python 国家标准行业编码标准格式化处理
代码在上次的基础上做了一点优化,之前对项目要的最终结果理解有些偏差:
原始数据的那一列行业编码是存在三位数和四位数的,我上次理解的三位数就是分割成两位数进行查找,其实三位数的编码是由于第一位的0没有显示,
所以例如311的编码其实应该是0311,所以代码进行了修改,对于三位数需要在开头的位置补一个0,成为四位数再进行查找。
把三个方法的参数做了优化,获取json字符串的方法只需要一个参数(国标文件),获取单个结果的方法需要两个参数(待查字符串,国标文件),
获取整个文件需要三个参数(原始数据文件,新建文件,国标文件)这个方法原始数据文件每一行的编码的遍历+使用国标文件调用获取json的方法一个个获得结果。
最终结果图:
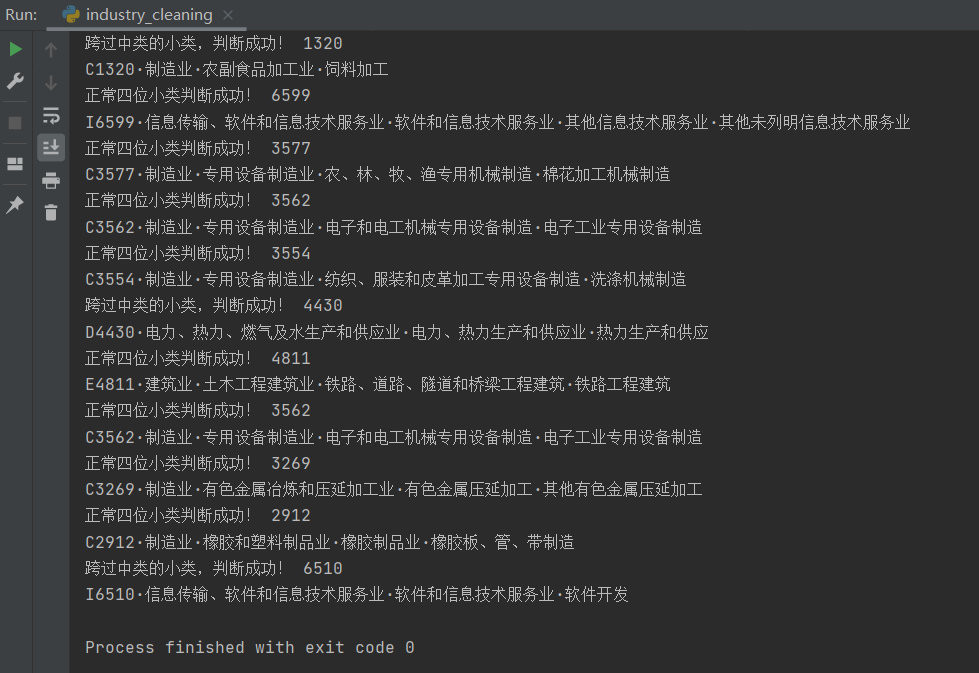
源代码:
1 import pandas as pd
2 import xlwt
3
4 """
5 rank的一系列变量是生成json字符串需要的标志
6 由于json结构是循环遍历生成的,所以在每一层都要留下标记,以便于下一层的构建
7 """
8
9 rank10="" #A 门类编号
10 rank11="" #A 门类名字
11 rank20="" #01 大类编号
12 rank21="" # 大类名字
13 rank30="" #012 中类编号
14 rank31="" # 中类名字
15 rank40="" #0121小类编号
16 rank41="" # 小类名字
17
18 """
19 ------------------------------------------------------------------------------------------------------------------------
20 """
21
22 def get_json(stdfilepwd):
23 """
24 :param stdfilepwd:标准国标文件
25 :return: 标准行业维度json
26 """
27 """
28 filepwd 国标文件格式
29 A 农、林、牧、渔业
30 A 农、林、牧、渔业
31 01 农业
32 011 谷物种植
33 0111 稻谷种植
34 0112 小麦种植
35 0113 玉米种植
36 """
37 # dict={"A":{"01":{"011":"谷物种植","0111":"稻谷种植"} ,
38 # "02":{"021":"林木育种和育苗","0211":"林木育种"}},
39 #
40 # "B":{"06":{ "0610":"烟煤和无烟煤开采洗选","0620":"褐煤开采洗选"},
41 # "07":{"0710":"石油开采","0720":"天然气开采"}}
42 # }
43 # layer1=dict['A']
44 # print("第一层 A:\n",layer1)
45 #
46 # layer2 = dict['A']['01']
47 # print("第二层 01农业:\n", layer2)
48 #
49 # layer3 = dict['A']['01']["011"]
50 # print("第三层 :\n", layer3)
51 #读取标准文件 df默认不读取第一行数据
52 df = pd.read_excel(stdfilepwd)
53 #首先寻找第一层大写字母层的数据 定位行loc[] 定位
54 # print(df.columns.values[0]) #A
55
56 my_dict={"A":{}} #最终生成的字典
57 new_dict={"A":
58 {"农、林、牧、渔业":
59 {"01":
60 {"农业":
61 {"001":
62 {"谷物种植":
63 {
64 "0111":"稻谷种植","0112":"小麦种植"
65 }
66 }
67 }
68 }
69 }
70 }
71 }
72 # new_dict["A"].update(
73 # {df.loc[0].values[0]:df.loc[0].values[1]}
74 # )
75 # print("excel表的行数:\n",len(df.index.values))
76 # print("测试字典:\n",new_dict)
77 # print(df.loc[80].values)
78 # print("一个单元格数据的数据类型:\n",type(df.loc[0].values[0]))
79
80 #测试完毕 开始构建行业领域分类字典
81 #开始遍历表格 0 - 1423
82 for i in range(len(df.index.values)):
83 #由于表格的第一列数据的数字被判定为int型 所以要转化成str
84 temp=df.loc[i].values
