【行云流水线】满足你对工作流编排的一切幻想~skr
流水线模型
众所周知,DevOps流水线(DevOps pipeline)的本质是实现自动化工作流程,用于支持软件开发、测试和部署的连续集成、交付和部署(CI/CD)实践。它是DevOps方法论的核心组成部分,旨在加速软件交付、提高质量和实现持续改进。流水线的核心是流水线模型,是实现工作流编排,执行的重要基石,一个优秀的流水线模型可以覆盖用户更多的实践场景,按照用户的所思所想支持编排相应的工作流程,通过模型的分层设计,通用原子能力的生态建设,尽可能满足用户的任意场景的需求。
流水线模型基于将整个工作流程划分为一系列连续的阶段或任务,并通过将每个阶段的输出作为下一个阶段的输入,实现高效的生产或处理流程。每个阶段专注于特定的任务,并将其结果传递给下一个阶段,以便整个过程能够连续地进行。
优秀的流水线模型特征
生活中的流水线
说起生活中的流水线大家可能想到的是车间,厂房中的流水线。这个也是经常被拿出来举例的场景。但我今天不举这个例子。大家可以思考下这两个场景有什么区别?

任天堂Switch有一款叫做“胡闹厨房”的游戏,俗称“分手厨房”,据说一玩就分手。这是一款以高难度合作著称的游戏,在形形色色的厨房中,你需要和你的同伴一起克服重重难关,按照指定的顺序生产出美味佳肴,满足客人的味蕾。在游戏过程中,制作一道菜需要完成许多的步骤,这就像我们在工作中使用的流水线,流水线有个总目标,也会拆分成几个阶段来完成分阶段的目标,作为下个阶段的输入。
这里我们以“制作Pizza”的流程为例,简单的把操作拆分为4个阶段:准备食材Prepare(如鸡肉,起司,青椒等),揉面Knead(面粉,油,发酵),制作(组合准备的食材与披萨底座),最终烘焙完成。在整个流程中,前后阶段是隐含着依赖关系,并驱动每一个阶段继续执行下去。

回想我们在实际工作中的流程,往往并不能通过简单的串联并联解决问题。都是有依赖关系的执行流程,场景可能比以上例子更复杂。

行云流水线模型升级
