2023-08-08:给你一棵 n 个节点的树(连通无向无环的图) 节点编号从 0 到 n - 1 且恰好有 n - 1 条边 给你一个长度为 n 下标从 0 开始的整数数组 vals 分别表示每个节
2023-08-08:给你一棵 n 个节点的树(连通无向无环的图)
节点编号从 0 到 n - 1 且恰好有 n - 1 条边
给你一个长度为 n 下标从 0 开始的整数数组 vals
分别表示每个节点的值
同时给你一个二维整数数组 edges
其中 edges[i] = [ai, bi] 表示节点 ai 和 bi 之间有一条 无向 边
一条 好路径 需要满足以下条件:
开始节点和结束节点的值 相同 。
开始节点和结束节点中间的所有节点值都 小于等于 开始节点的值。
(也就是说开始节点的值应该是路径上所有节点的最大值)。
请你返回不同好路径的数目。
注意,一条路径和它反向的路径算作 同一 路径。
比方说, 0 -> 1 与 1 -> 0 视为同一条路径。单个节点也视为一条合法路径。
输入:vals = [1,1,2,2,3], edges = [[0,1],[1,2],[2,3],[2,4]]。
输出:7。
来自谷歌。
来自左神
答案2023-08-08:
大致的步骤如下:
1.创建一个图(树)数据结构,并初始化节点的值和连接关系。
2.对节点的值进行排序,按照值的大小顺序处理节点。
3.初始化并查集,用于管理节点的连通性。
4.创建一个数组记录每个连通分量中值最大的节点的索引。
5.创建一个数组记录每个连通分量中值最大的节点所在连通分量的节点数。
6.初始化答案为节点的总数。
7.遍历排序后的节点列表,依次处理每个节点:
7.1.获取当前节点的索引和值。
7.2.查找当前节点的连通分量代表节点。
7.3.查找当前连通分量代表节点的最大值节点的索引。
7.4.遍历当前节点的邻居节点,将邻居节点的值与当前节点值进行比较。
7.5.若邻居节点的值小于等于当前节点值,并且邻居节点所在的连通分量与当前连通分量不同,则进行以下操作:
7.5.1.查找邻居节点连通分量的代表节点的最大值节点的索引。
7.5.2.若邻居节点的值等于该最大值节点的值,则更新答案并累加该最大值节点所在连通分量的节点数。
7.5.3.合并当前节点和邻居节点所在的连通分量。
7.5.4.更新当前连通分量代表节点的索引。
8.返回答案。
时间复杂度为O(nlogn)。
空间复杂度为O(n)。
go完整代码如下:
package main
import (
"fmt"
"sort"
)
func numberOfGoodPaths(vals []int, edges [][]int) int {
n := len(vals)
graph := make([][]int, n)
for i := 0; i < n; i++ {
graph[i] = make([]int, 0)
}
for _, e := range edges {
graph[e[0]] = append(graph[e[0]], e[1])
graph[e[1]] = append(graph[e[1]], e[0])
}
nodes := make([][]int, n)
for i := 0; i < n; i++ {
nodes[i] = make([]int, 2)
nodes[i][0] = i
nodes[i][1] = vals[i]
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i][1] < nodes[j][1]
})
uf := NewUnionFind(n)
maxIndex := make([]int, n)
for i := 0; i < n; i++ {
maxIndex[i] = i
}
maxCnts := make([]int, n)