85 #转化字符串 为了保险起见 两列统一化处理 均转化为字符串
86 # one 就是编码 two就是编码对应的行业名称
87 one = str(temp[0])
88 # print(len(one))
89 two = str(temp[1])
90 # print("数据格式:\n",type(temp[0]))
91 #通过判断values[0](数字编码)的字符串的长度判断处于字典的哪一层 如果长度是1 那么在第一层门类 如果长度是2那么在第二层大类 如果长度是3那么在第三层中类
92 if(len(one)==1):
93 #rank10保存编码 rank11保存行业名称 后面类似
94 global rank10
95 global rank11
96 rank10=one
97 rank11=two
98 my_dict.update({rank10:{rank11:{}}})
99 if(len(one)==2):
100 global rank20
101 global rank21
102 rank20 = one
103 rank21 = two
104 my_dict[rank10][rank11].update({rank20:{rank21:{}}})
105 if (len(one) == 3):
106 global rank30
107 global rank31
108 rank30 = one
109 rank31 = two
110 #虽然会出现21 , 2111 中间没有210的情况出现 但是可以优先生成所有的中类三位数的json结构 这一层会保留最后一个三位数中类 可以在后面进行判断
111 my_dict[rank10][rank11][rank20][rank21].update({rank30:{rank31:{}}})
112 #这里做了代码的前三位字符串切分,为了判断一下有没有小类跳过中类的情况,需要直接跨过中类存储,少了一层字典{}
113 if (len(one) == 4):
114 global rank40
115 global rank41
116 rank40 = one
117 rank41 = two
118 #把编码分片 只取前三位 然后和距离这个编码最近的那个三位数中类做比较 如果相同则可以放到该中类的下一层字典 如果不同则该四位编码自成一个字典
119 divide_rank40=rank40[:3]
120 # print(divide_rank40,rank30)
121 #判等
122 if(divide_rank40==rank30):
123 # print("!!!!!~~~~~~~~~~~~")
124 #相等 -> 放入该中类的下一层字典
125 my_dict[rank10][rank11][rank20][rank21][rank30][rank31].update({rank40:rank41})
126 else:
127 #不等 -> 自己成为一个字典 在大类里直接自成一个字典
128 my_dict[rank10][rank11][rank20][rank21].update({rank40: rank41})
129 #得到最终的字典my_dict
130 # print(my_dict.keys())
131 # print(my_dict)
132 return my_dict
133 """
134 最终生成的json文件
135
136 'A': {
137 '农、林、牧、渔业': {
138 '01': {
139 '农业': {
140 '011': {
141 '谷物种植': {
142 '0111': '稻谷种植',
143 '0112': '小麦种植',
144 '0113': '玉米种植',
145 '0119': '其他谷物种植'
146 }
147 },
148 '012': {
149 '豆类、油料和薯类种植': {
150 '0121': '豆类种植',
151 '0122': '油料种植',
152 '0123': '薯类种植'
153 }
154 },
155 '013': {
156 '棉、麻、糖、烟草种植': {
157 '0131': '棉花种植',
158 '0132': '麻类种植',
159 '0133': '糖料种植',
160 '0134': '烟草种植'
161 }
162 },
163 '014': {
164
165 """
166
167
168 """
169 ------------------------------------------------------------------------------------------------------------------------
170 """
171
172 def ger_stdstr(qb03,stdfilepwd):
173 """
174 :param qb03,stdfilepwd:
175 :return: str 标准行业维度字符串 行业代码·门类名称·大类名称·中类名称·小类名称
176 qb03,待查编码
177 stdfilepwd,标准国标文件
178 """
179 #设置个标记,初始值False 说明默认找不到这个编码 如果找到了则设为True 如果最终是False则重新分割字符串,回调函数
180 flag = False
181 #获取字典
182 my_dict={}
183 my_dict.update(get_json(stdfilepwd))
184 # print(my_dict)
185
186 category="" #门类 名字
187
188 big_class="" #大类 名字
189
190 medium_class="" #中类 名字
191
192 small_class="" #小类 名字
193 # for 遍历第一层 门类
194 for items in my_dict.items():
195 res = "" # 定义该方法最终要返回的标准化行业维度字符串
196 # print(items[0]) #ABCD
197 for layer_0 in items[1].items(): #这个for循环已经进入了 第一层 {} 里面格式是 (门类名称:{ })
198 # print("门类:\n",layer_0)
199 # print("门类名称:\n",layer_0[0])
200 category=layer_0[0] #门类名称[0]
201 """
202 -------------------------------------------------------------------
203 """
204 # 遍历第二层大类
205 """
206 每进入一层遍历,第一个for循环是进入一个这样格式的数据 ( 编码:{ } ) [0]是名称 [1]是字典
207 之后第二个for循环进入那个字典{ }
208 字典构建的方式是 上一层是key 下一层是对应的value 同时它作为下一层的key
209 """
210 for layer_10 in layer_0[1].items():
211 # print("大类编码(两位):\n",layer_10[0])
212 #进入A对应的{ }
213 for layer_11 in layer_10[1].items(): #这个for循环已经进入了 第二层 {} 里面格式是 (大类名称:{ })
214 # print("大类:\n",layer_11)
215 big_class = layer_11[0]
216 # print("大类名称:\n",big_class)
217 """
218 ---------------------------------------
219 """
220 #进入大类(01,{ })
221 for layer_20 in layer_11[1].items():#这个for循环已经进入了 第三层 {} 里面格式是 (中类名称:{ })或者不正常的跨过中类的四位编码
222 # 这个分支的意思是有的类别只到了大类,没有经过中类直接分到了四位数的小类,所以必须分开遍历
223 #判断第二层下一级的编码是三位还是四位,如果是三位那么是正常的中类划分,如果是四位,那么是跳过了中类划分到了小类
224 if(len(layer_20[0])==4):
225 small_class=layer_20[1]
226 # print("大类直接分到小类:\n",small_class)
227 #判断字符串
228 if(qb03==layer_20[0]):
229 print("跨过中类的小类,判断成功!",qb03)
230 flag=True
231 res = items[0]+ qb03+ "·"+ category + "·" + big_class + "·"+small_class
232 return res
233 else:
234 for layer_21 in layer_20[1].items(): #这个for循环已经进入了 第三层正常的中类 {} 里面格式是 (中类名称:{ })
235 # print("中类:\n",layer_21)
236 medium_class = layer_21[0]
237 # print("中类名称:\n",medium_class)
238 # 这里是个大坑,我的遍历是进入值的那一层,编码在上一级的遍历 layer_20[0]
239 # if (qb03 == layer_20[0]):
240 # print("三位中类判断成功!", qb03)
241 # flag=True
242 # res = qb03 + "·" + category + "·" + big_class + "·" + medium_class