在众多流水线能力中,工作流的编排和执行能力是最核心的能力,也是用户实现自定义流程配置的基础和载体。行云流水线通过把流程中的不同阶段和任务串联在一起,实现提高阶段见的连接效率,通过阶段内部的垂直领域原子能力,实现阶段内各个原子或步骤的执行效率提升。
为了能更好的支撑用户的使用场景,云原生流水线升级了工作流模型。
流水线模型与交付流程的映射

竞品分析
对比Harness,Azure,Github Actions等平台在不同pipeline维度的模型策略
| 行云流水线 | Harness | Azure | Github | 云效 | |
| 执行模式-Stage级 | DAG 默认parallel | serial/parallel | DAG 默认serial | DAG 默认parallel | serial |
| 执行模式-Job/Atom级 | serial | serial/parallel | serial | serial | parallel |
| 编排模式-图形化 | |||||
| 编排模式-yaml |
serial:只串行执行 parallel:只并行执行 serial/parallel:支持串并行组合方式,编排workflow DAG:依赖声明方式编排workflow 默认serial:无依赖声明的步骤,串行编排 默认parallel:无依赖声明的步骤,并行编排
平台用户的最佳实践
场景1:测试环境的按需更新与测试
测试环境一般不是独立存在的,可能也不是只更新某一个服务就可以满足测试条件的。在这种情况下,用户结合环境拓扑的概念,先基于拓扑创建一套环境,再更新所需的多个服务实例,以快速,自动化的方式实现测试环境的按需更新。通过准入流水线,创建测试环境(创建拓扑环境,更新拓扑节点等),并进行接口测试

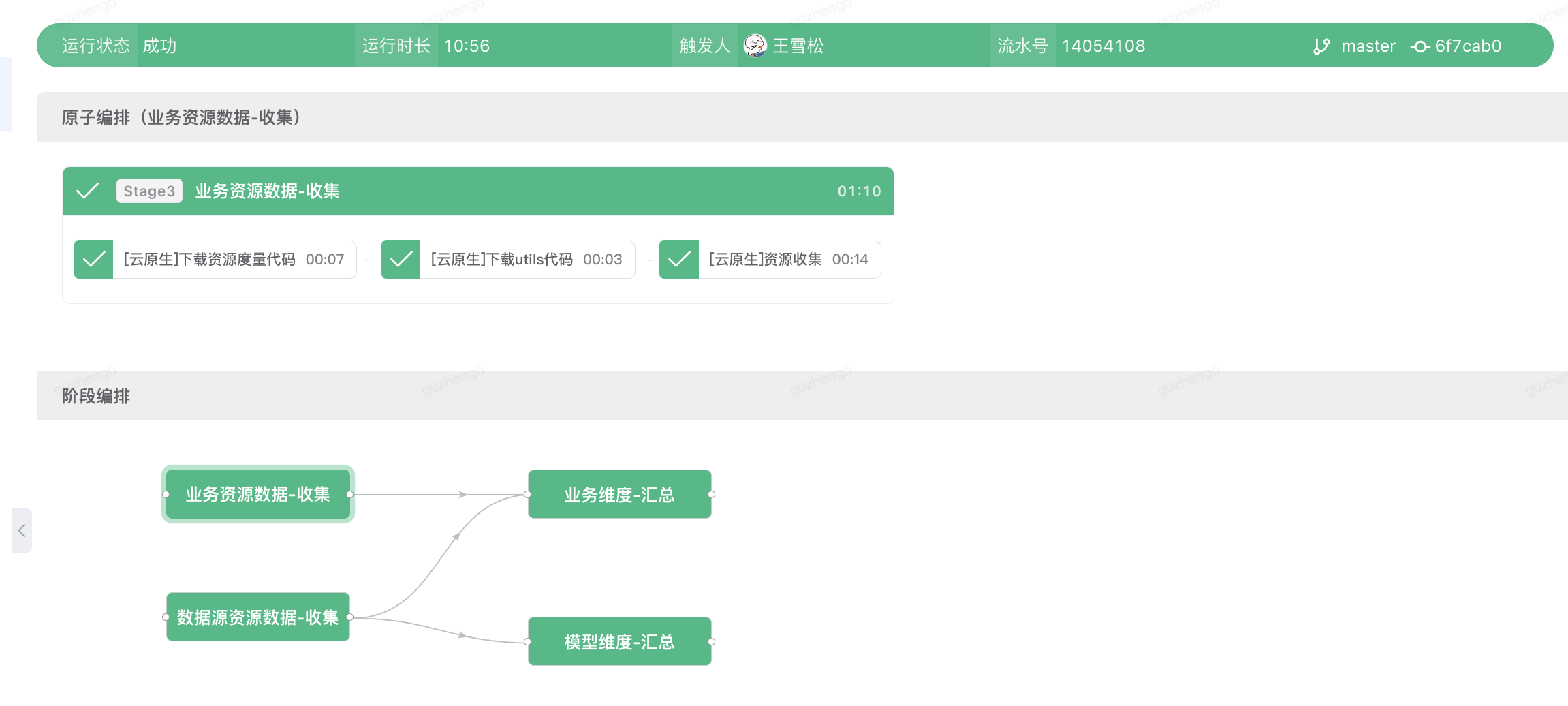
下图为用户流水线编排界面


场景2:多维度的数据资源收集与分析
