md5) #显示新老md5码进行观察
if md5 != old_md5:
print('数据已更新...')
sp=BeautifulSoup(html,'html.parser') #解析网页内容
jsondata = ast.literal_eval(sp.text) #此时jscondata取到的是字典类型数据
# 删除数据表内容
js1=jsondata.get("aqidata") #取出字典数据中的aqidata项的值(值是列表)
conn.execute("delete from TablePM25")
conn.commit()
n=1
for city in js1: #city此时是列表js1中的第一条字典数据
CityName=city["city"] #取出city字典数据中的值为"city"的key
if(city["pm2_5"] == ""):
PM25=0
else: #如果city字典中的key对应的value为空,则PM25=0,否则,把PM25=value
PM25=int(city["pm2_5"])
print("城市:{} PM2.5={}".format(CityName,PM25)) #显示城市对应的名称与PM2.5值
# 新增一笔记录
sqlstr="insert into TablePM25 values({},'{}',{})" .format(n,CityName,PM25)
cursor.execute(sqlstr)
n+=1
conn.commit() # 主动更新
else:
print('数据未更新,从数据库读取...')
cursor=conn.execute("select * from TablePM25")
rows=cursor.fetchall()
for row in rows:
print("城市:{} PM2.5={}".format(row[1],row[2])) conn.close() # 关闭数据库连

........................................................

import os
import ast
import hashlib
import sqlite3
import requests from bs4 import BeautifulSoup # cur_path=os.path.dirname(__file__) # 取得目前路径
# print(cur_path)
conn = sqlite3.connect('F:\\pythonBase\\pythonex\\' + 'DataBasePM25.sqlite') # 建立数据库连接
cursor = conn.cursor() # 建立 cursor 对象 # 建立一个数据表
sqlstr='''
CREATE TABLE IF NOT EXISTS TablePM25 ("no" INTEGER PRIMARY KEY AUTOINCREMENT
NOT NULL UNIQUE ,"SiteName" TEXT NOT NULL ,"PM25" INTEGER)
'''
cursor.execute(sqlstr) url = "http://api.help.bj.cn/apis/aqilist/"
# 读取网页原始码
# html=requests.get(url).text.encode('utf-8-sig')
html=requests.get(url).text.encode('iso-8859-1').decode('utf-8-sig')
# print(html)
html = html.encode('utf-8-sig') print('数据已更新...')
sp=BeautifulSoup(html,'html.parser') #sp是bs4.Beautifulsoup类
# 将网页内转换为 list,list 中的元素是 dict
jsondata = ast.literal_eval(sp.text) #把sp.text字符串转为dict类型
js=jsondata.get("aqidata") #从jasondata中取出值为"aqidata"的key对应的value的列表 # 删除数据表内容
conn.execute("delete from TablePM25")
conn.commit() #把抓到的数据逐条存到数据库
n=1
for city in js:
CityName=city["city"]
PM25=0 if city["pm2_5"] == "" else int(city["pm2_5"])
print("城市:{} PM2.5={}".format(CityName,PM25))
# 新增一条记录
sqlstr="insert into TablePM25 values({},'{}',{})" .format(n,CityName,PM25)
cursor.execute(sqlstr)
n+=1
conn.commit() # 主动更新
conn.close() # 关闭数据库连

from time import sleep
from selenium import webdriver urls = ['http://www.baidu.com','http://www.wsbookshow.com','http://news.sina.com.cn/'] browser = webdriver.Chrome()
browser.maximize_window
for url in urls:
browser.get(url)
sleep(3) browser.quit()
from selenium import webdriver #导入webdriver url='http://www.wsbookshow.com/bookshow/jc/bk/cxsj/12442.html' #以此链接为例
browser=webdriver.Chrome() #生成Chrome浏览器对象(结果是打开Chrome浏览器)
browser.get(url) #在浏览器中打开url
login_form=browser.find_element_by_id("menu_1") ##查找id="menu_1"的元素
print(login_form.text) #显示元素内容
#browser.quit() #退出浏览器,退出驱动程序
username=browser.find_element_by_name("username") #查找name="username"的元素
print(username)
password=browser.find_element_by_name("pwd") #查找name="pwd"的元素
print(password)
login_form=browser.find_element_by_xpath("//input[@name='arcID']")
print(login_form)
login_form=browser.find_element_by_xpath("//div[@id='feedback_userbox']")
print(login_form)
continue_link=browser.find_element_by_link_text('新概念美语')
print(continue_link)
continue_link=browser.find_element_by_link_text('英语')
print(continue_link)
heading1=browser.find_element_by_tag_name('h1')
print(heading1)
content=browser.find_elements_by_class_name('topbanner')
print(content)
content=browser.find_elements_by_css_selector('.topsearch')
print(content)
# print(content.get_property)
print()
browser.quit() #退出浏览器,退出驱动程序

