ETL工具-nifi干货系列 第十三讲 nifi处理器QueryDatabaseTable查询表数据实战教程
1、处理器QueryDatabaseTable,该组件生成一个 SQL 查询,或者使用用户提供的语句,并执行它以获取所有在指定的最大值列中值大于先前所见最大值的行。查询结果将被转换为 Avro 格式,如下图所示:
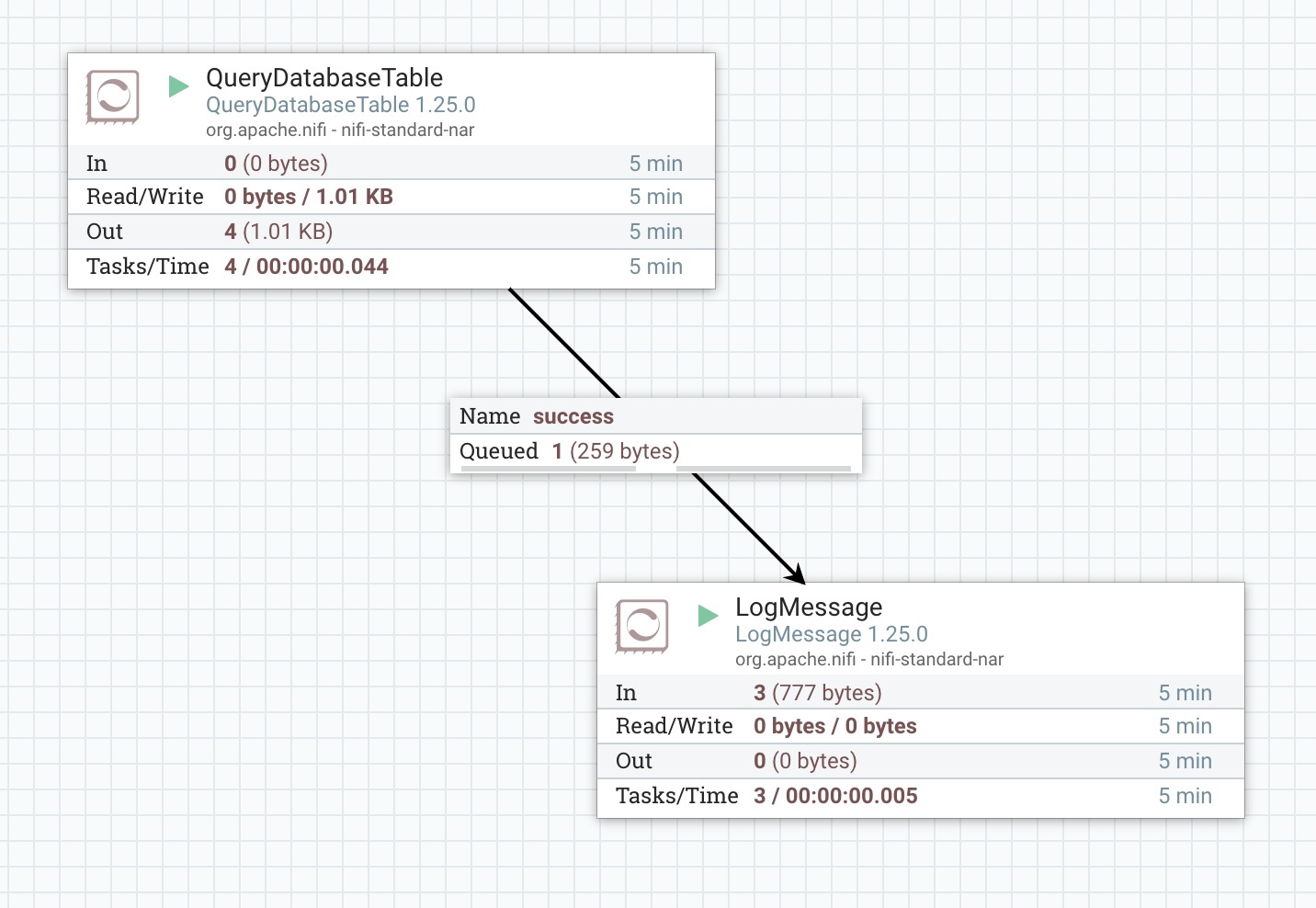
本示例通过QueryDatabaseTable处理器连接数据库查询表数据,然后连接到LogMessage打印日志消息。
2、处理器QueryDatabaseTable属性配置,如下图所示:
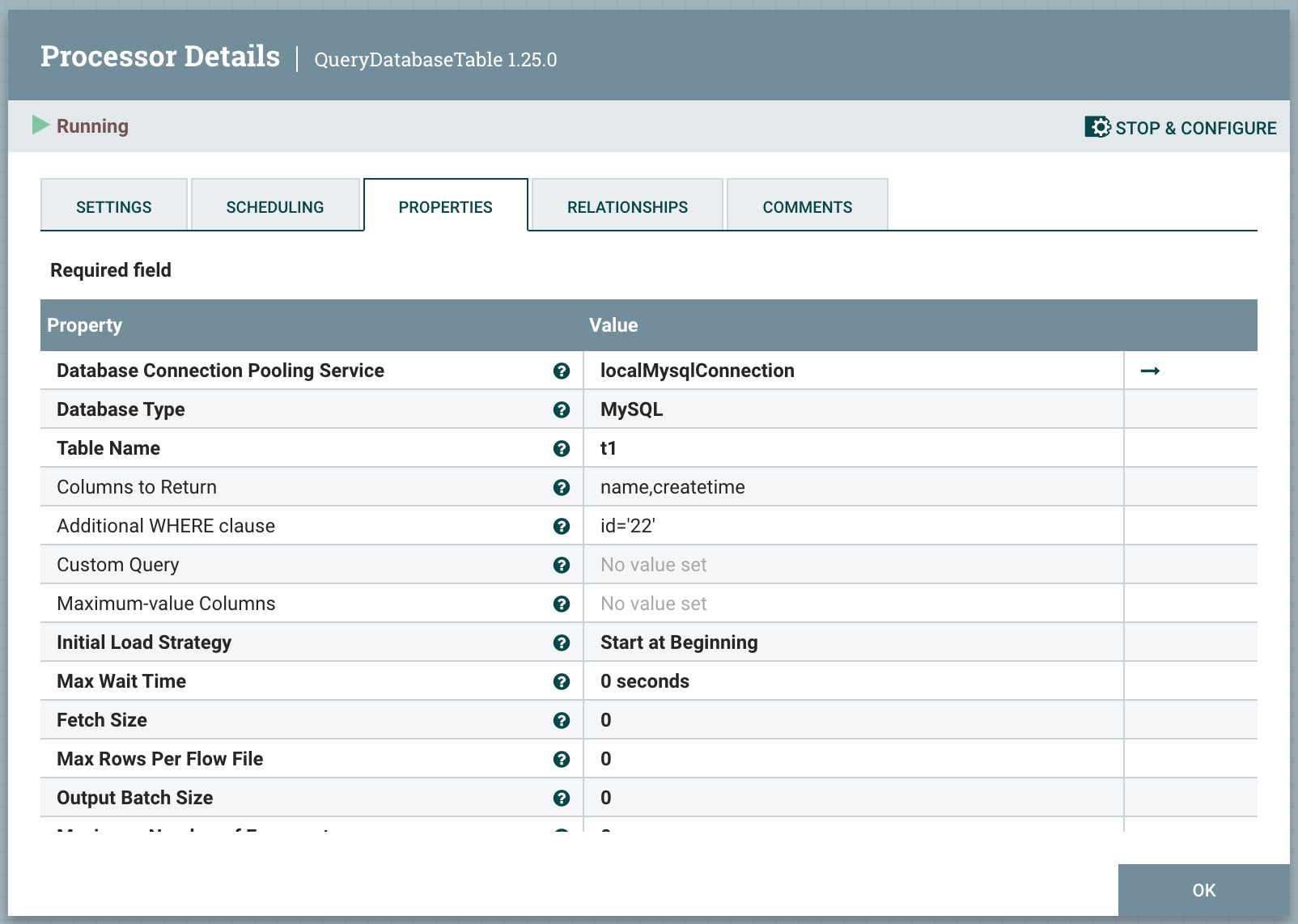
Database Connection Pooling Service:设置数据库连接信息,如设置ip,端口,用户名,密码等。
Database Type:设置数据库类型,有如下选项Generic 、Oracle 、Oracle 12+ 、MS SQL 2012+ 、MS SQL 2008 、MySQL 、PostgreSQL 、Phoenix 。本次演示采用mysql。
Table Name:设置表名,这里设置为t1。