在数据分析的业务场景下,此流水线支持SRAS搜推算法服务,作为推送模型到线上的前置准备任务。用户需要收集多维度的数据源信息,通过扇入的方式聚合数据,并通过python脚本逻辑做数模型据汇总
云原生流水线编排功能介绍
入口:流水线列表或流水线构建记录页,点击“配置流水线”

编排界面布局:下方为阶段编排,点击其中一个stage时,上方显示stage内的原子排列顺序

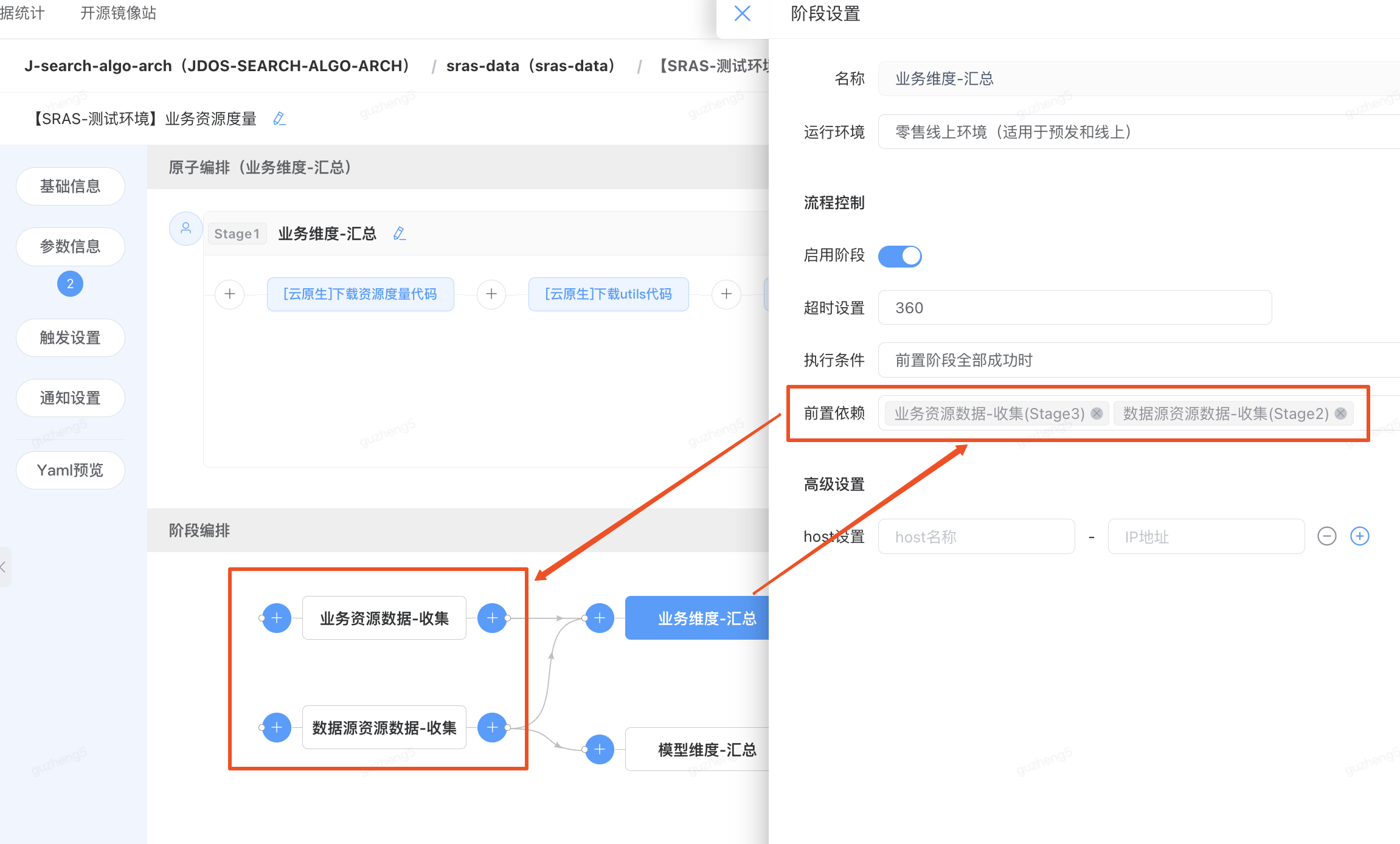
1)添加阶段
图形化的“阶段编排”快速搭建流程,在每个stage的前后分别会有一个“”号,此加号作用是建立前后依赖关系。当点击左侧加号时,添加前置依赖阶段;点击右侧加号时,添加依赖于当前阶段的后续阶段。在点击完成的同时,弹出stage模版(分阶段选择)添加创建。

点击右侧加号,选择开发阶段中的Java单元测试模版
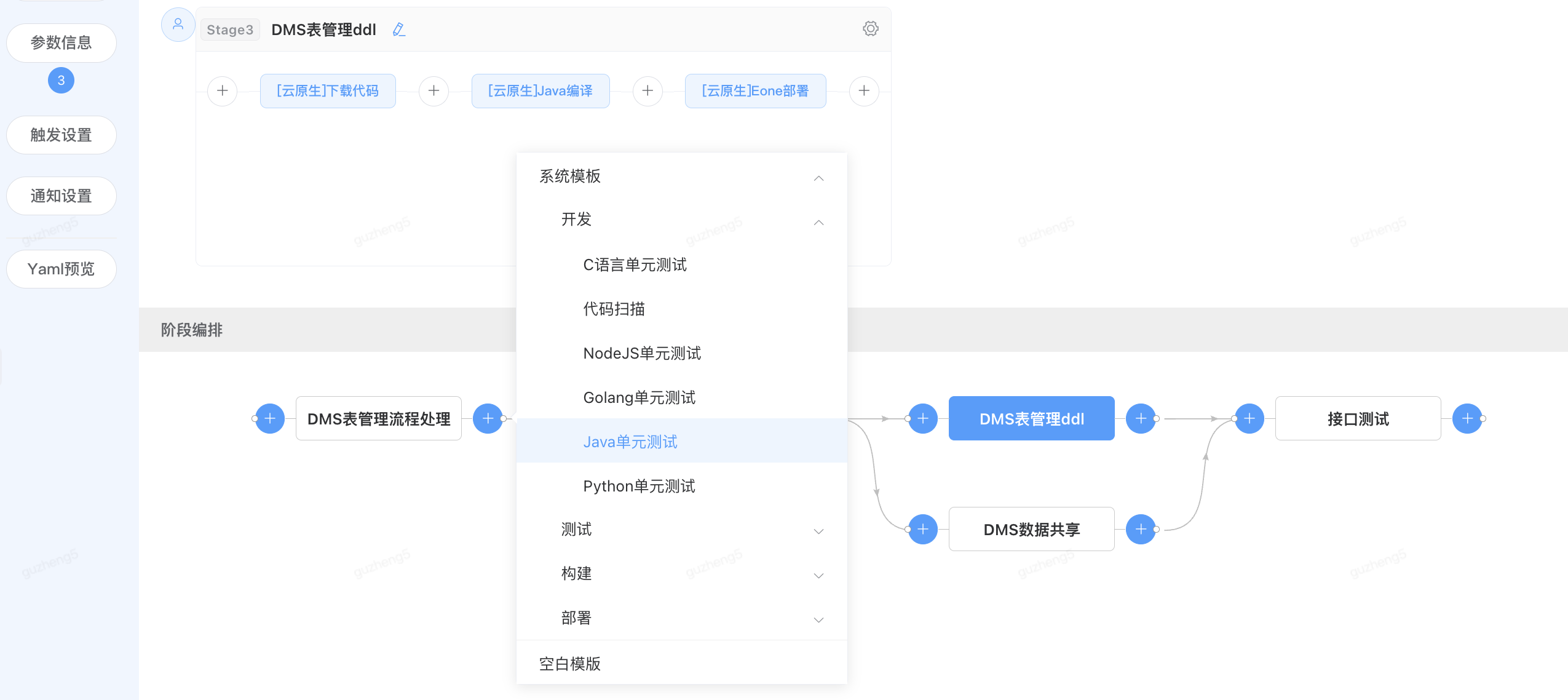
快速添加后续执行阶段,并在上方显示原子编排顺序
