[转帖]陈巍谈芯:NLP里比BERT更优秀的XLNet长什么样?
https://zhuanlan.zhihu.com/p/447836322
本文适合适合AI芯片设计人员入门与芯片赛道投资人了解技术内涵。
■ 陈巍,资深芯片专家,人工智能算法-芯片协同设计专家,擅长芯片架构与存算一体。
相关推荐
陈巍谈芯:什么是存算一体技术?发展史、优势、应用方向、主要介质(收录于存算一体芯片赛道投资融资分析)
陈巍谈芯: 3.5 目标检测网络SSD —《AI芯片设计:原理与实践》节选
陈巍谈芯:7.2 RRAM模拟存内计算 《先进存算一体芯片设计》节选
陈巍谈芯:7 分析实战:Hopper架构——《GPGPU 芯片设计:原理与实践》节选

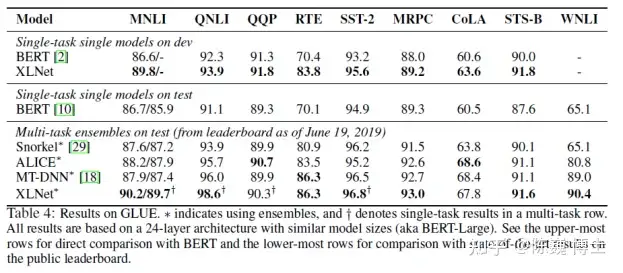
自从BERT模型夺得NLP(自然语言处理)武林大赛桂冠后,就不断有年轻的后辈前来挑战切磋。
之后踢馆成功出名的是CMU的Zhilin Yang等提出的XLNet。
这个新的NLP武林盟主号称在20项任务比拼中撸了BERT模型的羊毛。
废话不多说,让我们看看这XLNet到底厉害在哪里,招式如何?
一、XLNet的优势
先放上原文源码地址为敬:
论文地址:https://arxiv.org/pdf/1906.08237.pdf
预训练模型及代码地址:https://github.com/zihangdai/xlne
我们再看看XLNet这小伙子的优势:
1)独得AR与AE两大绝学
一直以来,AR(autoregressive,自回归)与AE(autoencoding,自编码)就是无监督表征学习中的两大绝学。
AR语言模型基于大量语料统计,被训练为编码单向上下文。AE则通过被掩盖的输入重建原始数据(例如BERT),弥补了双向信息的损失,但却由于信息的掩盖导致训练与实际推理的偏差。
XLNet的出现一开始就对准了这两个绝学的命门。
首先,XLNet借鉴NADE中的置换(Permutation),考虑句段各种分解顺序的可能性。这样就把上下文信息都加进的AR的计算之中。
其次,XLNet训练不再依赖于数据遮盖(Mask),这样就把BERT训练时遮遮掩掩与实际推理的偏差规避了。
2)集成了Tansformer-XL
借助了Tansformer-XL(戏称:超大号变形金刚)的循环机制和相对位置编码。(后面会详细介绍)从而改善了长文本序列的客户体验与准确度。
二、XLNet的结构特点
1) 置换语言模型(PermutationLanguage Modeling,PLM)
Permutation(置换)是个很有意思的数学思想。
其最早的实践大概来自于Fisher提出的置换检验(Permutation Test)。就是利用样本的随机排列进行统计分析和推断。置换这个概念非常适合总体分布未知的样本数据。
XLNet借用最近提出的了OrderlessNADE想法来实现置换。把序列中所有的元素都放到计算袋子里求最大期望:
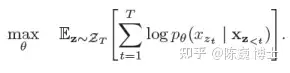
这一模型收集了元素两端所有位置的信息来进行训练,从而具备了捕获双向上下文的能力。
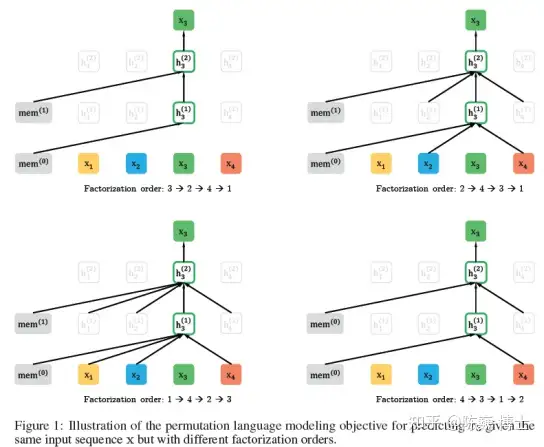
不同排列对x3的预测
又例如,以句子序列
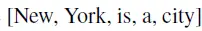
为例,假设
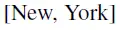
是预测目标。XLNet和BERT的期望计算可以近似理解为:
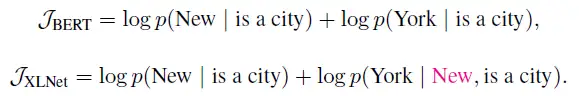
2) 双流自注意(Two-StreamSelf-Attention)机制