for i := 0; i < n; i++ {
maxCnts[i] = 1
}
ans := n
for _, node := range nodes {
curi := node[0]
curv := vals[curi]
curCandidate := uf.Find(curi)
curMaxIndex := maxIndex[curCandidate]
for _, nexti := range graph[curi] {
nextv := vals[nexti]
nextCandidate := uf.Find(nexti)
if curCandidate != nextCandidate && curv >= nextv {
nextMaxIndex := maxIndex[nextCandidate]
if curv == vals[nextMaxIndex] {
ans += maxCnts[curMaxIndex] * maxCnts[nextMaxIndex]
maxCnts[curMaxIndex] += maxCnts[nextMaxIndex]
}
candidate := uf.Union(curi, nexti)
maxIndex[candidate] = curMaxIndex
}
}
}
return ans
}
type UnionFind struct {
parent []int
size []int
help []int
}
func NewUnionFind(n int) *UnionFind {
uf := &UnionFind{
parent: make([]int, n),
size: make([]int, n),
help: make([]int, n),
}
for i := 0; i < n; i++ {
uf.parent[i] = i
uf.size[i] = 1
}
return uf
}
func (uf *UnionFind) Find(i int) int {
hi := 0
for i != uf.parent[i] {
uf.help[hi] = i
hi++
i = uf.parent[i]
}
for hi--; hi >= 0; hi-- {
uf.parent[uf.help[hi]] = i
}
return i
}
func (uf *UnionFind) Union(i, j int) int {
f1 := uf.Find(i)
f2 := uf.Find(j)
if f1 != f2 {
if uf.size[f1] >= uf.size[f2] {
uf.size[f1] += uf.size[f2]
uf.parent[f2] = f1
return f1
} else {
uf.size[f2] += uf.size[f1]
uf.parent[f1] = f2
return f2
}
}
return f1
}
func main() {
vals := []int{1, 1, 2, 2, 3}
edges := [][]int{{0, 1}, {1, 2}, {2, 3}, {2, 4}}
result := numberOfGoodPaths(vals, edges)
fmt.Println(result)
}
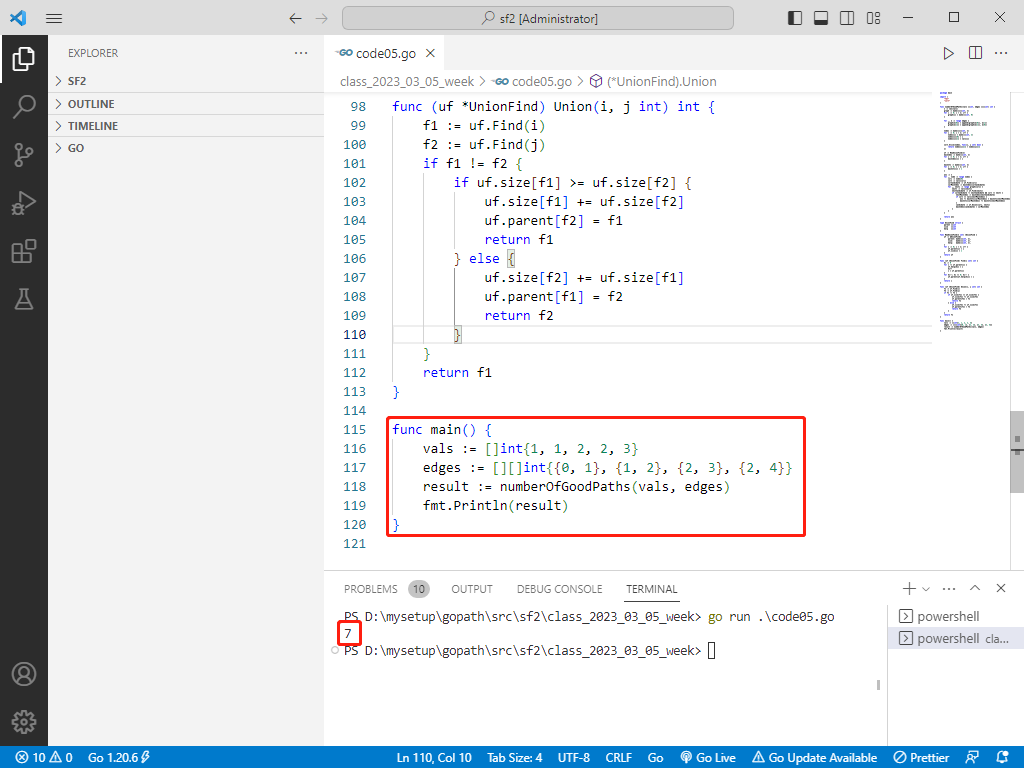
rust完整代码如下:
use std::cmp::Ordering;
fn number_of_good_paths(vals: Vec<i32>, edges: Vec<Vec<i32>>) -> i32 {
let n = vals.len();
let mut graph: Vec<Vec<i32>> = vec![Vec::new(); n];
