Django--ORM(模型层)--多表(重重点)
一、数据库表关系
单表
重复的字段太多,所以需要一对多,多对多来简化

多表
多对一 多对多 一对一 =============================================== 一对多:
Book
id title price publish_id
1 php 100 1
2 python 200 1
3 go 300 2
Publish
id name email addr
1 人名出版社 @ 北京
2 沙河出版社 @ 沙河 一旦确定是 一对多
怎么建立一对多的关系?---》 关联字段 ,建在‘多’的表中 查询python这本书的出版社的邮箱
(子查询)
select email from Publish where id = (
select publish_id from Book where title = 'python'
) =============================================== 多对多:(彼此一对多)
Book
id title price publish_id
1 php 100 1
2 python 200 1
3 go 300 2
Author
id name age addr
1 alex 34 beijing
2 egon 29 nanjing
Book2Author
id book_id author_id
1 2 1
2 2 2
3 3 2 alex 出版过的书籍名称 (子查询:以一个查询的结果作为下一个查询的条件)
select title from Book where id in (
select book_id from Book2Author where author_id = (
select id from Author where name = 'alex'
)
) =============================================== 一对一:
Author
id name age authordetail_id(unique) (一定要加)
1 alex 34 1
2 egon 29 2
AuthorDetail (这个信息不经常查,为了效率,扩展)
id addr gender tel gf_name
1 beijing male 110 小花
2 nanjing male 911 红花 =============================================== 总结:
一旦确定是 一对多
怎么建立一对多的关系?---》 关联字段 ,建在‘多’的表中
一旦确定是 多对多
怎么建立多对多的关系?---》 创建第三张表(关联表): id 和 两个关联字段
一旦确定是 一对一
怎么建立一对一的关系?---》 在两张表中的任意一张表中建立关联字段 + unique Publish
Book
AuthorDetail
Author
Book2Author
=====================================================
create table publish(
id int primary key auto_increment,
name varchar(20)
);
create table book(
id int primary key auto_increment,
title varchar(20),
price decimal(8,2),
pub_date date,
publish_id int,
foreign key (publish_id) references publish(id)
);
create table authordetail(
id int primary key auto_increment,
tel varchar(20)
);
create table author(
id int primary key auto_increment,
name varchar(20),
age int,
authordetail_id int unique,
foreign key (authordetail_id) references authordetail(id)
);
create table book2author(
id int primary key auto_increment,
book_id int,
author_id int
); =====================================================
pycharm自带 database配置--sqlite3



