DW:优化目标检测训练过程,更全面的正负权重计算 | CVPR 2022
论文提出自适应的label assignment方法DW,打破了以往耦合加权的惯例。根据不同角度的一致性和非一致性指标,动态地为anchor分配独立的pos权重和neg权重,可以更全面地监督训练。此外,论文还提出了新的预测框精调操作,在回归特征图上直接精调预测框
来源:晓飞的算法工程笔记 公众号
论文:A Dual Weighting Label Assignment Scheme for Object Detection

Introduction
Anchor作为目标检测器训练的基础单元,需要被赋予正确的分类标签和回归标签,这样的标签指定(LA, label assignment)过程也可认为是损失权重指定过程。对于单个anchor的cls损失计算,可以统一地表示为:
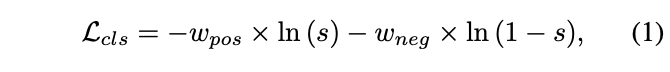
\(w_{pos}\)和\(w_{neg}\)为正向权重和反向权重,用于控制训练的方向。基于这个设计,可以将LA方法分为两个大类:
- Hard LA:每个anchor都可被分为pos或neg,即\(w_{pos},w_{neg}\in \{0,1\}\)以及\(w_{pos}+w_{neg}=1\),这类方法的核心在于找到区分正负anchor的界限。经典的做法直接采用固定的IoU阈值进行判断,忽略了目标在大小和形状上的差异。而近期如ATSS等研究则提出动态阈值的概念,根据具体的IoU分布来划分anchor。但对于训练来说,不管是静态还是动态的Hard LA方法,都忽略了anchor本身的重要性差异。
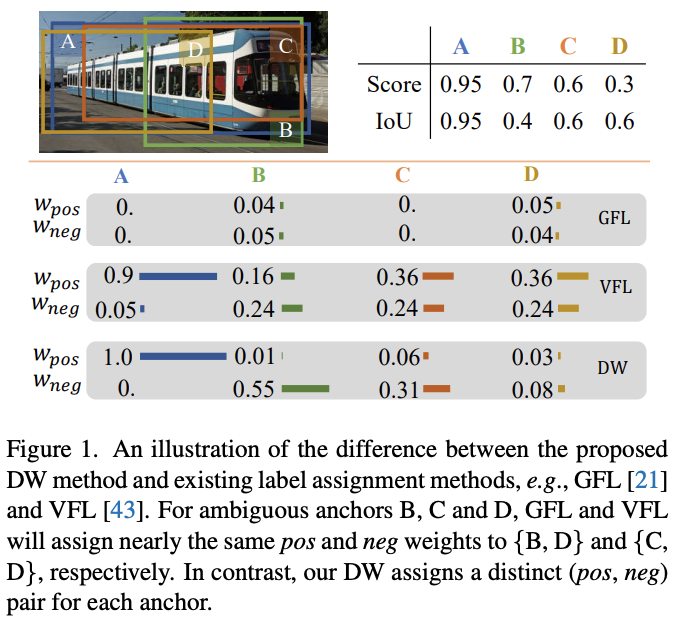
- Soft LA:为了克服Hard LA的缺点,GFL和VFL等研究提出了soft权重的概念。这类方法基于IoU为每个anchor设定soft label目标,并且根据cls分数和reg分数为anchor计算\(w_{pos}\)和\(w_{neg}\)。但目前这些方法都专注于\(w_{pos}\)的设计,\(w_{neg}\)一般直接从\(w_{pos}\)中衍生而来,导致网络缺少来自于neg权重的监督信息。如图1所示,GFL和VFL为质量不同的anchor赋予相似的损失权重,这可能会降低检测器的性能。
