【Flink入门修炼】1-3 Flink WordCount 入门实现
本篇文章将带大家运行 Flink 最简单的程序 WordCount。先实践后理论,对其基本输入输出、编程代码有初步了解,后续篇章再对 Flink 的各种概念和架构进行介绍。
下面将从创建项目开始,介绍如何创建出一个 Flink 项目;然后从 DataStream 流处理和 FlinkSQL 执行两种方式来带大家学习 WordCount 程序的开发。
Flink 各版本之间变化较多,之前版本的函数在后续版本可能不再支持。跟随学习时,请尽量选择和笔者同版本的 Flink。本文使用的 Flink 版本是 1.13.2。
一、创建项目
在很多其他教程中,会看到如下来创建 Flink 程序的方式。虽然简单方便,但对初学者来说,不知道初始化项目的时候做了什么,如果报错了也不知道该如何排查。
mvn archetype:generate
-DarchetypeGroupId=org.apache.flink
-DarchetypeArtifactId=flink-quickstart-java
-DarchetypeVersion=1.13.2
通过指定 Maven 工程的三要素,即 GroupId、ArtifactId、Version 来创建一个新的工程。同时 Flink 给我提供了更为方便的创建 Flink 工程的方法:
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.13.2
因此,我们手动来创建一个 Maven 项目,看看到底如何创建出一个 Flink 项目。
1、通过 IDEA 创建一个 Maven 项目
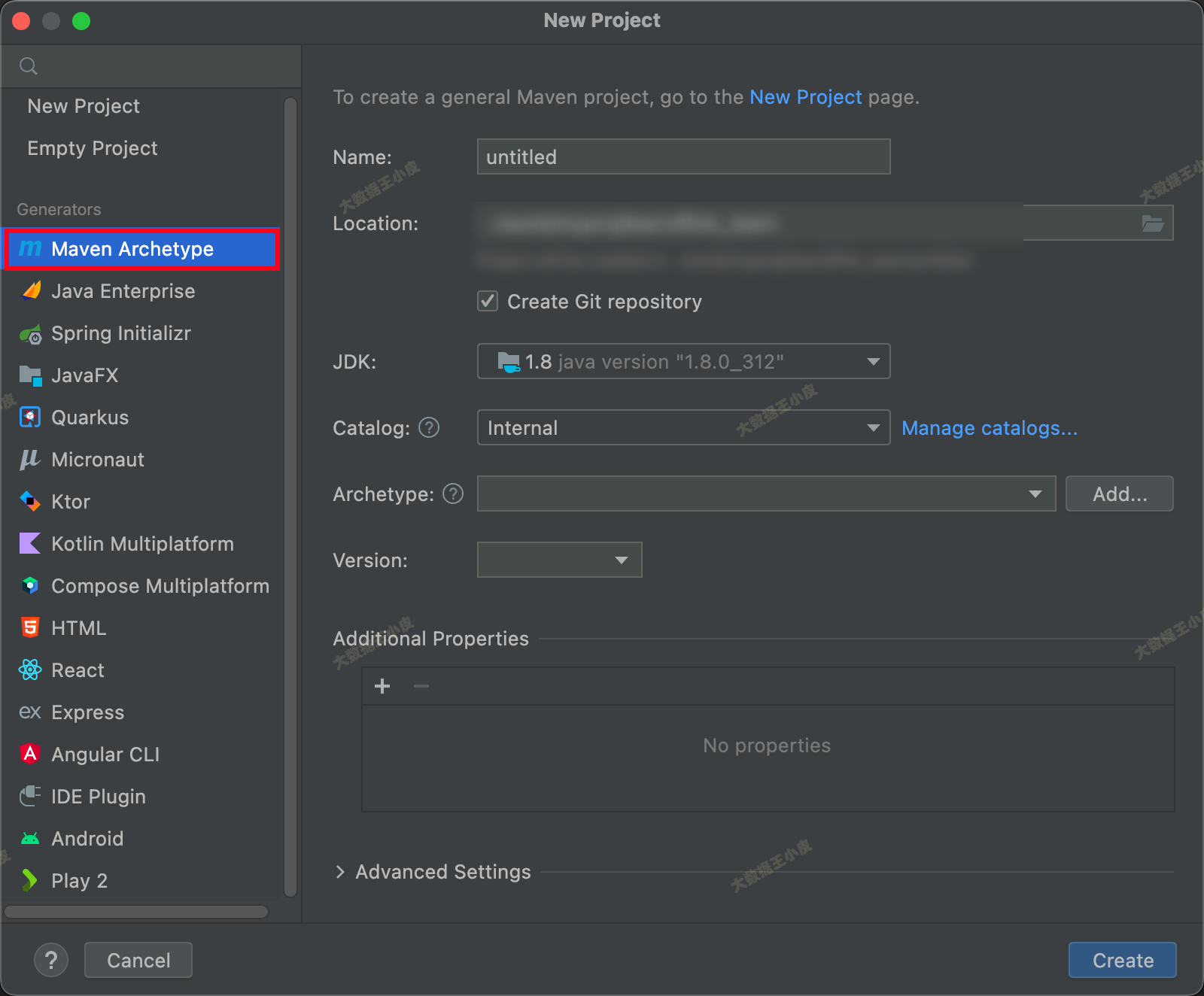
2、pom.xml 添加:
这里我们选择的是 Flink 1.13.2 版本(Flink 1.14 之后部分类和函数有变化,可自行探索)。
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.13.2</flink.version> <!-- 1.14 之后部分类和函数有变化,可自行探索 -->
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
二、DataStream WordCount
一)编写程序
基础项目环境已经搞好了,接下来我们模仿一个流式环境,监听本地的 Socket 端口,使用 Flink 统计流入的不同单词个数。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class SocketTextStreamWordCount {