for edge in edges {
let a = edge[0] as i32;
let b = edge[1] as i32;
graph[a as usize].push(b);
graph[b as usize].push(a);
}
let mut nodes: Vec<[i32; 2]> = vals
.iter()
.enumerate()
.map(|(i, &v)| [i as i32, v as i32])
.collect();
nodes.sort_by(|a, b| a[1].cmp(&b[1]));
let mut uf = UnionFind::new(n as i32);
let mut max_index: Vec<i32> = (0..n as i32).collect();
let mut max_counts: Vec<i32> = vec![1; n];
let mut ans = n as i32;
for node in nodes {
let cur_i = node[0];
let cur_v = vals[cur_i as usize];
let cur_candidate = uf.find(cur_i);
let cur_max_index = max_index[cur_candidate as usize];
for &next_i in &graph[cur_i as usize] {
let next_v = vals[next_i as usize];
let next_candidate = uf.find(next_i);
if cur_candidate != next_candidate && cur_v >= next_v {
let next_max_index = max_index[next_candidate as usize];
if cur_v == vals[next_max_index as usize] {
ans += max_counts[cur_max_index as usize] * max_counts[next_max_index as usize];
max_counts[cur_max_index as usize] += max_counts[next_max_index as usize];
}
let candidate = uf.union(cur_i, next_i);
max_index[candidate as usize] = cur_max_index;
}
}
}
ans
}
struct UnionFind {
parent: Vec<i32>,
size: Vec<i32>,
help: Vec<i32>,
}
impl UnionFind {
fn new(n: i32) -> UnionFind {
UnionFind {
parent: (0..n).collect(),
size: vec![1; n as usize],
help: Vec::new(),
}
}
fn find(&mut self, i: i32) -> i32 {
let mut hi = 0;
let mut x = i;
while x != self.parent[x as usize] {
self.help.push(x);
x = self.parent[x as usize];
hi += 1;
}
for hi in (0..hi).rev() {
self.parent[self.help[hi as usize] as usize] = x;
}
self.help.clear();
x
}
fn union(&mut self, i: i32, j: i32) -> i32 {