为了给检测器提供更多的监督信息,论文提出了新的LA方法DW(dual weighting),从不同的角度单独计算\(w_{pos}\)和\(w_{neg}\)并让其能够互补。此外,为了给权重计算函数提供更准确的reg分数,论文还提出了新的bbox精调操作,预测目标的边界位置并根据对应的特征产生更准确的精调信息。
Proposed Method
Motivation and Framework
由于NMS的存在,检测器应该预测一致的bbox,既有高分类分数也有准确的位置定位。但如果在训练时平等地对待所有的训练样本,而cls分数越高的预测结果的reg位置不一定越准确,这往往会导致cls head与reg head之间就会存在不一致性。为此,Soft LA通过加权损失来更柔和地对待训练样本,加强cls head与reg head的一致性。基于Soft LA,anchor的损失可以表示为:
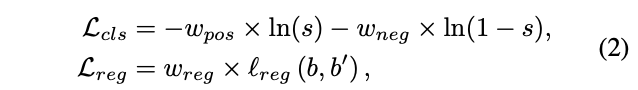
其中\(s\)为预测的cls分数。为一致性更高的预测结果分配更大的\(w_{pos}\)和\(w_{reg}\),能够使得网络专注于学习高质量的预测结果,减轻cls head与reg head的不一致问题。

当前的方法直接将\(w_{reg}\)设置为\(w_{pos}\),主要关注如何定义一致性以及如何将其集成到损失权重中。表1总结了一些方法对\(w_{pos}\)和\(w_{neg}\)的计算公式,这些方法先定义用于度量一致性的指标\(t\),随后将\(1-t\)作为不一致性的度量指标,最后添加缩放因子将指标集成到损失权重中。
上述方法的\(w_{pos}\)和\(w_{neg}\)都是高度相关的,而论文认为pos和neg权重应该以prediction-aware的方式单独设置,具体如下:
- pos weighting function:以预测的cls分数和预测框的IoU作为输入,预测两者的一致性程度作为pos权重。
