LLVM技术在GaussDB等数据库中的应用
本文分享自华为云社区《【GaussTech第3期】LLVM技术在GaussDB等数据库中的应用》,作者:GaussDB 数据库。
Hi,别急!
让技术触达每一个角落,赋能更多的人,GaussTech第3期《LLVM技术在GaussDB等数据库中的应用》,不仅带来满满的技术干货,还推出【分享集赞回帖赢好礼】活动,参与就能赢好礼,文末见惊喜哦!
万物互联的态势下,数据量的激增使得“如何提升数据处理性能”成为各家数据库共同面临的挑战。作为编译优化技术的代表,基于LLVM的CodeGen技术,能为每个查询生成定制的机器码替代原本的通用函数,减少实际查询时冗余的条件逻辑判断、虚函数调用并提高数据局域性,从而达到提升查询整体性能的目的,成为数据库性能优化的一项重要技术。
LLVM能在分析类场景中给用户带来较大的收益,也能在特定的交易性场景中给用户带来一定的收益。接下来详细解读一下LLVM技术在GaussDB等数据库中的应用吧。
LLVM和数据库
LLVM(Low Level Virtual Machine)是一款流行的开源编译器框架,是CodeGen(生成源代码的工具)技术的事实标准,被广泛运用于数据库(如KES, AnalyticDB, GaussDB)、大数据(如Spark)、AI平台(如tensorflow)等领域,用于提升数据处理的性能。
在没有引入LLVM这类CodeGen技术之前,数据库会使用通用的处理逻辑来处理数据。但通用逻辑“笨重”(递归、封装、类型判断转换)的代码实现方式,存在虚函数开销、缓存使用率低下、对指令集不敏感等性能短板。
引入LLVM之后,可以为具体的查询生成定制化的机器码,并尽可能地将数据存储在CPU的寄存器中进一步加快计算的速度:
- LLVM天然支持JIT,该技术可以解决条件逻辑冗余的问题;
- 减少大量的虚函数调用;
- 将数据尽可能地从内存加载到Cache上;
- LLVM做了很多自动矢量化的工作;
比如,下图左侧是通用代码,右侧是CodeGen之后的代码。CodeGen根据实际情况消除了不必要的循环和判断。

▲ 图1 通用性处理逻辑和LLVM代码示意
另外,LLVM技术可以有不同的实现粒度。比如:可使用LLVM加速表达式计算,或再进一步,将多个算子融合编译成定制的机器码,或将自定义函数、存储过程等编译成定制的机器码。

▲ 图2 LLVM的实现粒度
数据库在执行引擎中,运用LLVM技术提升SQL的执行速度。如下图所示:
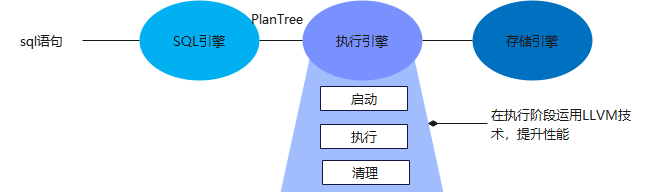
▲ 图3 LLVM技术运用于执行引擎
LLVM适用场景
LLVM对所有类型的SQL都会有收益吗?
因为执行实时编译本身需要耗费一定的时间(简单表达式能做到毫秒级,复杂情况在百毫秒级),对于查询本身耗时较少的场景,加入LLVM反而会导致性能劣化。
因此,目前LLVM在OLAP/HTAP分析型业务场景中收益较大,有着广泛应用,而在OLTP交易型业务场景中,则相对没有那么广泛。
LLVM在OLTP中就一定没有收益吗?
答案同样是否定的。
找对场景,一样有收益。比如根据ISPRAS 2017年发表的实验结果(jit-compiling sql queries in postgresql using llvm)可知:pgbench测试下,OLTP场景中简单的查询加上JIT(Just-in-time及时编译,LLVM天然支持)扩展没有带来性能的提升,甚至将TPS(事务数/秒)从21.8降低到了7.8。
但是在Prepared query(plan cached)的情况下,和简单的查询相比,Plancache + CodeGen将TPS从21.8提升到了43,性能上有了约两倍的提升。

▲ 图4 简单查询、CodeGen流程、Plancache和“Plancache +CodeGen”流程的性能对比
GaussDB中的LLVM
1. LLVM在华为应用于数据库的时间线
华为数据库在LLVM上的研究还是非常超前的。早在2015年,华为就作为PostgreSQL全球开发者大会的赞助商,在会上发表的动态编译(Go Faster with Native Compilation)演讲并引起了很大的反响。
当时社区领袖Josh Burkus在其博客里面,用一节篇幅专门详细介绍了华为动态编译的议题。