orm参数
https://www.cnblogs.com/liwenzhou/p/8688919.html
二、ORM生成关联表模型
''
Book
Publish
Author
AuthorDetail
Book2Author 会自定生成 Book -- Publish 一对多
Author -- AuthorDetail 一对一
Book -- Author 多对多 Book2Author '''
from django.db import models # 作者详情表
class AuthorDetail(models.Model):
nid = models.AutoField(primary_key=True)
birthday = models.DateField()
telephone = models.BigIntegerField()
addr = models.CharField(max_length=64) class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField() # 一对一 关系 这里会生成一个字段 authordetail_id
authordetail = models.OneToOneField(to='AuthorDetail',to_field='nid',on_delete=models.CASCADE) class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField() # def __str__(self): # 打印的时候 可以打印出name
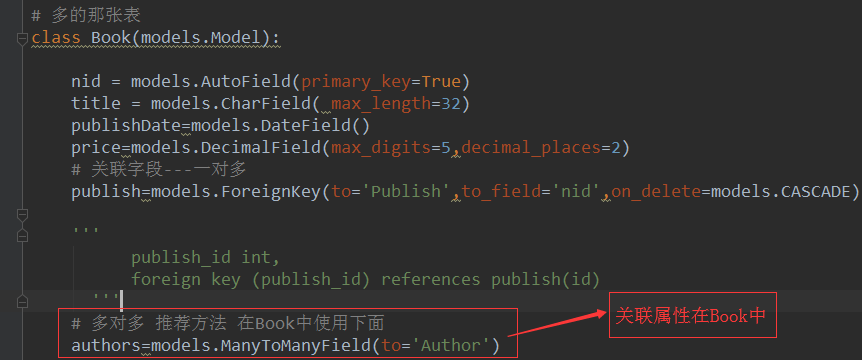
# return self.name class Book(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField(max_length=32)
publishDate = models.DateField()
price = models.DecimalField(max_digits=8,decimal_places=2) # 一对多 关系 # 这里会生成一个 字段 publish_id
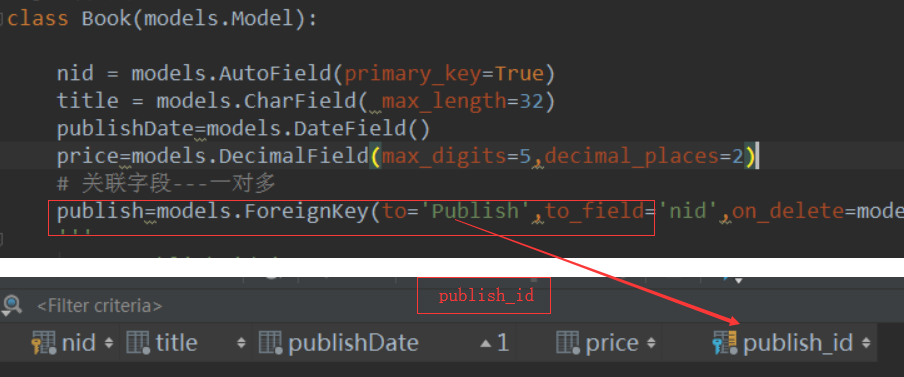
publish = models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE)
'''
publish_id int,
foreign key (publish_id) references publish(id)
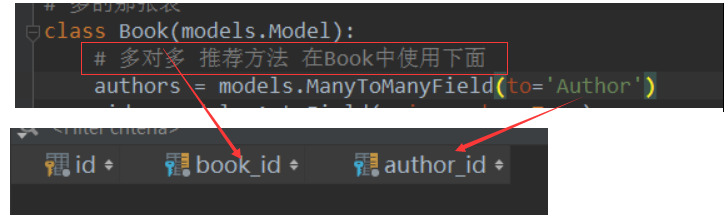
''' # 多对多 # 这里会生成第三张表 book_authors
authors = models.ManyToManyField(to='Author')
'''
create table book_authors(
id int primary key auto_increment,
book_id int,
author_id int
);
''' def __str__(self):
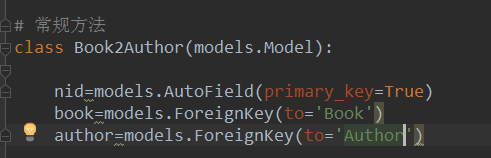
return self.title # 这里生成第三张表的本质 # django 去写不用我们写
# class Book2Author(models.Model):
# nid = models.AutoField(primary_key=True)
# book = models.ForeignKey(to='Book') # 默认关联主键
# author = models.ForeignKey(to='Author') '''
数据库迁移
python manage.py makemigrations
python manage.py migrate
''' '''
注:
# 这就是django2.0问题
authordetail = models.OneToOneField(to='AuthorDetail',to_field='nid')
TypeError: __init__() missing 1 required positional argument: 'on_delete'
解决办法:
authordetail = models.OneToOneField(to='AuthorDetail',to_field='nid',on_delete=models.CASCADE)
publish = models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE) 需要加上 on_delete = models.CASCADE django1 默认加上了 on_delete '''

多对多创建方法:

# 级联删除字段必须加否则创建时报错 on_delete=models.CASCADE 一对多 一对一
publish = models.ForeignKey(to=Publish, to_field='nid', on_delete=models.CASCADE)
authordeatil = models.OneToOneField(to="AuthorDetail", to_field="nid", on_delete=models.CASCADE)
# authors = models.ManyToManyField(to="Author") 多对多 不会报错
利用pycharm自带的sqlite数据库 python manage.py makemigrations
python manage.py migrate
生成数据库表:

注意事项:
- 表的名称
myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称 id字段是自动添加的- 对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
- 这个例子中的
CREATE TABLESQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。 - 定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加
models.py所在应用的名称。 - 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
多表操作 添加记录
1.单表
from app01.models import *
def add(request):
pub=Publish.objects.create(name='人民出版社',email='123@qq.com',city='武汉')
return HttpResponse('OK')

表的创建关系

================一对多====================
方式一:
# 为book表绑定关系 book---------publish
book_obj=Book.objects.create(title='红楼梦',price=100,publishDate='2012-1-1',publish_id=1)
print(book_obj.title)

