ElasticSearch 7.7 + Kibana的部署
ElasticSearch目前最新版是7.7.0,其中部署的细节和之前的6.x有很多的不同,所以这里单独拉出来写一下,希望对用7.x的童鞋有一些帮助,然后部署完ES后配套的kibana也是7.7.0,这个就简单了放到最后说,下面先进入ES 7.7.0的部署.
首先是下载es的安装包,官网下载即可,我这里的包是:elasticsearch-7.7.0-linux-x86_64.tar.gz,准备安装位置:/opt/elasticsearch,其实每个节点操作都是一样的,我这里不再详细叙述每个机器的细节,而只是写通用的配置,第一步就是解压包到指定的位置:
tar -xvzf elasticsearch-7.7.0-linux-x86_64.tar.gz -C /opt
cd /opt
ln -s elasticsearch-7.7.0 elasticsearch
cd elasticsearch
上面做个软链接就是为了管理多个版本方便,老的版本不用删除,每次进目录直接cd到/opt/elasticsearch就可以了,这个根据自己的习惯来就可以
进入目录后首先还是修改ES的主配置文件:config/elasticsearch.yml,依次来看下面的配置项:
cluster.name这个和之前一样配置集群名称,我这里配置为:cluster.name: es-cluster
node.name 配置节点的名称,一般和主机名一样,或者自己定义一个集群中唯一的标识,我这和主机名不同,第一个节点配置为:node.name: cloud-1,后面的节点以此类推就是cloud-2,cloud-3等等
path.data 索引和数据存储目录,支持配置多个,一般情况下是1个,我这里配置为:path.data: /data/elasticsearch
path.logs 日志存储目录,我这里默认注释,让日志打在/opt/elasticsearch/logs下面,默认解压出来就有这个logs目录
bootstrap.memory_lock 是否锁定内存,默认是注释的,这里建议打开,让es锁定jvm heap不被抢占,我这里配置是:bootstrap.memory_lock: true,但是这里还要开启另外的允许锁定内存的内核参数,这个待会再说明
network.host 配置es绑定主机的ip地址,可以设置为当前实际的ip,如果有多个网卡都想绑定的话,可以设置为:0.0.0.0,这样每个机器都一样即可,network.host: 0.0.0.0
http.port 配置http的端口号,默认9200,如果不修改可以不打开
transport.port 配置tcp的端口号,默认是9300,这个配置项不存在,如果修改需要自己添加,这个在es 6.x中配置项为:transport.tcp.port注意这个变化
discovery.seed_hosts 这个配置集群中的主机列表,以便能够在es启动的时候进行通信,并且为主机发现提供种子,这个通信使用的端口为tcp端口也就是transport.port配置的端口,默认的话可以不加端口,可以配置多个ip地址或者主机名都可以,如果有多个网卡这里要配置带宽高的,以便在集群中实现更快速的通信,官网给出的配置示例如下:
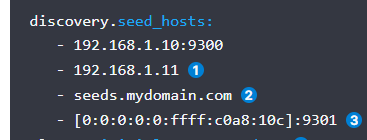
这个参数在6.x中的配置为:discovery.zen.ping.unicast.hosts,未来会被废弃,要使用这个新的名称,但是含义是一样的
cluster.initial_master_nodes 这个配置启动全新的集群时,那些节点可以作为master节点进行选票,其实默认不配置es也可以自动选举,但是这样是不安全的,所以需要配置一部分可以作为master节点的机器,之前的node.master其实可以不用配置了,另外防止脑裂的节点个数配置也去掉了,要注意:这里配置的不是主机名和ip,而是节点名称,是前面node.name中配置的名称,务必注意.