Columns to Return:一个逗号分隔的列名列表,用于在查询中使用。如果您的数据库对这些名称需要特殊处理(例如引号),每个名称都应包括此处理方式。如果未提供列名,则将返回指定表中的所有列。
Additional WHERE clause:构建 SQL 查询时要添加到 WHERE 条件中的自定义子句。
Custom Query:自定义查询语句,如select * from t1 where id='22';
Maximum-value Columns:一个逗号分隔的列名列表。处理器将跟踪自处理器启动以来返回的每个列的最大值。使用多个列意味着对列列表有一个顺序,并且预期每个列的值增长速度比前一个列的值慢。因此,使用多个列意味着列的分层结构,通常用于分区表。此处理器可用于仅检索自上次检索以来已添加/更新的行。请注意,一些 JDBC 类型,如 bit/boolean,并不利于维护最大值,因此不应在此属性中列出这些类型的列,并且在处理过程中会导致错误。如果未提供列,则将考虑来自表的所有行,这可能会影响性能。注意:为了使增量获取正常工作,对于给定表格,使用一致的最大值列名非常重要。
Initial Load Strategy:
Max Wait Time:运行中的 SQL 查询所允许的最长时间,零表示没有限制。小于1秒的最长时间将等同于零。
Fetch Size:每次从结果集中获取的结果行数。这是对数据库驱动程序的提示,可能不会被采纳和/或精确执行。如果指定的值为零,则提示将被忽略。
Max Rows Per Flow File:单个FlowFile中将包含的最大结果行数。这将允许您将非常大的结果集分成多个FlowFiles。如果指定的值为零,则所有行都将在单个FlowFile中返回。
Output Batch Size:在提交处理会话之前排队的输出FlowFiles的数量。当设置为零时,会话将在所有结果集行都已处理并且输出FlowFiles准备好传输到下游关系时提交。对于大型结果集,这可能会导致在处理器执行结束时传输大量的FlowFiles。如果设置了此属性,则当指定数量的FlowFiles准备好传输时,会话将被提交,从而释放FlowFiles到下游关系。注意:当设置此属性时,FlowFiles上将不设置maxvalue.*和fragment.count属性。
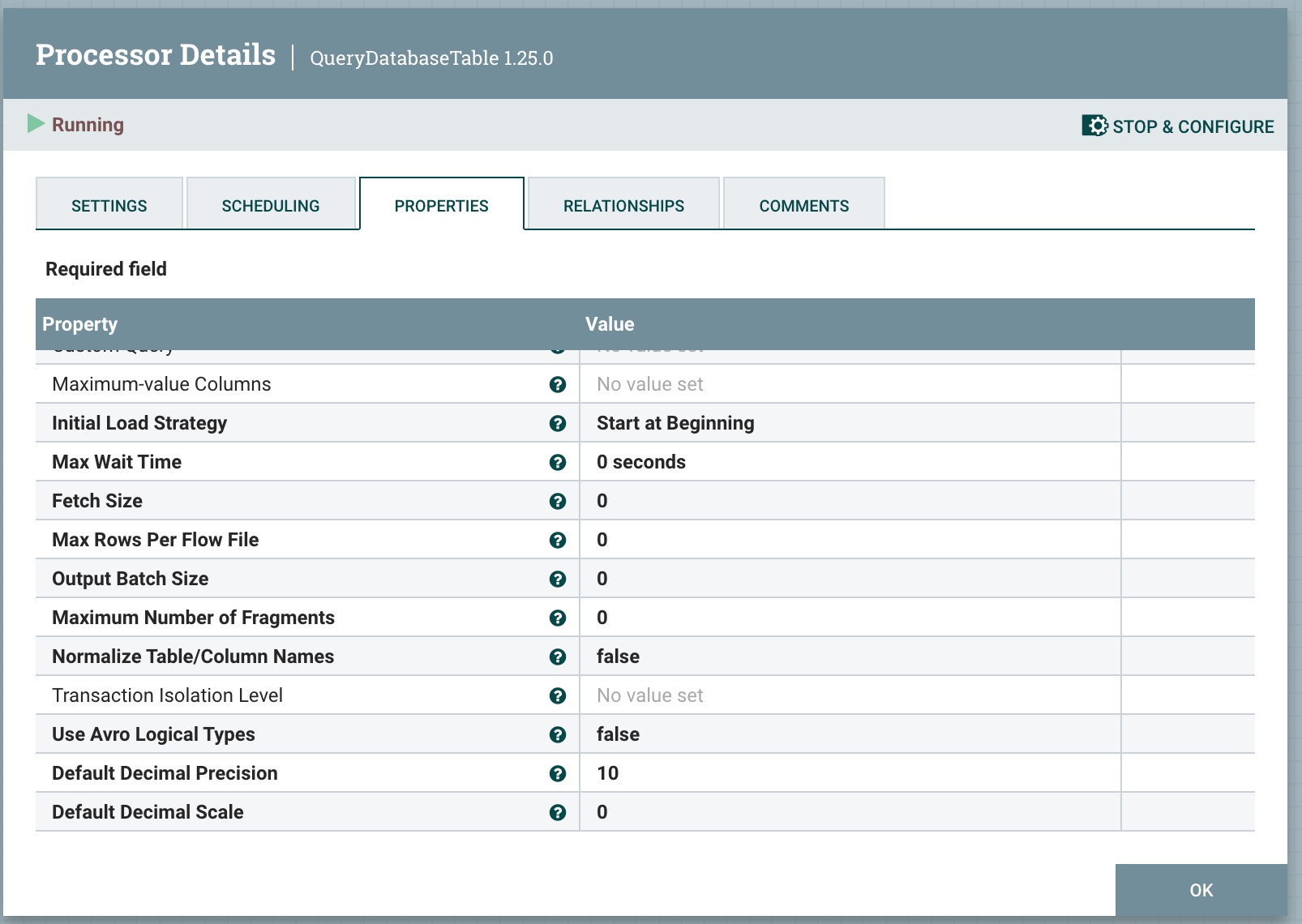
