论文解读(TAMEPT)《A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification》
论文信息
论文标题:A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification
论文作者:Yunlong Feng, Bohan Li, Libo Qin, Xiao Xu, Wanxiang Che
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
动机:以前的工作主要集中于提取 域不变特征 或 任务不可知特征,而忽略了存在于目标域中可能对下游任务有用的域感知特征;
贡献:
- 提出一个两阶段的学习框架,使现有的分类模型能够有效地适应目标领域;
- 引入自监督蒸馏,可以帮助模型更好地从目标领域的未标记数据中捕获域感知特征;
- 在 Amazon 跨域分类基准上的实验表明,取得了 SOTA ;
2 相关
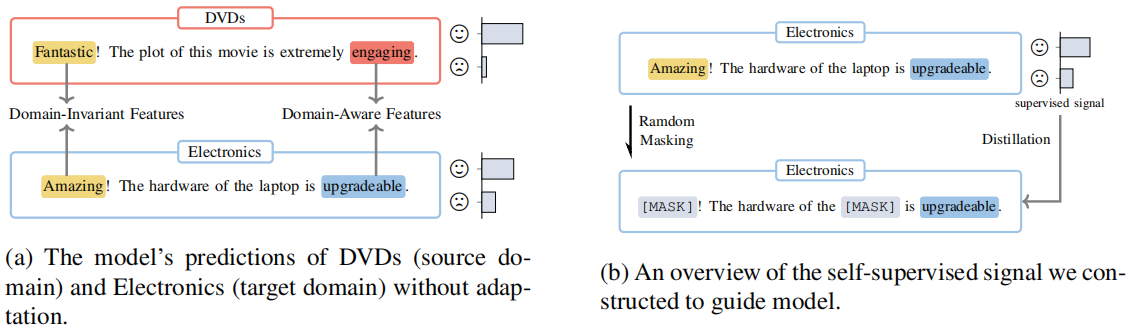
Figure 1(a):阐述域不变特征和域感知特征与任务的关系;
Figure 1(b):阐述遮蔽域不变特征和域感知特征与预测的关系:
- 通过掩盖域不变特征,模型建立预测和域感知特征的相关性;
- 通过掩盖域感知特征,模型加强了预测和域不变特征的关系;
一个文本提示组成如下:
$\boldsymbol{x}_{\mathrm{p}}=\text { "[CLS] } \boldsymbol{x} \text {. It is [MASK]. [SEP]"} \quad\quad(1)$
$\text{PLM}$ 将 $\boldsymbol{x}_{\mathrm{p}}$ 作为输入,并利用上下文信息用词汇表中的一个单词填充 $\text{[MASK]}$ 作为输出,输出单词随后被映射到一个标签 $\mathcal{Y}$。
PT 的目标:
$\mathcal{L}_{p m t}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=-\sum_{\boldsymbol{x}, y \in \mathcal{D}} y \log p_{\theta_{\mathcal{M}}}\left(\hat{y} \mid \boldsymbol{x}_{\mathrm{p}}\right)$
使用 $\text{MLM }$ 来避免快捷学习($\text{shortcut learning}$),并适应目标域分布。具体来说,构造了一个掩蔽文本提示符 $\boldsymbol{x}_{\mathrm{pm}}$:
$\boldsymbol{x}_{\mathrm{pm}}=\text { "[CLS] } \boldsymbol{x}_{\mathrm{m}} \text {. It is [MASK]. [SEP]"}$
其中,$m\left(y_{\mathrm{m}}\right)$ 和 $\operatorname{len}_{m\left(\boldsymbol{x}_{\mathrm{m}}\right)}$ 分别表示 $x_{\mathrm{m}}$ 中的掩码词和计数;
SSKD
核心:使模型能够在预测和目标域的域感知特征之间建立联系;
具体:模型迫使 $x_{\mathrm{p}}$ 的预测和 $\boldsymbol{x}_{\mathrm{pm}}$ 的未掩蔽词之间联系起来,本文在 $p_{\theta}\left(y \mid \boldsymbol{x}_{\mathrm{pm}}\right)$ 和 $p_{\theta}\left(y \mid \boldsymbol{x}_{\mathrm{p}}\right)$ 的预测之间进行 $\text{KD}$:
