让容器跑得更快:CPU Burst 技术实践
简介:让人讨厌的 CPU 限流影响容器运行,有时人们不得不牺牲容器部署密度来避免 CPU 限流出现。我们设计的 CPU Burst 技术既能保证容器运行服务质量,又不降低容器部署密度。CPU Burst 特性已合入 Linux 5.14,Anolis OS 8.2、Alibaba Cloud Linux2、Alibaba Cloud Linux3 也都支持 CPU Burst 特性。
作者:常怀鑫、丁天琛
让人讨厌的 CPU 限流影响容器运行,有时人们不得不牺牲容器部署密度来避免 CPU 限流出现。我们设计的 CPU Burst 技术既能保证容器运行服务质量,又不降低容器部署密度。CPU Burst 特性已合入 Linux 5.14,Anolis OS 8.2、Alibaba Cloud Linux2、Alibaba Cloud Linux3 也都支持 CPU Burst 特性。
在 K8s 容器调度中,容器的 CPU 资源上限是由 CPU limits 参数指定。设置 CPU 资源上限可以限制个别容器消耗过多的 CPU 运行时间,并确保其他容器拿到足够的 CPU 资源。CPU limits 限制在 Linux 内核中是用 CPU Bandwidth Controller 实现的,它通过 CPU 限流限制 cgroup 的资源消耗。所以当一个容器中的进程使用了超过 CPU limits 的资源的时候,这些进程就会被 CPU 限流,他们使用的 CPU 时间就会受到限制,进程中一些关键的延迟指标就会变差。
面对这种情况,我们应该怎么办呢?一般情况下,我们会结合这个容器日常峰值的 CPU 利用率并乘以一个相对安全的系数来设置这个容器的 CPU limits ,这样我们既可以避免容器因为限流而导致的服务质量变差,同时也可以兼顾 CPU 资源的利用。举个简单的例子,我们有一个容器,他日常峰值的 CPU 使用率在 250% 左右,那么我们就把容器 CPU limits 设置到 400% 来保证容器服务质量,此时容器的 CPU 利用率是 62.5%(250%/400%)。
然而生活真的那么美好吗?显然不是!CPU 限流的出现比预期频繁了很多。怎么办?似乎看上去我们只能继续调大 CPU limits 来解决这个问题。很多时候,当容器的 CPU limits 被放大 5~10 倍的时候,这个容器的服务质量才得到了比较好的保障,相应的这时容器的总 CPU 利用率只有 10%~20%。所以为了应对可能的容器 CPU 使用高峰,容器的部署密度必须大大降低。
