一行超长日志引发的 “血案” - Containerd 频繁 OOM 背后的真相
案发现场:混沌初现
2024年6月10日,本应是平静的一天。但从上午 9 点开始,Sealos 公有云的运维监控告警就开始不停地响。北京可用区服务器节点突然出现大量 “not ready” 告警,紧接着,系统自动触发 004 节点重启,让服务暂时恢复了正常。
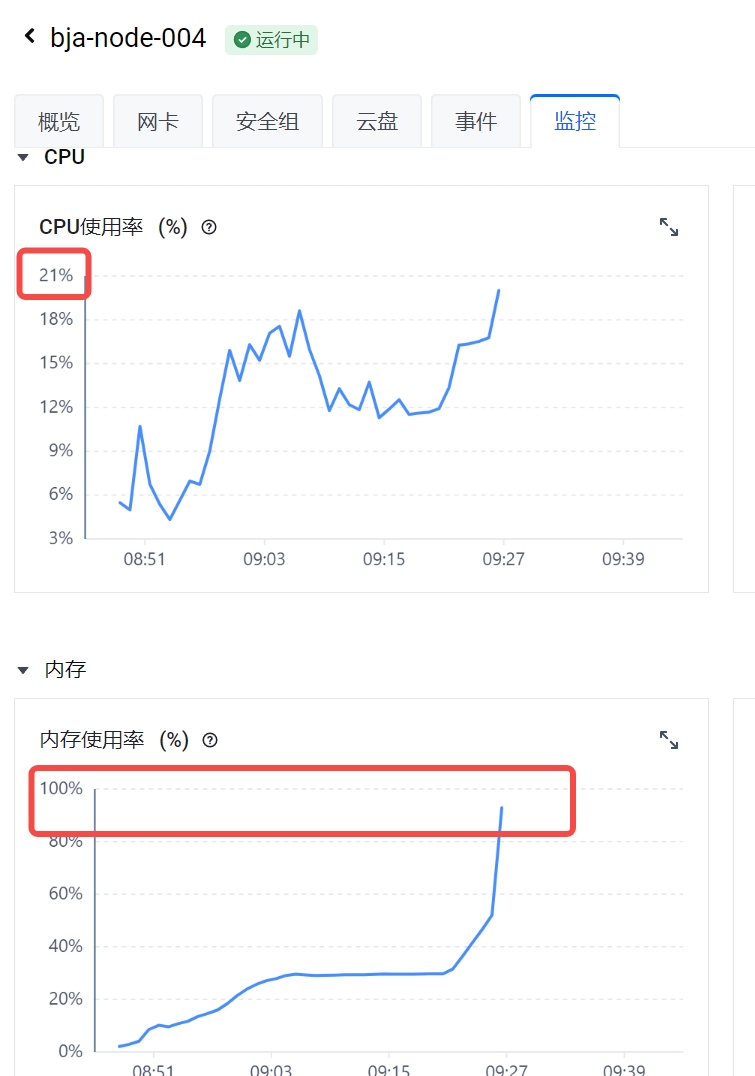
就在我以为这只是个小插曲的时候,7分钟后,广州可用区服务器也沦陷了!001 节点不得不重启以求自保。事情似乎并没有那么简单。
“发生什么事了?!” 运维同学们迅速登录服务器排查。原本稳定运行在 30%左右的内存使用率,在几分钟内飙升到 100%。“看起来像是有新应用大量占用内存?”
问题排查:真相难明
“难道是底层机器的内存不足以支撑业务的增长?” 抱着姑且一试的态度,我们紧急升级了北京可用区服务器的配置,将内存容量直接翻倍。观察一段时间后,服务基本恢复稳定。“看来还是资源预留不足,3 倍底线仍然扛不住啊。” 大家暂时松了口气。
广州可用区的扩容也在40分钟后完成。
正当大家松了一口气,准备撤离 “战场” 时,北京可用区又开始卷土重来:16:22,接连不断的 not ready 告警又回来了!003 和 004 节点在资源耗尽的边缘反复横跳。人工重启维持一会儿还好,可 10 几分钟后,崩溃又卷土重来,内存曲线坚定地向右上方奔去...