243 # return res
244 #继续划分到小类
245 for layer_30 in layer_21[1].items(): #这个for循环已经进入了 第四层 {} 里面格式是 (小类名称:{ })
246 #这个layer_30就是最后一层的四位数数据了 格式: ('0111', '稻谷种植') 是一个tuple 索引0是编码1是名称
247 small_class=layer_30[1]
248 # print("小类名称:\n",small_class)
249 #--------------------------------------------------------------------------------
250 # 判断字符串
251 if (qb03 == layer_30[0]):
252 print("正常四位小类判断成功!", qb03)
253 flag=True
254 res=items[0]+qb03+"·"+category+"·"+big_class+"·"+medium_class+"·"+small_class
255 return res
256 #这里是对没有找到的编码进行二次寻找,字符串拼接,最前面加个0
257 if(flag==False):
258 new_qb03="0"+qb03
259 return ger_stdstr(new_qb03,stdfilepwd) #递归调用自身
260
261 """
262 ------------------------------------------------------------------------------------------------------------------------
263 """
264
265 def do_clean(filepwd,newfilepwd,stdfilepwd):
266 """
267 1、读取源数据表格
268 2、逐个把数据传入get_stdstr(qb03,stdfilepwd)方法获得返回值存回excel表格
269 参数:需要清洗的行业编码,单列数据
270 filepwd,需要清洗的文件
271 newfilepwd,新生成的文件存储路径
272 stdfilepwd,标准的国标文件
273 :return:None
274 """
275 """
276 待清洗的文件格式:filepwd
277 QB03
278 2812
279 3511
280 3071
281 3434
282 2614
283 3620
284 2613
285 2614
286 3512
287
288 清洗完毕的文件格式:newfilepwd
289 data
290 2812·制造业·化学纤维制造业·纤维素纤维原料及纤维制造·人造纤维(纤维素纤维)制造
291 3511·制造业·专用设备制造业·采矿、冶金、建筑专用设备制造·矿山机械制造
292 3071·制造业·非金属矿物制品业·陶瓷制品制造·卫生陶瓷制品制造
293 3434·制造业·通用设备制造业·物料搬运设备制造·连续搬运设备制造
294 2614·制造业·化学原料和化学制品制造业·基础化学原料制造·有机化学原料制造
295 3620·制造业·汽车制造业·改装汽车制造·改装汽车制造
296 2613·制造业·化学原料和化学制品制造业·基础化学原料制造·无机盐制造
297 2614·制造业·化学原料和化学制品制造业·基础化学原料制造·有机化学原料制造
298 3512·制造业·专用设备制造业·采矿、冶金、建筑专用设备制造·石油钻采专用设备制造
299 3599·制造业·专用设备制造业·环保、社会公共服务及其他专用设备制造·其他专用设备制造
300 511·批发和零售业·批发业·农、林、牧产品批发·农、林、牧产品批发
301 3821·制造业·电气机械和器材制造业·输配电及控制设备制造·变压器、整流器和电感器制造
302 6520·信息传输、软件和信息技术服务业·软件和信息技术服务业·信息系统集成服务·信息系统集成服务
303 7330·科学研究和技术服务业·研究和试验发展·农业科学研究和试验发展·农业科学研究和试验发展
304 2922·制造业·橡胶和塑料制品业·塑料制品业·塑料板、管、型材制造
305 """
306 df=pd.read_excel(filepwd)
307 # print(df.loc[0].values)
308 res=[]
309 temp_res=""
310 #range(len(df.index.values))
311 for i in range(len(df.index.values)):
312 # print(df.loc[i].values[0])
313 """
314 ger_stdstr()
315 两个参数 一个是待查编码 一个是标准json文件路径
316 """