$\mathcal{L}_{s s d}\left(\mathcal{D} ; \theta_{\mathcal{M}}\right)=\sum_{\boldsymbol{x} \in \mathcal{D}} K L\left(p_{\theta_{\mathcal{M}}}\left(y \mid \boldsymbol{x}_{\mathrm{pm}}\right)|| p_{\theta_{\mathcal{M}}}\left(y \mid \boldsymbol{x}_{\mathrm{p}}\right)\right)$
注意:$\boldsymbol{x}_{\mathrm{pm}}$ 可能包含域不变、域感知特征,或两者都包含;
2 方法
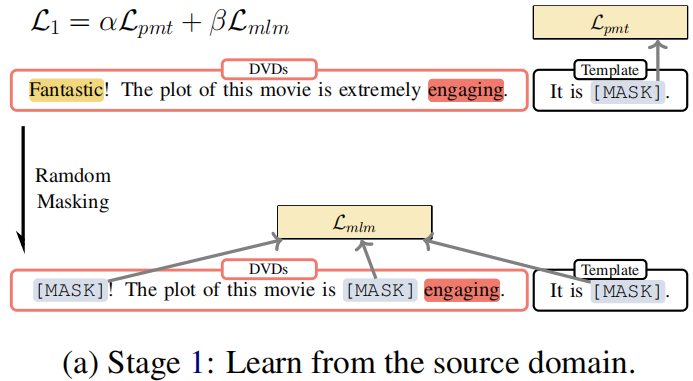
Procedure:
- Firstly, we calculate the classification loss of those sentences and update the parameters with the loss, as shown in line 5 of Algorithm 1.
- Then we mask the same sentence and calculate mask language modeling loss to update the parameters, as depicted in line 8 of Algorithm 1. The parameters of the model will be updated together by these two losses.
Objective:
$\begin{array}{l}\mathcal{L}_{1}^{\prime}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=\alpha \mathcal{L}_{p m t}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right) \\\mathcal{L}_{1}^{\prime \prime}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=\beta \mathcal{L}_{m l m}\left(\mathcal{D} ; \theta_{\mathcal{M}}\right)\end{array}$
Stage 2: Adapt to the target domain
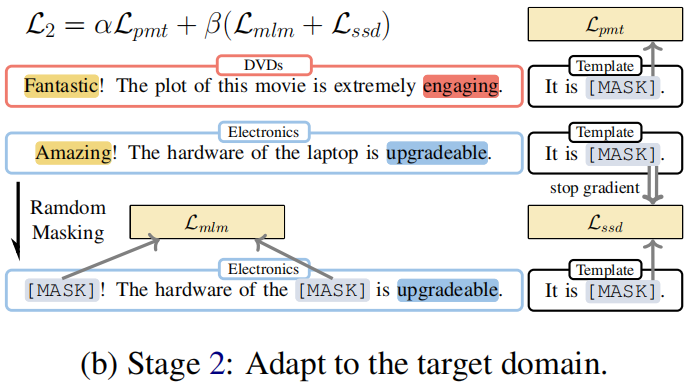
Procedure:
- Firstly, we sample labeled data from the source domain $\mathcal{D}_{S}^{\mathcal{T}} $ and calculate sentiment classification loss. The model parameters are updated using this loss in line 5 of Algorithm 2.
- Next, we sample unlabeled data from the target domain $\mathcal{D}_{T} $ and mask the unlabeled data to do a masking language model and selfsupervised distillation with the previous prediction.