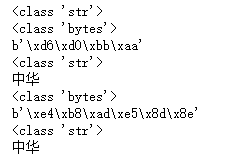
text = '中华'
print(type(text))#<class 'str'>
text1 = text.encode('gbk')
print(type(text1))#<class 'bytes'>
print(text1)#b'\xd6\xd0\xbb\xaa'
text2 = text1.decode('gbk')
print(type(text2))#<class 'str'>
print(text2)#中华 text4= text.encode('utf-8')
print(type(text4))#<class 'bytes'>
print(text4)#b'\xe4\xb8\xad\xe5\x8d\x8e'
text5 = text4.decode('utf-8')
print(type(text5))#<class 'str'>
print(text5)#中华
import requests url="http://www.baidu.com"
response = requests.get(url)
content = response.text.encode('iso-8859-1').decode('utf-8')
#把网页源代码解码成Unicode编码,然后用utf-8编码
print(content)

from selenium import webdriver # 导入webdriver模块 chrome_obj = webdriver.Chrome() # 打开Google浏览器
chrome_obj.get("https://www.baidu.com") # 打开 网址
print(chrome_obj.title)
from selenium import webdriver # 导入webdriver模块 chrome_obj = webdriver.Chrome() # 打开Google浏览器 chrome_obj.get(r"C:\desktop\text.html") # 打开本地 html页面
吴裕雄 python 爬虫(3)的更多相关文章
- 吴裕雄 python 爬虫(4)
import requests user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, li ...
- 吴裕雄 python 爬虫(2)
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com' html = requests.get(url) ...
- 吴裕雄 python 爬虫(1)
from urllib.parse import urlparse url = 'http://www.pm25x.com/city/beijing.htm' o = urlparse(url) pr ...
- 吴裕雄--python学习笔记:爬虫基础
一.什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息. 二.Python爬虫架构 Python 爬虫架构主要由五个部分组成,分别是调度器.URL管理器.网页下载器.网 ...
- 吴裕雄--python学习笔记:爬虫包的更换
python 3.x报错:No module named 'cookielib'或No module named 'urllib2' 1. ModuleNotFoundError: No module ...
- 吴裕雄--python学习笔记:爬虫
import chardet import urllib.request page = urllib.request.urlopen('http://photo.sina.com.cn/') #打开网 ...
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- css初探
CSS 语法 CSS 规则由两个主要的部分构成:选择器,以及一条或多条声明. selector { property: value; ...
- 一篇文章,教你学会Git
在日常工作中,经常会用到Git操作.但是对于新人来讲,刚上来对Git很陌生,操作起来也很懵逼.本篇文章主要针对刚开始接触Git的新人,理解Git的基本原理,掌握常用的一些命令. 一.Git工作流程 以 ...
- es6基础(2)--解构赋值
//解构赋值 { let a,b,rest; [a,b]=[1,2]; console.log(a,b); } //数组解构赋值 { let a,b,rest; [a,b,...rest]=[1,2, ...
- Uncaught (in promise) DOMException: Failed to execute 'open' on 'XMLHttpRequest': Invalid URL
解决方案:url前面一定要加http://
- 【Eclipse】如何在Eclipse中如何自动添加注释和自定义注释风格
背景简介 丰富的注释和良好的代码规范,对于代码的阅读性和可维护性起着至关重要的作用.几乎每个公司对这的要求还是比较严格的,往往会形成自己的一套编码规范.但是再实施过程中,如果全靠手动完成,不仅效率低下 ...
- uiautomator 代码记录 : 随机发送短信
package sms_test; import java.lang.*; import java.util.Random; import javax.microedition.khronos.egl ...
- 修改json文件
第三方库jq https://stedolan.github.io/jq/manual/ cat old_deploy.json \ | jq --arg cpu_limit $cpu_limit ' ...
- python tkinter chk
视频过程中的练习, 可以在python2.7下运行. 001: hello,world: 1 2 3 4 5 6 from Tkinter import Label, Tk root = Tk() t ...
- 笔记:Sublime Text 3
http://www.sublimetext.com/3 Sublime Text官网 http://www.sublimetextcn.com/3/ Sublime Text中文官网 http:// ...
- #Weex与Android交互(一)
用Weex开发Android程序 参考:开发HelloWorld程序(Weex开发) 1.创建Android工程 2.集成WeexSDK,参考[WEEX SDK 集成到 Android 工程](htt ...