历史上人们在 CPU Bandwidth Controller 中修复了一些 BUG 导致的 CPU 限流问题,我们发现当前非预期限流是由于 100ms 级别 CPU 突发使用引起,并且提出 CPU Burst 技术允许一定的 CPU 突发使用,避免平均 CPU 利用率低于限制时的 CPU 限流。在云计算场景中,CPU Burst 技术的价值有:
- 不提高 CPU 配置的前提下改善 CPU 资源服务质量;
- 允许资源所有者不牺牲资源服务质量降低 CPU 资源配置,提升 CPU 资源利用率;
- 降低资源成本(TCO,Total Cost of Ownership)。
你看到的 CPU 利用率不是全部真相
秒级 CPU 利用率不能反映 Bandwidth Controller 工作的 100ms 级别 CPU 使用情况,是导致非预期 CPU 限流出现的原因。
Bandwidth Controller 适用于 CFS 任务,用 period 和 quota 管理 cgroup 的 CPU 时间消耗。若 cgroup 的 period 是 100ms quota 是 50ms,cgroup 的进程每 100ms 周期内最多使用 50ms CPU 时间。当 100ms 周期的 CPU 使用超过 50ms 时进程会被限流,cgroup 的 CPU 使用被限制到 50%。
CPU 利用率是一段时间内 CPU 使用的平均,以较粗的粒度统计 CPU 的使用需求,CPU 利用率趋向稳定;当观察的粒度变细,CPU 使用的突发特征更明显。以 1s 粒度和 100ms 粒度同时观测容器负载运行,当观测粒度是 1s 时 CPU 利用率的秒级平均在 250% 左右,而在 Bandwidth Controller 工作的 100ms 级别观测 CPU 利用率的峰值已经突破 400% 。
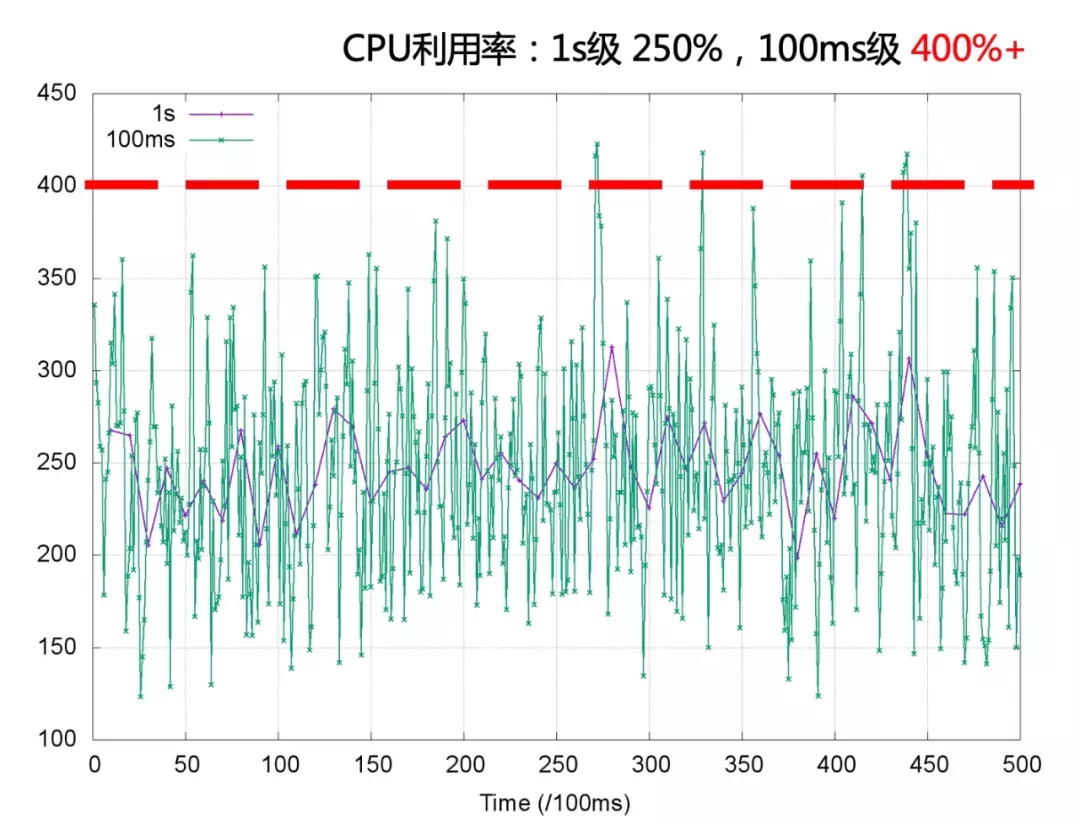
根据秒级观察到的 CPU 利用率 250% 设置容器 quota 和 period 分别为 400ms 和 100ms ,容器进程的细粒度突发被 Bandwidth Controller 限流,容器进程的 CPU 使用受到影响。
如何改善