▲ 图5 2015年社区领袖Josh Burkus介绍华为的动态编译议题
在2017年,华为在面向OLAP场景的数据库内核中突破了LLVM动态编译技术,并在运营商、金融证券等多个行业的POC项目中帮助客户提升数据处理性能,同时,在软件开发过程中充分模块化、通用化接口设计,将LLVM同年落地到面向OLTP的数据库设计中。
目前,GaussDB数据库对于LLVM也在不断地演进开发。
2. GaussDB LLVM实现简析
GaussDB针对向量化引擎(主要用于分析场景)、行存(主要用于交易场景)都实现了CodeGen。如下图所示,从代码模块层次来看:
1) GaussDB通过API接口层封装处理了LLVM环境、资源、基本元素等。
2) GaussDB在CodeGen层调用API接口进行了不同粒度的实现。
3) GaussDB在执行引擎侧根据情况使用CodeGen技术进行性能优化。

▲ 图6 GaussDB LLVM 模块层次图
GaussDB启动后会进行LLVM的初始化工作,检查CPU对CodeGen的支持情况,并进行环境初始化。
在执行启动阶段,以表达式为例,程序会判断当前表达式是否可JIT,是的话,则会进行IR函数的生成和生成定制机器码,及原本表达式执行函数的入口替代工作。
在实际执行过程中,运行处理函数(该函数已经在上一阶段进行了入口替代)进行实际执行工作。
在执行结束后的清理阶段,释放LLVM相关资源。

▲ 图7 GaussDB CodeGen编译执行流程简图
GaussDB使用了阈值codegen_cost_threshold来估算当前查询使用LLVM技术是否能带来收益。如果处理数据的规模大于该阈值后,才会继续使用LLVM技术进行相关处理。该阈值代表行数,也可以理解成处理数据的规模,默认值为100000行,可以调节。
在OLAP场景中,GaussDB在判断是否能够对于一个算子进行CodeGen后(如:数据类型,算子类型判断等),开始生成对应的IR bytecode片段,之后MCJIT模块会调用生成的LLVM Module单元进行执行。
在OLTP场景中,GaussDB则会在Plan Cache场景下结合CodeGen框架,通过缓存机器码的方式,节省下编译生成中间语言IR Func以及优化成机器码的时间,整个过程是异步的。因此,在大量重复查询的场景下,后续的查询也会因为LLVM技术而受益。
另外,为了避免行数估计错误而选择CodeGen导致性能劣化,GaussDB还研发了当前业界独有的异步编译功能,即在查询语句确定要使用CodeGen的时候,将编译工作转交给后台线程,工作线程在JIT函数编译完成前继续使用原始执行逻辑执行,编译完成后,再替换成JIT函数执行。
3. GaussDB LLVM支持加速的场景
支持LLVM的表达式:

行存表达式计算支持的数据类型不受限制。
在向量化执行引擎中,仅当表达式出现在Scan节点的filter、Hash Join节点中的complicate hash condition, hash join filter, hash join target, Nested Loop节点中的filter, join filter, Merge Join节点的merge join filter, merge join target, Group节点中的filter表达式时,才会考虑是否使用LLVM动态编译优化。
在行执行引擎中,除一次性的表达式计算外,会考虑为所有算子的filter和Targetlist表达式都使用LLVM动态编译优化。
支持LLVM的算子:
其中,HashJoin算子仅支持Hash Inner Join,对应的hash cond仅支持int4, bigint, bpchar类型的比较;HashAgg算子仅支持针对bigint, numeric类型的sum及avg操作,且group by语句仅支持int4, bigint, bpchar, text, varchar, timestamp类型操作,同时支持count(*)聚集操作。Sort算子仅支持对int4, bigint, numeric, bpchar, text, varchar数据类型的比较操作。除此之外,无法使用LLVM动态编译优化,具体可通过explain performance工具进行显示。
4. GaussDB LLVM使用建议
GUC参数:
enable_codegen:控制LLVM特性的打开和关闭。目前数据库内核侧默认打开。
codegen_cost_threshold:使用处理行数控制是否开启codegen,默认为10000。10000是通过实验验证得出的优化值,不建议将此值设置的过低。
另外,在开启LLVM特性的前提下,建议在允许的条件下尽可能设置较大的work_mem,如果出现大量下盘,则建议关闭LLVM动态编译优化。用户可通过analysis_options为on(LLVM_COMPILE),执行对应查询语句,在User Define Profiling中就可以看到LLVM的编译时间。结合此数据,可对codegen_cost_threshold进一步调整以获取更好的查询性能。
5. GaussDB LLVM性能表现
GaussDB实验室分别就codegen打开和关闭进行了TPCH性能测试。