方式二:
# 方式2
# publish_obj = Publish.objects.filter(id=2).first() # 没有id属性
publish_obj = Publish.objects.filter(nid=2).first() # 先查找publish_obj 对象 book_obj = Book.objects.create(
title='红楼梦',
price=200,
publishDate="2012-11-11",
publish=publish_obj,#出版社对象
)
print(book_obj.title)
print(book_obj.price)
print(book_obj.publishDate)
print(book_obj.publish) # 与这本书关联的出版社对象
print(book_obj.publish.email) # 出版社对象,可以继续 使用 点方法
print(book_obj.publish_id)
每张表加



查询 出版 三国演义 出版社的邮箱

=============================绑定多对多的关系==================================
from django.shortcuts import render,HttpResponse
from app01.models import *
def add(request):
# 单表
pub = Publish.objects.create(name='人名出版社',city='陕西',email='1234@qq.com')
# =============================绑定一对多的关系==================================
# 方式一 book -- publish
book_obj = Book.objects.create(title='西游记',publishDate='2012-12-1',price=100,publish_id=1)
print(book_obj.title) # 西游记
print(book_obj.publish) # Publish object (1)
print(book_obj.publish_id) #
# 方式二
pub_obj = Publish.objects.filter(nid = 2).first() # 对象
book_obj = Book.objects.create(title='放风筝得人',publishDate='2012-1-2',price=150,publish=pub_obj)
print(book_obj.title) # 放风筝得人
print(book_obj.price) #
print(book_obj.publish_id) #
print(book_obj.publish) # Publish object (3)
print(book_obj.publish.name) # 人名出版社
print(book_obj.publish.city) # 陕西
# 查询西游记这本书,出版社对应的邮箱
book_obj = Book.objects.filter(title='西游记').first()
print(book_obj.publish.email) # yuan@163.com
# =============================绑定多对多的关系==================================
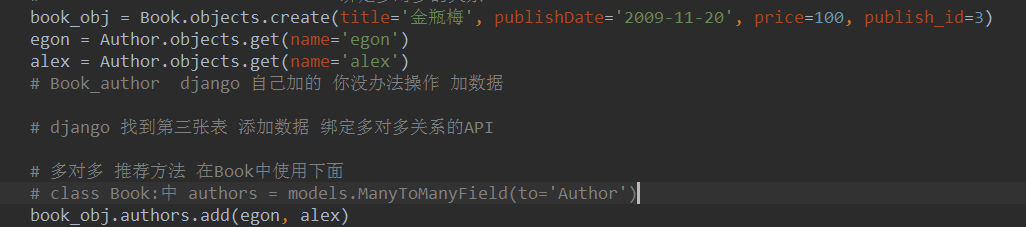
book_obj = Book.objects.create(title='西游记',publishDate='2009-11-20',price=100,publish_id=3)
egon = Author.objects.get(name='egon')
alex = Author.objects.get(name='alex')
# Book_author django 自己加的 你没办法操作 加数据
# django 找到第三张表 添加数据 绑定多对多关系的API
book_obj.authors.add(egon,alex)
book_obj.authors.add(1,2)
book_obj.authors.add(*[1,2]) # # 等效于 传位置参数时 加 *
# 解除 多对多的 关系
book_obj = Book.objects.filter(nid=4).first()
book_obj.authors.remove(2)
book_obj.authors.remove(1,2)
book_obj.authors.remove(*[1,2])
# 全解除
book_obj.authors.clear()
# 查询出所有作者对象集合
print(book_obj.authors.all()) # #queryset [obj1.obj2] # 与这本书关联的所有作者对象
# 查询主键为4 的书籍的 所有作者的名字
print(book_obj.authors.all().values('name')) # # <QuerySet [{'name': 'alex'}, {'name': 'egon'}]>
总体概况
手动添加



----
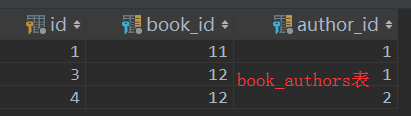
给同一本书添加两个作者
book表中 :


book_authors表中:


解除多对多的关系

在book_authors表中:book_id=11 ,作者id=2的被删除
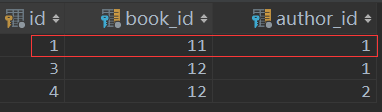
# 解除 多对多的 关系
book_obj = Book.objects.filter(nid=11).first()
book_obj.authors.remove(2) #删除作者id=2
book_obj.authors.remove(1, 2) # 删除作者id=1,2
book_obj.authors.remove(*[1, 2])
# 全解除
book_obj.authors.clear()
# 查询出所有作者对象集合
print(book_obj.authors.all()) # #queryset [obj1.obj2] # 与这本书关联的所有作者对象 # 查询主键为4 的书籍的 所有作者的名字
print(book_obj.authors.all().values('name')) # # <QuerySet [{'name': 'alex'}, {'name': 'egon'}]>
重点:
# 关联字段---一对多
class Book:publish=models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE)
print(book_obj.publish) # Publish object (3) # 与这本书关联的出本社对象
# 查询出所有作者对象集合
print(book_obj.authors.all()) # #queryset [obj1.obj2] # 与这本书关联的所有作者对象
http://www.cnblogs.com/yuanchenqi/articles/8963244.html http://www.cnblogs.com/yuanchenqi/articles/8978167.html add(obj1[, obj2, ...]) create(**kwargs) remove(obj1[, obj2, ...]) clear() set()方法 对于所有类型的关联字段,add()、create()、remove()和clear(),set()都会马上更新数据库。换句话说,在关联的任何一端,都不需要再调用save()方法
查询 - 基于对象 - 跨表--重点-难点
一对多查询(Publish 与 Book)
正向查询(按字段:publish):
基于对象的跨表查询 (子查询)
def query(request):
"""
跨表查询:
1.基于对象查询
2.基于双下划线查询
3.聚合、分组查询
4. F Q 查询
""" # ----基于对象的跨表查询(子查询)
# 1.一对多查询(publish与book) """
# 一对多查询
正向查询:按字段
反向查询:表名小写_set.all()
如果关联属性在中A,由A查B就是正向查询
正向查询按字段查询;反向查询按表名小写_set.all() #queryset
book_obj.publish
Book(关联属性:publish)对象 --------------> Publish对象
<--------------
publish_obj.book_set.all() # queryset """
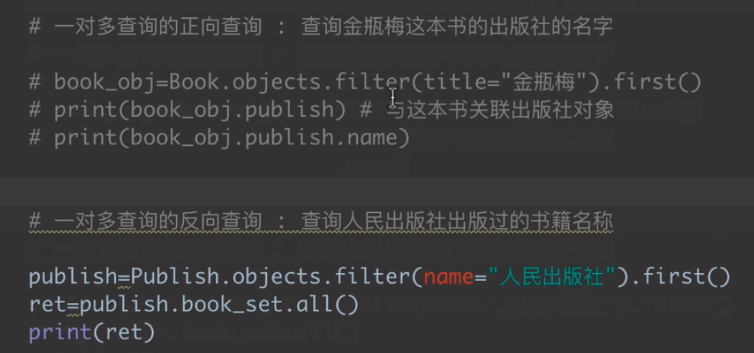
# 正向查询:查询三国演义这本书的出版社的名字
book_obj = Book.objects.filter(title='').first()
publish_obj = book_obj.publish # 与这本书关联的出版社对象
publish_name = publish_obj.name
print(publish_name) # 南京出版社 # 反向查询:查询人民出版社出版的书籍名称
publish_obj = Publish.objects.filter(name='人民出版社').first()
books_obj = publish_obj.book_set.all()
print(books_obj) # <QuerySet [<Book: 三国演义>, <Book: 西方文学史>, <Book: 美国文学史>]>
# print(books_obj.title) #error 'QuerySet' object has no attribute 'title' # 2.多对多
"""
# 多对多查询
正向查询:按字段
反向查询:表名小写_set.all() book_obj.authors.all()
Book(关联属性:authors)对象 ------------------------> Author对象
<------------------------
author_obj.book_set.all() # queryset """
# 正向查询:查询三国演义这本书的所有作者
book_obj=Book.objects.filter(title='三国演义').first()
authors_list = book_obj.authors.all()
print(authors_list) # QuerySet对象 <QuerySet [<Author: alex>, <Author: jack>]> for author in authors_list:
print(author.name) # 反向查询:查询alex出版过的所有书籍名称
author_obj = Author.objects.filter(name='alex').first()
books_list = author_obj.book_set.all()
print(books_list)
for book in books_list:
print(book.title) # 3. 一对一
"""
# 一对一查询