Objective:
$\begin{aligned}\mathcal{L}_{2}^{\prime}\left(\mathcal{D}_{S}^{\mathcal{T}}, \mathcal{D}_{T} ; \theta_{\mathcal{M}}\right) & =\alpha \mathcal{L}_{p m t}\left(\mathcal{D}_{S}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right) \\\mathcal{L}_{2}^{\prime \prime}\left(\mathcal{D}_{S}^{\mathcal{T}}, \mathcal{D}_{T} ; \theta_{\mathcal{M}}\right) & =\beta\left(\mathcal{L}_{m l m}\left(\mathcal{D}_{T} ; \theta_{\mathcal{M}}\right)\right. \left.+\mathcal{L}_{s s d}\left(\mathcal{D}_{T} ; \theta_{\mathcal{M}}\right)\right)\end{aligned}$
Algorithm

3 实验
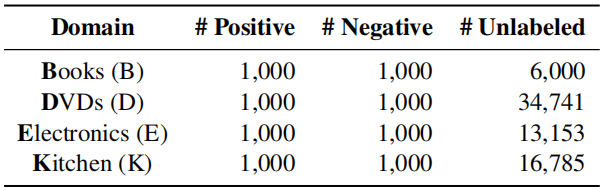
Dataset
Amazon reviews dataset
- $\text{R-PERL }$(2020): Use BERT for cross-domain text classification with pivot-based fine-tuning.
- $\text{DAAT}$ (2020): Use BERT post training for cross-domain text classification with adversarial training.
- $\text{p+CFd}$ (2020): Use XLM-R for cross-domain text classification with class-aware feature self-distillation (CFd).
- $\text{SENTIX}_{\text{Fix}}$ (2020): Pre-train a sentiment-aware language model by several pretraining tasks.
- $\text{UDALM}$ (2021): Fine-tuning with a mixed classification and MLM loss on domain-adapted PLMs.
- $\text{AdSPT}$ (2022): Soft Prompt tuning with an adversarial training object on vanilla PLMs.
- During Stage 1, we train 10 epochs with batch size 4 and early stopping (patience =3 ) on the accuracy metric. The optimizer is AdamW with learning rate 1 $\times 10^{-5}$ . And we halve the learning rate every 3 epochs. We set $\alpha=1.0$, $\beta=0.6$ for Eq.6 .