317 temp_res=ger_stdstr(str(df.loc[i].values[0]),stdfilepwd)
318 print(temp_res)
319 if(temp_res!=None):
320 res.append(temp_res)
321 else:
322 res.append(str(df.loc[i].values[0]))
323 # print(res)
324 #把结果存储到excel表
325 workbook = xlwt.Workbook(encoding='utf-8')
326 sheet = workbook.add_sheet('sheet1', cell_overwrite_ok=True)
327 sheet.col(0).width=256*100
328 sheet.write(0, 0, "DATA")
329 for i in range(len(res)):
330 sheet.write(i+1, 0, res[i])
331 workbook.save(newfilepwd)
332 return None
333 if __name__ == '__main__':
334 #封装方法getjson()
335 """
336 1、封装构建json的方法 getjson() , 方法有一个参数 参数是文件路径
337 文件的格式是两列,由于读取文件不包括表头,如果表头数据有需要的话 需要复制一行表头数据
338 第一列是行业编码 第二列是行业名称
339 """
340 #测试调用
341 stdfilepwd="GBT4754-2011.xlsx"
342 # get_json(stdfilepwd)
343 """
344 --------------------------------------------------------------
345 """
346
347 #封装方法do_clean(filepwd,newfilepwd,stdfilepwd)
348 # 测试调用
349 filepwd="2013_year_data.xlsx" #需要处理的文件路径13年
350 newfilepwd="2013_res_data.xls" #处理完毕转存的文件路径13年
351
352 filepwd16 = "2016_year_data.xlsx" # 需要处理的文件路径16年
353 newfilepwd16 = "2016_res_data.xls" # 处理完毕转存的文件路径16年
354 do_clean(filepwd16, newfilepwd16, stdfilepwd)
355
356 """
357 --------------------------------------------------------------
358 """
359 #封装ger_stdstr(qb03,jsonfilepwd) 方法 参数1是四位待查编码 参数2是json文件的路径
360 # res=ger_stdstr("321",stdfilepwd)
361 # print(res)
完整版行业分类关注【靠谱杨阅读人生】回复【行业】获取
python 国家标准行业编码标准格式化处理的更多相关文章
- 记录我的 python 学习历程-Day02-while 循环/格式化输出/运算符/编码的初识
一.流程控制之--while 循环 循环就是重复做同一件事,它可以终止当前循环,也可以跳出这一次循环,继续下一次循环. 基本结构(基本循环) while 条件: 循环体 示例 # 这是一个模拟音乐循环 ...
- python学习第四天 --字符编码 与格式化及其字符串切片
字符编码 与格式化 第三天已经知道了字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采 ...
- 【Python④】python恼人的字符串,格式化输出
恼人的字符串 计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母.数字和一些符号,这个编码 ...
- Python里的编码问题
马克一篇 http://bbs.chinaunix.net/archiver/tid-1163613.html http://www.openhome.cc/Gossip/Python/ImportI ...
- Python字符串和编码
在最早的时候只有127个字符被编码到计算机里,也就是大小写英文字母.数字和一些符号,这个编码被成为ASCII编码. 但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突 ...
- Python字符和编码
1. 字符和编码 背景 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte). 由于计算机是美国人发明的,因此, ...