我们用 CPU Burst 技术来满足这种细粒度 CPU 突发需求,在传统的 CPU Bandwidth Controller quota 和 period 基础上引入 burst 的概念。当容器的 CPU 使用低于 quota 时,可用于突发的 burst 资源累积下来;当容器的 CPU 使用超过 quota,允许使用累积的 burst 资源。最终达到的效果是将容器更长时间的平均 CPU 消耗限制在 quota 范围内,允许短时间内的 CPU 使用超过其 quota。
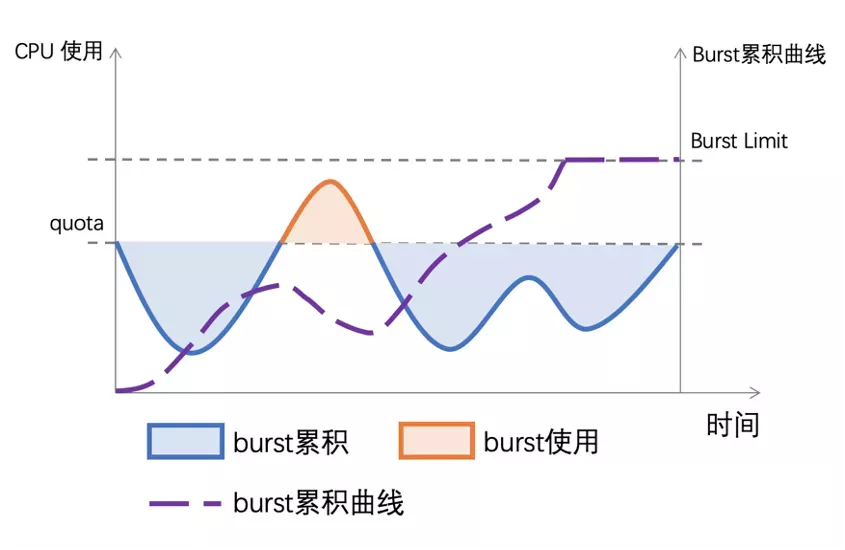
如果用 Bandwidth Controller 算法来管理休假,假期管理的周期(period)是一年,一年里假期的额度是 quota ,有了 CPU Burst 技术之后今年修不完的假期可以放到以后来休了。
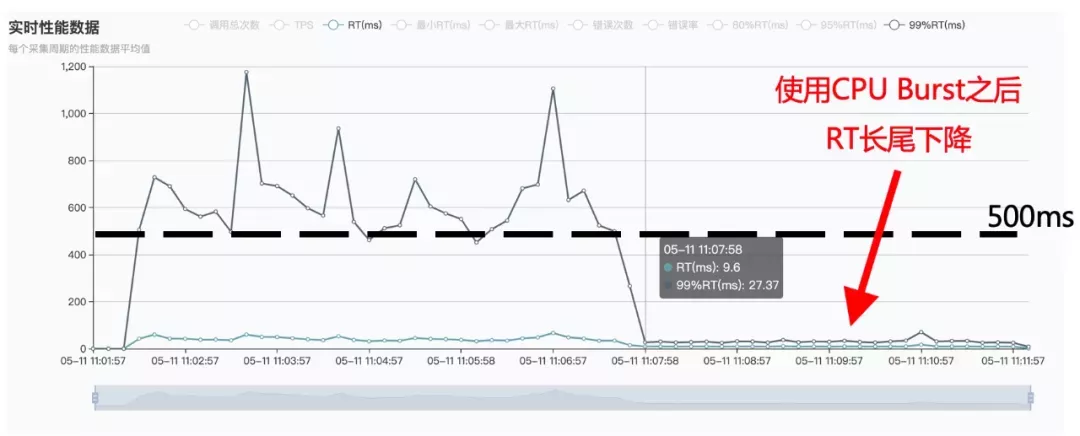
在容器场景中使用 CPU Burst 之后,测试容器的服务质量显著提升。观察到 RT 均值下降 68%(从 30+ms 下降到 9.6ms );99% RT 下降 94.5%(从 500+ms 下降到 27.37ms )。
CPU Bandwidth Controller 的保证
使用 CPU Bandwidth Controller 可以避免某些进程消耗过多 CPU 时间,并确保所有需要 CPU 的进程都拿到足够的 CPU 时间。之所以有这样好的稳定性保证,是因为当 Bandwidth Controller 设置满足下述情况时,
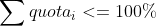

有如下的调度稳定性约束:
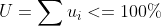
其中,

是第 i 个 cgroup 的 quota,是一个 period 内该 cgroup 的 CPU 需求。Bandwidth Controller 对每个周期分别做 CPU 时间统计,调度稳定性约束保证在一个 period 内提交的全部任务都能在该周期内处理完;对每个 CPU cgroup 而言,这意味着任何时候提交的任务都能在一个 period 内执行完,即任务实时性约束:
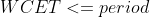
不管任务优先级如何,最坏情况下任务执行时间(WCET, Worst-Case Execution Time)不超过一个 period。
假如持续出现
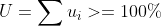
调度器稳定性被打破,在每个 period 都有任务积攒下来,新提交的作业执行时间不断增加。
使用 CPU Burst 的影响