所谓的双流,就是内容(Contenet)与查询(Query)。通过这两组Attention,来进行PLM的训练。
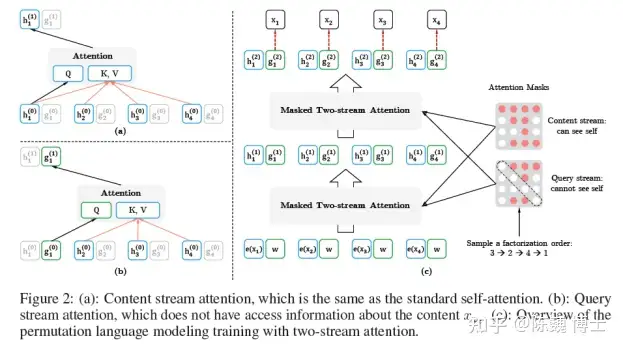
Content流与Query流的定义如下:
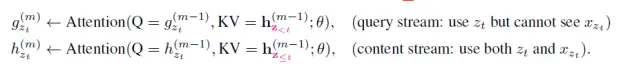
Q,K,V分别表示Attention中的Query,Key和Value。
Content流提供了完整的上下文信息用于AR的完整期望训练,而Query提供了类似掩盖的方式来增强预测。
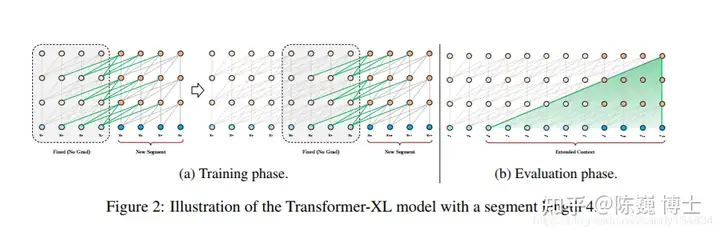
3)引入Transformer-XL
Transformer-XL 是在VanillaTransformer的基础上诞生的。
长程依赖现象在序列数据很常见。例如常见的订票问答中的一个回答,可能要参照若干条对话之前订票人员信息。Vanilla Transformer使用固定长度上下文在数据单元之间建立直接的长程依赖关系。但这也使得句子边界附近的上下文碎片化。

具有固定长度上下文的Vanilla Transformer
具有句段循环的 Transformer-XL
Transformer-XL则引入了两个关键工作:
1) 循环机制(RecurrenceMechanism)
2) 相对位置编码(RelativePositional Encoding)
先说循环机制。在训练期间,为前一个句段计算的表征会被修正并缓存,当处理下一句段时,前一个句段即作为扩展上下文使用。
在Transformer-XL中,相对位置信息由一组位置编码提供,即相对位置编码。
基于上述两点,Transformer-XL 学习的依赖关系大约比传统RNN 长 80%,比 Vanilla Transformer 长 450%。当然,Transformer-XL由于参数量巨大,训练和推理所需的算力也是很大的(烧钱的)。
很有意思的是,Transformer-XL的论文投稿到 ICLR 2019 是被毫不留情的拒绝了的。估计也是评委们心里暗想土豪(TPU的所有者,Google的卡丽熙,算力吞噬者……)就不要用钱砸场子了。
三、XLNet与BERT模型带来的NLP算力竞赛
XLNet确实对得起它的名字,XL号的,训练时使用了512块 TPU v3芯片!
要知道,这可是极度碾压阿尔法狗的算力啊,相当于XL学问答要用几百个李世石的围棋脑力。
我们从自然界的角度来看,似乎可以看到一些端倪:
大部分昆虫凭借很小的脑容量就可以拥有视觉能力,却难以通过语音交互;
大部分小型哺乳动物拥有中等的脑容量可以通过语音交互(类似于ASR之类的命令词)却难以进行复杂的表达和对话(类似NLP的多轮对话);
目前看,几乎只有人类,拥有较大的脑容量和几乎最大的脑重比,才可以进行复杂的自然语言处理和理解。
BERT、XLnet和自然界,似乎在暗示我们:算力,应该是类人NLP的基础。
人工智能领域的竞赛,正逐渐变为算力和芯片的角逐。芯片,正成为人工智能体系中必不可少的一环。
[转帖]陈巍谈芯:NLP里比BERT更优秀的XLNet长什么样?的更多相关文章
- 【转帖】 解开龙芯与mips4000的关系
-- 苏联给的套件,我们只要把电子管插上就好. -- 千万次机器,不晓得来源 DJS-130系列,16位小型机,仿造美国NOVA DJS-180系列,超级小型机,仿造美国DEC VAX, 能跑DEC的 ...
- NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268 NLP突破性成果 BERT 模型详细解读 章鱼小丸子 不懂算法的产品经理不是好的程序员 关注她 82 人赞了该文章 Goo ...