更让人无语的是,计划赶不上变化,17:46,广州可用区也开始出问题,两个集群再次陷入节点轮番崩溃的怪圈。
揭示真相:内存炸弹,原来是你!
局势愈发紧张,我们只能通过不断重启节点,维持业务的运转。但内存增长的势头依然强劲,系统每隔 15-30分钟就会崩溃。
内存泄露?
面对诡异的内存曲线,有人提出会不会是内存泄露?大家决定从系统内核和容器两个方向深挖。
首先怀疑是不是有容器在疯狂打印日志。统计对比发现整体集群的 Pod 数量上升并不异常,排除了 Pod 数量暴增导致的资源问题。但在统计各节点内存使用时,发现所有 Pod 的实际内存使用总和,远小于宿主机的内存占用。
进一步确认是 Containerd 进程的内存占用在飙升,最高达到了恐怖的 1G/s 速率!而与此同时,Pod 本身的资源使用一直很平稳。
定位罪魁祸首
进一步怀疑可能是 Containerd 的 Bug 导致内存泄露。我们决定先将整个集群的 Containerd 升级到最新的 1.7.18 版本再继续观察。升级命令如下:
#!/usr/bin/env bashset -euxo pipefail
wget https://github.com/containerd/containerd/releases/download/v1.7.18/containerd-1.7.18-linux-amd64.tar.gz
tar xfz containerd-1.7.18-linux-amd64.tar.gz -C /usr
systemctl restart containerd && sleep 3
systemctl is-active containerd
结果负载降低后,Containerd 的内存占用依然在缓慢上涨。也就是说,更新后的 Containerd 还是在快速泄露内存。
大家开始把注意力放到 Containerd 身上,从多个角度展开排查:
1。通过 pprof 采样分析 containerd 内存分配情况
首先修改 containerd 配置,使其输出 debug 日志信息:
[debug]
address = "/run/containerd/containerd-debug.sock"
uid = 0
gid = 0
level = "debug"
format = "json"
然后开始采样,输出 pprof 文件:
ctr pprof --debug-socket /run/containerd/containerd-debug.sock heap >> containerd.pprof
查看 pprof 文件内容,怀疑与容器日志有关。

于是开始通过节点保存的容器日志查找是否有 pod 输出了大量日志。
2。观察集群节点互相重启的情况,尝试通过黑盒方式定位出问题的容器/镜像
首先通过命令获取节点的所有正在运行的 Pod,获取其中的所有 image 信息,减去其他正常节点的所有 image 信息,得到只在出问题节点运行的 image 镜像列表。
通过北京可用区节点和广州可用区节点的上述操作求交集,进一步减少独立出现的镜像列表,得到如下的列表:
aibotk/wechat-assistant
aibotk/wechat-assistant:v4.6.28
calciumion/new-api:latest
cloudreve/cloudreve
cloudtogouser/pageplug-ce
csjiangyj/filesys