- Python第一章-编码规范
Python的基础知识 一.编码规范 PEP8[^ 注] 编码规范 Guido的关键点之一是:代码更多是用来读而不是写.编码规范旨在改善Python代码的可读性. 风格指南强调一致性.项目.模块或函数 ...
- Python的字符编码
Python的字符编码 1. Python字符编码简介 1. 1 ASCII Python解释器在加载.py文件的代码时,会对内容进行编码,一般默认为ASCII码.ASCII(American St ...
- javascript编码标准
前面的话 编码标准是有争议的.几乎每个人都有自己的标准,但对标准应该是什么样的,则似乎很少能达成共识.但编码标准意味着,通过共同语言和一致的结构,把开发人员从无意义的工作中解放出来.允许开发人员把创新 ...
- python中的编码与解码
编码与解码 首先,明确一点,计算机中存储的信息都是二进制的 编码/解码本质上是一种映射(对应关系),比如‘a’用ascii编码则是65,计算机中存储的就是00110101,但是显示的时候不能显 ...
随机推荐
- Java I/O 教程(九) FileWriter和FileReader
FileWriter Java FileWriter 用于往文件中写入字符数据. 不像FileOutputStream类,你无需转换字符串成字节数组,因为它提供了直接写字符串的方法. 类定义 publ ...
- 具备有效期的sessionStorage存储
具备有效期的sessionStorage存储 类方式 // 具备有效期的sessionStorage存储-类方式. class SessionStorageWrapper { // 存储数据到sess ...
- 案例分享:Qt激光加工焊接设备信息化软件研发(西门子PLC,mysql数据库,用户权限控制,界面设计,参数定制,播放器,二维图,rgv小车,期限控制,参数调试等)
需求 1.键鼠控制,承担ui界面设计,布局兼容分辨率1024x768 ~ 1920x1080. 2.权限控制:三种权限,分为管理员(可以定制模块界面,修改产品名称等定制化软件和其他权限,同时具备 ...
- 【Azure 应用服务】Azure Data Factory中调用Function App遇见403 - Forbidden
问题描述 在Azure Data Factory (数据工厂)中,调用同在Azure中的Function App函数,却出现403 - Forbidden错误. 截图如下: 问题解答 访问Azure ...
- 【Azure 事件中心】适用Mirror Maker生产数据发送到Azure Event Hub出现发送一段时间后Timeout Exception: Expiring 18 record(s) for xxxxxxx: 79823 ms has passed since last append
问题描述 根据"将 Apache Kafka MirrorMaker 与事件中心配合使用"一文,成功配置了Mirror Maker来发送数据到Event Hub中.为什么只能成功运 ...
- Codeforces Round 924 (Div. 2)B. Equalize(思维+双指针)
目录 题面 链接 题意 题解 代码 题面 链接 B. Equalize 题意 给一个数组\(a\),然后让你给这个数组加上一个排列,求出现最多的次数 题解 赛时没过不应该. 最开始很容易想到要去重,因 ...
- PaddleOCR 服务化部署(基于PaddleHub Serving)
最近用到百度飞桨的 PaddleOCR,研究了一下PaddleOCR的服务化部署,简单记录一些部署过程和碰到的问题. 基础环境 paddlepaddle 2.5.2 python 3.7 paddle ...
- 记spring boot启动出现Unable to start ServletWebServerApplicationContext due to missing ServletWebServerFactory bean.问题处理
今天拉下了一个新的springboot工程,启动时出现了Unable to start web server; nested exception is org.springframework.cont ...
- CSS Navigation - vscode 插件 - vue css 跳转
CSS Navigation - vscode 插件 - vue css 跳转
- C#实现软件开机自启动(不需要管理员权限)
目录 原理简介 使用方法 完整代码 原理简介 本文参考C#/WPF/WinForm/程序实现软件开机自动启动的两种常用方法,将里面中的第一种方法做了封装成AutoStart类,使用时直接两三行代码就可 ...