let f1 = self.find(i);
let f2 = self.find(j);
if f1 != f2 {
if self.size[f1 as usize] >= self.size[f2 as usize] {
self.size[f1 as usize] += self.size[f2 as usize];
self.parent[f2 as usize] = f1;
return f1;
} else {
self.size[f2 as usize] += self.size[f1 as usize];
self.parent[f1 as usize] = f2;
return f2;
}
}
f1
}
}
fn main() {
let vals = vec![1, 1, 2, 2, 3];
let edges = vec![vec![0, 1], vec![1, 2], vec![2, 3], vec![2, 4]];
let result = number_of_good_paths(vals, edges);
println!("Number of good paths: {}", result);
}
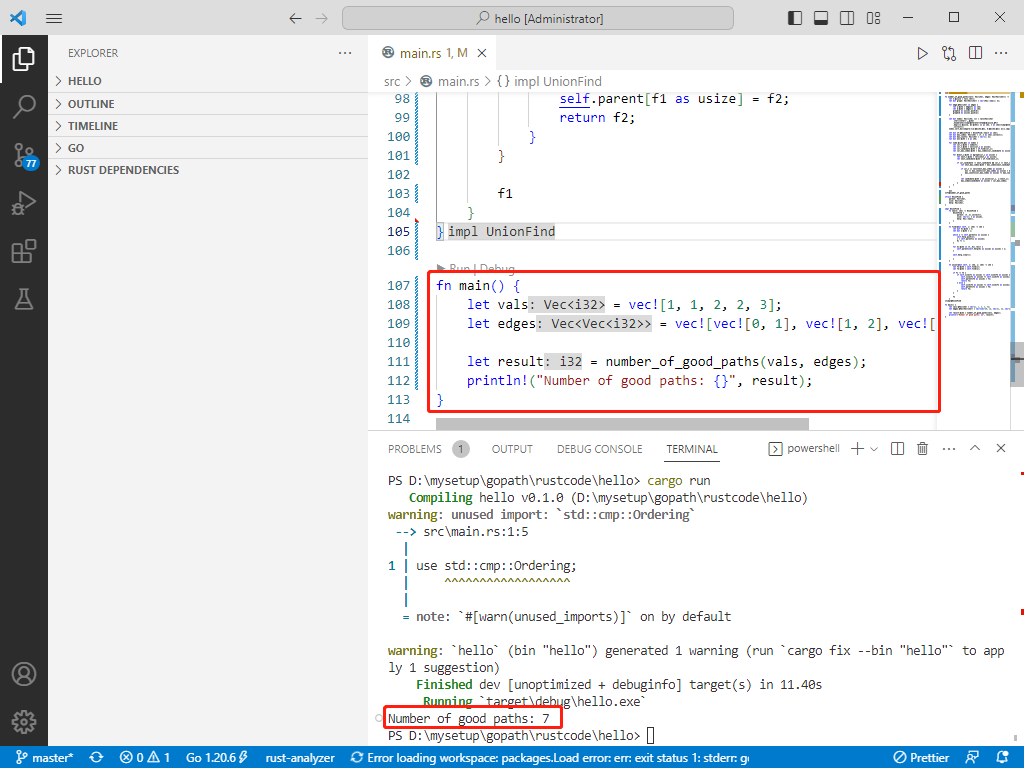
c++完整代码如下:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int numberOfGoodPaths(vector<int>& vals, vector<vector<int>>& edges) {
int n = vals.size();
// Build the graph
vector<vector<int>> graph(n);
for (auto& edge : edges) {
int a = edge[0];
int b = edge[1];
graph[a].push_back(b);
graph[b].push_back(a);
}
// Sort the nodes based on values
vector<pair<int, int>> nodes;
for (int i = 0; i < n; i++) {
nodes.push_back({ vals[i], i });
}
sort(nodes.begin(), nodes.end());
vector<int> parent(n);
vector<int> size(n, 1);
vector<int> maxIndex(n);
vector<int> maxCnts(n, 1);
for (int i = 0; i < n; i++) {
parent[i] = i;
maxIndex[i] = i;
}
int ans = n;
// Traverse the nodes in ascending order of values
for (int i = 0; i < n; i++) {
int curi = nodes[i].second;
int curv = vals[curi];
int curCandidate = parent[curi];
int curMaxIndex = maxIndex[curCandidate];
// Iterate over the neighbors
for (int nexti : graph[curi]) {
int nextv = vals[nexti];
int nextCandidate = parent[nexti];
if (curCandidate != nextCandidate && curv >= nextv) {
int nextMaxIndex = maxIndex[nextCandidate];