docker.io/semitechnologies/weaviate:1.19.6
ghcr.io/songquanpeng/one-api:latest
harbor.service.xiaoyangedu.net/zadig/confluence-crack:7.13.20
infracreate-registry.cn-zhangjiakou.cr.aliyuncs.com/apecloud/csi-attacher:v3.4.0
jupyter/scipy-notebook
prom/alertmanager:v0.25.0
quay.io/cilium/hubble-ui-backend:v0.13.0@sha256:1e7657d997c5a48253bb8dc91ecee75b63018d16ff5e5797e5af367336bc8803
quay.io/cilium/hubble-ui:v0.13.0@sha256:7d663dc16538dd6e29061abd1047013a645e6e69c115e008bee9ea9fef9a6666
quay.io/cilium/operator-generic:v1.15.5@sha256:f5d3d19754074ca052be6aac5d1ffb1de1eb5f2d947222b5f10f6d97ad4383e8
registry.cn-chengdu.aliyuncs.com/wyxz_test/wyxz:go-man-2024-05-22-15-04-30-2
registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:latest
registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt-sandbox:v4.8.3
registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:v4.7
registry.cn-hangzhou.aliyuncs.com/gxtatu/guet-server:latest
registry.cn-hangzhou.aliyuncs.com/pandak/ssh:latest
registry.cn-hongkong.aliyuncs.com/manyun2024/subconverter:clashv2
registry.k8s.io/coredns/coredns:v1.10.1
排除掉最常见的集群内部组件的镜像,也还是有十多个应用镜像,于是我们尝试逐个进入应用终端内排查,可是每个容器资源占用都很正常。
排查过程中,出现问题的节点仍然因为 OOM 不得不反复重启 Containerd。
继续研究 containerd 的内存使用和日志处理流程,终于在 NewCRILogger 函数的 redirectLogs 中,发现端倪:
redirectLogs 会根据传入的 maxLen,也就是 max_container_log_line_size 参数,来决定内存缓冲区的大小。如果 maxLen 是-1 (无限制),那么任何超长的日志,都会一次性载入内存,直到把内存吃光!
顺藤摸瓜,发现罪魁祸首正是 Sealos 集群默认配置里的 max_container_log_line_size=-1。而 Containerd 官方默认值应该是 16384。