public static void main(String[] args) throws Exception {
//参数检查
if (args.length != 2) {
// System.err.println("USAGE:\nSocketTextStreamWordCount <hostname> <port>");
// return;
args = new String[]{"127.0.0.1", "9000"};
}
String hostname = args[0];
Integer port = Integer.parseInt(args[1]);
// 创建 streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取数据
DataStreamSource<String> stream = env.socketTextStream(hostname, port);
// 计数
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = stream.flatMap(new LineSplitter())
.keyBy(0)
.sum(1);
sum.print();
env.execute("Java WordCount from SocketTextStream Example");
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) {
String[] tokens = s.toLowerCase().split("\\W+");
for (String token: tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}
二)测试
接下来我们进行程序测试。
我们在本地使用 netcat 命令启动一个端口:
nc -l 9000
然后启动程序,能看到控制台一些输出:
接下来,在 nc 中输入:
$ nc -l 9000
hello world
flink flink flink
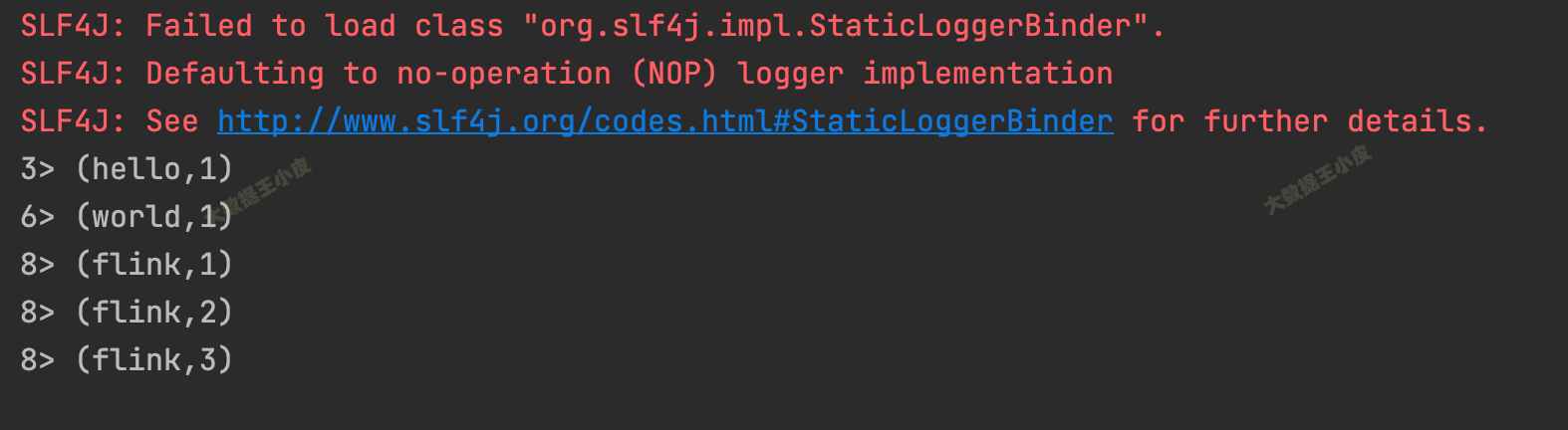
回到我们的程序,能看到统计的输出:
3> (hello,1)
6> (world,1)
8> (flink,1)
8> (flink,2)
8> (flink,3)
三)如果有报错
如果出现执行报错:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/api/java/io/TextInputFormat
at com.shuofxz.SocketTextStreamWordCount.main(SocketTextStreamWordCount.java:25)