if (curv == vals[nextMaxIndex]) {
ans += maxCnts[curMaxIndex] * maxCnts[nextMaxIndex];
maxCnts[curMaxIndex] += maxCnts[nextMaxIndex];
}
int candidate = parent[curi] = parent[nexti] = curMaxIndex;
maxIndex[candidate] = curMaxIndex;
}
}
}
return ans;
}
int main() {
vector<int> vals = { 1, 1, 2, 2, 3 };
vector<vector<int>> edges = { {0, 1}, {1, 2}, {2, 3}, {2, 4} };
int result = numberOfGoodPaths(vals, edges);
cout << "Number of Good Paths: " << result << endl;
return 0;
}
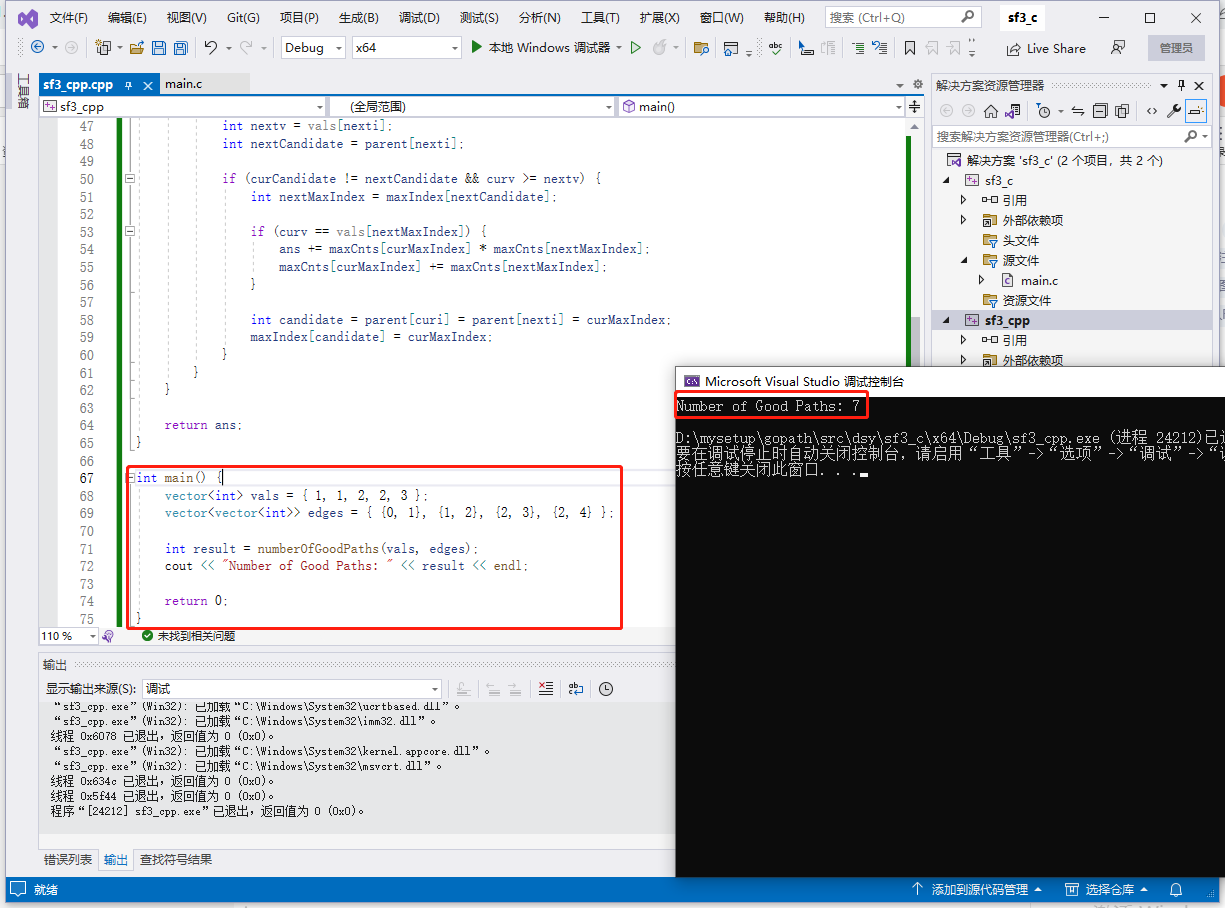
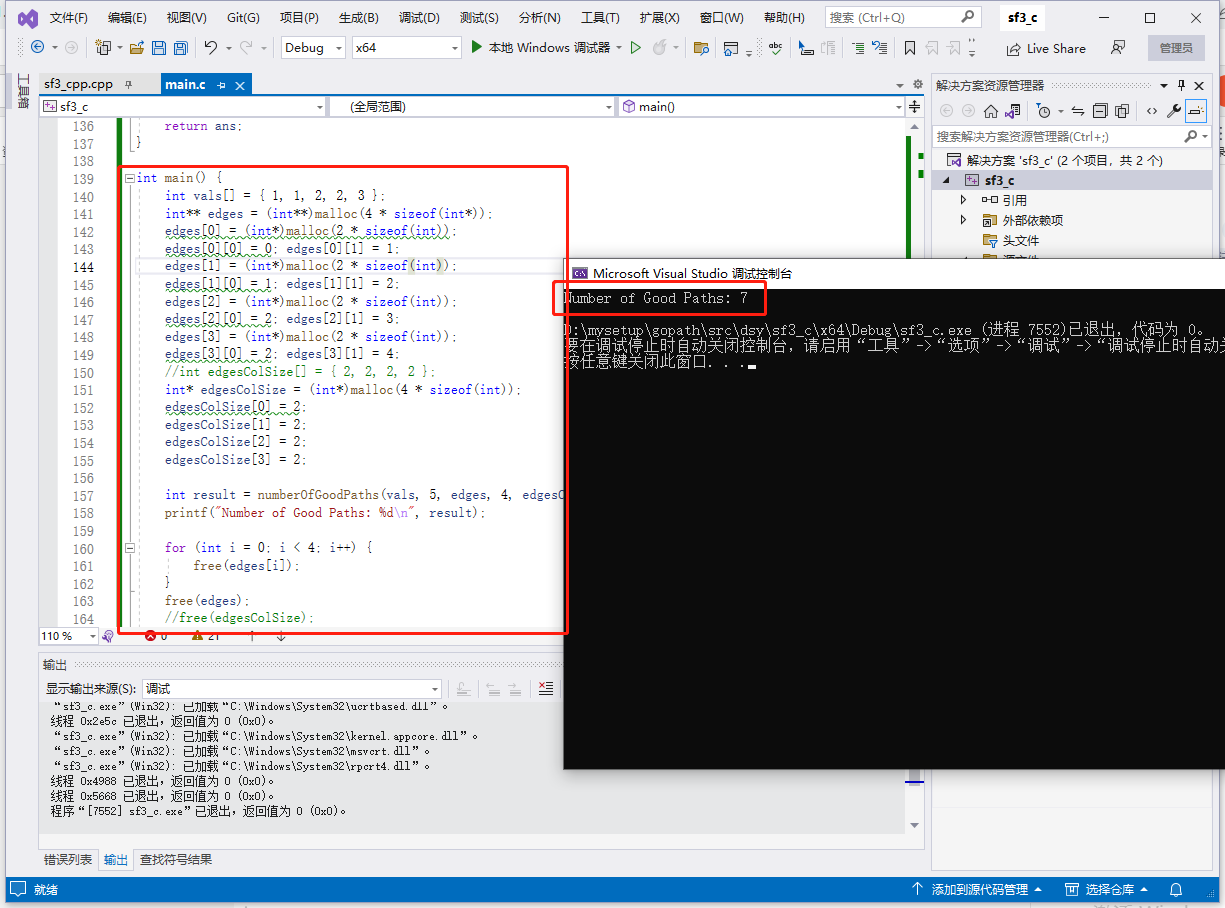
c完整代码如下:
#include <stdio.h>
#include <stdlib.h>
struct UnionFind {
int* parent;
int* size;
int* help;
};
struct UnionFind* createUnionFind(int n) {
struct UnionFind* uf = (struct UnionFind*)malloc(sizeof(struct UnionFind));
uf->parent = (int*)malloc(n * sizeof(int));
uf->size = (int*)malloc(n * sizeof(int));
uf->help = (int*)malloc(n * sizeof(int));
int i;
for (i = 0; i < n; i++) {
uf->parent[i] = i;
uf->size[i] = 1;
}
return uf;
}
int find(struct UnionFind* uf, int i) {
int hi = 0;
while (i != uf->parent[i]) {
uf->help[hi++] = i;
i = uf->parent[i];
}
for (hi--; hi >= 0; hi--) {
uf->parent[uf->help[hi]] = i;
}
return i;
}
int unionSet(struct UnionFind* uf, int i, int j) {
int f1 = find(uf, i);
int f2 = find(uf, j);
if (f1 != f2) {
if (uf->size[f1] >= uf->size[f2]) {
uf->size[f1] += uf->size[f2];
uf->parent[f2] = f1;
return f1;
}
else {
uf->size[f2] += uf->size[f1];
uf->parent[f1] = f2;
return f2;
}
}
return f1;
}
// Comparison function for qsort
int compare(const void* a, const void* b) {
int* na = *(int**)a;
int* nb = *(int**)b;
return na[1] - nb[1];
}
