Paimon Compaction实现
Compact主要涉及以下几个组件
- CompactManager 管理Compact task
- CompactRewriter 用于compact过程中数据的重写实现, 比如compact过程中产生changelog等
- CompactStrategy 决定哪些文件需要被compact
Append Only表
对于Append Only表, compaction过程主要是为了合并小文件, 主要实现逻辑在AppendOnlyCompactManager 在每次Checkpoint或者主动触发compact时 会进行Compaction.
Compaction会分为Full Compaction和Auto Compaction. 一个会处理本批的全部文件,一个是处理部分文件.
CompactRewriter的行为就是把老数据读出来重写
Primary Key表
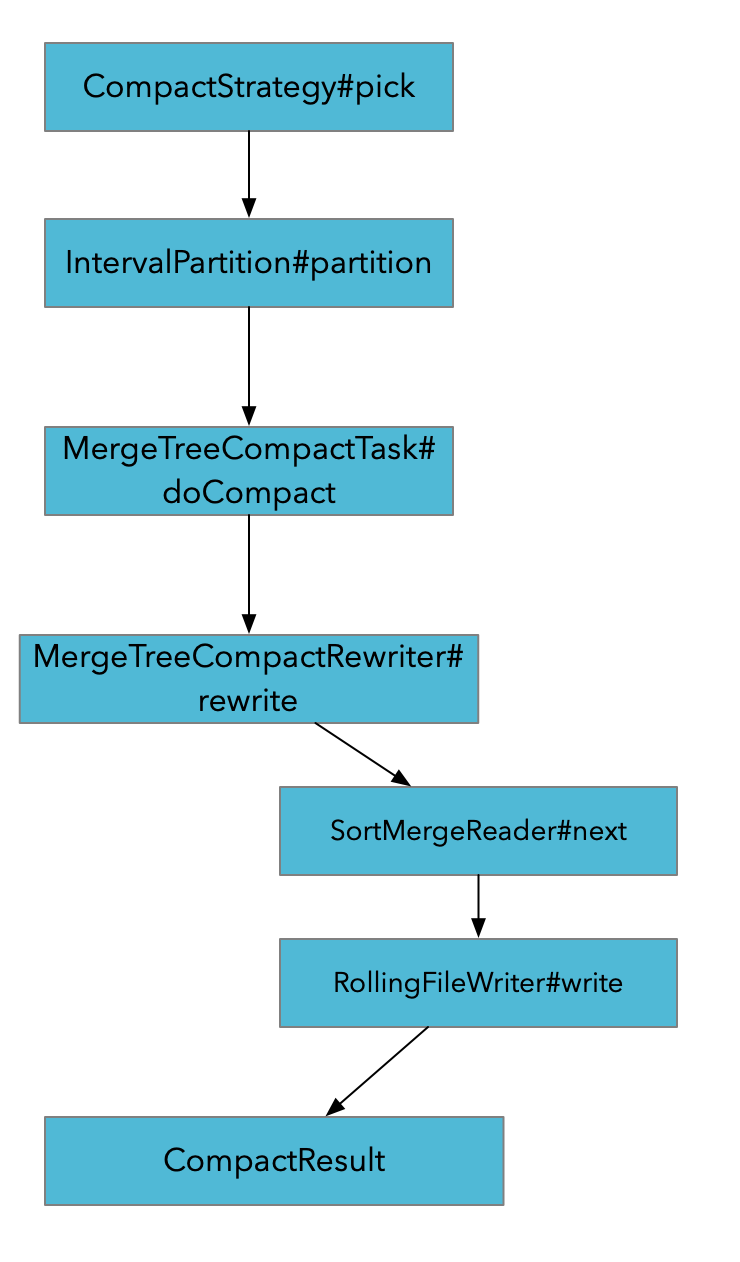
- pick 会根据CompactStrategy挑选需要Compact的文件. 如果是Full compact的话会将所有的文件挑选出来
- 对SortedRun 进行partition.
- 通过SortMegeReader将原文件中数据读取出来合并
- 合并完的结果写入新的文件, 如果过程中有产生Changelog的需求, 那么会在MergeFunction的实现中产生出Changelog, 并写到Changelog文件中去.
- CompactResult包含了 三组文件: before , after, changelog文件
CompactStrategy
Paimon的LSM结构
L0 每一个文件对应一个sorted run, L0往下每一层有一个sorted run. 每一个sorted run 对应一个或多个文件,文件写到一定大小就会rolling out. 所以同一层的sorted run看做是一个全局按照pk排序的文件.
一个文件中的文件会按照primary key排序. 一个Sorted Run中的各个文件之间的key range不会重叠. 但是不同的sorted run之间key range是会重叠的.