- neg weighting function:同样以预测cls分数和预测框的IoU作为输入,但将neg权重定义为anchor为负的概率以及anchor作为负的重要程度的乘积。
通过上述定义,对于pos权重相似的这种模棱两可的anchor,就可以根据不同的neg权重得到更细粒度的监督信息。
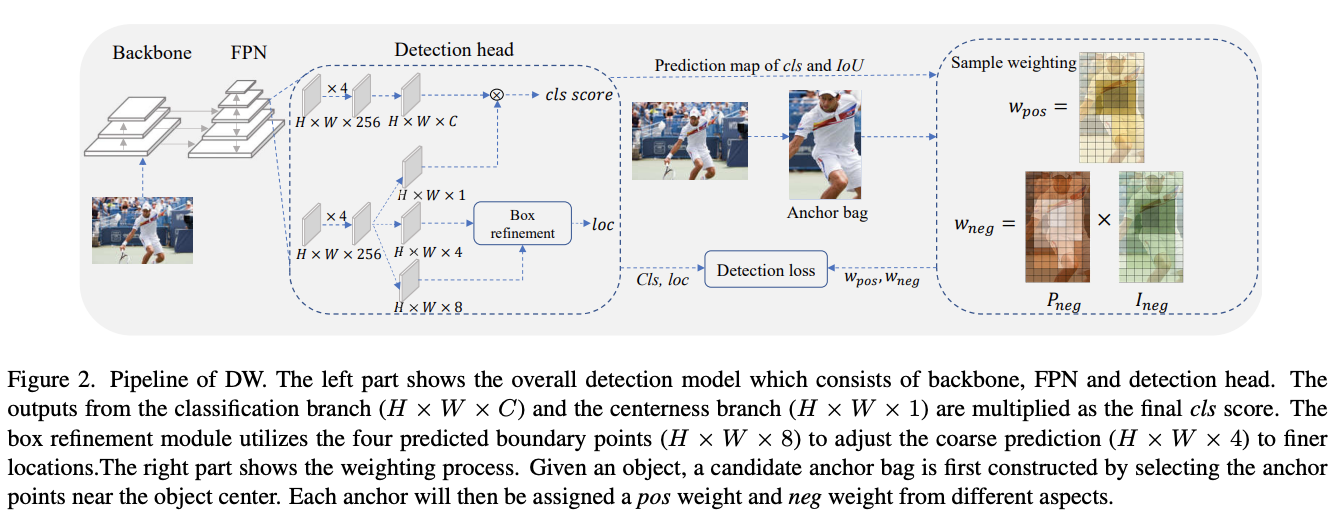
DW方法的整体流程如图2所示,先根据中心点距离来为每个GT构造候选正样本集,其余的anchor为候选负样本。由于负样本的统计信息十分混乱,所以不参与权重函数的计算。候选正样本会被赋予三个权重\(W_{pos}\)、\(W_{neg}\)以及\(W_{reg}\),用于更有效地监督训练。
Positive Weighting Function
pos权重需要反映预测结果对检测性能的重要性,论文从目标检测的验证指标来分析影响重要性的因素。在测试时,通常会根据cls分数或cls分数与IoU的结合对单分类的预测结果进行排序,从前往后依次判断。正确的预测需满足以下两点:
- a. 与所属GT的IoU大于阈值\(\theta\)。
- b. 无其他排名靠前且所属GT相同的预测结果满足条件a。
上述条件可认为是选择高ranking分数以及高IoU的预测结果,也意味着满足这两个条件的预测结果有更大概率在测试阶段被选择。从这个角度来看,pos权重\(w_{pos}\)就应该与IoU和ranking分数正相关。首先定义一致性指标\(t\),用于度量两个条件的对齐程度:
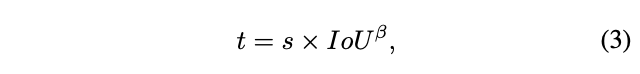
为了让不同anchor的pos权重的方差更大,添加指数调节因子:
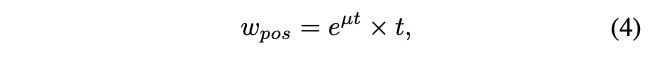
最终,各anchor的pos权重会根据对应GT的候选anchor的pos权重之和进行归一化。
Negative Weighting Function