▲ 表1 测试环境
测试结果显示,打开codegen时,带有qual的SQL,查询性能都有明显提升,且提升比例与qual在整个SQL中的占比相关,像Q6、Q12、Q19等qual占比较高的查询,性能提升也较多。

▲ 表2 TPCH 部分Query的测试结果
TPCC的性能提升并没有TPCH那么多,但据实验室数据,打开codegen后,tpmC提升了约7%。
PostgreSQL中的LLVM
1. LLVM在PostgreSQL应用的时间线
LLVM在PostgreSQL社区中的技术讨论开始的比较早:
2015年,上文提到的华为在PostgreSQL开发者大会上做的演讲;
2016年,PostgreSQL社区开始对JIT的实现进行了讨论;
2018年,PostgreSQL11中,第一次正式采用LLVM加速表达式计算。
2. PostgreSQL LLVM实现简析
如下图所示,和GaussDB相同,PostgreSQL执行引擎使用CodeGen技术做性能优化。针对表达式求值和元组分解为所需的属性集合两大性能瓶颈,做了可选的编译执行加速。

▲ 图 8 PgSQL LLVM 模块层次图
PostgreSQL使用了三个参数来判断是否使用CodeGen优化:
- jit_above_cost,表示超过多少cost 的查询才会使用JIT 功能。默认为100000,如果设置为-1 则关闭JIT。
- jit_inline_above_cost,表示超过多少cost 的查询使用JIT 的inline 功能。默认为500000,-1则关闭inline 功能。
- jit_optimize_above_cost,表示超过多少cost 的查询使用JIT 的optimization 功能。默认为500000,-1则关闭优化功能。
其中,后两个参数都需要设置得比jit_above_cost大,否则没有意义。这和GaussDB的使用数据集大小来控制是否开启CodeGen思想类似。
另外,PostgreSQL对于LLVM生成的字节码目前无法在plan cache中复用。这个功能的实现在PostgreSQL的中长期计划中。
3. PostgreSQL LLVM支持加速的场景
当前,PostgreSQL的JIT实现支持对表达式计算以及元组拆解的加速。
表达式计算被用来计算WHERE子句、target lists, aggregate聚合和projections投影。通过为每一种情况生成专门的代码来实现加速。
元组拆解是把一个磁盘上的元组转换成其在内存中表示的过程。通过创建一个专门针对该表布局和要被抽取的列数的函数来实现加速。
总结
华为和PostgreSQL关于LLVM特性的研究都起步很早,华为作为LLVM技术应用于数据库先驱者引领了PostgreSQL的技术发展。对于LLVM应用于数据库,GaussDB和PostgreSQL各有实现方法。GaussDB作为企业级数据库,对比PostgreSQL数据库,其实现特性多于PostgreSQL。

“【分享集赞回帖赢好礼】LLVM技术在GaussDB等数据库中的应用”活动来啦!参与就有机会赢取华为背包、华为云定制短袖、蓝牙音箱、书籍等好礼!
活动时间:2024/5/28-6/10
如何参与?
长按识别二维码,即可参与!