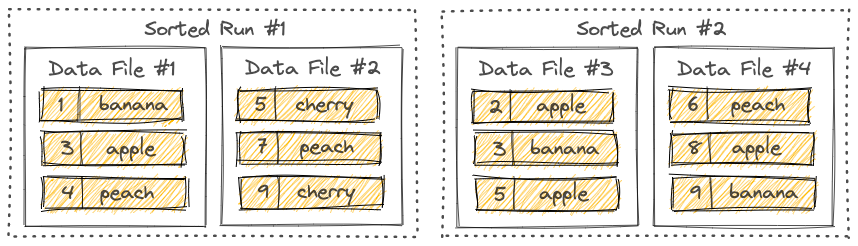
和Rocksdb中sorted run的定义也是一样
Universal Compaction
CompactionStrategy主要就是决定有哪些文件要参与compaction, compaction的目的是为了减少不同的sorted run之间key的overlap, 提升查询效率, 减少数据重复.
Paimon中默认采用的是类似RocksDB Universal compaction. Compacion的策略分为两大类level compaction 和 size tiered compaction. Universal compaction 是Rocksdb的size tiered compaction的实现. size tiered compaction 比较适合 write intensive 的 workload, 数据湖场景也是高密度写入的场景, 猜测因此把Universal compaction 策略作为默认的compaction策略.
如Rocksdb的wiki所描述, Universal compaction是一个写放大相对较小, 但是读放大和空间放大比较大.
Universal Compaction Style is a compaction style, targeting the use cases requiring lower write amplification, trading off read amplification and space amplification.
这个算法策略的基本思想
The basic idea of the compaction style: with a threshold of number of sorted runs N, we only start compaction when number of sorted runs reaches N. When it happens, we try to pick files to compact so that number of sorted runs is reduced in the most economic way: (1) it starts from the smallest file; (2) one more sorted run is included if its size is no larger than the existing compaction size. The strategy assumes and itself tries to maintain that the sorted run containing more recent data is smaller than ones containing older data.
- 有限个sorted run,当达到这么多sorted run时就触发compact
- 触发compact时 使用最经济的方式减少sorted run的个数
- 从最小的文件开始
- 如果其大小不大于下一个的Sorted run的大小,则再包含一个Sorted run
- 该策略假设并试图保持包含较新数据的Sorted run 的个数小于包含较旧数据的Sorted run
由Space Amplification触发的合并
判断R1-R(n-1) sorted run大小有没有超过 最高层(最老数据)的两倍, 超过了那就触发一次full compaction.
size amplification ratio = (size(R1) + size(R2) + ... size(Rn-1)) / size(Rn)
空间放大为什么这么算

由Individual Size Ratio触发的合并
size_ratio_trigger = (100 + options.compaction_options_universal.size_ratio) / 100
我们从R1开始,如果size(R2) / size(R1) <= size_ratio_trigger, 那么(R1,R2)被合并到一起。我们以此继续决定R3是不是可以加进来。如果size(R3) / size(R1+r2) <= size_ratio_trigger,R3应该被包含,得到(R1,R2,R3)。然后我们对R4做同样的事情。我们一直用所有已有的大小总和,跟下一个排序结果比较,直到size_ratio_trigger条件不满足。
1 1 1 1 1 => 5
1 5 (no compaction triggered)
1 1 5 (no compaction triggered)
1 1 1 5 (no compaction triggered)
1 1 1 1 5 => 4 5
1 4 5 (no compaction triggered)
1 1 4 5 (no compaction triggered)
1 1 1 4 5 => 3 4 5
1 3 4 5 (no compaction triggered)
1 1 3 4 5 => 2 3 4 5
paimon中默认size ratio 是1%, 也就是前N个的size 之和 / 第N+1个的 size <= 101/100, 那么就合并这N+1个sorted run.
这个策略的效果有点类似于是除了最高层之外, 把各个sorted run的大小尽可能靠近对齐
Full Compaction
全部文件参与compaction, 并合并到maxlevel
参考
https://github.com/facebook/rocksdb/wiki/Universal-Compaction
https://blog.csdn.net/qq_40586164/article/details/117914647
https://zhuanlan.zhihu.com/p/141186118
https://zhuanlan.zhihu.com/p/165137544
Paimon Compaction实现的更多相关文章
- Rocksdb Compaction原理
概述 compaction主要包括两类:将内存中imutable 转储到磁盘上sst的过程称之为flush或者minor compaction:磁盘上的sst文件从低层向高层转储的过程称之为compa ...
- leveldb源码分析--SSTable之Compaction
对于compaction是leveldb中体量最大的一部分,也应该是最为复杂的部分,为了便于理解我们首先从一些基本的概念开始.下面是一些从doc/impl.html中翻译和整理的内容: Level 0 ...
- RocksDB笔记 - Compaction中的Iterator
Compaction中的Iterator 一般来说,Compaction的Input涉及两层数据的合并,对于涉及到的每一层数据: 如果是level-0,对level-0的每一个sstable文件建立一 ...