pos权重虽然可以使得一致的anchor同时具有高cls分数和高IoU,但无法区分不一致anchor的重要程度。如前面图1所示,anchor D定位校准但分类分数较低,而anchor B恰好相反。两者的一致性程度\(t\)一致,pos权重无法区分差异。为了给检测器提供更多的监督信息,准确地体现anchor的重要程度,论文提出为两者赋予更清晰的neg权重,具体由以下两部分构成。
Probability of being a Negative Sample
根据COCO的验证指标,IoU不满足阈值的预测结果一律归为错误的检测。所以,IoU是决定achor为负样本的概率的唯一因素,记为\(P_{neg}\)。由于COCO使用0.5-0.95的IoU阈值来计算AO,所以\(P_{neg}\)应该满足以下规则:
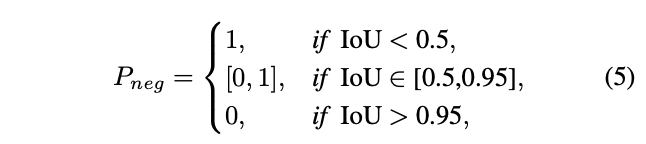
任意\([0.5,0.95]\)上单调递减的函数都可以作为\(P_{neg}\)中间部分。为了简便,论文采用了以下函数:
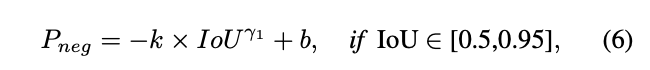
公式6需要穿过点\((0.5,1)\)和\((0.95, 0)\),一旦\(\gamma_1\)确定了,参数\(k\)和\(b\)可通过待定系数法确定。
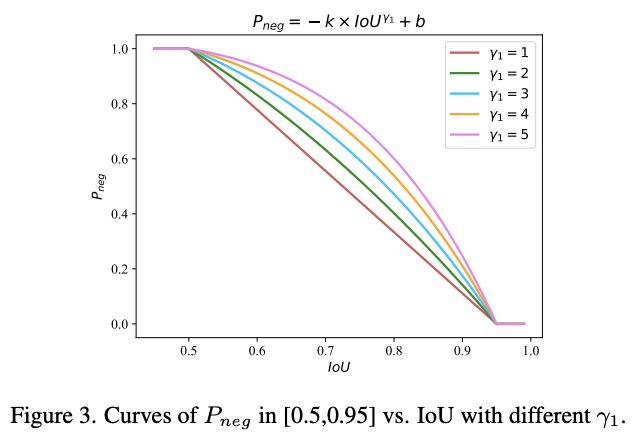
图3展示了不同\(\gamma_1\)下的\(P_{neg}\)曲线。
Importance Conditioned on being a Negative Sample
在推理时,ranking队列中靠前的neg预测结果虽然不会影响召回率,但会降低准确率。为了得到更高的性能,应该尽可能地降低neg预测结果的ranking分数。所以在训练中,ranking分数较高的neg预测结果应该比ranking分数较低的预测结果更为重要。基于此,定义neg预测结果的重要程度\(I_{neg}\)为ranking分数的函数:
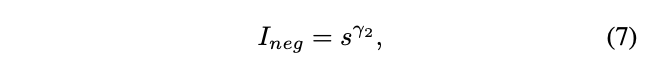
最终,整体的neg权重\(w_{neg}=P_{neg}\times I_{neg}\)变为:
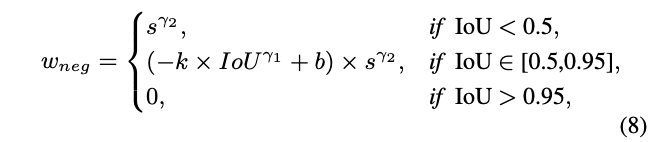