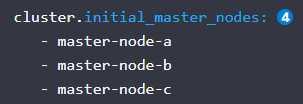
简单地配置就是以上这些,具体还有很多配置需要根据需要参考文档,下面将刚才的配置整理如下:
cluster.name: es-cluster
node.name: cloud-1
path.data: /data/elasticsearch
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["cloud1", "cloud2", "cloud3", "cloud4", "cloud5", "cloud6"]
cluster.initial_master_nodes: ["cloud-1", "cloud-2", "cloud-3"]
然后保存并退出,其实每个机器不同的地方只有node.name需要修改,如果network.host配置0.0.0.0则每个机器都不用改
然后配置jvm heap大小,配置文件:config/jvm.options
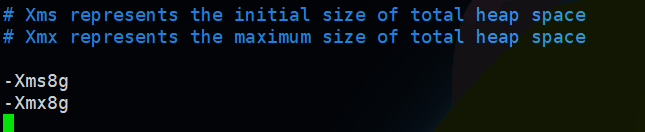
注意这里不要超过jvm长指针临界空间的大小,最大不超过32G,但是实际上根据不同机器有所变化,正常最大配置26G是安全的,在启动的时候日志中会有输出:

只要上面显示true则表示启用了压缩指针,对于实际的机器可以反复的修改调试找到一个合理的临界值.
修改完jvm配置后es就算基本配置完毕了,接下来就是要把整个安装目录发送到各个其他的节点并修改对应的node.name配置,
然后所有机器都要按照下面的操作配置内核参数:
1. 最大文件数
es要求文件数最小为65536,查看当前文件数命令为: ulimit -n ,调大文件数可以修改配置文件:/etc/security/limits.conf,添加如下配置:
* soft nofile 666666
* hard nofile 999999
保存配置后,重新登录shell即可生效,可以再次通过上面的命令确认一下
2. 内核参数max_map_count
es要求max_map_count虚拟内存区域数量至少为262144,而默认操作系统的值都为:65536,因此也需要设置一下否则会报错,临时设置命令如下:
sysctl vm.max_map_count=2560000
这样设置重启机器参数值会还原所以还需要编辑/etc/sysctl.conf添加配置 vm.max_map_count=2560000 并且保存即可永久生效
3. 允许锁定内存
刚才配置文件设置了bootstrap.memory_lock为true,但是默认操作系统不允许用户程序锁定内存,因此还需要配置解除限制,配置文件同样是/etc/security/limits.conf,需要在其中添加:
elastic soft memlock unlimited
elastic hard memlock unlimited
第一列elastic是es的用户,这个待会会创建,要保证和这里的一致,unlimited表示不限制锁定内存的大小,保存配置待会切换到elastic用户即可自动生效
4. 配置内存交换倾向
如果没有交换分区则可以忽略这个配置,如果有交换分区的话并不建议完全禁用,因为在系统内存占用非常大的时候可以通过临时交换到磁盘而避免系统崩溃,但是可以通过调整交换倾向让系统尽可能的少使用交换分区,这个参数通过vm.swappiness进行配置在redhat/centos 7.x中这个值默认为60,比较大建议设置为1~10,临时修改同样使用: sysctl vm.swappiness=1 ,永久修改同样是改配置文件,这个参数在redhat/centos 8.x默认会根据机器配置调整,有可能已经就是10了,所以只需要看一下,有可能不用修改.
注意上面4个参数在每个节点都要配置,配置完参数下面需要在每个节点创建数据目录和用户并授权:
# 创建数据目录
mkdir /data/elasticsearch
# 创建用户
useradd elastic
# 设置密码 根据提示输入两次
passwd elastic
# 进入es安装目录修改权限
chown -R elastic:elastic jdk config logs /data/elasticsearch
值得注意的是7.7版本的es安装包中已经有jdk环境了用的是AdoptOpenJDK,版本为最新的14,也就是说机器无需安装jdk环境就可以使用es,上面四个目录是必须要授权的,jdk目录如果不授权启动es的时候会提示无法执行文件也就是没有权限,为了方便也可以直接给整个目录加上权限.