- hbase中Compaction的理解及RegionServer内存的使用,CacheBlock机制
Compaction有两种类型: (1)minor compaction:属于轻量级.将多个小的storefile文件重写为数量较少的大storefile文件,减少存储文件的数量,实际上是个多路归并的 ...
- LevelDB的源码阅读(四) Compaction操作
leveldb的数据存储采用LSM的思想,将随机写入变为顺序写入,记录写入操作日志,一旦日志被以追加写的形式写入硬盘,就返回写入成功,由后台线程将写入日志作用于原有的磁盘文件生成新的磁盘数据.Leve ...
- HBase MetaStore和Compaction剖析
1.概述 客户端读写数据是先从HBase Master获取RegionServer的元数据信息,比如Region地址信息.在执行数据写操作时,HBase会先写MetaStore,为什么会写到MetaS ...
- Stripe Compaction
借鉴于LevelDB.Cassandra的Compaction方法,https://issues.apache.org/jira/browse/HBASE-7667 提出了Stripe Compact ...
- HBase Compaction
当 client 向 hregion 端 put() 数据时, HRegion 会判断当前的 memstore 的大小是否大于参数hbase.hregion.memstore.flush.size 值 ...
- HBase写入性能及改造——multi-thread flush and compaction(续:详细测试数据)[转]
转载:http://blog.csdn.net/kalaamong/article/details/7290192 接上文啊: 测试机性能 CPU 16* Intel(R) Xeon(R) CPU ...
- HBase Compaction详解
HBase Compaction策略 RegionServer这种类LSM存储引擎需要不断的进行Compaction来减少磁盘上数据文件的个数和删除无用的数据从而保证读性能. RegionServer ...
随机推荐
- 图与网络分析—R实现(二)
图与网络 网络在各种实际背景问题中以各种各样的形式存在.交通.电子和通讯网络遍及我们日常生活的各个方面,网络规划也广泛用于解决不同领域中的各种问题,如生产.分配.项目计划.厂址选择.资源管理和财务策划 ...
- 深入理解 python 虚拟机:字节码教程(1)——原来装饰器是这样实现的
深入理解 python 虚拟机:字节码教程(1)--原来装饰器是这样实现的 在本篇文章当中主要给大家介绍在 cpython 当中一些比较常见的字节码,从根本上理解 python 程序的执行.在本文当中 ...
- tcp,udp tcp三次握手四次挥手,基于套接字进行简单通信
1.应用层: 应用层功能:规定应用程序的数据格式. 例:TCP协议可以为各种各样的程序传递数据,比如Email.WWW.FTP等等.那么,必须有不同协议规定电子邮件.网页.FTP数据的格式,这些应用程 ...
- 用Abp实现找回密码和密码强制过期策略
@ 目录 重置密码 找回密码 发送验证码 校验验证码 发送重置密码链接 创建接口 密码强制过期策略 改写接口 Vue网页端开发 重置密码页面 忘记密码控件 密码过期提示 项目地址 用户找回密码,确切地 ...
- day01-项目介绍&功能实现
项目介绍&功能实现 1.项目介绍&环境搭建 一个以社交平台为核心的轻电商项目,功能如下: 短信登录.商户查询缓存.优惠券秒杀.达人探店.好友关注.附近的商户.用户签到.UV统计 1.1 ...
- .net使用nacos配置,手把手教你分布式配置中心
.net使用nacos配置,手把手教你分布式配置中心 Nacos是一个更易于构建云原生应用的动态服务发现.配置管理和服务管理平台. 这么优秀的分布式服务管理平台,怎么能不接入呢? nacos的安装和使 ...
- Godot 4.0 设置应用程序图标、项目图标
godot版本:4.0.2,理论上4.0.0版也适用. 本文章是针对window应用程序而写的,其他平台不一定适用,仅供参考. 效果 输出的可执行文件图标为指定的图标,适配多种尺寸 执行时窗口图标为指 ...
- Marior去除边距和迭代内容矫正用于自然文档矫正
一.简要介绍 本文简要介绍了论文" Marior: Margin Removal and Iterative Content Rectification for Document Dewar ...
- 深度相机:结构光、TOF、双目相机
随着人工智能与机器人.无人驾驶的火热,深度相机的技术和应用也受到关注,何谓深度相机? 顾名思义,就是可以测量物体到相机的距离(深度) 传统的RGB彩色普通相机称为2D相机,只能拍摄相机视角内的物体,没 ...
- [双目视差] 立体匹配-SGBM半全局立体匹配算法
立体匹配-SGBM半全局立体匹配算法 一.SGBM算法实现过程 1.预处理 预处理目的是得到图像的梯度信息 Step1:SGBM采用水平Sobel算子,对图像做处理,公式为: Sobel(x,y)=2 ...