为了验证,我们设置广州可用区的 node004 节点的 Containerd 将 maxLen 改为 16384,重启后案情峰回路转,内存终于不再失控了!
为了确保这就是根本原因,我们编写了一个测试程序,不断打印超长日志。在有问题的默认配置下,成功稳定复现了节点 Containerd 内存飙升的现象。而限制了长度的新配置,即使打印再多日志也不会有问题。
究其根本,只是之前没遇到打印特别长日志的应用,一直 “藏而不发” 罢了。
问题复现
最终我们可以确定,在出问题的默认配置的 Containerd 环境上,如果有容器在一行打印大量日志,必定会出现大量占用内存的情形。
可以参考我们 mock 程序源码地址,其中的核心就一个 fmt.Printf 函数。
私有化部署的 Sealos 环境可以直接在 Launchpad 上部署我们打包好的镜像,可以稳定复现。测试镜像地址:docker.io/lingdie/containerd-log-debug:dev
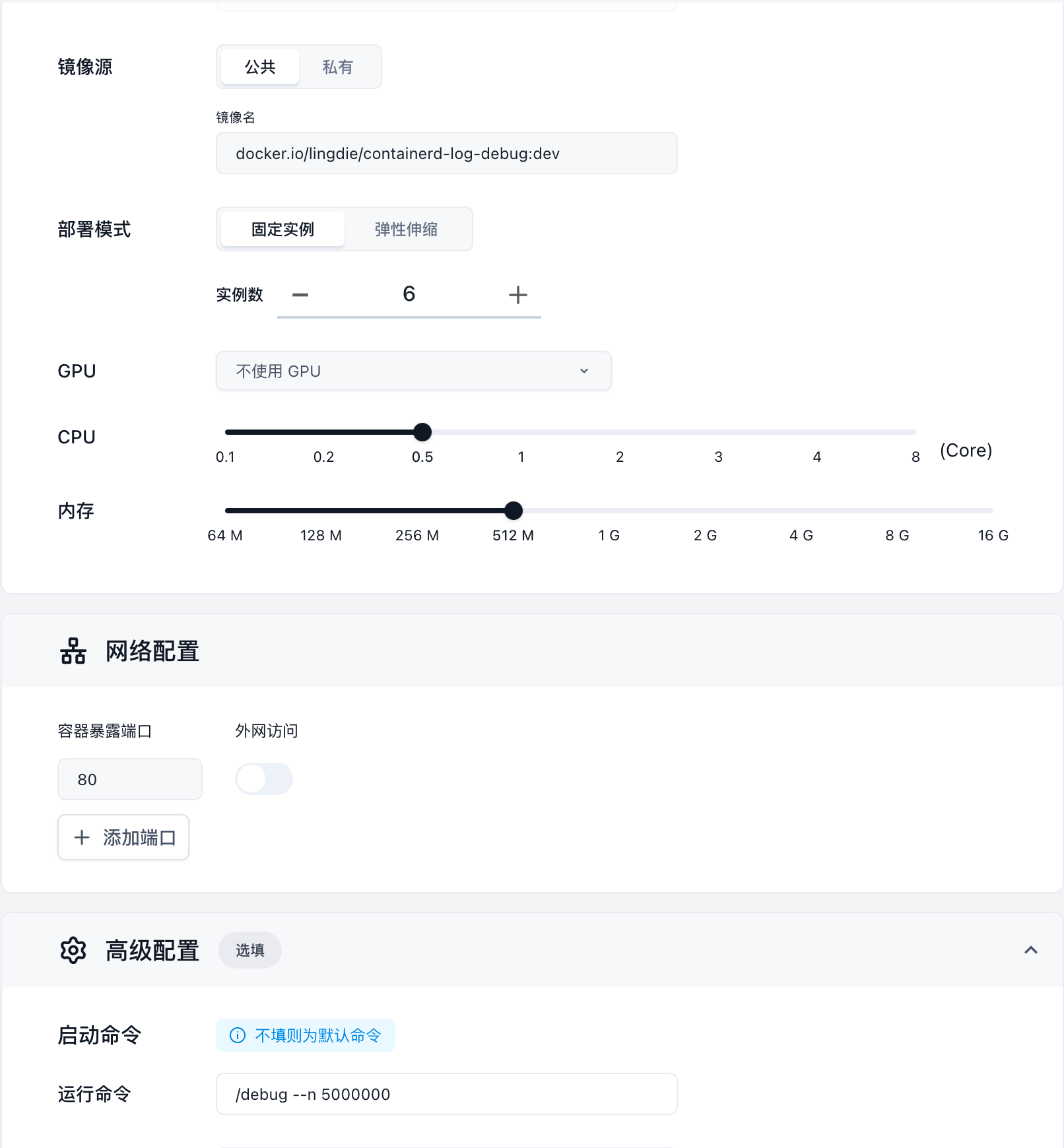
刨根问底
Sealos 的 runtime 将 Containerd 的 max_container_log_line_size 参数设置为默认值 -1,这块代码在创建时就没有再动过,而排查 Containerd 的源码发现其最新版的默认值是 16384。
通过深入源码发现,这里的参数会影响系统申请的 buf 的实现,参考:https://github.com/containerd/containerd/blob/main/internal/cri/io/logger.go
这个 max_container_log_line_size 会作为 NewCRILogger 的 maxLen 参数传递进来:
// 这里的 maxLen,sealos 默认值是-1, containerd 最新版默认值是 16384
func NewCRILogger(path string, w io.Writer, stream StreamType, maxLen int) (io.WriteCloser, <-chan struct{}) {
log.L.Debugf("Start writing stream %q to log file %q", stream, path)
prc, pwc := io.Pipe()
stop := make(chan struct{})
go func() {
redirectLogs(path, prc, w, stream, maxLen)
close(stop)
}()
return pwc, stop
}
这里会启动一个 channel 去重定向日志,而其中最关键的 redirectLogs 函数里面,会根据 maxLen 决定 buf 的大小:
const (
// defaultBufSize is the default size of the read buffer in bytes.
defaultBufSize = 4096
)
...
func redirectLogs(path string, rc io.ReadCloser, w io.Writer, s StreamType, maxLen int) {
var (
...
bufSize = defaultBufSize
...
)
...