Caused by: java.lang.ClassNotFoundException: org.apache.flink.api.java.io.TextInputFormat
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:419)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:352)
... 1 more
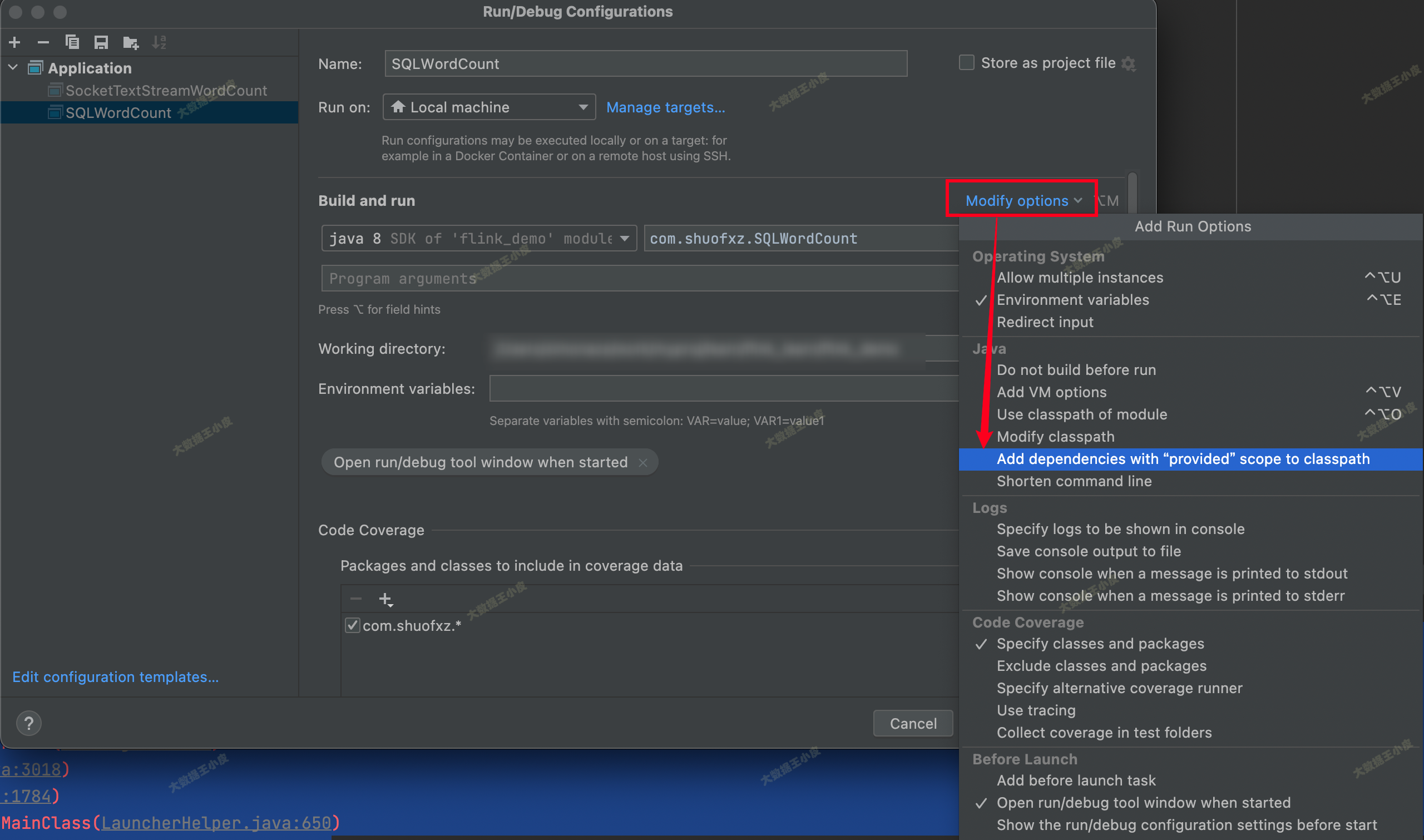
在 IDE 中把 「Add dependencies with "Provided" scope to classpath」勾选上:
三、Flink Table & SQL WordCount
一)介绍 FlinkSQL
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
上面单词统计的逻辑可以转化为下面的 SQL。
直接来看这个 SQL:
select word as word, sum(frequency) as frequency from WordCount group by word
WordCount是要进行单词统计的表,我们会先做一些处理,将输入的单词都存放到这个表中- 表我们定义为两列
(word, frequency),初始转化输入每个单词占一行,frequency 都是 1 - 然后,就可以按照 SQL 的逻辑来进行统计聚合了。
其中,WordCount 表数据如下:
| word | frequency |
|---|---|
| hello | 1 |
| world | 1 |
| flink | 1 |
| flink | 1 |
| flink | 1 |
那么接下来我们看,如何写一个 FlinkSQL 的程序。
二)环境和程序
首先,添加 FlinkSQL 需要的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
程序如下:
public class SQLWordCount {
public static void main(String[] args) throws Exception {
// 创建上下文环境
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
// 读取一行模拟数据作为输入
String words = "hello world flink flink flink";
String[] split = words.split("\\W+");
ArrayList<WC> list = new ArrayList<>();