出于改善服务质量的需要,我们使用 CPU Burst 允许突发的 CPU 使用之后,对调度器的稳定性产生什么影响?答案是当多个 cgroup 同时突发使用 CPU,调度器稳定性约束和任务实时性保证有可能被打破。这时候两个约束得到保证的概率是关键,如果两个约束得到保证的概率很高,对大多数周期来任务实时性都得到保证,可以放心大胆使用 CPU Burst;如果任务实时性得到保证的概率很低,这时候要改善服务质量不能直接使用 CPU Burst,应该先降低部署密度提高 CPU 资源配置。
于是下一个关心的问题是,怎么计算特定场景下两个约束被打破的概率。
评估影响大小
定量计算可以定义成经典的排队论问题,并且用蒙特卡洛模拟方法求解。定量计算的结果表明,判断当前场景是否可以使用 CPU Burst 的主要影响因素是平均 CPU 利用率和 cgroup 数目。CPU 利用率越低,或者 cgroup 数目越多,两个约束越不容易被打破可以放心使用 CPU Burst。反之如果 CPU 利用率很高或者 cgroup 数目较少,要消除 CPU 限流对进程执行的影响,应该降低部署提高配置再使用 CPU Burst。
问题定义是:一共有 m 个 cgroup,每个 cgroup 的 quota 限制为 1/m,每个 cgroup 在每个周期产生的计算需求(CPU 利用率)服从某个具体分布,这些分布是相互独立的。假设任务在每个周期的开始到达,如果该周期内的 CPU 需求超过 100%,当前周期任务 WCET 超过 1 个 period,超过的部分累积下来和下个周期新产生的 CPU 需求一起在下个需求处理。输入是 cgroup 的数目 m 和每个 CPU 需求满足的具体分布,输出是每个周期结束 WCET > period 的概率和 WCET 期望。
以输入的 CPU 需求为帕累托分布、m=10/20/30 的结果为例进行说明。选择帕累托分布进行说明的原因是它产生比较多的长尾 CPU 突发使用,容易产生较大影响。表格中数据项的格式为
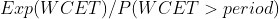
其中
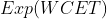
越接近 1 越好,
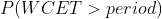
概率越低越好。
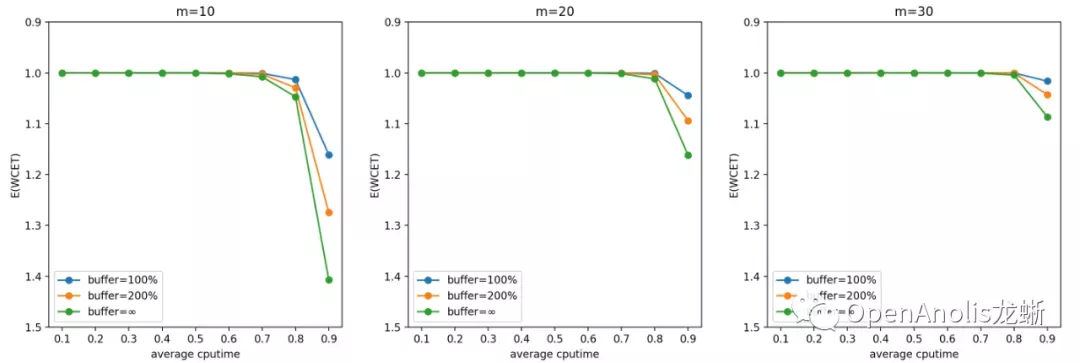
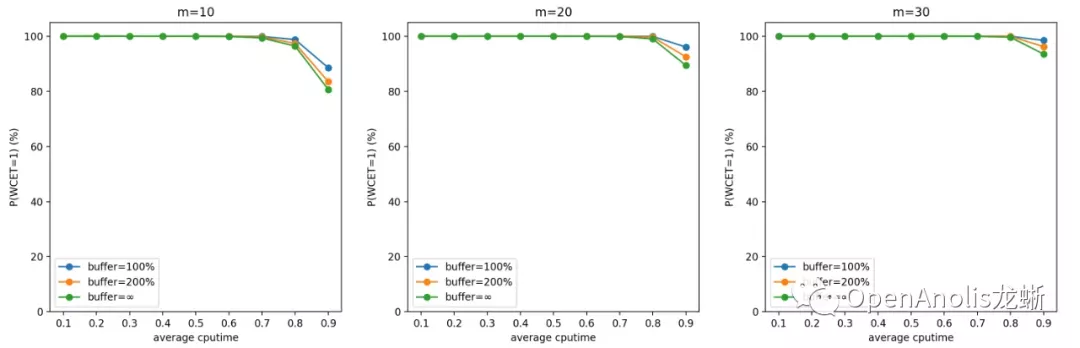