- During Stage 2, we train 10 epochs with batch size 4 and early stopping (patience =3 ) on the mixing loss of classification loss and mask language modeling loss. The optimizer is AdamW with a learning rate $1 \times 10^{-6}$ without learning rate decay. And we set $\alpha=0.5$, $\beta=0.5$ for Eq. 7 .
- In addition, for the mask language modeling objective and the self-supervised distillation objective, we randomly replace 30% of tokens to [MASK] and the maximum sequence length is set to 512 by truncation of inputs. Especially we randomly select the equal num unlabeled data from the target domain every epoch during Stage 2.
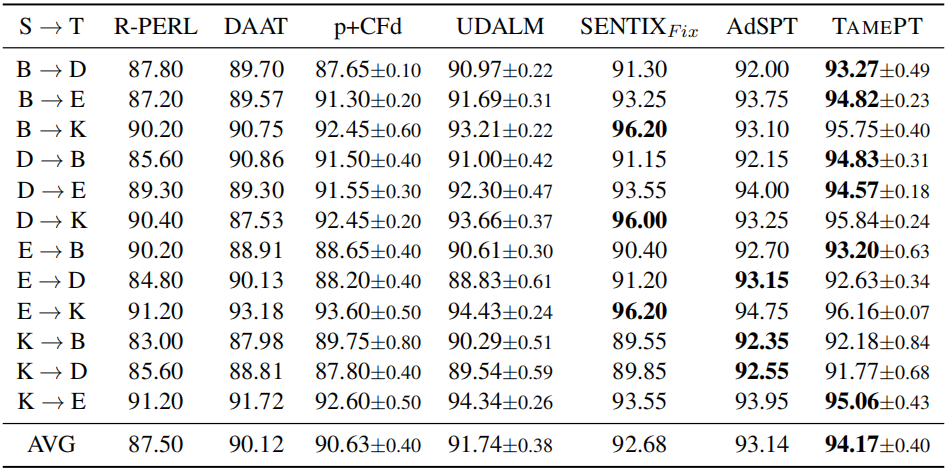
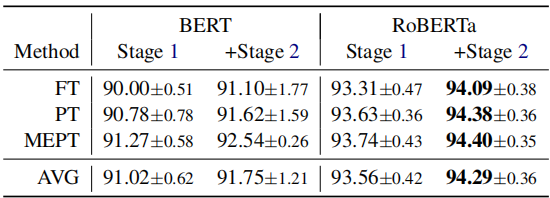
Single-source domain adaptation on Amazon reviews
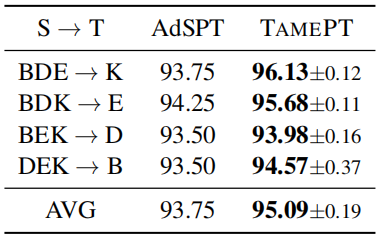
Multi-source domain adaptation on Amazon reviews
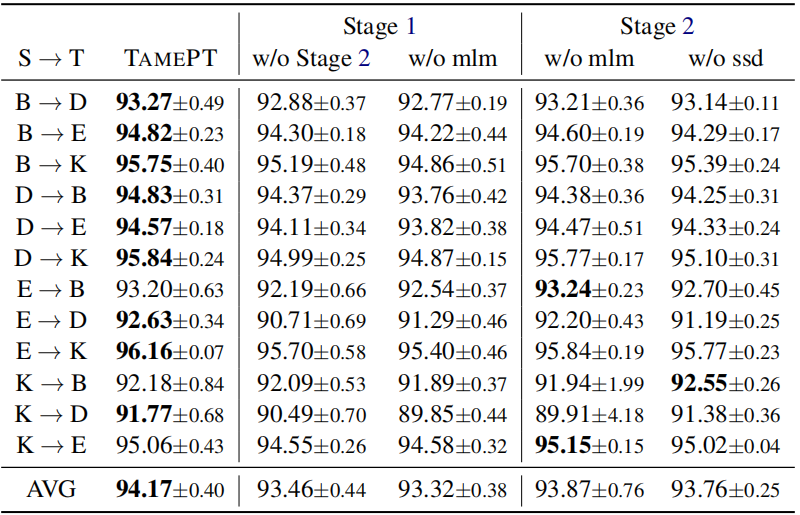
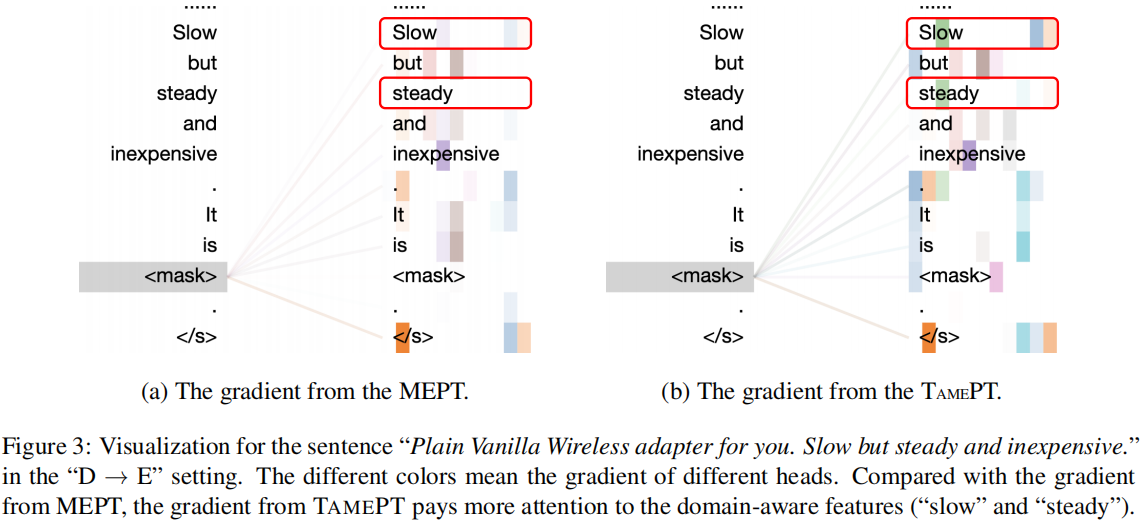

论文解读(TAMEPT)《A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification》的更多相关文章
- 论文解读(SimGRACE)《SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation》
论文信息 论文标题:SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation论文作者: ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- 论文解读(SDNE)《Structural Deep Network Embedding》
论文题目:<Structural Deep Network Embedding>发表时间: KDD 2016 论文作者: Aditya Grover;Aditya Grover; Ju ...