正向查询:按字段
反向查询:表名小写 author.authordetail
Author(关联属性:authordetail)对象 ------------------------>AuthorDetail对象
<------------------------
authordetail.author """
# 正向查询:查询alex的手机号
author_obj = Author.objects.filter(name='alex').first()
phone = author_obj.authordetail.telephone # 与author关联的authordetail对象
print(phone) # 反向查询:查询手机号为110的作者的名字和年龄
ad_obj = AuthorDetail.objects.filter(telephone="").first()
name = ad_obj.author.name # 关联的对象author
age = ad_obj.author.age
print(name, age) return HttpResponse("查询成功")
查询 - 基于双下划线(join)- 跨表

Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。
要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的 model 为止。
关键点:正向查询按字段,反向查询按表名。
一对多查询
# 正向查询 按字段:publish
queryResult=Book.objects
.filter(publish__name="苹果出版社")
.values_list("title","price")
# 反向查询 按表名:book
queryResult=Publish.objects
.filter(name="苹果出版社")
.values_list("book__title","book__price")
多对多查询:
利用正向和反向查询一个结果,关键看怎么断句

def joinquery(request):
# ----基于双下划线的跨表查询(join查询)
"""
正向查询按字段, 告诉ORM引擎join哪张表
反向查询按表名小写, 告诉ORM引擎join哪张表
"""
# 1.一对多查询: # 查询金2瓶梅这本书的出版社的名字
# 正向查询:
ret = Book.objects.filter(title='水浒').values('publish__name')
print(ret) # <QuerySet [{'publish__name': '南京出版社'}]>
# 反向查询:
ret = Publish.objects.filter(book__title='水浒').values('name')
print(ret) # <QuerySet [{'authors__name': 'alex'}, {'authors__name': 'jack'},
# 2.多对多 查询金2瓶梅这本书的所有作者的名字
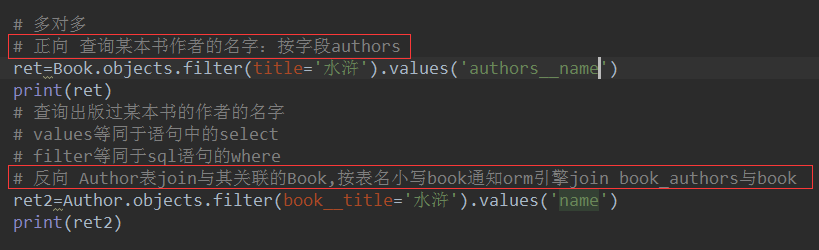
# 正向查询:
# 需求:通过Book表join与其关联的Author表,属于正向查询:按字段authors通知ORM引擎join book_author与author表
ret = Book.objects.filter(title='水浒').values('authors__name')
print(ret)
# 反向查询
# 需求:通过Author表join与其关联的Book表,属于反向查询:按表名小写book通知ORM引擎join book_authors与book表
ret = Author.objects.filter(book__title='水浒').values('name')
print(ret) # <QuerySet [{'name': 'alex'}, {'name': 'jack'}]>
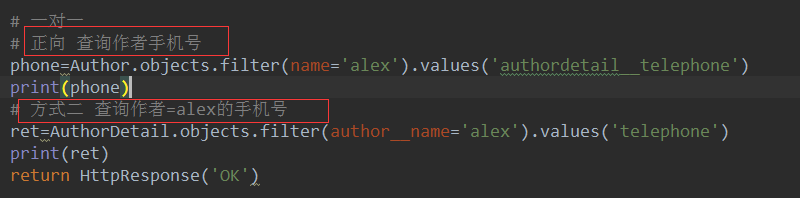
# 3. 一对一 # 查询alex的手机号
# 正向查询:
# 需求:通过Author表join与其相关联的AuthorDetail表,属于正向查询:按字段authordetail通知ORM join AuthorDetail表
ret = Author.objects.filter(name='alex').values('authordetail__telephone')
print(ret)
# 反向查询:
# 需求:通过AuthorDetail表join与其相关联的Author表,属于反向查询:按表名小写author通知ORM join Author表
ret = AuthorDetail.objects.filter(author__name='alex').values('telephone')
print(ret)
return HttpResponse('join查询成功')
一对一:

进阶联系---连续跨表
# 练习:手机号以100开头的作者出版过的所有书籍名称以及书籍出版社名称
# Book.objects.filter() ret=Author.objects.filter(authordetail__telephone=110).values('book__title','book__publish__name')
print(ret)
<QuerySet [{'book__title': '水浒', 'book__publish__name': '北京出版社'}, {'book__title': '三国', 'book__publish__name': '北京出版社'}]>
[
-----
# 以书籍为基准
# 通过Book表--作者--join AuthorDetail ,Book与AuthorDetail无关联,所以必须练习跨表
ret2=Book.objects.filter(authors__authordetail__telephone=110).values('title','publish__name')
print(ret2)
<QuerySet [{'title': '水浒', 'publish__name': '北京出版社'}, {'title': '三国', 'publish__name': '北京出版社'}]>
聚合查询与分组查询
聚合 aggregate(*args, **kwargs)
from django.db.models import Avg,Max,Min,Sum,Count
# 查询所有书籍的平均价格
ret=Book.objects.all().aggregate(Avg('price'),Max('price'),Min('price'))
print(ret) # 查询出出版社的数量
ret2=Publish.objects.aggregate(Count('nid'))
print(ret2)
{'price__avg': 104.16666666666667, 'price__max': Decimal('150'), 'price__min': Decimal('100')}
{'nid__count': 3}
分组查询
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)

在pycharm的Terminal执行
python manage.py makemigrations
python manage.py migrate

#==================单表=======================
# 查询每一个部门的名称以及员工的平均薪水
# select dep,Avg(salary) from emp group by dep
# annotate()
# 为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
from django.db.models import Avg, Max, Min, Sum, Count
ret=Emp.objects.values('dep').annotate(Avg('salary'))
print(ret) # 单表分组查询的ORM语法:单表模型.objects.values('group by的字段').annotate(聚合函数('统计字段')) # 实例二
# 查询每一个省份的名称以及对于的员工数
# values('province')---values('group by的字段')
ret2=Emp.objects.values('province').annotate(Count('id'))
print(ret2) # 补充知识点Emp.objects.all()-----select * from emp
# 补充知识点Emp.objects.all().values('name')-----select name from emp # 单表下按主键分组是没有意义的
#==============分组查询-----多表=========================
跨表的分组查询:
Book表
id title date price publish_id
1 红楼梦 2012-12-12 101 1
2 西游记 2012-12-12 101 1
3 三国演绎 2012-12-12 101 1
4 金2瓶梅 2012-12-12 301 2
Publish表
id name addr email
1 人民出版社 北京 123@qq.com
2 南京出版社 南京 345@163.com
分组查询sql:
select publish.name,Count("title") from Book inner join Publish on book.publish_id=publish.id
group by publish.id,publish.name,publish.addr,publish.email
思考:如何用ORM语法进行跨表分组查询
# 总结 跨表的分组查询的模型: 使用的时候用模型,理解用sql语句
# 每一个后的表模型.objects.values("pk").annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段") # 推荐pk字段查找 # 每一个后的表模型.objects.annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段")