结果跟直觉是吻合的。一方面,CPU 需求(CPU 利用率)越高,CPU 突发越容易打破稳定性约束,造成任务 WCET 期望变长。另一方面,CPU 需求独立分布的 cgroup 数目越多,它们同时产生 CPU 突发需求的可能性越低,调度器稳定性约束越容易保持,WCET 的期望越接近 1 个 period。
场景和参数设定
我们设定整个系统存在 m 个 cgroup,每个 cgroup 公平瓜分总量为 100% 的 CPU 资源,即 quota=1/m。每个 cgoup 按相同规律(独立同分布)产生计算需求并交给 CPU 执行。
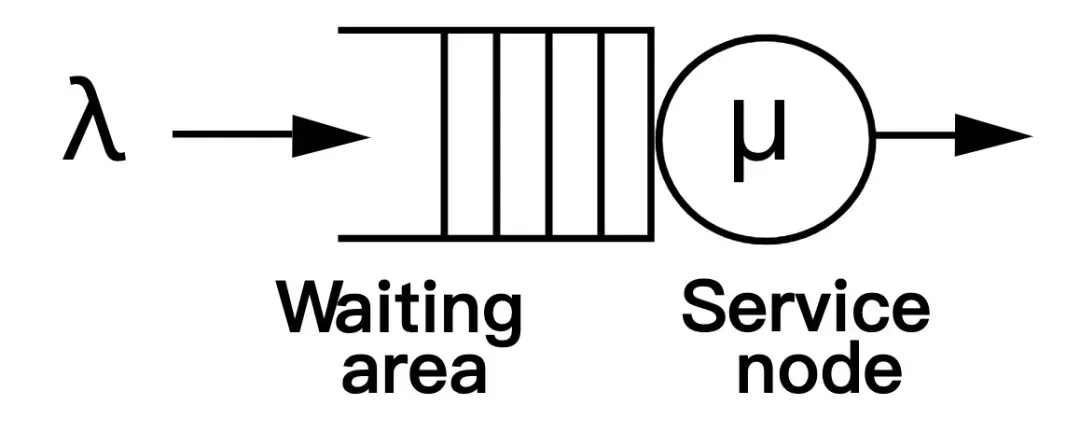
我们参考排队论的模型,将每个 cgroup 视为一位顾客,CPU 即为服务台,每位顾客的服务时间受到 quota 的限制。为了简化模型,我们离散化地定义所有顾客的到达时间间隔为常数,然后在该间隔内 CPU 最多能服务 100% 的计算需求,这个时间间隔即为一个周期。
然后我们需要定义每位顾客在一个周期内的服务时间。我们假定顾客产生的计算需求是独立同分布的,其平均值是自身 quota 的 u_avg 倍。顾客在每个周期得不到满足的计算需求会一直累积,它每个周期向服务台提交的服务时间取决于它自身的计算需求和系统允许的最大 CPU time(即其 quota 加上之前周期累积的 token)。
最后,CPU Burst 技术中有一项可调参数 buffer,表示允许累积的 token 上限。它决定了每个 cgroup 的瞬时突发能力,我们将其大小用 quota 的 b 倍表示。
我们对上述定义的参数作出了如下设置:
负指数分布是排队论模型中最常见、最多被使用的分布之一。其密度函数为
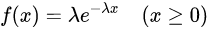
其中
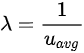
帕累托分布是计算机调度系统中比较常见的分布,且它能够模拟出较大的延迟长尾,从而体现 CPU Burst 的效果。其密度函数为:
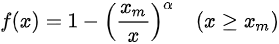
为了抑制尾部的概率分布使其不至于过于夸张,我们设置了:
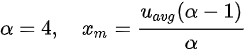
此时当 u_avg=30% 时可能产生的最大计算需求约为 500%。
数据展示
