何时使用交叉熵,何时使用KL散度:计算分布差距为啥使用KL散度而不用交叉熵,计算预测差距时为啥使用交叉熵而不用KL散度
问题:
何时使用交叉熵,何时使用KL散度?
计算分布差距为啥使用KL散度而不用交叉熵,计算预测差距时为啥使用交叉熵而不用KL散度
问题很大,答案却很简单。
答案:
- 熵是一种量度,是信息不确定性的量度;
- KL散度不是一种量度,并且不对称,KL(P||Q)一般不等于KL(Q||P);
- 交叉熵不是一种量度;
对于交叉熵不是一种量度进行说明:
如果:
H(P1 || Q1)=0.1
H(P2 || Q2)=0.2
我们是不能说P1分布与Q1分布之间的差距要小于P2分布与Q2分布之间的差距的,因为这两者是不具有比较性的。
只有当
H(P || Q1)=0.1
H(P || Q2)=0.2
时,我们可以说P分布与Q1分布之间的差距要小于P分布与Q2分布之间的差距的,也就是此时才可以说P与Q1的分布差距小于P与Q2的分布的。
需要注意:
H(P || Q1) - H(P || Q2) = KL(P || Q1) - KL(P || Q2)
换句话说,KL散度可以比较两个分布之间的差距,但是无法度量,并且不对称;
同理,交叉熵无法度量两个分布之间的差距,并且无法比较两个分布之间的差距,只有在某个分布固定的前提下才可以比较,而此时在分布差距比较的这一点上交叉熵等价于KL散度。
注意:
KL散度是有方向性的,是不对称的,因此KL(P || Q)是分布P与Q的差距,而不是分布Q与P的差距。因此在下文中使用交叉熵替代KL散度时其也是具有方向性的。
由于交叉熵不具有比较分布差异性的能力,因此在进行计算分布差距和计算预测差距时都是应该使用KL散度而不是交叉熵的。
但是通过KL散度和交叉熵的计算公式可以知道,KL散度的计算复杂度高于交叉熵,同时由于预测差距时真实的分布(label)是已知并且固定的,标签分布用P表示,即分布P已知且固定,也就是说此时 H(P(X)) 是固定不变的,因此的KL散度等价于交叉熵,待优化的分布为Q,因此进行预测差距计算的损失函数使用交叉熵而不是KL散度,就是为了节省计算开销。
也就是说,在P分布已知且固定时,KL(P || Q)等价于H(P || Q),同时由于H(P || Q)计算更快,因此在计算预测差距时损失函数使用交叉熵而不是KL散度,此时待优化的分布为Q。
但是在计算两个分布之间的差距时,分布P是未知的且不固定的,是神经网络的输出值,是待优化的变量,而此时的Q分布往往是采样来的采样数据的分布,并且Q的分布也是随着计算迭代而变量的(不固定的),因此此时是无法使用交叉熵来进行简化计算的,因为此时二者并不等价。
那么既然在预测差距时,我们设定真实标签分布为P,待优化分布为Q,获得KL(P || Q)等价于H(P || Q),从而使用交叉熵代替KL散度,那么我们为啥不在计算分布差距时将待优化分布设置为Q而是设置为P呢?