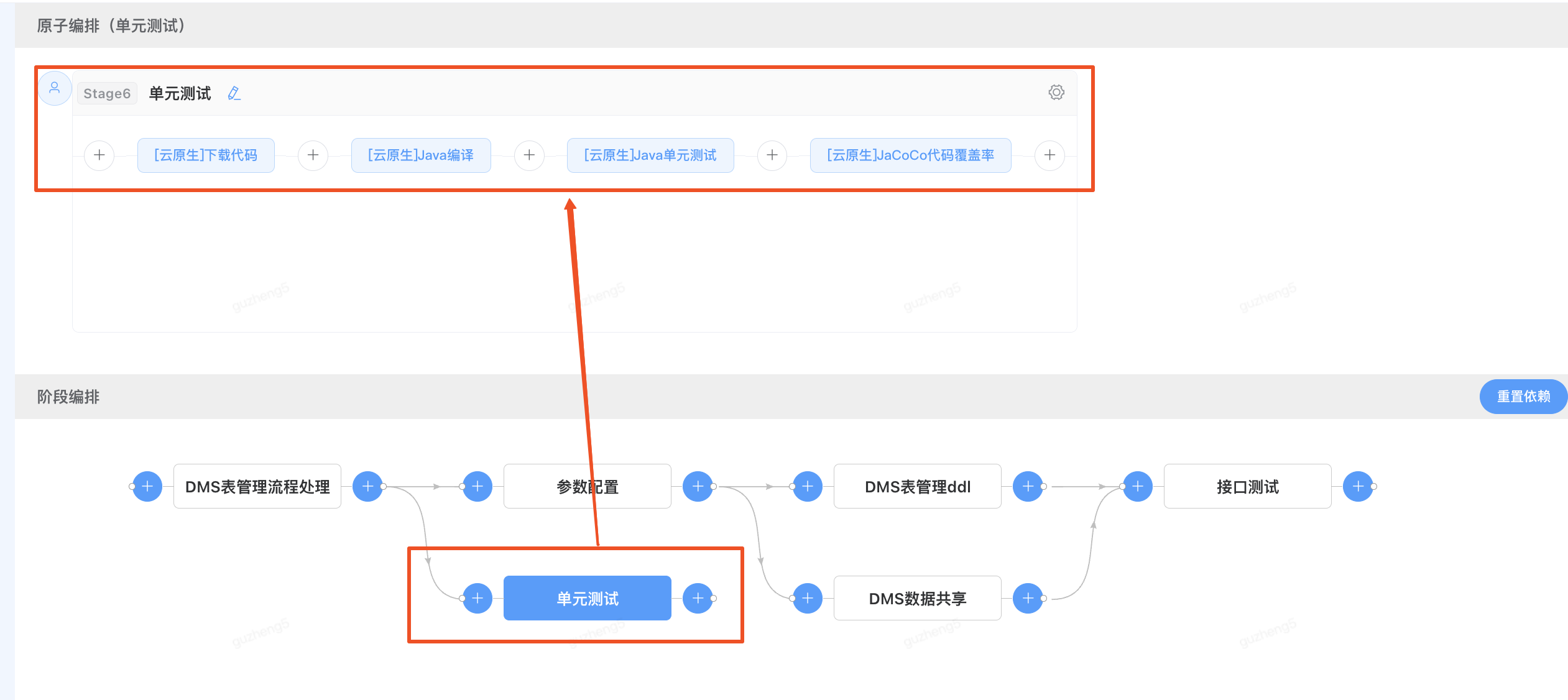
查看单元测试阶段的依赖设置,前置依赖-“DMS表管理流程处理”
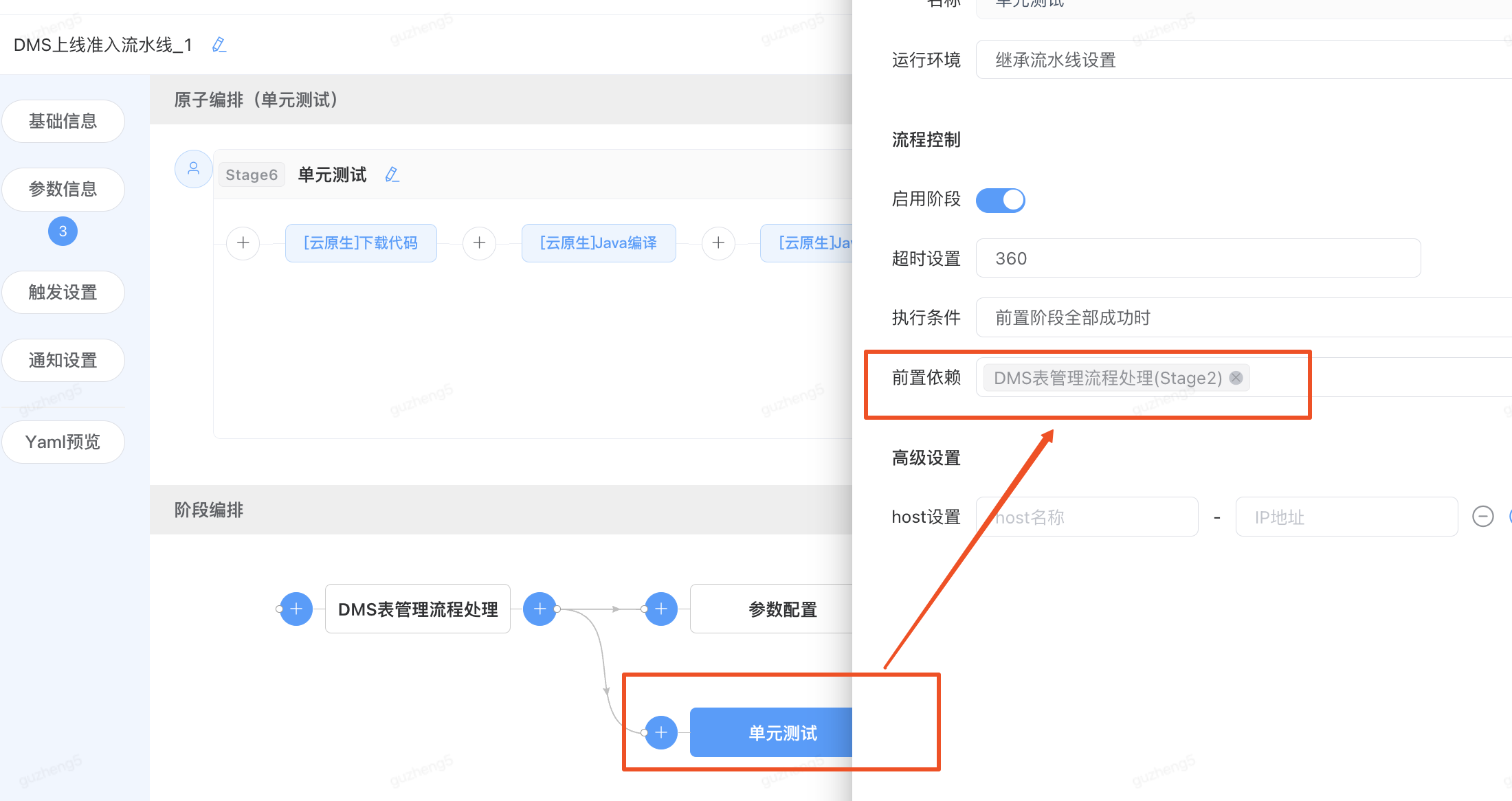
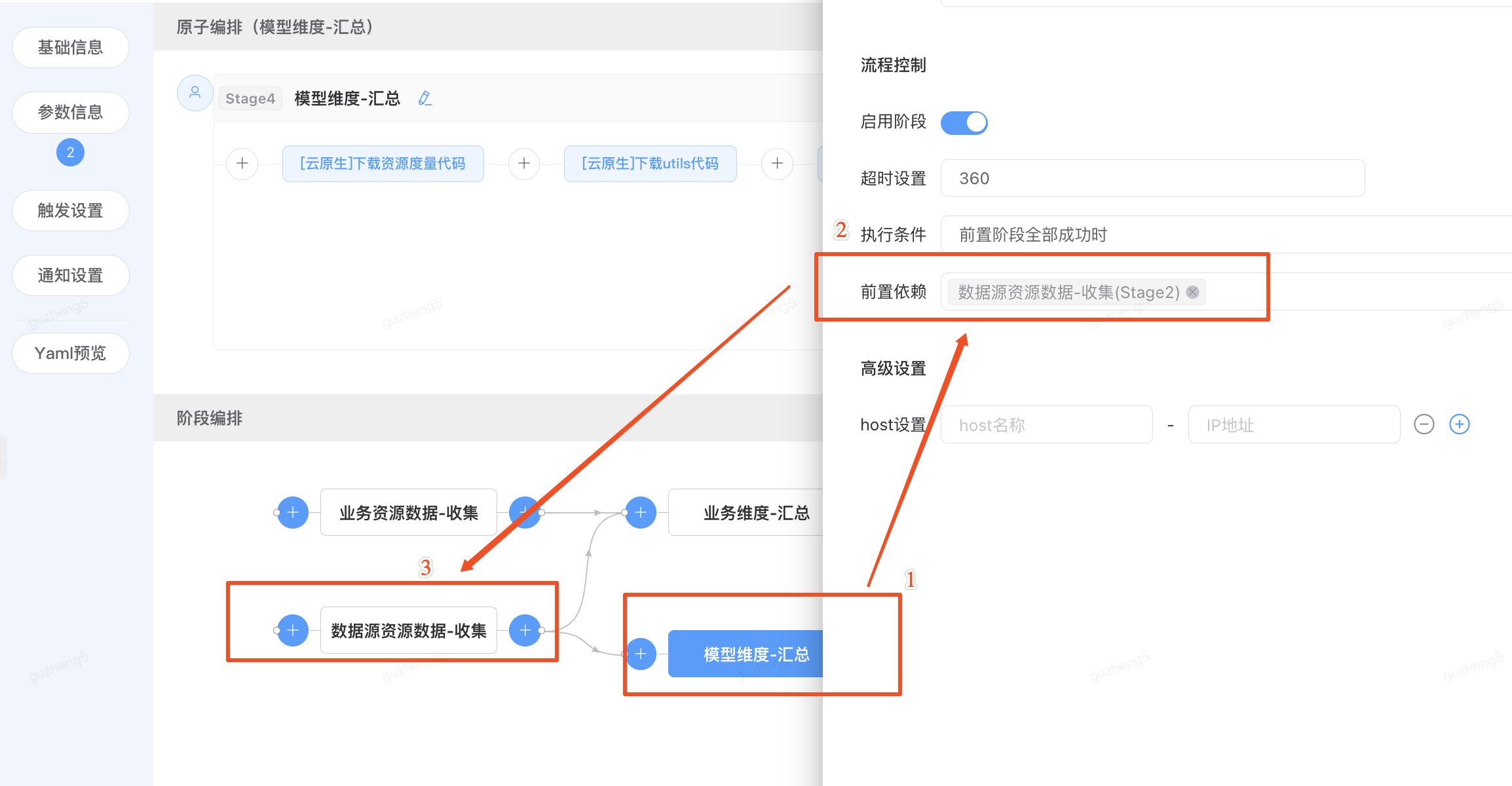
2)调整依赖阶段
当调整“单元测试阶段”到DMS数据共享阶段之后执行
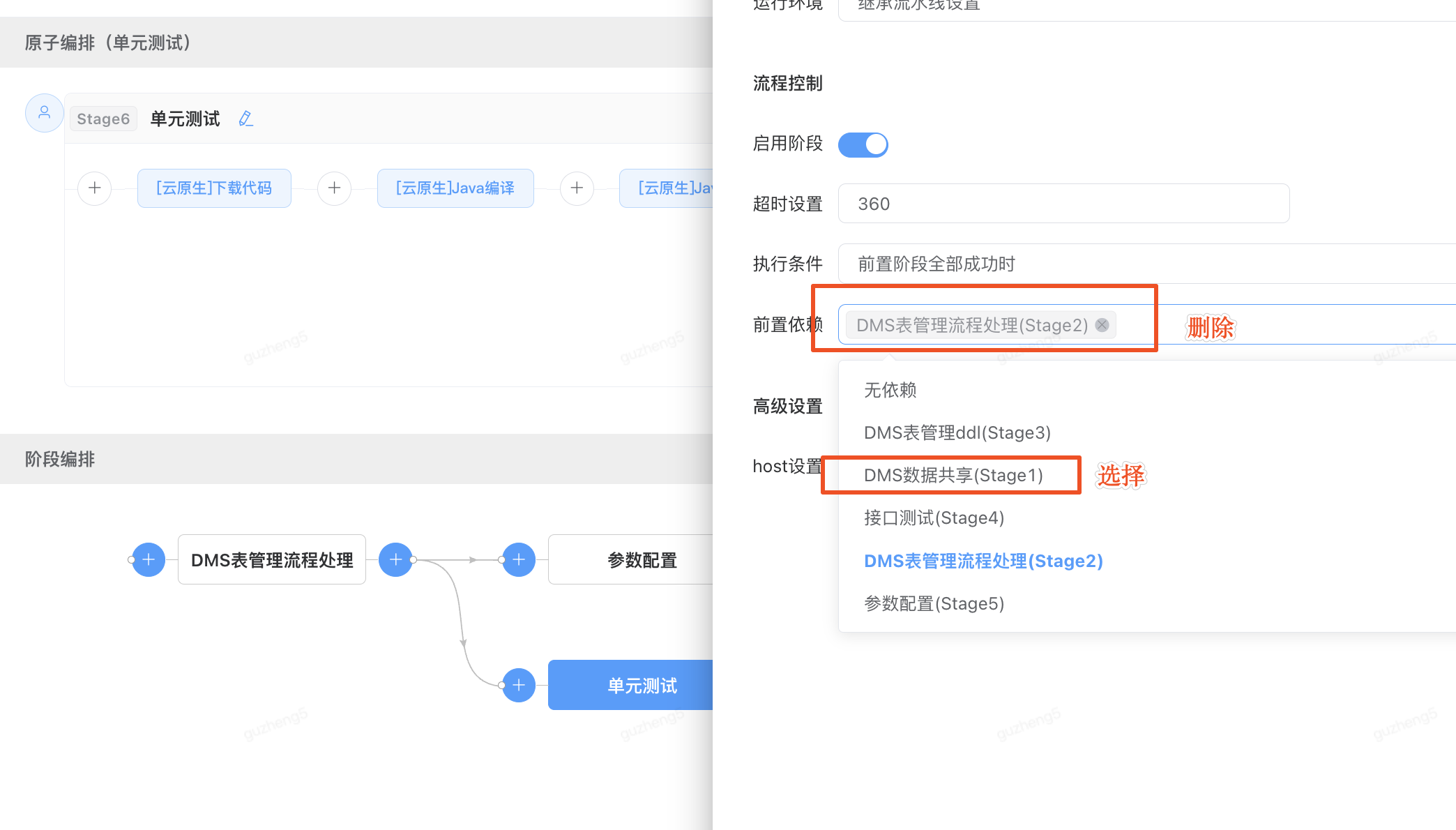
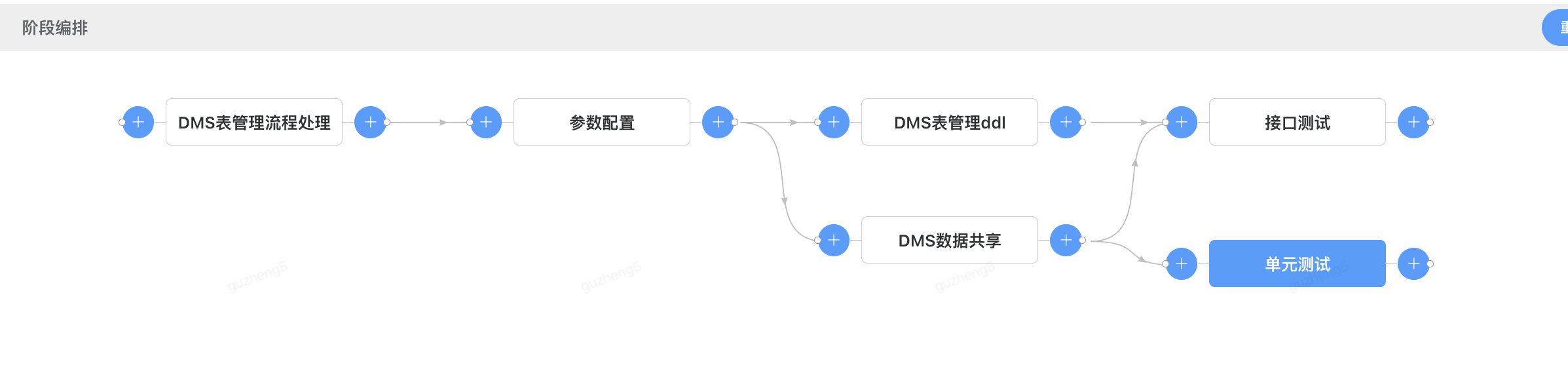
3)删除阶段
stage右上角直接删除并确认

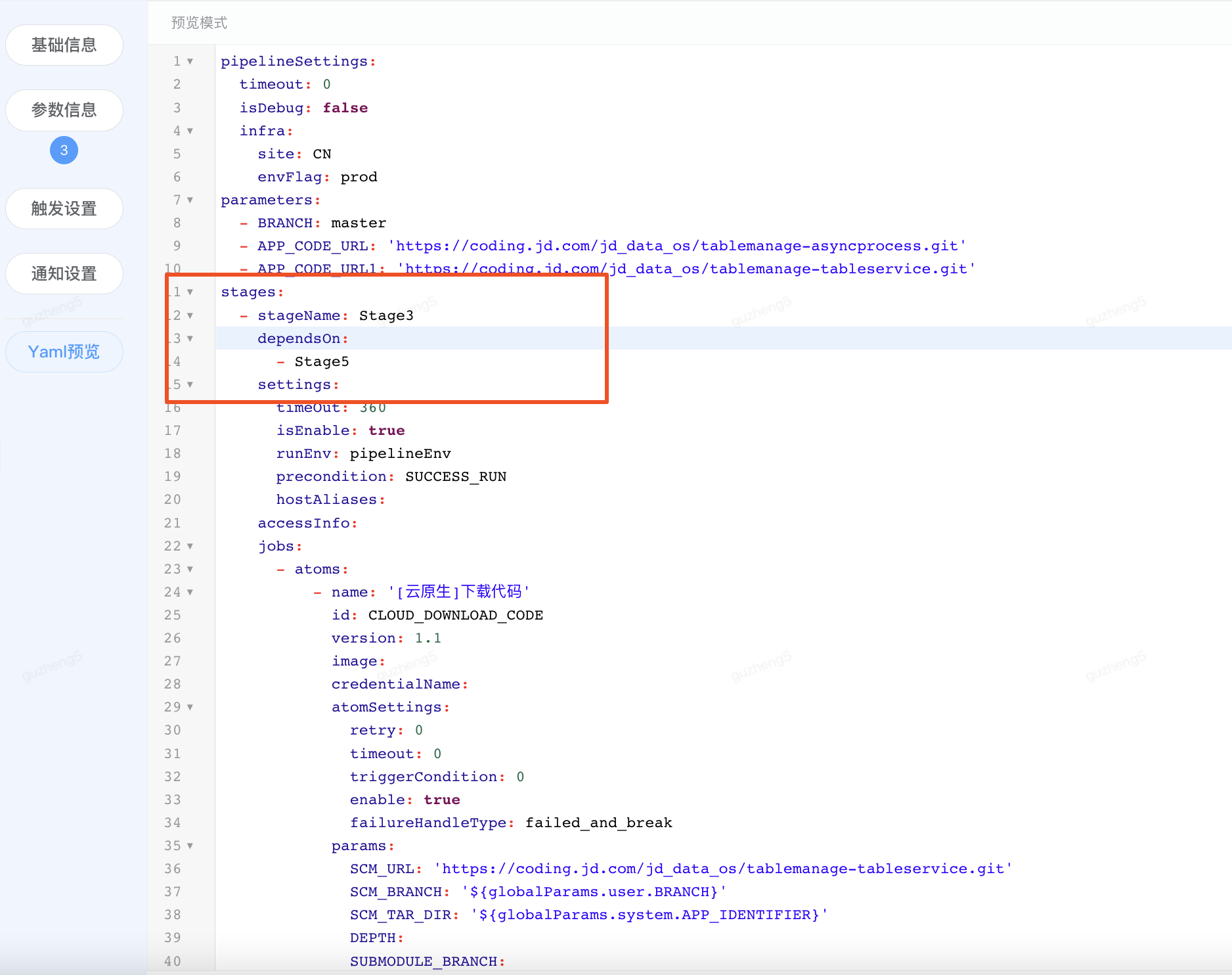
4)Yaml配置中的依赖关系
现阶段开放依赖关系的查看,可通过yaml方式导出创建具备DAG模式的流水线模型,后续将开放编排yaml功能
Q&A
Q:流水线模型的升级与级联流水线冲突吗?
A:不冲突,从能力上看,级联流水线只具备简单的扇出能力,不具备扇入能力,也不具备复杂流程的编排能力。级联流水线更多的是支持通过流水线A触发流水线B的触发模式。级联流水线在配置上,参数传递上都比较复杂,用户使用,大规模应用成本较高。我们希望随着云原生流水线模型的升级,未来逐步替代级联流水线,并支持用户更多场景。
以上介绍了云原生流水线模型升级的价值,解决的问题,用户实践,简单上手操作等。后续随着用户使用场景的增加,我们会持续介绍用户实践,技术探索等等。欢迎大家提出建议或吐槽。
作者:京东零售 顾铮
来源:京东云开发者社区 转载请注明来源
【行云流水线】满足你对工作流编排的一切幻想~skr的更多相关文章
- 云原生流水线 Argo Workflow 的安装、使用以及个人体验
注意:这篇文章并不是一篇入门教程,学习 Argo Workflow 请移步官方文档 Argo Documentation Argo Workflow 是一个云原生工作流引擎,专注于编排并行任务.它的特 ...