按上述参数设置进行蒙特卡洛模拟的结果如下所示。我们将第一张(WCET 期望)的图表 y 轴进行颠倒来更好地符合直觉。同样地,第二张图表(WCET 等于 1 的概率)表示调度的实时性得到保证的概率,以百分制表示。
负指数分布

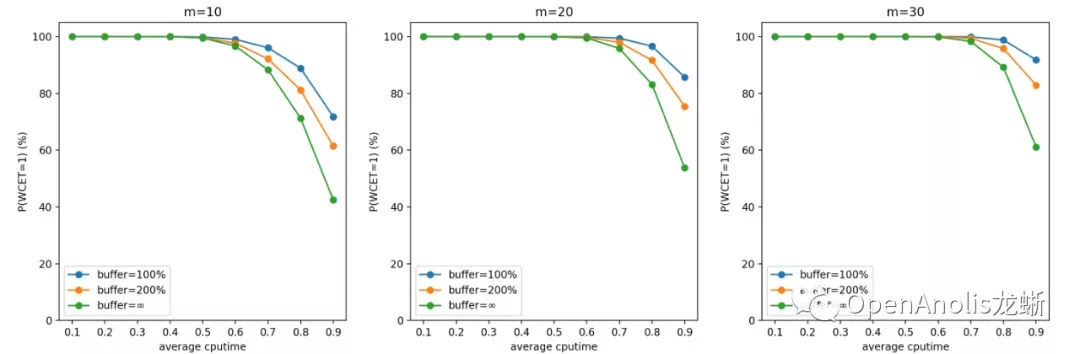
帕累托分布
结论
一般来说,u_avg(计算需求的负荷)越高,m(cgroup 数量)越少,WCET 越大。前者是显然的结论,后者是因为独立同分布情况下任务数量越多,整体产生需求越趋于平均,超出 quota 需求的任务和低于 quota 从而空出 cpu 时间的任务更容易互补。
提高 buffer 会使得 CPU Burst 发挥更好的效果,对单个任务的优化收益更明显;但同时也会增大 WCET,意味着增加对相邻任务的干扰。这也是符合直觉的结论。
在设置 buffer 大小时,我们建议根据具体业务场景的计算需求(包括分布和均值)和容器数量,以及自身需求来决定。如果希望增加整体系统的吞吐量,以及在平均负荷不高的情况下优化容器性能,可以增大 buffer;反之如果希望保证调度的稳定性和公平性,在整体负荷较高的情况下减少容器受到的影响,可以适当减小 buffer。
一般而言,在低于 70% 平均 CPU 利用率的场景中,CPU Burst 不会对相邻容器造成较大影响。
模拟工具与使用方法
说完了枯燥的数据和结论,接下来介绍可能有许多读者关心的问题:CPU Burst 会不会对我的实际业务场景造成影响?为了解决这个疑惑,我们将蒙特卡洛模拟方法所用工具稍加改造,从而能帮助大家在自己的实际场景中测试具体的影响~
工具可以在这里获取:cpuburst-simulator · 研发工作台 · OpenAnolis社区
详细的使用说明也附在 README 中了,下面让我们看一个具体的例子吧。
小 A 想在他的服务器上部署 10 台容器用于相同业务。为了获取准确的测量数据,他先启动了一台容器正常运行业务,绑定到名为 cg1 的 cgroup 中,不设限流以获取该业务的真实表现。
然后调用 sample.py 进行数据采集:(演示效果只采集了 1000 次,实际建议有条件的情况下采集次数越大越好)

这些数据被存储到了./data/cg1_data.npy 中。最后输出的提示说明该业务平均占用了约 6.5% 的 CPU,部署 10 台容器的情况下总的平均 CPU 利用率约为 65%。(PS:方差数据同样打印出来作为参考,也许方差越大,越能从 CPU Burst 中受益哦)