KL散度虽然可以用来比较两个分布之间的差距,但是其非对称性及其数学定义要求前者分布为真实分布,后者分布为估计分布;也就是说KL散度的基准是前者分布,也就是说P分布要求是真实分布或待优化的目标分布,Q分布可以是拟合分布也可以是采样估计分布。当P分布是固定真实分布时,Q分布为拟合分布;当P分布为待优化的目标分布时,Q分布为采样数据的分布;也就是说KL散度中这个P分布和Q分布是有顺序要求的,重点在于P分布需要为分布比较的基准,或者说P分布要么是固定不变的真实分布,要么是待优化的目标分布。这个问题在计算预测差距时是比较好理解的,难点在于计算分布差距时。
我们假设计算分布差距时,P分布为待优化的目标分布,而Q分布为采样分布,通过计算分布差距实现对P分布的优化(P分布是有参函数,可以当做是一个神经网络)。如果在计算损失函数时我们不使用 KL(P || Q) 而是使用 KL(Q || P),那么每次计算分布差距时的基准则是Q分布,而迭代计算过程中Q分布是不连续变化的,因此这样计算是无法保证计算的收敛和稳定的。换句话说,KL散度的前者分布要求是一个稳定不变的分布或者是一个连续变化的分布,也可以说KL散度中前者分布是优化过程中的target,因此在计算分布差距时前者分布为P,即待优化目标分布,而不能是采样分布。
给出百度本科上的KL散度的定义:


在信息理论中,KL分布是用来度量使用基于Q的编码来编码来自P的样本平均所需的额外的比特个数。典型情况下, P表示数据的真实分布, Q表示数据的理论分布,模型分布,或P的近似分布。
直白的理解,可以认为,KL散度中,P分布为固定不变的,或相对稳定的如待优化目标分布,因为P分布为KL计算中的基准分布。
总结
在本文中,我们介绍了KL散度和交叉熵这两个概念,并比较了它们之间的异同。KL散度用于比较两个概率分布之间的差异,而交叉熵用于衡量模型预测和真实标签之间的差异。尽管它们有一定的联系,但它们在使用和应用上还是有所区别。在机器学习中,KL散度和交叉熵都有着广泛的应用,可以用来评估模型的性能和更新模型参数。
KL散度与交叉熵之间的关系:
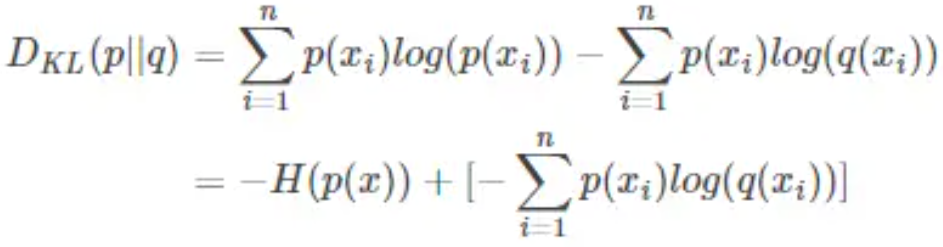
交叉熵:
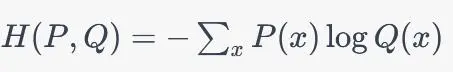
交叉熵具有以下性质:
交叉熵是非负的,即CE(P, Q) >= 0,当且仅当P和Q是完全相同的分布时等号成立。
交叉熵是不对称的。
交叉熵不是度量,因为它不具有三角不等式。
KL散度:
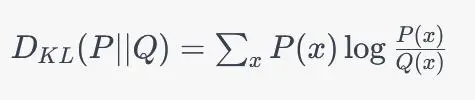
KL散度具有以下性质:
KL散度是非负的,即 KLD(P||Q) >= 0,当且仅当P和Q是完全相同的分布时等号成立。
KL散度不满足交换律,即 KLD(P||Q) != KLD(Q||P)。
KL散度通常不是对称的,即 KLD(P||Q) != KLD(Q||P)。
KL散度不是度量,因为它不具有对称性和三角不等式。
在机器学习中,KL散度通常用于比较两个概率分布之间的差异,例如在无监督学习中用于评估生成模型的性能。
参考:
https://baijiahao.baidu.com/s?id=1763841223452070719&wfr=spider&for=pc
何时使用交叉熵,何时使用KL散度:计算分布差距为啥使用KL散度而不用交叉熵,计算预测差距时为啥使用交叉熵而不用KL散度的更多相关文章
- [cocos2d-x]判断两个矩形是否有交叉区域
bool Rect::intersectsRect(const Rect& rect) const { return !( getMaxX() < rect.getMinX() || r ...
- 决策树 ID3 C4.5 CART(未完)
1.决策树 :监督学习 决策树是一种依托决策而建立起来的一种树. 在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某 ...
- 剖析虚幻渲染体系(15)- XR专题
目录 15.1 本篇概述 15.1.1 本篇内容 15.1.2 XR概念 15.1.2.1 VR 15.1.2.2 AR 15.1.2.3 MR 15.1.2.4 XR 15.1.3 XR综述 15. ...