Maximum Number of Fragments:最大碎片数量。如果指定的值为零,则返回所有碎片。当此处理器摄取大型表格时,这可以防止OutOfMemoryError。注意:设置此属性可能会导致数据丢失,因为传入的结果未排序,并且碎片可能在不包含在结果集中的行的任意边界结束。
Normalize Table/Column Names:是否将列名中的非Avro兼容字符更改为Avro兼容字符。例如,冒号和句点将被更改为下划线,以构建有效的Avro记录,有true和false两个选项。
Transaction Isolation Level:此设置将为支持此设置的驱动程序设置数据库连接的事务隔离级别。
Use Avro Logical Types:是否使用 Avro 逻辑类型来处理 DECIMAL/NUMBER、DATE、TIME 和 TIMESTAMP 列。如果禁用,则写入为字符串。如果启用,则使用逻辑类型并按其底层类型写入,具体来说,DECIMAL/NUMBER 作为逻辑 ‘decimal’:按字节写入,并附加精度和比例元数据,DATE 作为逻辑 ‘date-millis’:按整数写入,表示自 Unix 纪元(1970-01-01)以来的天数,TIME 作为逻辑 ‘time-millis’:按整数写入,表示自 Unix 纪元以来的毫秒数,以及 TIMESTAMP 作为逻辑 ‘timestamp-millis’:按长整数写入,表示自 Unix 纪元以来的毫秒数。