接下来,他利用 simu_from_data.py 计算配置 10 个 和 cg1 相同场景的 cgroup 时,将 buffer 设置为 200% 的影响:

根据模拟结果,开启 CPU Burst 功能对该业务场景下的容器几乎没有负面影响,小 A 可以放心使用啦。
想要进一步了解该工具的用法,或是出于对理论的兴趣去改变分布查看模拟结果,都可以访问上面的仓库链接找到答案~
关于作者
常怀鑫(一斋),阿里云内核组工程师,擅长 CPU 调度领域。
丁天琛(鹰羽),2021 年加入阿里云内核组,目前在调度领域等方面学习研究。
原文链接
本文为阿里云原创内容,未经允许不得转载。
让容器跑得更快:CPU Burst 技术实践的更多相关文章
- 面试官:如何写出让 CPU 跑得更快的代码?
前言 代码都是由 CPU 跑起来的,我们代码写的好与坏就决定了 CPU 的执行效率,特别是在编写计算密集型的程序,更要注重 CPU 的执行效率,否则将会大大影响系统性能. CPU 内部嵌入了 CPU ...
- 让DB2跑得更快——DB2内部解析与性能优化
让DB2跑得更快——DB2内部解析与性能优化 (DB2数据库领域的精彩强音,DB2技巧精髓的热心分享,资深数据库专家牛新庄.干毅民.成孜论.唐志刚联袂推荐!) 洪烨著 2013年10月出版 定价:7 ...
- UOJ 【UR #5】怎样跑得更快
[UOJ#62]怎样跑得更快 题面 这个题让人有高斯消元的冲动,但肯定是不行的. 这个题算是莫比乌斯反演的一个非常巧妙的应用(不看题解不会做). 套路1: 因为\(b(i)\)能表达成一系列\(x(i ...
- 【UOJ#62】【UR #5】怎样跑得更快(莫比乌斯反演)
[UOJ#62][UR #5]怎样跑得更快(莫比乌斯反演) 题面 UOJ 题解 众所周知,\(lcm(i,j)=\frac{ij}{gcd(i,j)}\),于是原式就变成了: \[\sum_{j=1} ...
- 「UR#5」怎样跑得更快
「UR#5」怎样跑得更快 膜这个您就会了 下面是复读机mangoyang 我们要求 \[ \sum_{j=1}^n \gcd(i,j)^{c-d} j^d x_j=\frac{b_i}{i^d} \] ...
- 安装好Windows 8后必做的几件事情,让你的Win8跑的更快更流畅。
1.关闭家庭组,因为这功能会导致硬盘和CPU处于高负荷状态. 关闭方法:Win+C-设置-更改电脑设置-家庭组-离开 如果用不到家庭组可以直接把家庭组服务也给关闭了:控制面板-管理工具-服务-Home ...