for (String word : split) {
WC wc = new WC(word, 1);
list.add(wc);
}
DataSource<WC> input = fbEnv.fromCollection(list);
// DataSet 转 SQL,指定字段名
Table table = fbTableEnv.fromDataSet(input, "word,frequency");
table.printSchema();
// 注册为一个表
fbTableEnv.createTemporaryView("WordCount", table);
Table table1 = fbTableEnv.sqlQuery("select word as word, sum(frequency) as frequency from WordCount group by word");
DataSet<WC> ds1 = fbTableEnv.toDataSet(table1, WC.class);
ds1.printToErr();
}
public static class WC {
public String word;
public long frequency;
public WC() {}
public WC(String word, long frequency) {
this.word = word;
this.frequency = frequency;
}
@Override
public String toString() {
return word + ", " + frequency;
}
}
}
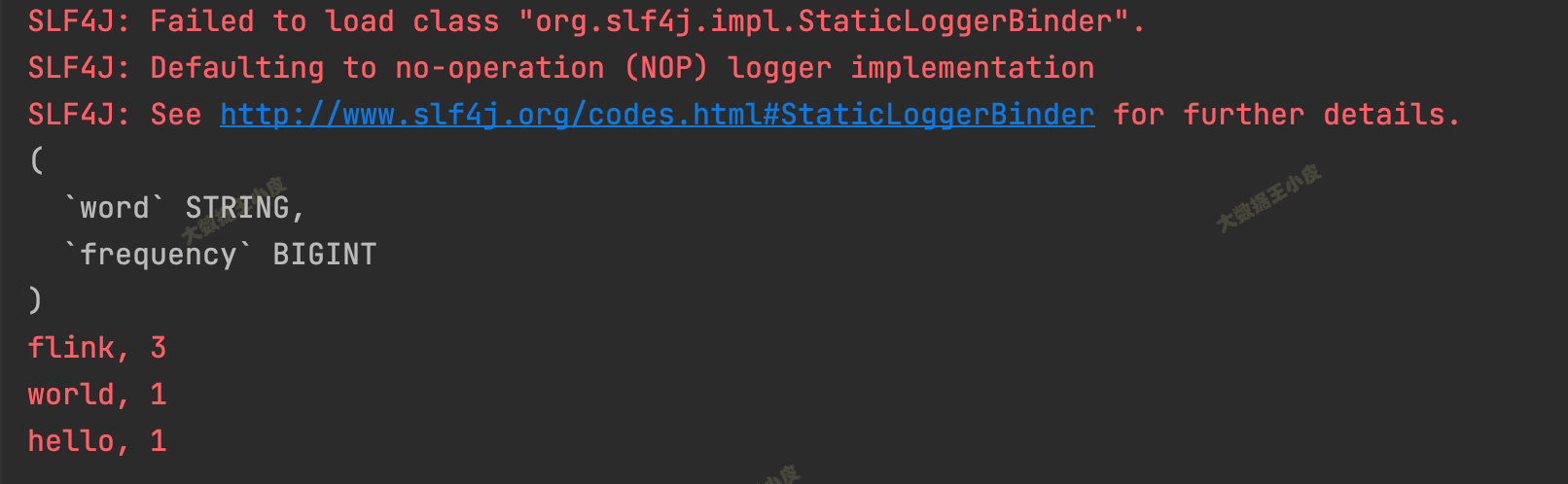
执行,结果输出:
(
`word` STRING,
`frequency` BIGINT
)
flink, 3
world, 1
hello, 1
四、小结
本篇手把手的带大家搭建起 Flink Maven 项目,然后使用 DataStream 和 FlinkSQL 两种方式来学习 WordCount 单词计数这一最简单最经典的 Flink 程序开发。跟着步骤一步步执行下来,大家应该对 Flink 程序基本执行流程有个初步的了解,为后续的学习打下了基础。
【Flink入门修炼】1-3 Flink WordCount 入门实现的更多相关文章
- 《从0到1学习Flink》—— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
准备工作 1.安装查看 Java 的版本号,推荐使用 Java 8. 安装 Flink 2.在 Mac OS X 上安装 Flink 是非常方便的.推荐通过 homebrew 来安装. brew in ...