\(w_{neg}\)与\(IoU\)负相关,与\(s\)正相关。对于pos权重相同的anchor,IoU更小的会有更大的neg权重。在兼容验证指标的同时,\(w_{neg}\)能给予检测器更多的监督信息。
Box Refinement
pos权重和neg权重都以IoU作为输入,更准确的IoU可以保证更高质量的训练样本,有助于学习更强的特征。为此,论文提出了新的box精调操作,基于预测的四条边的偏移值\(O\in R^{H\times W\times 4}\)进行下一步的精调。

考虑到目标边界上的点有更大的概率预测准确的位置,论文设计了可学习的预测模块,基于初步的bbox为每条边生成边界点。如图4所示,四个边界点的坐标定义为:
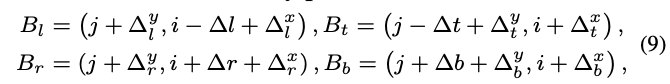
其中,\(\{\Delta^x_l,\Delta^y_l,\Delta^x_t,\Delta^y_t,\Delta^x_r,\Delta^y_r,\Delta^x_b,\Delta^y_b\}\)为精调模块的输出。最后,结合边界点的预测和精调模块的输出,最终精调后的anchor偏移\(O^{'}\)为:
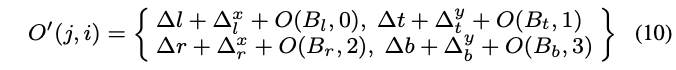
Loss Function
DW策略可直接应用到大多数的dense检测器中。论文将DW应用到FCOS中并进行了少量修改,将centerness分支和分类分支合并成cls分数,网络的损失为:
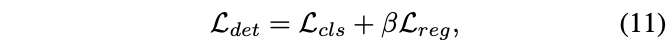
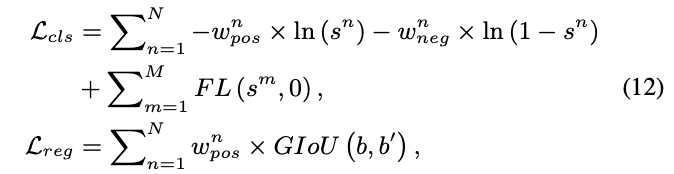
这里的\(\beta\)跟公式3是同一个,\(N\)和\(M\)分别为候选anchor数和非候选anchor数。
Experiment
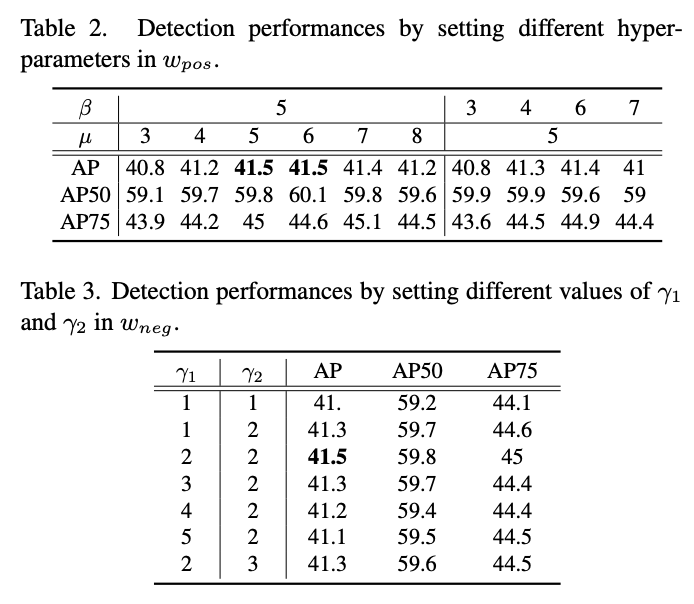
平衡超参数对性能的影响。
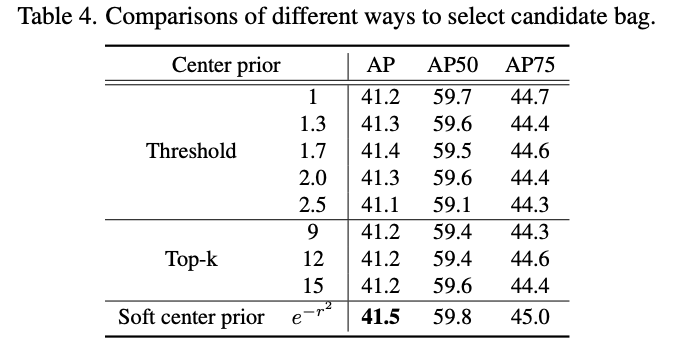
候选anchor选择方法对性能的影响。第一种为中心点的距离阈值,第二种选择最近的几个,第三种为距离权重与pos权重乘积排序。