int numberOfGoodPaths(int* vals, int valsSize, int** edges, int edgesSize, int* edgesColSize) {
int n = valsSize;
int i, j;
// 创建图
int** graph = (int**)malloc(n * sizeof(int*));
for (i = 0; i < n; i++) {
graph[i] = (int*)malloc(n * sizeof(int));
edgesColSize[i] = 0;
}
for (i = 0; i < edgesSize; i++) {
int u = edges[i][0];
int v = edges[i][1];
graph[u][edgesColSize[u]++] = v;
graph[v][edgesColSize[v]++] = u;
}
// 创建节点数组
int** nodes = (int**)malloc(n * sizeof(int*));
for (i = 0; i < n; i++) {
nodes[i] = (int*)malloc(2 * sizeof(int));
nodes[i][0] = i;
nodes[i][1] = vals[i];
}
// 根据节点值排序
qsort(nodes, n, sizeof(nodes[0]),compare);
// 创建并初始化并查集
struct UnionFind* uf = createUnionFind(n);
int* maxIndex = (int*)malloc(n * sizeof(int));
int* maxCnts = (int*)malloc(n * sizeof(int));
for (i = 0; i < n; i++) {
maxIndex[i] = i;
maxCnts[i] = 1;
}
int ans = n;
// 遍历节点
for (i = 0; i < n; i++) {
int curi = nodes[i][0];
int curv = vals[curi];
int curCandidate = find(uf, curi);
int curMaxIndex = maxIndex[curCandidate];
// 遍历邻居
for (j = 0; j < edgesColSize[curi]; j++) {
int nexti = graph[curi][j];
int nextv = vals[nexti];
int nextCandidate = find(uf, nexti);
if (curCandidate != nextCandidate && curv >= nextv) {
int nextMaxIndex = maxIndex[nextCandidate];
if (curv == vals[nextMaxIndex]) {
ans += maxCnts[curMaxIndex] * maxCnts[nextMaxIndex];
maxCnts[curMaxIndex] += maxCnts[nextMaxIndex];
}
int candidate = unionSet(uf, curi, nexti);
maxIndex[candidate] = curMaxIndex;
}
}
}
// 释放内存
for (i = 0; i < n; i++) {
free(graph[i]);
free(nodes[i]);
}
free(graph);
free(nodes);
free(maxIndex);
free(maxCnts);
free(uf->parent);
free(uf->size);
free(uf->help);
free(uf);
return ans;
}