LLVM技术在GaussDB等数据库中的应用的更多相关文章
- ajax技术实现登录判断用户名是否重复以及利用xml实现二级下拉框联动,还有从数据库中获得
今天学了ajax技术,特地在此写下来作为复习. 一.什么是ajax? 客户端(特指PC浏览器)与服务器,可以在[不必刷新整个浏览器]的情况下,与服务器进行异步通讯的技术 即,AJAX是一个[局部刷新 ...
- Android+PHP+MYSQL把数据库中的数据显示在Android界面上
俗话说,好记性不如烂笔头.今天终于体会其中的道理了.昨天写好的代码不知道为何找不到了.所以今天我一定得抽出一点时间把我的代码保存起来,以防我的代码再没有了. 还是先上图片. 这个界面是用ListVie ...
- MySQL存储引擎的实际应用以及对MySQL数据库中各主要存储引擎的独特特点的描述
MySQL存储引擎的实际应用以及对MySQL数据库中各主要存储引擎的独特特点的描述: 1.MySQL有多种存储引擎: MyISAM.InnoDB.MERGE.MEMORY(HEAP).BDB(Berk ...
- Java删除数据库中的数据
1:删除数据库中数据表中的数据同样也是一个非常用的技术,使用executeUpdate()方法执行用来做删除SQL的语句可以删除数据库表中的数据 2:本案例使用Statement接口中的execute ...
- Eclipse中java向数据库中添加数据,更新数据,删除数据
前面详细写过如何连接数据库的具体操作,下面介绍向数据库中添加数据. 注意事项:如果参考下面代码,需要 改包名,数据库名,数据库账号,密码,和数据表(数据表里面的信息) package com.ning ...
- Oracle数据库中调用Java类开发存储过程、函数的方法
Oracle数据库中调用Java类开发存储过程.函数的方法 时间:2014年12月24日 浏览:5538次 oracle数据库的开发非常灵活,不仅支持最基本的SQL,而且还提供了独有的PL/SQL, ...
- 数据库中MyISAM与InnoDB区别
数据库中MyISAM与InnoDB区别 首页 » DIY技术区 » 数据库中MyISAM与InnoDB区别 09:57:40 MyISAM:这个是默认类型,它是基于传统的ISAM类型,ISAM是I ...
- SQL Server数据库中还原孤立用户的方法集合
虽然SQL Server现在搬迁的技术越来越多,自带的方法也越来越高级. 但是我们的SQL Server在搬迁的会出现很多孤立用户,微软没有自动的处理. 因为我们的数据库权限表都不会在应用数据库中,但 ...
- MVC设计模式((javaWEB)在数据库连接池下,实现对数据库中的数据增删改查操作)
设计功能的实现: ----没有业务层,直接由Servlet调用DAO,所以也没有事务操作,所以从DAO中直接获取connection对象 ----采用MVC设计模式 ----采用到的技术 .MVC设计 ...
- Sliverlight linq中的数组筛选数据库中的数据
首先 什么是linq呢 ? LINQ即Language Integrated Query(语言集成查询),LINQ是集成到C#和Visual Basic.NET这些语言中用于提供查询数据能力的一个新特 ...
随机推荐
- python实现:有一个列表为num_list,找到一个具有最大和的连续子列表,返回其最大和。
# 有一个列表为num_list,找到一个具有最大和的连续子列表,返回其最大和.# 示例:# 输入: [-3,1,-1,6,-1,2,4,-5,4]# 输出: 11# 解释: 连续子数组 [6,-1, ...
- 力扣500(java&python)-键盘行(简单)
题目: 给你一个字符串数组 words ,只返回可以使用在 美式键盘 同一行的字母打印出来的单词.键盘如下图所示. 美式键盘 中: 第一行由字符 "qwertyuiop" 组成.第 ...
- CF1481D AB Graph 题解
CF1481D AB Graph 题解 [思路] 首先有几个显而易见的东西. 如果存在两个点,他们之间的两条边字母相同,那么一定有解(在两个点之间跳.) 否则,这张图的邻接矩阵一定长成这样: * a ...
- CDN应用进阶 | 正确使用CDN 让你更好规避安全风险
为了帮助用户更好地了解和使用CDN产品,CDN应用实践进阶系统课程开课了.12月17日,阿里云CDN产品专家彭飞在线分享了<正确使用CDN,让你更好规避安全风险>议题,内容主要包括以下几个 ...
- 融合趋势下基于 Flink Kylin Hudi 湖仓一体的大数据生态体系
简介: 本文由 T3 出行大数据平台负责人杨华和资深大数据平台开发工程师王祥虎介绍 Flink.Kylin 和 Hudi 湖仓一体的大数据生态体系以及在 T3 的相关应用场景. 本文由 T3 出行大数 ...
- KubeVela 上手(1)|让云端应用交付更加丝滑
简介: KubeVela 是阿里云和微软共同发起的 OAM(Open Application Model)标准的技术实现,旨在打造统一.标准.跨环境的云端应用交付,省时省力,轻松简单 作者|KubeV ...
- 一文详解Redis中BigKey、HotKey的发现与处理
简介: 在Redis的使用过程中,我们经常会遇到BigKey(下文将其称为"大key")及HotKey(下文将其称为"热key").大Key与热Key如果未能及 ...
- LlamaIndex 探索视频系列
如果您喜欢通过视频学习,现在正是查看我们的"探索 LlamaIndex"系列的好时机.否则,我们建议您继续阅读"理解 LlamaIndex"教程. 自下而上开发 ...
- 微信小程序支付实现流程
基本流程 用户操作流程 小程序流程 整体支付流程 代码实现 创建订单 创建订单,主要是前端将订单的信息提交到后端.但是在创建订单之前还有一些准备工作要做: 获取用户数据GetUserInfo 获取用户 ...
- Fastbin attack&&Double free和Unsortbin leak的综合使用
Fastbin attack&&Double free和Unsortbin leak的综合使用 今天做一个综合题目,包括利用Fastbin attack实现多指针指向一个地址,以及利用 ...