- 熵(Entropy),交叉熵(Cross-Entropy),KL-松散度(KL Divergence)
1.介绍: 当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练模型的时候就不停地调整参数使得我们预测出来的概率和真是的概率更加接近. 这篇文章我们关注在我们的模型假设这些类 ...
- 【机器学习基础】熵、KL散度、交叉熵
熵(entropy).KL 散度(Kullback-Leibler (KL) divergence)和交叉熵(cross-entropy)在机器学习的很多地方会用到.比如在决策树模型使用信息增益来选择 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- [转]熵(Entropy),交叉熵(Cross-Entropy),KL-松散度(KL Divergence)
https://www.cnblogs.com/silent-stranger/p/7987708.html 1.介绍: 当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练 ...
- 交叉熵cross entropy和相对熵(kl散度)
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量真实分布p与当前训练得到的概率分布q有多么大的差异. 相对熵(relativ ...
- 熵、交叉熵、相对熵(KL 散度)意义及其关系
熵:H(p)=−∑xp(x)logp(x) 交叉熵:H(p,q)=−∑xp(x)logq(x) 相对熵:KL(p∥q)=−∑xp(x)logq(x)p(x) 相对熵(relative entropy) ...
- KL散度=交叉熵-熵
熵:可以表示一个事件A的自信息量,也就是A包含多少信息. KL散度:可以用来表示从事件A的角度来看,事件B有多大不同. 交叉熵:可以用来表示从事件A的角度来看,如何描述事件B. 一种信息论的解释是: ...
随机推荐
- linux,curl命令发送各类请求详解
当你经常面对api时,curl将是你重要学习的工具,因为curl可以让你不需要浏览器也能作为Http客户端发送请求.而且它是跨平台的,Linux.Windows.Mac都会执行的很好. 一.curl ...
- Spark-submit常用任务命令参数和说明
Spark常用任务命令参数和说明 spark-submit \ --name task2018072711591669 \ --master yarn --deploy-mode client \ - ...
- PowerShell 遇到 .ps1,因为在此系统上禁止运行脚本
PowerShell 遇到 .ps1,因为在此系统上禁止运行脚本 解决方法: 以管理员身份打开PowerShell: 查看当前的执行策略: Get-ExecutionPolicy * `Restric ...
- 导出excel文件接口代码示例
导出excel文件接口代码示例 1.该导出接口,token不能通过请求头来传输,需要在get请求的参数中带出来2.验证token的方法除了在拦截器中统一拦截,针对get接口传参数的方式也需要单独在接口 ...
- python globals()[]将字符串转化类,并通过反射执行方法
背景: 通过关键字设计ui自动化框架,将测试用例及其步骤存放到excel文件:其中步骤中包含了封装好的关键字方法,如打开浏览器.输入页面操作等,关键字保存的内容:具体类实例.方法 通过excel获取到 ...
- 实验12.dhcp服务器实验
实验12.dhcp服务器实验 测试DHCP服务的可用性 实验组 交换机配置 R1 interface GigabitEthernet0/0/0 ip address 192.168.1.1 255.2 ...
- day01小程序快速入门
这几天正式开始微信小程序的修炼了,就目前而言来看简直就是vue和react的结合体,所以在学小程序前,先把框架熟悉还是挺有用的. 一.简介 1.1与普通网页区别 二.第一个小程序 需要注册小程序开发账 ...
- ComfyUI进阶篇:ComfyUI核心节点(三)
ComfyUI核心节点(三) 前言: 学习ComfyUI是一场持久战.当你掌握了ComfyUI的安装和运行之后,会发现大量五花八门的节点.面对各种各样的工作流和复杂的节点种类,可能会让人感到不知所措. ...
- 直接给一个数组项赋值,Vue 能检测到变化吗?
由于 JavaScript 的限制,Vue 不能检测到以下数组的变动: 当你利用索引直接设置一个数组项时,例如: vm.items[indexOfItem] = newValue 当你修改数组的长度时 ...
- Happus:给准备离职成为独立开发者的你 5 点建议
名字:Happus 开发者 / 团队:Regina Dan 平台:iOS, visionOS 请简要介绍下这款产品 Happus 是你追寻幸福健康关系.甚至提高婚姻生活品质的贴心助手.无论是关系维系. ...