int main() {
int vals[] = { 1, 1, 2, 2, 3 };
int** edges = (int**)malloc(4 * sizeof(int*));
edges[0] = (int*)malloc(2 * sizeof(int));
edges[0][0] = 0; edges[0][1] = 1;
edges[1] = (int*)malloc(2 * sizeof(int));
edges[1][0] = 1; edges[1][1] = 2;
edges[2] = (int*)malloc(2 * sizeof(int));
edges[2][0] = 2; edges[2][1] = 3;
edges[3] = (int*)malloc(2 * sizeof(int));
edges[3][0] = 2; edges[3][1] = 4;
//int edgesColSize[] = { 2, 2, 2, 2 };
int* edgesColSize = (int*)malloc(4 * sizeof(int));
edgesColSize[0] = 2;
edgesColSize[1] = 2;
edgesColSize[2] = 2;
edgesColSize[3] = 2;
int result = numberOfGoodPaths(vals, 5, edges, 4, edgesColSize);
printf("Number of Good Paths: %d\n", result);
for (int i = 0; i < 4; i++) {
free(edges[i]);
}
free(edges);
//free(edgesColSize);
return 0;
}
2023-08-08:给你一棵 n 个节点的树(连通无向无环的图) 节点编号从 0 到 n - 1 且恰好有 n - 1 条边 给你一个长度为 n 下标从 0 开始的整数数组 vals 分别表示每个节的更多相关文章
- 前端面试题:不使用loop循环,创建一个长度为100的数组,并且每个元素的值等于它的下标,,怎么实现好?
昨天,看这道题,脑子锈住了,就是没有思路,没看明白是什么意思?⊙﹏⊙|∣今天早上起床,想到需要思考一下这个问题. 当然,我没想明白为什么要这样做?(创建一个长度为100的数组,并且每个元素的值等于它的 ...
- 面试题:给定一个长度为N的数组,其中每个元素的取值范围都是1到N。判断数组中是否有重复的数字
题目:给定一个长度为N的数组,其中每个元素的取值范围都是1到N.判断数组中是否有重复的数字.(原数组不必保留) 方法1.对数组进行排序(快速,堆),然后比较相邻的元素是否相同.时间复杂度为O(nlog ...
- 不用循环,、es6创建一个长度为100的数组
问题描述:在不使用循环的条件下,如何创建一个长度为100的数组,并且数组的每一个元素是该元素的下标? 结果为: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1 ...
- 用最小的空间复杂度找出一个长度为n的数组且数据中的元素是[0,n-1]中任一个重复的数据。
用最小的空间复杂度找出一个长度为n的数组且数据中的元素是[0,n-1]中任一个重复的数据. 比如:[1, 2, 3, 3, 2, 2, 6, 7, 8, 9] 中 2 or 3 分析:这道题目,实现比 ...
- 2021.08.05 P2168 荷马史诗(哈夫曼树模板)
2021.08.05 P2168 荷马史诗(哈夫曼树模板) [P2168 NOI2015] 荷马史诗 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 重点: 1.k叉哈夫曼树如果子结 ...