- 此utf8 非彼utf8 ——谈http协议里的编码问题
我这里看两个编码: BDPAGETYPE:2BDQID:0xc92b034d0bc985e8BDUSERID:809441751 Cache-Control:private Connection:Ke ...
- JS 浅谈函数柯里化,不明觉厉
在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术.这个技术由 Christopher ...
- Hadoop概念学习系列之谈hadoop/spark里为什么都有,YARN呢?(四十一)
在Hadoop集群里,有三种模式: 1.本地模式 2.伪分布模式 3.全分布模式 在Spark集群里,有四种模式: 1.local单机模式 结果xshell可见: ./bin/spark-submit ...
- Hadoop概念学习系列之谈hadoop/spark里为什么都有,键值对呢?(四十)
很少有人会这样来自问自己?只知道,以键值对的形式处理数据并输出结果,而没有解释为什么要以键值对的形式进行. 包括hadoop的mapreduce里的键值对,spark里的rdd里的map等. 这是为什 ...
- [转帖]疑似兆芯开先KX-7000跑分曝光:IPC性能大幅提升
疑似兆芯开先KX-7000跑分曝光:IPC性能大幅提升 https://www.bilibili.com/read/cv4028300 数码 11-23 1589阅读28点赞22评论 尽管有ARM架构 ...
- Hadoop概念学习系列之谈hadoop/spark里分别是如何实现容错性?(四十二)
Hadoop使用数据复制来实现容错性(I/O高) Spark使用RDD数据存储模型来实现容错性. RDD是只读的.分区记录的集合.如果一个RDD的一个分区丢失,RDD含有如何重建这个分区的相关信息. ...
- [转帖] 知乎: 为什么品牌机器里面的VTX都是关闭的..
为何品牌机BIOS中的硬件虚拟化都是默认关闭的? 知乎老狼原创: https://www.zhihu.com/question/40381254/answer/499617881 谢邀.先说结论, ...
- 谈一谈关于NODE里的N管理
模块可能与当前的NODE版本不和,NODE升级问题? 一切尽在掌握 1.首先设置好PATH(你安装的目录) Debian系列: sudo gedit /etc/profile Redhat系列: su ...
随机推荐
- 华为云 UCS GitOps:轻松交付多集群云原生应用
摘要:使用华为云 UCS GitOps 配置管理来交付您的多云应用. 本文分享自华为云社区<华为云 UCS GitOps:轻松交付多集群云原生应用>,作者:华为云云原生团队. 随着业务的全 ...
- 古有诸葛亮八卦阵阻敌,今有 iptables 护网安
摘要:保障网络环境的安全,我们得"武装"起来,守住各个入口.怎么"武装"呢? 网络世界就和现实世界一样,总是会有些不怀好意的"人"出现,扫扫 ...
- 云小课 | 守护网络安全不是问题,iptables的四表五链为你开启“八卦阵”
摘要:担心网络基本安全?iptables八卦阵为您守护!本文带您一起了解iptables的相关知识. 网络世界就和现实世界一样,总是会有些不怀好意的"人"出现,扫扫你的端口啊,探测 ...
- 华为云数据库GaussDB(for openGauss):初次见面,认识一下
摘要:本文从总体架构.主打场景.关键技术特性等方面进行介绍GaussDB(for openGauss). 1.背景介绍 3月16日,在华为云主办的GaussDB(for openGauss)系列技术第 ...
- 跟我学ModelArts丨探索ModelArts平台个性化联邦学习API
摘要:ModelArts提供了一个实现个性化联邦学习的API--pytorch_fedamp_emnist_classification,它主要是让拥有相似数据分布的客户进行更多合作的一个横向联邦学习 ...
- 冠军斩获10万奖金!首届“域见杯”医检AI开发者大赛精彩落幕
摘要:首届"域见杯"医检AI开发者大赛精彩落幕. 8月24日,由广州市科学技术局指导,金域医学和华为云共同打造的中国第三方医检行业首个开发者大赛--"域见杯"医 ...
- linux 账号管理 添加用户与修改用户权限与密码
添加用户 useradd zhoulujun 修改用户密码 passwd zhoulujun 修改用户组 usermod -g root zhoulujun 记住这个几个就够了--
- Solon 开发进阶,五、全局异常订阅
Solon 开发进阶 一.插件扩展机制 二.体外扩展机制 三.常用配置说明 四.启动参数说明 五.全局异常订阅 所谓"全局异常",是指通过事件总线发布的异常.目前框架会把未吃掉的异 ...
- VS 进行了无法编译的编辑
Debug的时候碰到这个很烦人得重新运行 工具=>选项=>常规=>调试=>常规 将启用"编辑"并继续,勾取消掉
- SQL SERVER 查询表结构,导出到Excel 生成代码用
查询所有表 select * from information_schema.tables SQL SERVER 查询表结构,导出到Excel 生成代码用 --快速查看表结构字段(比较全面的) SEL ...