// Make sure bufSize <= maxLen
if maxLen > 0 && maxLen < bufSize {
bufSize = maxLen
}
r := bufio.NewReaderSize(rc, bufSize)
...
for {
newLine, isPrefix, err := readLine(r)
...
if maxLen > 0 && length > maxLen {
exceedLen := length - maxLen
last := buf[len(buf)-1]
if exceedLen > len(last) {
// exceedLen must <= len(last), or else the buffer
// should have be written in the previous iteration.
panic("exceed length should <= last buffer size")
}
buf[len(buf)-1] = last[:len(last)-exceedLen]
writeLineBuffer(partial, buf)
splitEntries.Inc()
buf = [][]byte{last[len(last)-exceedLen:]}
length = exceedLen
...
}
}
}
由于 Containerd 将日志写入文件的方式以行为单位,因此若某程序产生一行超长日志,且 max_container_log_line_size 不限制,那么将造成其日志永久占用内存资源,也无法在节点上查询这段日志 (比如 kubectl logs 无法返回日志)。
解决方案
明白病灶所在,治疗就轻而易举了。我们为所有集群的 containerd 配置都加上了合理的 maxLen 限制,观察一段时间后,问题不再出现。
同时修复了 Sealos 源码里的默认配置,重新打包了镜像。还对有问题的应用日志长度做了切分限制。
相关 PR:https://github.com/labring-actions/runtime/pull/15
相关 Issue:https://github.com/labring-actions/runtime/issues/14
私有化部署修复方案
sealos exec 'sed -i "s/max_container_log_line_size = -1/max_container_log_line_size = 16384/" /etc/containerd/config.toml'
sealos exec 'systemctl restart containerd'
经验总结
回顾这次事件,虽然过程一波三折,但庆幸我们没有被 “温水煮青蛙”,及时止损。感谢团队的通力协作,不眠不休地排除故障,力保业务平稳。这次的惨痛教训也让我们更加深刻地认识到,在复杂的容器环境中,Kernel 的每一个细微参数都可能带来致命影响。有几点经验在这里总结一下:
- 默认配置一定要设置合理,不能存有侥幸。无限制的内存很可能就是定时炸弹;
- 要警惕打印超长日志的情况,在应用侧做好长度截断。但底层程序也要有自我保护;
- 监控警报、资源曲线、节点指标,是异常的第一发现者。再结合运维同学的经验直觉,能快速圈定排查方向;
- 源码面前,了无秘密。当反复试错无果时,要学会深入源码一探究竟。这需要一定的技术积累,平时多读优秀开源项目的代码就很有帮助;
- 复盘总结很重要,要举一反三,从根本上解决类似问题,并形成规范和知识库,提升整个团队的效率。
一行超长日志引发的 “血案” - Containerd 频繁 OOM 背后的真相的更多相关文章
- [WCF]缺少一行代码引发的血案
这是今天作项目支持的发现的一个关于WCF的问题,虽然最终我只是添加了一行代码就解决了这个问题,但是整个纠错过程是痛苦的,甚至最终发现这个问题都具有偶然性.具体来说,这是一个关于如何自动为服务接口(契约 ...
- Replication的犄角旮旯(七)-- 一个DDL引发的血案(下)(聊聊logreader的延迟)
<Replication的犄角旮旯>系列导读 Replication的犄角旮旯(一)--变更订阅端表名的应用场景 Replication的犄角旮旯(二)--寻找订阅端丢失的记录 Repli ...
- 转:一个Sqrt函数引发的血案
转自:http://www.cnblogs.com/pkuoliver/archive/2010/10/06/1844725.html 源码下载地址:http://diducoder.com/sotr ...
- 一个Sqrt函数引发的血案(转)
作者: 码农1946 来源: 博客园 发布时间: 2013-10-09 11:37 阅读: 4556 次 推荐: 41 原文链接 [收藏] 好吧,我承认我标题党了,不过既然你来了, ...
- 一个无锁消息队列引发的血案(四)——月:RingQueue(上) 自旋锁
目录 (一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer (四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术 (六)RingQueue(中) 休眠的 ...