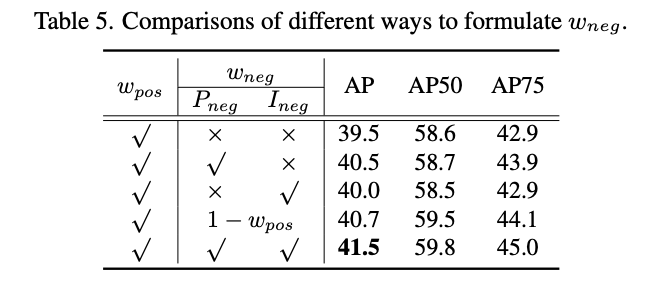
neg权重计算方式对比。
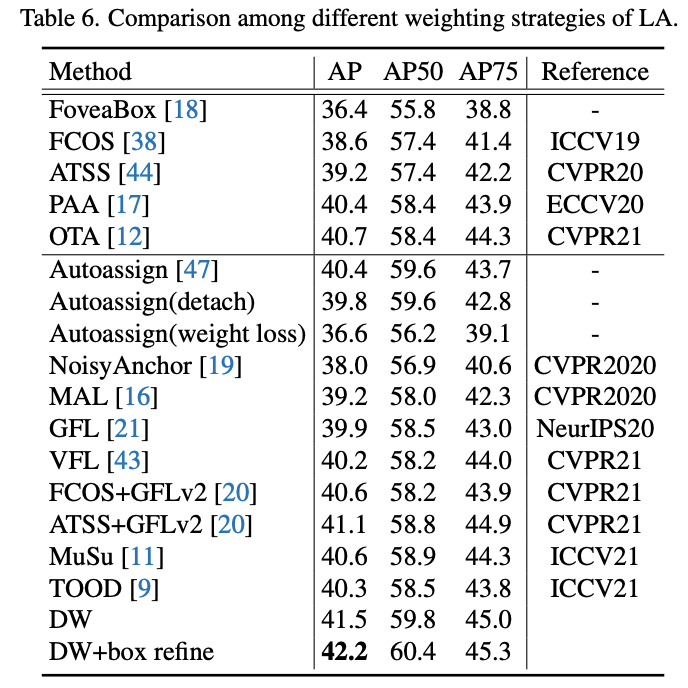
LA研究之间的对比。
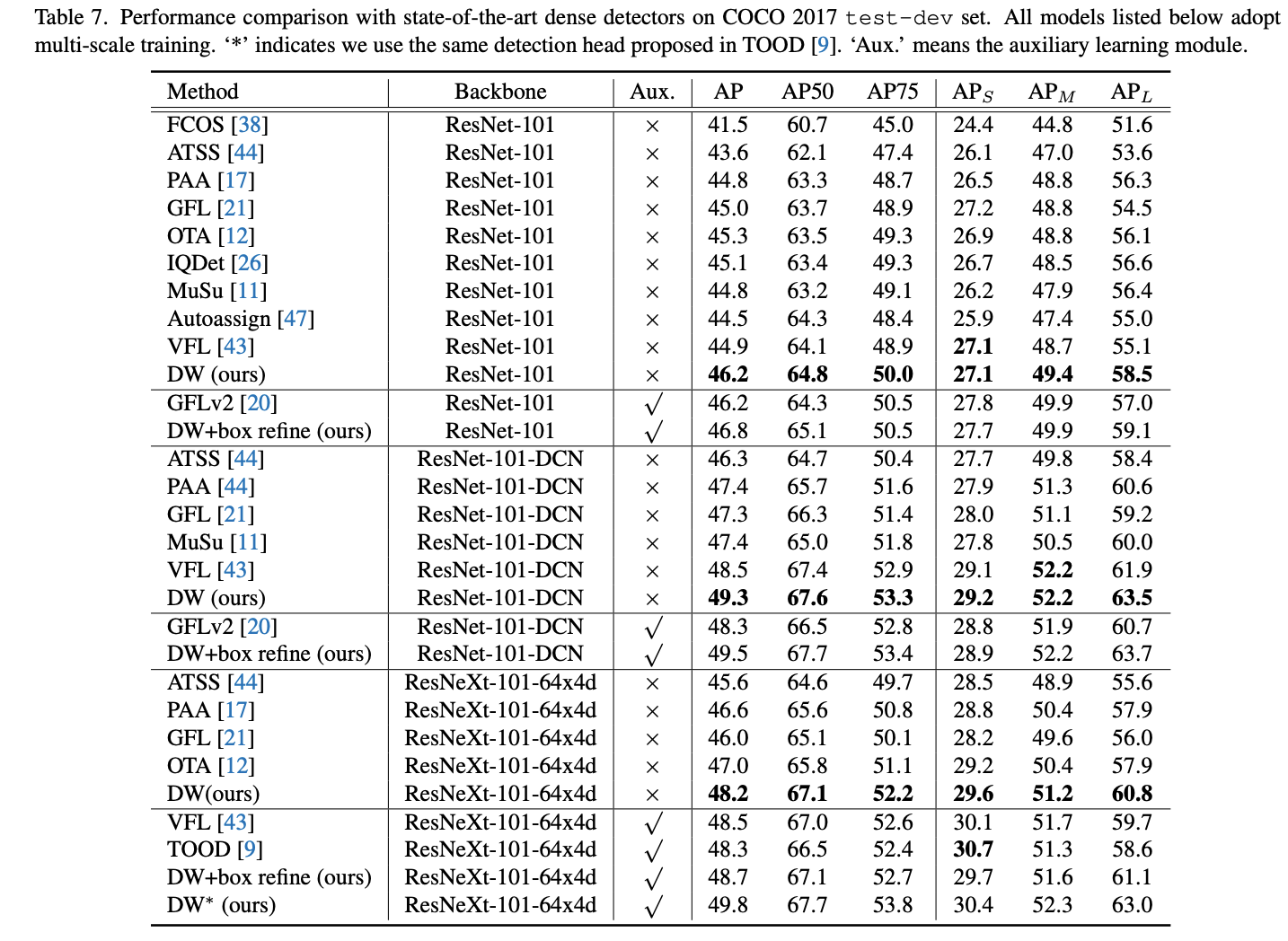
与SOTA检测算法对比。
Conclusion
论文提出自适应的label assignment方法DW,打破了以往耦合加权的惯例。根据不同角度的一致性和非一致性指标,动态地为anchor分配独立的pos权重和neg权重,可以更全面地监督训练。此外,论文还提出了新的预测框精调操作,在回归特征图上直接精调预测框。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

DW:优化目标检测训练过程,更全面的正负权重计算 | CVPR 2022的更多相关文章
- GPU上创建目标检测Pipeline管道
GPU上创建目标检测Pipeline管道 Creating an Object Detection Pipeline for GPUs 今年3月早些时候,展示了retinanet示例,这是一个开源示例 ...
- OpenCV 学习笔记 07 目标检测与识别
目标检测与识别是计算机视觉中最常见的挑战之一.属于高级主题. 本章节将扩展目标检测的概念,首先探讨人脸识别技术,然后将该技术应用到显示生活中的各种目标检测. 1 目标检测与识别技术 为了与OpenCV ...
- 基于候选区域的深度学习目标检测算法R-CNN,Fast R-CNN,Faster R-CNN
参考文献 [1]Rich feature hierarchies for accurate object detection and semantic segmentation [2]Fast R-C ...
- 【目标检测】SSD:
slides 讲得是相当清楚了: http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf 配合中文翻译来看: https://www.cnb ...