- [翻译] 5点建议,让iOS程序跑得更快
[文章原地址]http://mobile.tutsplus.com/tutorials/iphone/ios-quick-tip-5-tips-to-increase-app-performanc ...
- 让你的 Node.js 应用跑得更快的 10 个技巧(转)
Node.js 受益于它的事件驱动和异步的特征,已经很快了.但是,在现代网络中只是快是不行的.如果你打算用 Node.js 开发你的下一个Web 应用的话,那么你就应该无所不用其极,让你的应用更快,异 ...
- 让你的 Node.js 应用跑得更快的 10 个技巧
Node.js 受益于它的事件驱动和异步的特征,已经很快了.但是,在现代网络中只是快是不行的.如果你打算用 Node.js 开发你的下一个Web 应用的话,那么你就应该无所不用其极,让你的应用更快,异 ...
- 让JAVA代码跑得更快
本文简单介绍一下在写代码过程中用到的一些让JAVA代码更高效的技巧. 1. 将一些系统资源放在池中(如数据库连接, 线程等) 在standalone的应用中, 数据库连接池可以使用一些开源的连接池 ...
随机推荐
- C++ allocator类
new在申请内存时,他将内存分配和对象的构造放在了一起,delete也将对象的析构和内存的释放结合在一起.但allocator类允许将内存分配和对象构造分开. 分配内存 allocator<st ...
- 浅析三维模型3DTile格式轻量化处理常见问题与处理措施
浅析三维模型3DTile格式轻量化处理常见问题与处理措施 三维模型3DTile格式的轻量化处理是大规模三维地理空间数据可视化的关键环节,但在实际操作过程中,往往会遇到一些问题.下面我们来看一下这些常见 ...
- 记录--Loading 用户体验 - 加载时避免闪烁
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 在切换详情页中有这么一个场景,点击上一条,会显示上一条的详情页,同理,点击下一条,会显示下一条的详情页. 伪代码如下所示: 我们定义了一个 ...
- gRPC入门学习之旅(三)
gRPC入门学习之旅(一) gRPC入门学习之旅(二) 2.3.创建自定义服务 除上面的模板中自带的一个gRPC服务之后,我们再创建一个自己的服务,我将创建一个用户信息gRPC服务,主要功能有三个,登 ...
- LOTO示波器选型指南
LOTO示波器选型指南 LOTO示波器属于虚拟示波器,产品主要基于USB接口的,所以使用LOTO示波器产品需要配备一台Windows电脑或者Android(安卓)智能手机/平板. 针对一些特殊应用的工 ...
- STAR法则是什么(如何把一件事表达清楚)
STAR法则,即为Situation Task Action Result的缩写,具体含义是: Situation: 事情是在什么情况下发生 Task: 你是如何明确你的任务的 Action: 针对这 ...
- cloudflare认识2(picgo结合使用)
参考:https://zhuanlan.zhihu.com/p/658058503 https://blog.csdn.net/CCCChris001122/article/details/13585 ...
- #带权并查集#HDU 3038 How Many Answers Are Wrong
题目 有未知的\(n\)个数,有\(m\)组询问,形如区间和等于给定值, 问有多少条错误的询问,一旦错误忽略此条询问 \(n\leq 2*10^5,m\leq 4*10^4\) 分析 用带权并查集,记 ...
- #割点,Tarjan#洛谷 5058 [ZJOI2004]嗅探器
题目 询问能编号最小的割点删掉后使\(a\)和\(b\)无法连通 分析 考虑将\(a\)当作根,那么割点的dfn小于等于\(b\)的dfn就可以了, 怎么会呢,如果有一个环呢,所以得要让割点的子节点小 ...
- 直播预告丨OpenHarmony标准系统多媒体子系统之视频解读
5月19日(周四)晚上19点,OpenHarmony开源开发者成长计划知识赋能第五期"掌握OpenHarmony多媒体的框架原理"的第五节直播课,即将开播! 深开鸿资深技术专家胡浩 ...