- 【敏捷研发系列】前端DevOps流水线实践
作者:胡骏 一.背景现状 软件开发从传统的瀑布流方式到敏捷开发,将软件交付过程中开发和测试形成快速的迭代交付,但在软件交付客户之前或者使用过程中,还包括集成.部署.运维等环节需要进一步优化交付效率.因 ...
- Pipeline流水线设计的最佳实践
谈到到DevOps,持续交付流水线是绕不开的一个话题,相对于其他实践,通过流水线来实现快速高质量的交付价值是相对能快速见效的,特别对于开发测试人员,能够获得实实在在的收益.很多文章介绍流水线,不管是j ...
- 面向多场景而设计的 Erda Pipeline
作者|林俊(万念) 来源|尔达 Erda 公众号 Erda Pipeline 是端点自研.用 Go 编写的一款企业级流水线服务.截至目前,已经为众多行业头部客户提供交付和稳定的服务. 为什么我们坚持自 ...
- 印尼医疗龙头企业Halodoc的数据平台转型之Lakehouse架构
1. 摘要 在 Halodoc,我们始终致力于为最终用户简化医疗保健服务,随着公司的发展,我们不断构建和提供新功能. 我们两年前建立的可能无法支持我们今天管理的数据量,以解决我们决定改进数据平台架构的 ...
- 从函数计算到 Serverless 架构
前言 随着 Serverless 架构的不断发展,各云厂商和开源社区都已经在布局 Serverless 领域,一方面表现在云厂商推出传统服务/业务的 Serverless 化版本,或者 Serverl ...
- Serverless Streaming:毫秒级流式大文件处理探秘
摘要:本文将以图片处理的场景作为例子详细描述当前的问题以及华为云FunctionGraph函数工作流在面对该问题时采取的一系列实践. 文章作者|旧浪:华为云Serverless研发专家.平山:华为云中 ...
- 一文快速了解MaxCompute
很多刚初次接触MaxCompute的用户,面对繁多的产品文档内容以及社区文章,往往很难快速.全面了解MaxCompute产品全貌.同时,很多拥有大数据开发经验的开发者,也希望能够结合自身的背景知识,将 ...
- 轻松构建基于 Serverless 架构的弹性高可用音视频处理系统
前言 随着计算机技术和 Internet 的日新月异,视频点播技术因其良好的人机交互性和流媒体传输技术倍受教育.娱乐等行业青睐,而在当前, 云计算平台厂商的产品线不断成熟完善, 如果想要搭建视频点播类 ...
- 高德最佳实践:Serverless 规模化落地有哪些价值?
作者 | 何以然(以燃) 导读:曾经看上去很美.一直被观望的 Serverless,现已逐渐进入落地的阶段.今年的"十一出行节",高德在核心业务规模化落地 Serverless,由 ...
随机推荐
- AUC/ROC:面试中80%都会问的知识点
摘要:ROC/AUC作为机器学习的评估指标非常重要,也是面试中经常出现的问题(80%都会问到) 本文分享自华为云社区<技术干货 | 解决面试中80%问题,基于MindSpore实现AUC/ROC ...
- iOS distribution发布证书过期或者被手动revoke了app会被下架吗?
在距离distribution 证书过期一个月(或被手动revoke了)的时候会受到apple的邮件 编辑 虽然distribution过期(或者被手动revoke)了,如果你的开发者账号是co ...
- 【调试】sysRq按键使用方法
SysRq键简介 SysRq键是一个魔术案件,只要在内核没有完全卡死的情况下,内核都会相应SysRq 键的输入,使用这些组合键都可以搜集包括系统内存使用.CPU任务处理.进程运行状态等系统运行信息. ...
- Ubuntu 18.04安装arm-linux-gcc交叉编译器的两种方法(附下载地址)
方法一: 我们都知道Ubuntu有一个专门用来安装软件的工具apt,我们可以用它来全自动安装arm-linux-gcc. 此方法安装的是最新版的,但是此方法需要FQ,否则99%会失败,这就是为 ...
- 深度学习基础课:“判断性别”Demo需求分析和初步设计(上)
大家好~我开设了"深度学习基础班"的线上课程,带领同学从0开始学习全连接和卷积神经网络,进行数学推导,并且实现可以运行的Demo程序 线上课程资料: 本节课录像回放 扫码加QQ群, ...
- 如何一键私有化部署 Laf ?
太长不看:Laf 上架了 Sealos 的模板市场,通过 Laf 应用模板即可一键部署! Laf 是一个完全开源的项目,除了使用公有云之外,还有大量的用户选择私有化部署 Laf.然而,私有化部署通常伴 ...
- C#利用控件实现柱形图分析
数据 { using (SqlConnection con = new SqlConnection("server=.;uid=sa;pwd=;database=db_TomeOne&quo ...
- mvn 编译异常:Fatal error compiling: 无效的标记: -parameters
错误信息: [ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin::compile (defaul ...
- 【C/C++】宏参数多对一和宏部分替换
宏参数多对一:使用分号分隔多参数 宏部分替换:替换需要转换的再与后续宏接续 #include <stdio.h> #define _MESS_FAILED() printf("% ...
- 2023 SHCTF-校外赛道 MISC WP
WEEK1 请对我使用社工吧 提示:k1sme4的朋友考到了一所在k1sme4家附近的大学,一天,k1sme4的朋友去了学校对面的商场玩,并给k1sme4拍了一张照片,你能找到他的学校吗? flag格 ...