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
- Docker基础修炼1--Docker简介及快速入门体验
本文作为Docker基础系列第一篇文章,将详细阐述和分析三个问题:Docker是什么?为什么要用Docker?如何快速掌握Docker技术? 本系列文章中Docker的用法演示是基于CentOS7进行 ...
- Flink本地安装和创建Flink应用
本篇文章首发于头条号Flink本地安装和创建Flink应用,欢迎关注我的头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_tech)获取更多干货,也欢迎关注 ...
- flink学习笔记-快速生成Flink项目
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink资料(1)-- Flink基础概念(Basic Concept)
Flink基础概念 本文描述Flink的基础概念,翻译自https://ci.apache.org/projects/flink/flink-docs-release-1.0/concepts/con ...
- Flink学习(二)Flink中的时间
摘自Apache Flink官网 最早的streaming 架构是storm的lambda架构 分为三个layer batch layer serving layer speed layer 一.在s ...
- kafka传数据到Flink存储到mysql之Flink使用SQL语句聚合数据流(设置时间窗口,EventTime)
网上没什么资料,就分享下:) 简单模式:kafka传数据到Flink存储到mysql 可以参考网站: 利用Flink stream从kafka中写数据到mysql maven依赖情况: <pro ...
- scala 入门Eclipse环境搭建及第一个入门经典程序HelloWorld
scala 入门Eclipse环境搭建及第一个入门经典程序HelloWorld 学习了: http://blog.csdn.net/wangmuming/article/details/3407911 ...
- 如何进行Flink项目构建,快速开发Flink应用程序?
项目模板 Flink应用项目可以使用Maven或SBT来构建项目,Flink针对这些构建工具提供了相应项目模板. Maven模板命令如下,我们只需要根据提示输入应用项目的groupId.artifac ...
随机推荐
- springboot2.0+dubbo-spring-boot-starter聚合项目打可执行的jar包
springboot2.0+dubbo聚合项目打可执行的jar包 springboot2.0+dubbo-spring-boot-starter项目服务方打包和以前老版本的dubbo打包方式不一样,不 ...
- java进阶(1)--final、常量
final是java的关键字,主要表示最终的 一.final修饰的类无法被继承
- node pressure and pod eviction
0. overview There are too many guides about node pressure and pod eviction, most of them are specifi ...
- 【Linux】技术收集
Linux进程间通信(六)---信号量通信之semget().semctl().semop()及其基础实验 https://blog.csdn.net/mybelief321/article/deta ...
- javaweb 项目!号 解决方案
1:右击项目工程名称2:Properties3: Jvav Build Path4: Libraries5: Add External JARS6: 找到"E:\apache-tom ...
- [转帖]美国出口管制法律制度及中国企业风险防范——EAR核心内容解读
http://bzy.scjg.jl.gov.cn/wto/zszc/myxgzs/202202/t20220221_636006.html 发布时间:2022-01-18 一.<美国出口管理条 ...
- [转帖]人人都应该知道的CPU缓存运行效率
https://zhuanlan.zhihu.com/p/628017496 提到CPU性能,大部分同学想到的都是CPU利用率,这个指标确实应该首先被关注.但是除了利用率之外,还有很容易被人忽视的指标 ...
- Redis Cluster in K3S
Redis Cluster in K3S 学习资料 https://www.cnblogs.com/cheyunhua/p/15619317.html https://blog.csdn.net/cq ...
- ESXi查看底层存储磁盘厂商型号的方式与方法
ESXi查看底层存储磁盘厂商型号的方式与方法 背景 公司一台过保的服务器出现了磁盘告警 Vendor不太靠谱. 过保的机器就不管了 不买他们的服务器也不说一下是啥硬盘. 想自己替换,需要先获取磁盘的型 ...
- C#开源免费的开发效率提升利器:DevToys开发人员的瑞士军刀!
前言 今天分享一款基于C#开源(MIT License开源协议).免费.离线.功能齐全的Windows开发者工具箱,号称开发人员的瑞士军刀,可以帮助开发者完成日常工作开发中常用功能:DevToys. ...