- 【转载】一个Sqrt函数引发的血案
转自:http://www.cnblogs.com/pkuoliver/archive/2010/10/06/sotry-about-sqrt.html 源码下载地址:http://diducoder ...
- 一个Sqrt函数引发的血案
源码下载地址:http://diducoder.com/sotry-about-sqrt.html 好吧,我承认我标题党了,不过既然你来了,就认真看下去吧,保证你有收获. 我们平时经常会有一些数据运算 ...
- 一次"内存泄漏"引发的血案
本文转载自一次"内存泄漏"引发的血案 导语 2017年末,手Q春节红包项目期间,为保障活动期间服务正常稳定,我对性能不佳的Ark Server进行了改造和重写.重编发布一段时间后, ...
- Replication的犄角旮旯(六)-- 一个DDL引发的血案(上)(如何近似估算DDL操作进度)
<Replication的犄角旮旯>系列导读 Replication的犄角旮旯(一)--变更订阅端表名的应用场景 Replication的犄角旮旯(二)--寻找订阅端丢失的记录 Repli ...
- 一个无锁消息队列引发的血案(六)——RingQueue(中) 休眠的艺术 [续]
目录 (一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer (四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术 (六)RingQueue(中) 休眠的 ...
随机推荐
- RAG 工具和框架介绍: Haystack、 LangChain 和 LlamaIndex
Haystack. LangChain 和 LlamaIndex,以及这些工具是如何让我们轻松地构建 RAG 应用程序的? 我们将重点关注以下内容: Haystack LangChain LlamaI ...
- [FAQ] eggjs/egg 自定义 favicon.ico
从 egg 项目配置里找到这一段代码: https://github.com/eggjs/egg/blob/master/config/config.default.js#L205C21-L20 ...
- [FAQ] 设置 npm 镜像源
查看 npm 源: $ npm config get registry> http://registry.npmjs.org/ 修改 npm 源: $ npm config set regist ...
- SQL SERVER数据库存储过程加密
CREATE PROCEDURE [dbo].[kytj_Base_Worker] WITH ENCRYPTION AS SELECT u.worker_number, u.worker_name, ...
- shell 调试方法
shell 在 linux 系统中比较常见,简单的脚本可以看着确实没难度,但是当脚本功能复杂后,看起来就不那么流畅了,所以掌握一些调试方式还是很有必要的,这里我收集了一次常用的调试方式. shell调 ...
- localstory,sessionstory,vuex,cook
函数式组件 1.特点 没有this(没有实例) 没有响应式数据 它只是一个接受一些 prop 的函数. render MVVM分为Model.View.ViewModel三者. Model:代表数据模 ...
- webapp监听手机物理返回键,返回上一页面或者关闭app
网上抄的做笔记: 1.项目下建文件夹commonFunction->physicBackListener.js 2.这个js文件内复制代码: document.addEventListener( ...
- 4.10 + (double)(rand()%10)/100.0
黑色星期四 坏消息: 没有奥赛课,所以大概率调不出来 CF1479D 好消息: 5k 回来了,调题有望 中午起床直接来的机房,有学科自习就说 氟硫氢 不知道 结果被叫回去了 而且今天班里没水了,趁着大 ...
- ITIL4服务价值系统(SVS)与莫比乌斯环:无限服务优化的拓扑之旅
莫比乌斯环:单一而无限的象征 莫比乌斯环,这个拓扑学上的奇观,以其独特的一体两面特性,完美地映射了ITIL4服务价值系统的精髓.它象征着无限.统一和连续性,提示我们看待事物时应超越传统二元对立的视角, ...
- Sublime Text 3 初试牛刀
每次我在其他视频网站上看学习视频的时候,看着老师用的编辑器高大上档次,而我一般用Notepad,和Dreamweaver去编辑网页,需要每一行代码,打进去,效率低.最近看到sublime编辑器,在网上 ...