- 论文解读(IDEC)《Improved Deep Embedded Clustering with Local Structure Preservation》
Paper Information Title:<Improved Deep Embedded Clustering with Local Structure Preservation>A ...
- 论文解读(KP-GNN)《How Powerful are K-hop Message Passing Graph Neural Networks》
论文信息 论文标题:How Powerful are K-hop Message Passing Graph Neural Networks论文作者:Jiarui Feng, Yixin Chen, ...
- 论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
论文信息 论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data论文作者:Qi Zhu, ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
随机推荐
- action装饰器
视图集中附加action的声明 from rest_framework.decorators import action # 追加action:返回书记的倒叙地0个书籍的信息 @action(meth ...
- 如何科学地利用MTTR优化软件交付流程?
谷歌提出的衡量 DevOps 质量的 DORA 指标让 MTTR(平均恢复时间) 名声大振.在本文中,你将了解到 MTTR 的作用.为什么它对行业研究很有用.你可能被它误导的原因以及如何避免 MTTR ...
- 【Python&GIS】GDAL栅格转面&计算矢量面积
GDAL(Geospatial Data Abstraction Library)是一个在X/MIT许可协议下的开源栅格空间数据转换库.它利用抽象数据模型来表达所支持的各种文件格式.它 ...
- Spring事件监听机制使用和原理解析
你好,我是刘牌! 前言 好久没有更新Spring了,今天来分享一下Spring的事件监听机制,之前分享过一篇Spring监听机制的使用,今天从原理上进行解析,Spring的监听机制基于观察者模式,就是 ...
- 【技术积累】Python中的NumPy库【二】
NumPy库的主要类有哪些? NumPy库的主要类包括: ndarray:N维数组对象,是NumPy最重要的类之一.它是Python中数组的基本数据结构,可以进行高效的数学计算和数据处理操作. ufu ...
- Redis6 的安装
安装网址 Redis 官方网站 Redis 中文官方网站 http://redis.io http://redis.cn/ 安装版本 6.2.1 for Linux(redis-6.2.1 ...
- 发布一个Visual Studio 2022 插件,可以自动完成构造函数依赖注入代码
赖注入(DI)在开发中既是常见的也是必需的技术.它帮助我们优化了代码结构,使得应用更加灵活.易于扩展,同时也降低了各个模块之间的耦合度,更容易进行单元测试,提高了编码效率和质量.不过,手动注入依赖项也 ...
- ABP - 缓存模块(2)
1. 缓存模块源码解析 个人觉得 ABP 分布式缓存模块有三个值得关注的核心点.首先是 AbpRedisCache 类继承了微软原生的 RedisCache,并 通过反射的方式获取RedisCache ...
- rocketmq-console基本使用
rocketmq-console基本使用 作用:rocketmq-console是rocketmq的一款可视化工具,提供了mq的使用详情等功能. 一.安装部署 下载rocketmq组件 rocketm ...
- Web网页音视频通话之基于sipjs功能扩展
在上一篇开发基础上,已经实现了音视频通话.本文是在此基础上继续完成以下内容 关闭/开启音频 开启/关闭视频 屏幕共享 开启/关闭音频 javaScript /** * 静音 */ mute() { i ...