- 不带Anchors和NMS的目标检测
前言: 目标检测是计算机视觉中的一项传统任务.自2015年以来,人们倾向于使用现代深度学习技术来提高目标检测的性能.虽然模型的准确性越来越高,但模型的复杂性也增加了,主要是由于在训练和NMS后处理过 ...
- 带你读AI论文丨用于目标检测的高斯检测框与ProbIoU
摘要:本文解读了<Gaussian Bounding Boxes and Probabilistic Intersection-over-Union for Object Detection&g ...
- Anchor-free目标检测综述 -- Keypoint-based篇
早期目标检测研究以anchor-based为主,设定初始anchor,预测anchor的修正值,分为two-stage目标检测与one-stage目标检测,分别以Faster R-CNN和SSD作 ...
- 目标检测模型的评价标准-AP与mAP
目录 目录 目录 前言 一,精确率.召回率与F1 1.1,准确率 1.2,精确率.召回率 1.3,F1 分数 1.4,PR 曲线 1.4.1,如何理解 P-R 曲线 1.5,ROC 曲线与 AUC 面 ...
- 动手创建 SSD 目标检测框架
参考:单发多框检测(SSD) 本文代码被我放置在 Github:https://github.com/XinetAI/CVX/blob/master/app/gluoncvx/ssd.py 关于 SS ...
- 目标检测中常提到的IoU和mAP究竟是什么?
看完这篇就懂了. IoU intersect over union,中文:交并比.指目标预测框和真实框的交集和并集的比例. mAP mean average precision.是指每个类别的平均查准 ...
随机推荐
- Context与Reducer
Context与Reducer Context是React提供的一种跨组件的通信方案,useContext与useReducer是在React 16.8之后提供的Hooks API,我们可以通过use ...
- Innodb 存储引擎表
目录 索引组织表 Innodb逻辑存储结构 表空间 段 区 页 行 Innodb 行记录格式 Compact Redundant 行溢出数据 Compressed 和 Dynamic 行记录格式 ch ...
- C++ 多线程的错误和如何避免(12)
std::async 在简单的 IO 上比 std::thread 更有优势 前提:如果我们只需要一些异步执行的代码,这样不会阻塞主线程的执行,最好的办法是使用 std::async 来执行这些代码. ...
- RK3568开发笔记(三):RK3568虚拟机基础环境搭建之更新源、安装网络工具、串口调试、网络连接、文件传输、安装vscode和samba共享服务
前言 开始搭建RK3568的基础虚拟机,具备基本的通用功能,主要包含了串口工具minicom,远程登陆ssh,远程传输filezilla,代码编辑工具vscode. 虚拟机 文档对对虚拟机 ...
- 解决pip install时出现的Could not fetch URL https://pypi.org/simple/pip/问题
打开windows的我的电脑,在最上方目录栏输入%APPDATA%,回车,接着会定位到一个新的目录, 目录路径为C:\Users\Administrator\AppData\Roaming,在这个目录 ...
- 【Azure K8S|AKS】进入AKS的POD中查看文件,例如PVC Volume Mounts使用情况
问题描述 在昨天的文章中,创建了 Disk + PV + PVC + POD 方案(https://www.cnblogs.com/lulight/p/17604441.html),那么如何进入到PO ...
- [manjaro linux] 安装完成之后的配置工作,以及常用软件的安装
emmm 很久没有更新了,绝对不是丢掉了博客帐号,有时间还是要好好装饰以下博客的... https://zhuanlan.zhihu.com/p/114296129 看到很多过程 sudo pacma ...
- FolkMQ 作个简单的消息中间件(最简单的那种), v1.3.1 发布
功能简介 角色 功能 生产端(或发起端) 发布消息.定时消息(或叫延时).顺序消息.可过期消息.事务消息.发送消息(rpc)支持 Qos0.Qos1 消费端(或接收端) 订阅.取消订阅.消费-ACK( ...
- git 取消代理无效?试试这个
git 取消代理的命令操作 git conifg --global --unset http.proxy git conifg --global --unset https.proxy 一般情况下这种 ...
- 完整塔建一个spring 注解版 mybaties 过程可供复制代码
第一步引导包.新建工程maven模块 pom.xml 中导入相对应包 ++++++++++++++++++++++++++++++++++++++++++++ 1 +++++++ ...