- 风口之下,猪都能飞。当今中国股市牛市,真可谓“错过等七年”。 给你一个回顾历史的机会,已知一支股票连续n天的价格走势,以长度为n的整数数组表示,
转自:http://www.cnblogs.com/ranranblog/p/5845010.html 风口之下,猪都能飞.当今中国股市牛市,真可谓“错过等七年”. 给你一个回顾历史的机会,已知一支股 ...
- 【编程题目】一个整数数组,长度为 n,将其分为 m 份,使各份的和相等,求 m 的最大值★★ (自己没有做出来!!)
45.雅虎(运算.矩阵): 2.一个整数数组,长度为 n,将其分为 m 份,使各份的和相等,求 m 的最大值 比如{3,2,4,3,6} 可以分成 {3,2,4,3,6} m=1; {3,6}{2,4 ...
- java—数组乘积输入: 一个长度为n的整数数组input 输出: 一个长度为n的数组result,满足result[i] = input数组中,除了input[i] 之外的所有数的乘积,不用考虑溢出例如 input {2, 3, 4, 5} output: {60, 40, 30, 24}
/** * 小米关于小米笔试题 数组乘积输入: 一个长度为n的整数数组input 输出: 一个长度为n的数组result,满足result[i] = * input数组中,除了input[i] 之外的 ...
- R中,定义一个长度为0的向量
定义一个长度为0的向量 > x<-c()> length(x)[1] 0 修改该向量的类型 > class(x)="numeric"> class(x ...
- 一个简单的算法,定义一个长度为n的数组,随机顺序存储1至n的的全部正整数,不重复。
前些天看到.net笔试习题集上的一道小题,要求将1至100内的正整数随机填充到一个长度为100的数组,求一个简单的算法. 今天有空写了一下.代码如下,注释比较详细: using System; usi ...
随机推荐
- div 让a内容居中方法
<div>标签是HTML中的一个重要标签,它代表了一个文档中的一个分割区块或一个部分.在<div>标签中,我们可以放置各种内容,包括文本.图像.链接等等.有时候,我们需要将其中 ...
- Django框架——模板层
文章目录 1 模板层 一 模版简介 二 模版语法之变量 views.py html文件 三 模版之过滤器 语法: default length filesizeformat date slice tr ...
- ssr服务器极致渲染
域名 RDS 云服务器 ECS 中国站 文档购物车ICP备案控制台 金秋上云季 首页 技术与产品 社区 直播 开发者学堂 开发者云 工具与资源中心 天池大赛 飞 ...
- C#堆排序算法
前言 堆排序是一种高效的排序算法,基于二叉堆数据结构实现.它具有稳定性.时间复杂度为O(nlogn)和空间复杂度为O(1)的特点. 堆排序实现原理 构建最大堆:将待排序数组构建成一个最大堆,即满足父节 ...
- Maximum Diameter 题解
Maximum Diameter 题目大意 定义长度为 \(n\) 的序列 \(a\) 的权值为: 所有的 \(n\) 个点的第 \(i\) 个点的度数为 \(a_i\) 的树的直径最大值,如果不存在 ...
- 【Unity3D】UI Toolkit容器
1 前言 UI Toolkit简介 中介绍了 UI Builder.样式属性.UQuery.Debugger,UI Toolkit元素 中介绍了 Label.Button.TextField.To ...
- 利用Zip.js压缩并上传文件,后端使用.Net(Winform)接收转存
没时间解释了,快上车... 前端js: upload=function () { if(window.FormData) { var fileslist=$("input[type='fil ...
- MySQL锁:InnoDB行锁需要避免的坑
前言 换了工作之后,接近半年没有发博客了(一直加班),emmmm.....今天好不容易有时间,记录下工作中遇到的一些问题,接下来应该重拾知识点了.因为新公司工作中MySQL库经常出现查询慢,锁等待,节 ...
- 自然语言处理历史史诗:NLP的范式演变与Python全实现
本文全面回顾了自然语言处理(NLP)从20世纪50年代至今的历史发展.从初创期的符号学派和随机学派,到理性主义时代的逻辑和规则范式,再到经验主义和深度学习时代的数据驱动方法,以及最近的大模型时代,NL ...
- 聊聊 GPU 产品选型那些事
随着人工智能的飞速崛起,随之而来的是算力需求的指数级增加,CPU 已经不足以满足深度学习.大模型计算等场景的海量数据处理需求.GPU 作为一种强大的计算工具,无论是高性能计算.图形渲染还是机器学习领域 ...