如果写入的 Avro 记录的读取器也了解这些逻辑类型,那么根据读取器实现的不同上下文,这些值可以以更多的上下文进行反序列化。
Default Decimal Precision:当 DECIMAL/NUMBER 值被写入为 ‘decimal’ Avro 逻辑类型时,需要指定表示可用数字的数量的特定 ‘precision’。通常,精度由列数据类型定义或数据库引擎默认值定义。然而,一些数据库引擎可能会返回未定义的精度(0)。在写入这些未定义精度的数字时,将使用“默认十进制精度”。
Default Decimal Scale:当 DECIMAL/NUMBER 值被写入为 ‘decimal’ Avro 逻辑类型时,需要指定表示可用小数位数的特定 ‘scale’。通常,scale 由列数据类型定义或数据库引擎默认值定义。然而,当返回未定义的精度(0)时,在某些数据库引擎中,scale 也可能不确定。在写入这些未定义数字时,将使用“默认十进制 scale”。如果一个值的小数位数超过指定的 scale,则该值将四舍五入,例如,scale 为 0 时,1.53 变为 2,scale 为 1 时,1.5。
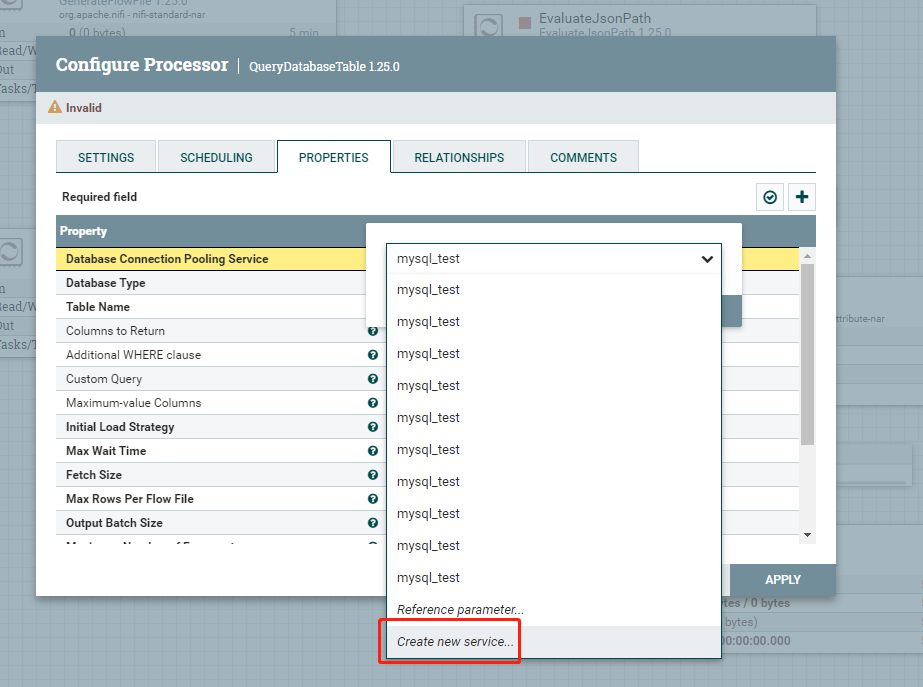
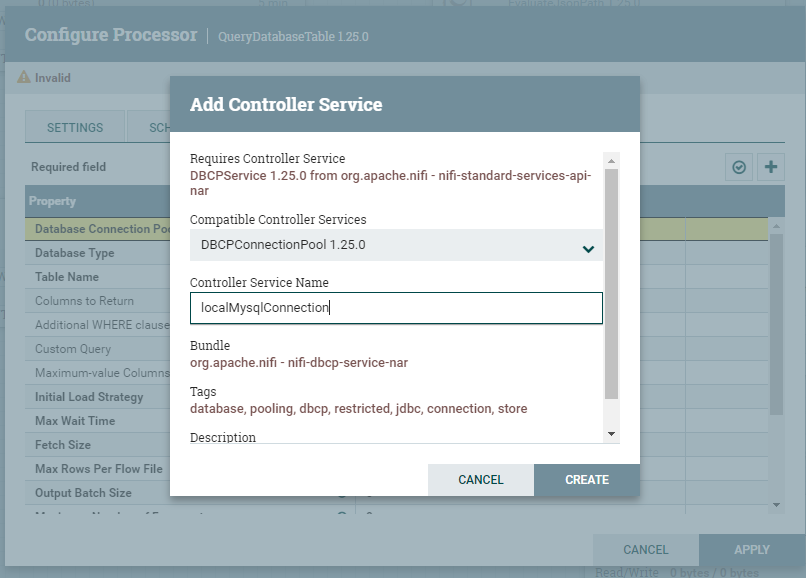
3、控制器服务,配置数据库连接,点击Database Connection Pooling Service 属性对应的值,选择Create new service,如下图所示:
选择合适的Compatible Controller Services,自定义Controller Service Name,如下图所示。
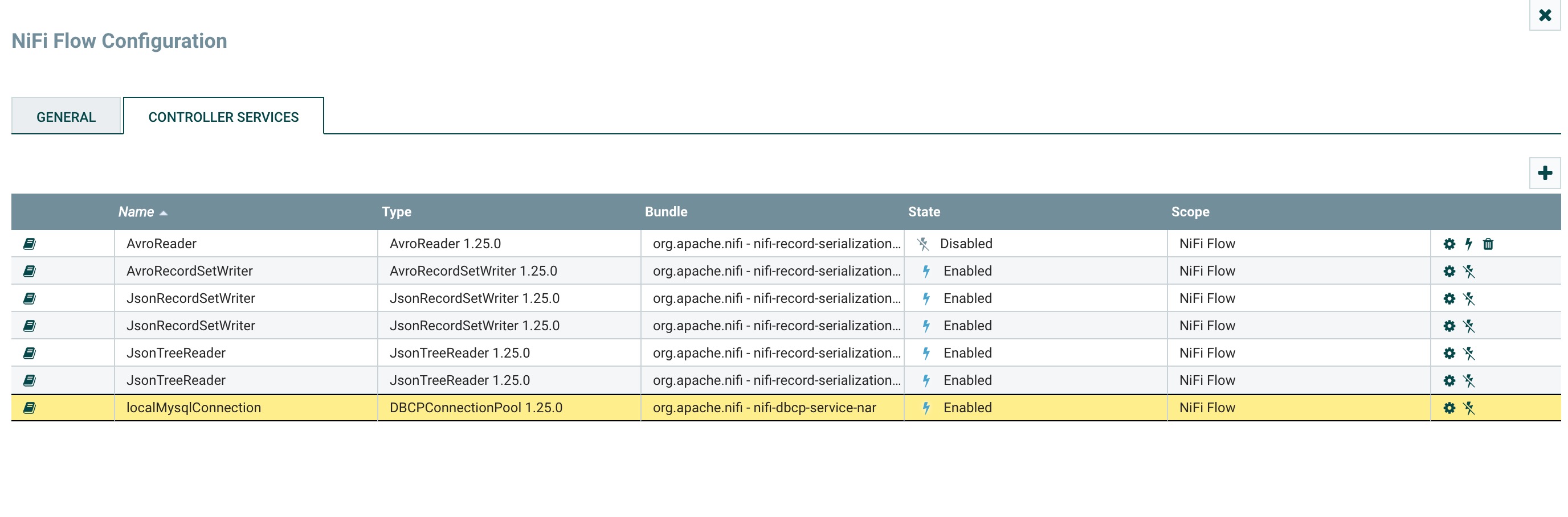
下种中的齿轮可以进行设置数据库连接信息,闪电标记可以启用和禁用。
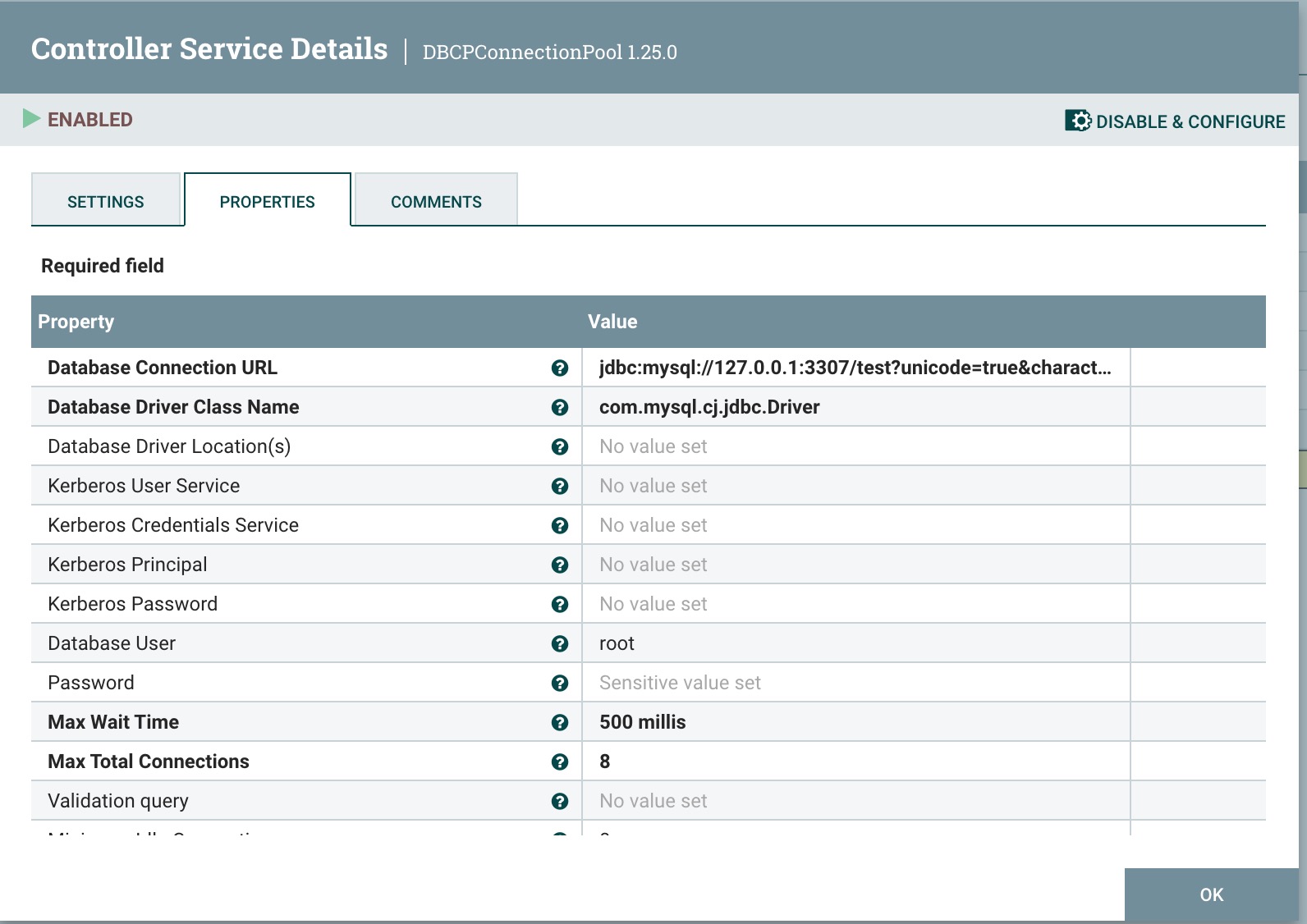
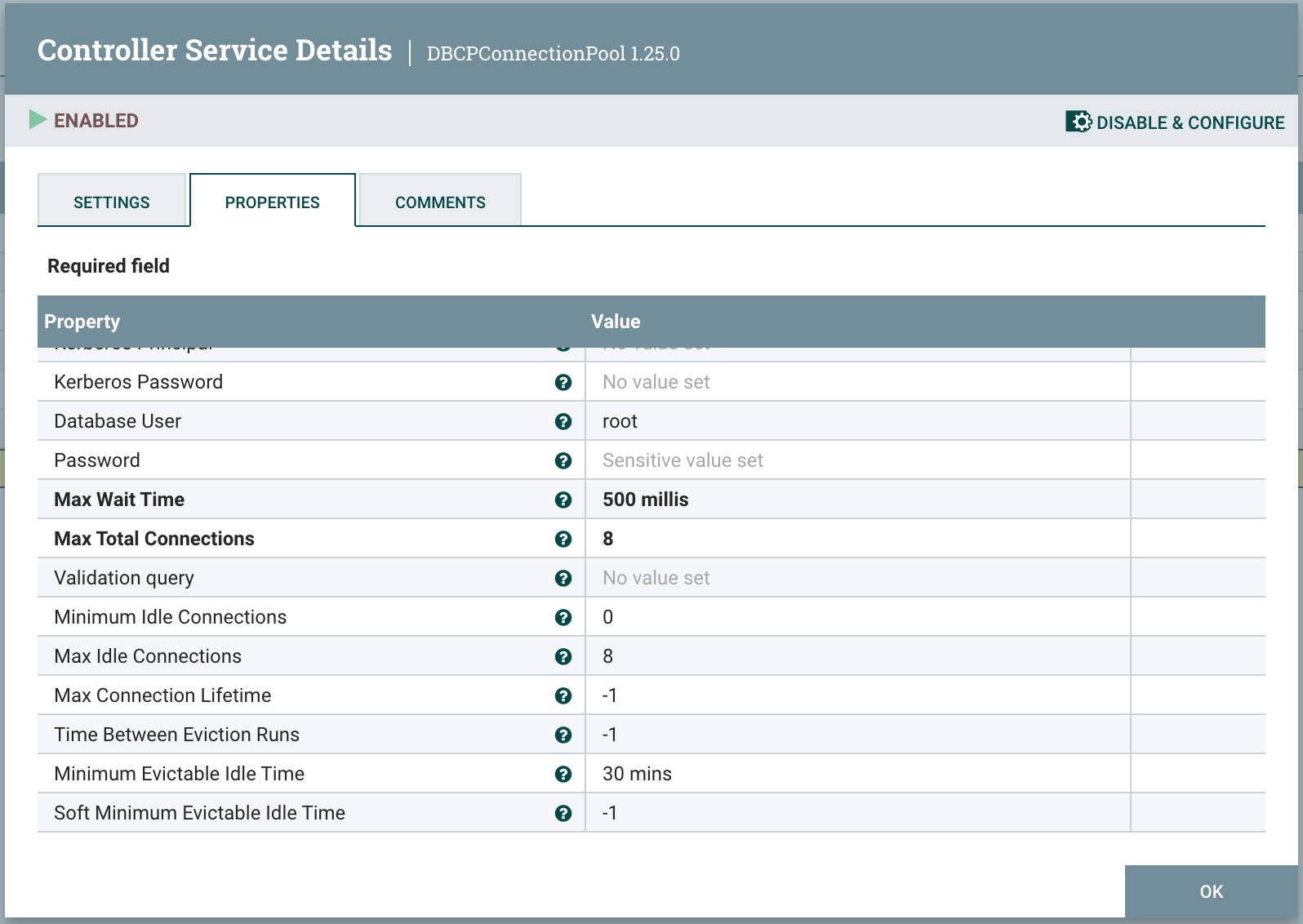
点击齿轮进行配置数据库连接信息,填写主要信息Database Connection Url、Database Driver Class Name,Database user和Password,如下图所示:
4、点击运行,然后查看数据溯源信息,attributes 中多了tablename、querydbtable.row.count、mime.type属性如下图所示:
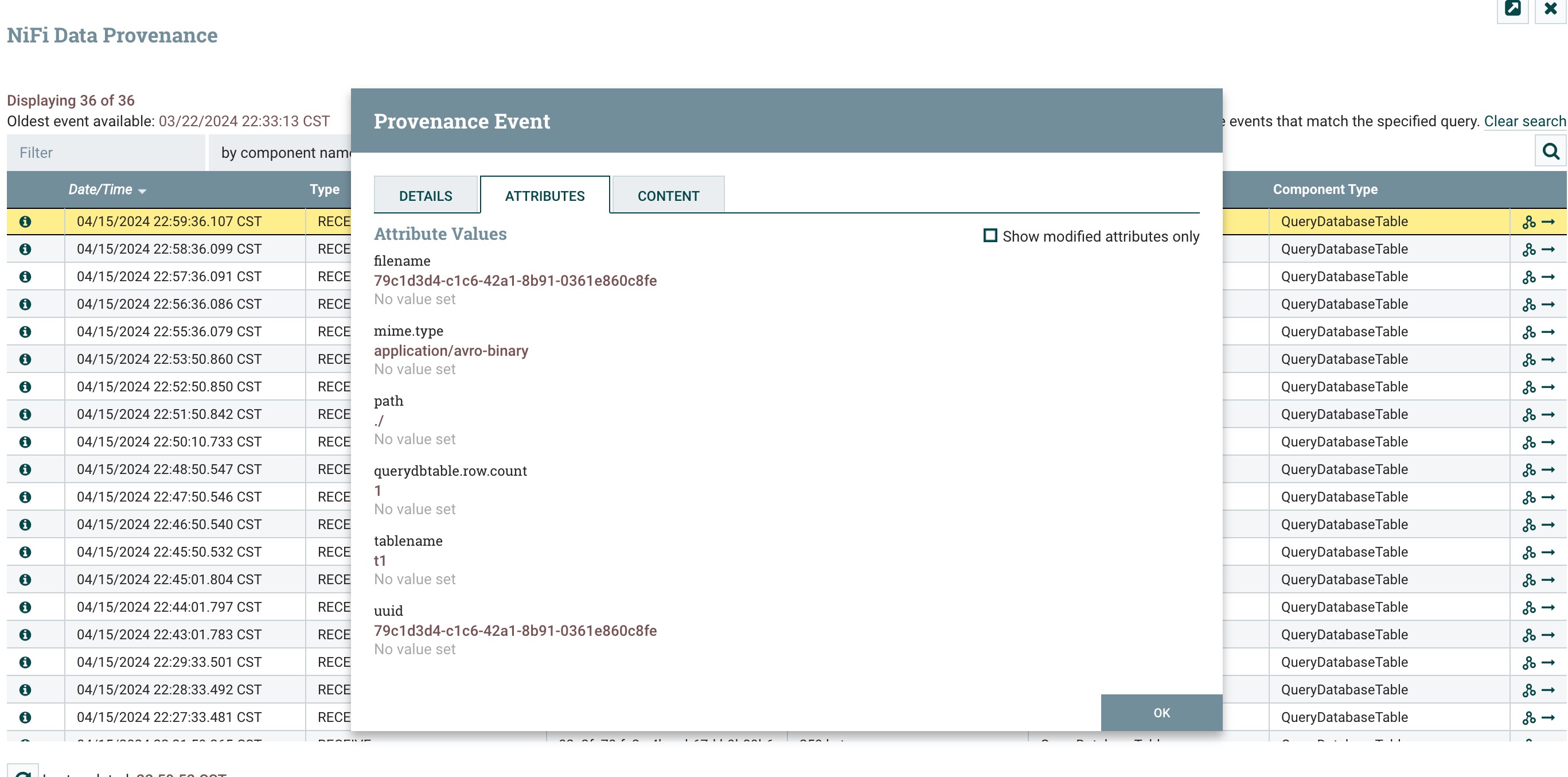
点击content选项卡,可以看到flowfile的content,点击view进行查看数据,如下图所示:
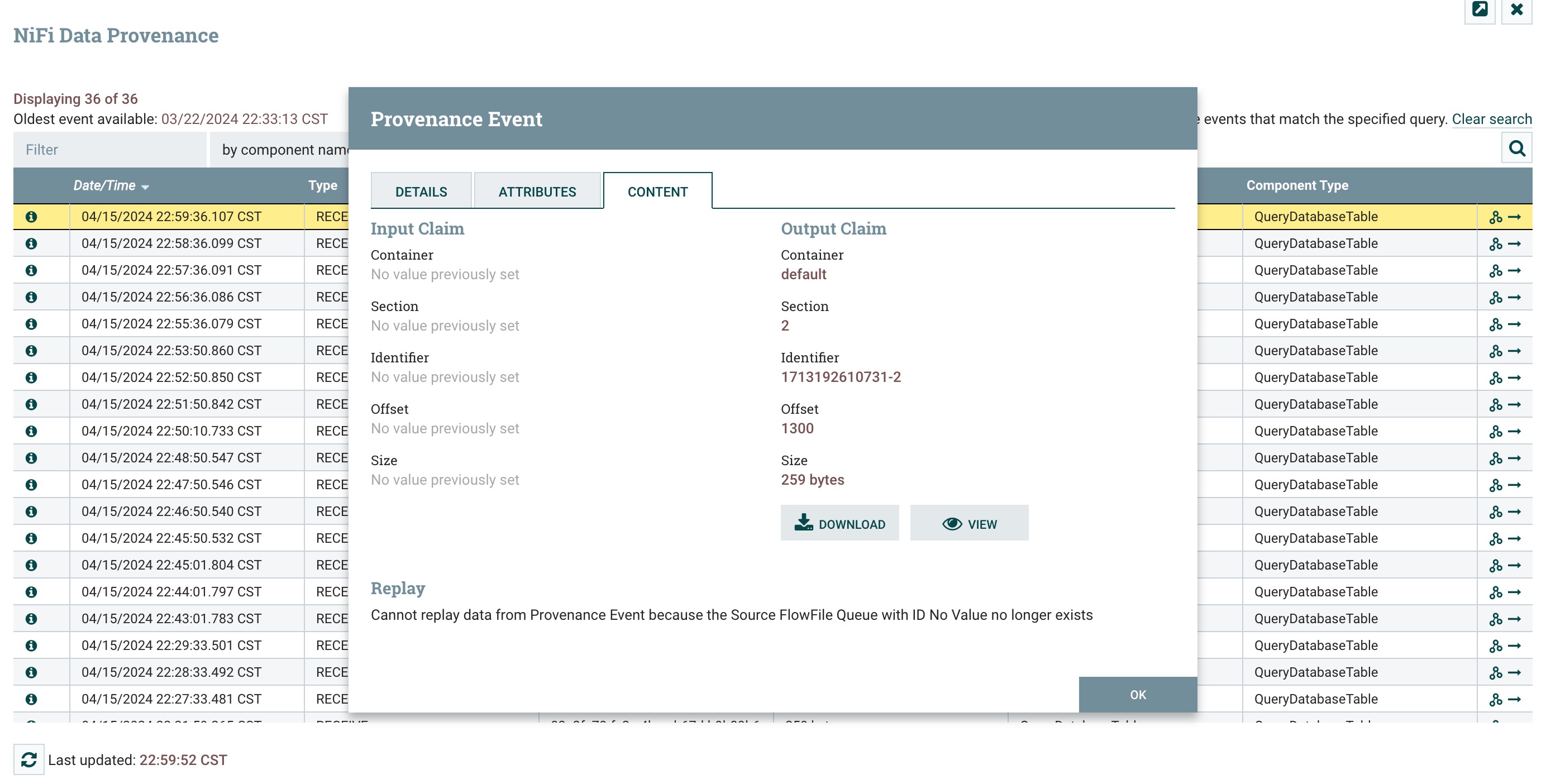
点击view查看数据,默认orginal格式为avro二进制数据所以会有中文乱码的情况,此处乱码不影响,忽略即可,如下图所示:
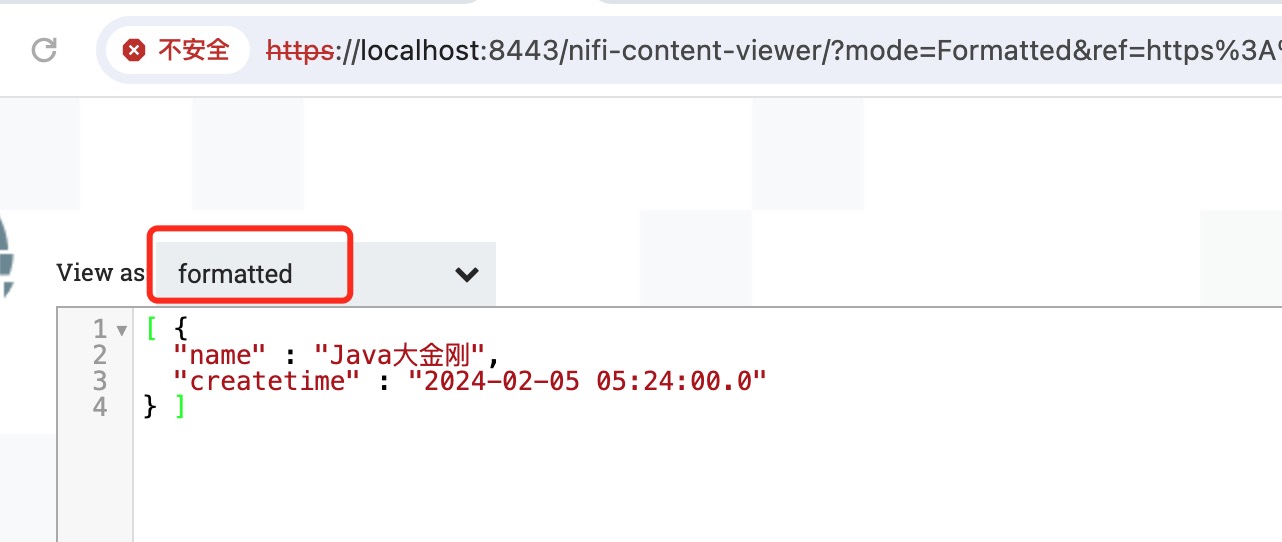
选择formatted,输出json格式的数据,如下图所示:

ETL工具-nifi干货系列 第十三讲 nifi处理器QueryDatabaseTable查询表数据实战教程的更多相关文章
- ETL工具之Kettle的简单使用一(不同数据库之间的数据抽取-转换-加载)
ETL工具之Kettle将一个数据库中的数据提取到另外一个数据库中: 1.打开ETL文件夹,双击Spoon.bat启动Kettle 2.资源库选择,诺无则选择取消 3.选择关闭 4.新建一个转换 5. ...