# 不需要分组的情况 查询每一个出版社出版的书籍个数
from django.db.models import Avg, Max, Min, Sum, Count
ret=Book.objects.values('publish_id').annotate(Count('nid'))
print(ret) # 查询每一个出版社的名称以及出版的书籍个数
#
ret2=Publish.objects.values('name').annotate(Count('book__title'))
print(ret2) # 用主键 id 进行分组
ret3=Publish.objects.values('nid').annotate(c=Count('book__title')).values('name','c')
print(ret3)
ret:<QuerySet [{'publish_id': 1, 'nid__count': 3}, {'publish_id': 2, 'nid__count': 1}]>
ret2:<QuerySet [{'name': '人民出版社 ', 'book__title__count': 3}, {'name': '南京出版社', 'book__title__count': 1}]>
ret3:<QuerySet [{'name': '人民出版社 ', 'c': 3}, {'name': '南京出版社', 'c': 1}]>
---------------------------------------------------------------------------
# 示例1:查询每个出版社的名称以及出版的书籍的个数
ret = Publish.objects.values('nid').annotate(count=Count('book__title'))
print(ret) # <QuerySet [{'nid': 1, 'count': 3}, {'nid': 2, 'count': 3}, {'nid': 3, 'count': 0}, {'nid': 4, 'count': 0}]> ret = Publish.objects.values('name').annotate(count=Count('book__title'))
print(ret) # <QuerySet [{'name': '人民出版社', 'count': 3}, {'name': '南京出版社', 'count': 3}]> # 推荐主键pk查找
Publish.objects.values('pk').annotate(c=Count('book__title')).values('name', 'c')
print(ret) # <QuerySet [{'name': '人民出版社', 'count': 3}, {'name': '南京出版社', 'count': 3}]> # 示例2:查询每一个作者的名字以及出版过的书籍的最高价格
ret = Author.objects.values('pk').annotate(max_price=Max('book__price')).values('name', 'max_price')
print(ret) # <QuerySet [{'name': 'alex', 'max_price': Decimal('200.00')}, {'name': 'jack', 'max_price': Decimal('200.00')}]> # 示例3: 查询每一个书籍的名称以及对应的作者个数
ret = Book.objects.values('pk').annotate(c=Count('authors__nid')).values('title','c')
print(ret)
跨表查询方式2
# ---------跨表分组查询的另一种玩法 ------------
# 示例1:查询每个出版社的名称以及出版的书籍的个数
ret = Publish.objects.all().annotate(c=Count('book__title')).values('name','c')
print(ret) # <QuerySet [{'name': '人民出版社', 'c': 3}, {'name': '南京出版社', 'c': 3}, {'name': '人民出版社', 'c': 0}, {'name': '南京出版社', 'c': 0}]> # value为什么可以取出来?取出来的是对象
ret = Publish.objects.values('nid').annotate(c=Count('book__title'))
print(ret) # <QuerySet [{'nid': 1, 'c': 3}, {'nid': 2, 'c': 3}, {'nid': 3, 'c': 0}, {'nid': 4, 'c': 0}]> # values可以取出Publish表的每个字段 + 聚合字段
ret = Publish.objects.values('nid').annotate(c=Count('book__title')).values()
print(ret)
# <QuerySet [{'nid': 1, 'name': '人民出版社', 'city': 'beijing', 'email': '123@qq.com', 'c': 3}, {'nid': 2, 'name': '南京出版社', 'city': 'nanjing', 'email': '456@qq.com', 'c': 3}, ]>
练习:
# ########## 练习#############
# 每一个后的表模型.objects.values("pk").annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段") # 推荐pk字段查找 # 统计每一本以py开头的书籍的作者个数:
#ret = Book.objects.values('pk').annotate(c=Count('authors__nid')).filter(title__startswith='py').values('c')
ret = Book.objects.filter(title__startswith='金').values('pk').annotate(c=Count('authors__nid')).values('title','c')
print(ret) # <QuerySet [{'name': 'alex', 'book__title': '大话设计模式'}, {'name': 'alex', 'book__title': '金2瓶梅'}, {'name': 'jack', 'book__title': '大话设计模式'}, {'name': 'jack', 'book__title': '金2瓶梅'}]> # 统计不止一个作者的图书
ret = Author.objects.values('pk').annotate(Count('book__nid')).values('name','book__title')
print(ret) # <QuerySet [{'book__title': '大话设计模式'}, {'book__title': '金2瓶梅'}, {'book__title': '大话设计模式'}, {'book__title': '金2瓶梅'}]> ret = Book.objects.values('pk').annotate(c=Count('authors__name')).filter(c__gt=1).values('title','c')
print(ret) # <QuerySet [{'title': '大话设计模式', 'c': 2}, {'title': '金2瓶梅', 'c': 2}]>

F查询与Q查询
添加数据

更新表结构
在pycharm的Terminal执行 python manage.py makemigrations python manage.py migrate
运行结果:

F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
#示例1: 评论数大于阅读数的书籍
# Book.objects.filter(comment_num__gt=read_num)
from django.db.models import F
ret = Book.objects.filter(comment_num__gt=F('read_num'))
print(ret) # 示例2:所有书籍的价格+1
# Book.objects.all().update(price+=1)
# Book.objects.all().update(price=price+1)
Book.objects.all().update(price=F('price')+1)
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
from django.db.models import Q
Q(title__startswith='Py')
# 与或非
from django.db.models import Q # 与
ret1 = Book.objects.filter(title='水浒传', price=106)
print(ret1) # <QuerySet [<Book: 水浒传>]>
ret2 = Book.objects.filter(Q(title='水浒传') & Q(price=106))
print(ret2) # <QuerySet [<Book: 水浒传>]> # 或
ret = Book.objects.filter(Q(title='红楼梦') | Q(price=106))
print(ret) # <QuerySet [<Book: 水浒传>, <Book: 西游记>, <Book: 红楼梦>, <Book: 金2瓶梅>]> # 非
ret = Book.objects.filter(~Q(price=106))
print(ret) # <QuerySet [<Book: 红楼梦>, <Book: 大话设计模式>, <Book: 金2瓶梅>]> # Book.objects.filter(comment_num__gt=100, ~(Q(title='红楼梦') | Q(price=106))) # Q查询需要放到最后面
Book.objects.filter(~(Q(title='红楼梦')|Q(price=106)),comment_num__gt=100)
Django--ORM(模型层)--多表(重重点)的更多相关文章
- 第五章、Django之模型层----多表查询
目录 第五章.Django之模型层----多表查询 一.一对多字段增删改查 1.增 2.查 3.改 4. 删除 二.多对多的增删改查 1. 增 2. 改 3. 删 三.ORM跨表查询 四.正反向的概念 ...
- 第五章、Django之模型层---单表操作
目录 第五章.Django之模型层---单表操作 一.ORM查询 二.Django测试环境搭建 三.单表查询 1. 增 2. 改 3. 删 4. 查 第五章.Django之模型层---单表操作 一.O ...
- Django之模型层:表操作
目录 Django之模型层:表操作 一.ORM简介 django测试环境搭建 Django终端打印SQL语句 二 单表操作 2.1 按步骤创建表 2.2记录 三.多表操作 1 创建模型 2 添加.删除 ...
- Django之模型层-多表操作
多表操作 数据库表关系 一对多:两个表之间的关系一旦确定为一对多,必须在数据多的表中创建关联字段 多对多:两个表之间的关系一定确定为多对多,必须创建第三张表(关联表) 一对一:一旦两个表之间的关系确定 ...
- 06 Django之模型层---多表操作
一 创建模型 表和表之间的关系 一对一.多对一.多对多 ,用book表和publish表自己来想想关系,想想里面的操作,加外键约束和不加外键约束的区别,一对一的外键约束是在一对多的约束上加上唯一约束. ...
- 4.Django|ORM模型层
ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的 ...
- Python之路【第二十九篇】:django ORM模型层
ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的 ...
- 05 Django之模型层---单表操作
一 ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人 ...
- Django之模型层-单表操作
单表操作 添加记录 方式1 # 先实例化models中的对象,按照定义的语句规则传入参数,然后使用对象调用save()保存到数据库 book_obj = Book(id=1,title='python ...
随机推荐
- JS之滚动条效果2
在前面一篇说的是滚动条效果,本篇继续在前面的基础上面针对滚动条进行操作.本次要实现的效果如下:拖动滚动条左右移动时,上面的图片内容也相对外层盒子做相对移动. 下面针对要实现的效果进行分析:首先是页面基 ...
- [转][Java]尝试解决Java多行字符串的编辑问题
转自:https://blog.csdn.net/jiuwuerliu/article/details/51207045 参考了:https://www.v2ex.com/amp/t/445522 除 ...
- java 泛型 checkcast
我们来看一段代码 public class Test3 { public static void main(String args[]) throws IllegalAccessException, ...
- ORM多表操作之创建关联表及添加表记录
创建关联表 关于表关系的几个结论 (1)一旦确立表关系是一对多:建立一对多关系----在多对应的表中创建关联字段. (2)一旦确立表关系是多对多:建立多对多关系----创建第三张关系表----id和两 ...
- Abp IRepository 方法解释(1)
// // 摘要: // This interface is implemented by all repositories to ensure implementation of ...
- Scala 入门详解
Scala 入门详解 基本语法 Scala 与 Java 的最大区别是:Scala 语句末尾的分号 ; 是可选的 Scala 程序是对象的集合,通过调用彼此的方法来实现消息传递.类,对象,方法,实例变 ...
- 用户授权的Sql脚本
正文 要想成功访问 SQL Server 数据库中的数据, 我们需要两个方面的授权: 获得准许连接 SQL Server 服务器的权利: 获得访问特定数据库中数据的权利(select, update, ...
- call与apply简单介绍
var pet={ word:'...', speak:function(say){ console.log(say+' '+this.word) } } //pet.speak('speak')// ...
- 数组转换成json key-value形式
eg1(数组中包含的是数组): var jsonData = {}; var arr = [[1, 'boy', 'dabing'], [2, 'girl', 'dabing']]; for (var ...
- 微信小程序 setData 的坑(转)
最近在使用微信小程序的setData时,遇到了以下问题.如下: 官网文档在使用setData()设置数组对象的某个元素的属性时,是这么使用的: Page({ data: { array: [{text ...