- Selenium系列(十四) - Web UI 自动化基础实战(1)
如果你还想从头学起Selenium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1680176.html 其次,如果你不懂前端基础知识, ...
- Selenium系列(十五) - Web UI 自动化基础实战(2)
如果你还想从头学起Selenium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1680176.html 其次,如果你不懂前端基础知识, ...
- Selenium系列(十六) - Web UI 自动化基础实战(3)
如果你还想从头学起Selenium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1680176.html 其次,如果你不懂前端基础知识, ...
- Selenium系列(十八) - Web UI 自动化基础实战(5)
如果你还想从头学起Selenium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1680176.html 其次,如果你不懂前端基础知识, ...
- Selenium系列(十九) - Web UI 自动化基础实战(6)
如果你还想从头学起Selenium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1680176.html 其次,如果你不懂前端基础知识, ...
- etl学习系列1——etl工具安装
ETL(Extract-Transform-Load的缩写,即数据抽取.转换.装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可 ...
- 集团公司(嵌入ETL工具)财务报表系统解决方案
集团公司(嵌入ETL工具)财务报表系统解决方案 一.项目背景: 某集团公司是一家拥有100多家子公司的大型集团公司,旗下子公司涉及各行各业,包括:金矿.铜矿.房产.化纤等.由于子公司在业务上的差异,子 ...
- 系统设计与架构笔记:ETL工具开发和设计的建议
最近项目组里想做一个ETL数据抽取工具,这是一个研发项目,但是感觉公司并不是特别重视,不重视不是代表它不重要,而是可能不会对这个项目要求太高,能满足我们公司的小需求就行,想从这个项目里衍生出更多的东西 ...
- Neo4j ETL工具快速上手:简化从关系数据库到图数据库的数据迁移
注:本文系从https://medium.com/neo4j/tap-into-hidden-connections-translating-your-relational-data-to-graph ...
随机推荐
- Helm Chart 多环境、多集群交付实践,透视资源拓扑和差异
简介: 在本文中,我们将介绍如何通过 KubeVela解决多集群环境下 Helm Chart 的部署问题.如果你手里没有多集群也不要紧,我们将介绍一种仅依赖于 Docker 或者 Linux 系统的轻 ...
- SysAK 应用抖动诊断篇—— eBPF又立功了! | 龙蜥技术
简介:且看 SysAK 是如何打造一款性能开销不大.安全可靠.且灵活的关中断检测工具. 文 / 系统运维 SIG 编者按:还记得曾经风靡一时的狄仁杰探案系列之<他抖任他抖,IO诊断在我手& ...
- 重磅 | 数据库自治服务DAS论文入选全球顶会SIGMOD,领航“数据库自动驾驶”新时代
简介: 近日,智能数据库和DAS团队研发的智能调参ResTune系统论文被SIGMOD 2021录用,SIGMOD是数据库三大顶会之首,是三大顶会中唯一一个Double Blind Review的,其 ...
- [Go] flag package 指南: 命令行参数标记的解析
flag 是 Golang 的官方包. 支持用法有三种,不同之处是二三两种用法是 Var() 函数可以绑定 flag 到一个变量上. 直接调用指定类型的函数有多种,如 flag.String(), B ...
- Multisim 教程
Multisim 教程 Multisim主要是用来做电路图绘制.仿真的程序.本教程介绍Multisim的功能和使用方法. Multisim 界面简介 Multisim是电路设计套件里完成电路图绘制和仿 ...
- van-tab吸顶后头部透明色渐变响应
方法一:监听滚动事件 $('.scrollContent').bind('touchmove', function(e){ var winHeight = $(window) ...
- 一分钟部署 Llama3 中文大模型,没别的,就是快
前段时间百度创始人李彦宏信誓旦旦地说开源大模型会越来越落后,闭源模型会持续领先.随后小扎同学就给了他当头一棒,向他展示了什么叫做顶级开源大模型. 美国当地时间4月18日,Meta 在官网上发布了两款开 ...
- Docker部署Scrapy-redis分布式爬虫框架(整合Selenium+Headless Chrome网页渲染)
前言 我的京东价格监控网站需要不间断爬取京东商品页面,爬虫模块我采用了Scrapy+selenium+Headless Chrome的方式进行商品信息的采集. 由于最近爬虫用的服务器到期,需要换到新服 ...
- [WC/CTS2024] 线段树 题解
Link 纪念一下场切题. 题意:给定一棵(分点不一定为中点)的线段树,给定若干个询问区间,问有多少个线段树上结点的集合,知道了这些结点对应的区间和就可以知道任何一个询问区间的和. 从询问区间开始考虑 ...
- IDEA 2020 版配置VUE
找到IDE工具栏,就是启动项目的run那里 点击下拉框,找到Eidt Confiuration,选择 选择小加号 选取npm 设置npm页,完成后,点击apply run npm ,如图选择run或者 ...