最后就是在每个节点启动es了,
su - elastic
cd /opt/elasticsearch
bin/elasticsearch -d
启动之后jps确定进程Elasticsearch正常存在,所有节点都启动后通过 curl 'localhost:9200/_cat/nodes?v' 确认当前的节点列表是否正常
现在es集群就部署完毕了,接下来可以部署一下es常用的管理界面kibana,这个基本部署特别简单,首先还是下载最新的7.7.0安装包然后解压:
tar -xvzf kibana-7.7.0-linux-x86_64.tar.gz
mv kibana-7.7.0-linux-x86_64 /opt/kibana-7.7.0
cd /opt/kibana-7.7.0
然后编辑配置文件,这里简单介绍一下基本的配置:
server.port kibana服务的端口号,默认是5601
server.host kibana绑定的ip,这里可以写实际的ip也可以写0.0.0.0绑定所有的网卡
server.name kibana的名称,这个用于界面显示,自定义即可
elasticsearch.hosts 需要连接的es集群主机列表,这个最好填写完整的集群节点,每个节点内容是:http://host:port
kibana.index kibana进行相关的界面显示需要将一些数据存放到es中,这个为es中创建索引名的前缀,默认为:.kibana
kibana.defaultAppId 默认的应用程序,默认是:home
基本的配置就是上面这些,另外还有更多详细的参数配置,比如ES集群连接的超时参数等等,这些详细的配置需要参考文档调整,目前只是一个简单地配置和使用,上面配置整理如下:
server.port: 5601
server.host: "0.0.0.0"
server.name: "cloud1"
elasticsearch.hosts: ["http://cloud1:9200", "http://cloud2:9200","http://cloud3:9200", "http://cloud4:9200", "http://cloud5:9200", "http://cloud6:9200"]
kibana.index: ".kibana"
kibana.defaultAppId: "home"
配置保存之后就可以启动kibana服务了,需要注意kibana也需要用特定的用户启动,如果用root用户直接启动会给出提示,可以添加--allow-root强制启动,启动命令为: bin/kibana --allow-root ,启动之后可能会有几个警告,可以先不用关心,等启动完毕可以通过浏览器输入http://ip:5601进入kibana的界面,具体界面的使用这里就不再详细的叙述了
上面就是ElasticSearch+kibana组合的简单部署,如果觉得kibana太重量也可以尝试一下cerebro这个轻量的es管理工具,github链接为:https://github.com/lmenezes/cerebro,另外有关于ES的其他问题欢迎一起交流.
ElasticSearch 7.7 + Kibana的部署的更多相关文章
- ElasticSearch+Logstash+Filebeat+Kibana集群日志管理分析平台搭建
一.ELK搜索引擎原理介绍 在使用搜索引擎是你可能会觉得很简单方便,只需要在搜索栏输入想要的关键字就能显示出想要的结果.但在这简单的操作背后是搜索引擎复杂的逻辑和许多组件协同工作的结果. 搜索引擎的组 ...
- elasticsearch+logstash+redis+kibana 实时分析nginx日志
1. 部署环境 2. 架构拓扑 3. nginx安装 安装在192.168.176.128服务器上 这里安装就简单粗暴了直接yum安装nginx [root@manager ~]# yum -y in ...
- Elasticsearch学习之ElasticSearch 5.0.0 安装部署常见错误或问题
ElasticSearch 5.0.0 安装部署常见错误或问题 问题一: [--06T16::,][WARN ][o.e.b.JNANatives ] unable to install syscal ...
- (转)How to Use Elasticsearch, Logstash, and Kibana to Manage MySQL Logs
A comprehensive log management and analysis strategy is vital, enabling organizations to understand ...
- ELK:ElasticSearch中有数据,Kibana查询不到数据
ElasticSearch中有数据,Kibana查询不到数据 多数原因就是Linux的时区问题, 在linux输入date查看当前时间是否根本地相对应,不对应那么你就来对了, 解决方案一. 这个选择的 ...
- 关于Elasticsearch版本升级,Kibana报index迁移与需要x-pack插件问题
关于Elasticsearch版本升级,Kibana报index迁移与需要x-pack插件问题 这个问题是由于elasticsearch旧版残留文件导致,使用下述指令删除即可 查看所有elastics ...
- 利用ansible-playbook一键部署ELK(ElasticSearch,logstash and kibana)
一.部署前环境介绍: es集群5台(es01,es02,es03,es04,es05),logstash服务器1台(logstash2),kibana服务器1台(kibana2),模拟apache服务 ...
- ElasticSearch+Kibana安装部署
在安装ElasticSearch时遇到了很多坑,所以在这里做个笔记记录一下. 首先我考虑的是使用docker进行部署,结果发现虚拟机直接内存溢出,我也是无解了,也就是说使用docker部署还得注意容器 ...
- 云服务器 Centos7 部署 Elasticsearch 8.0 + Kibana 8.0 指南
文章转载自:https://mp.weixin.qq.com/s/iPfh9Mkwxf5lieiqt6ltxQ 服务器是命令行模式登录,没法以浏览器方式访问.而官方推荐的快捷部署方式,在kibana ...
- Elasticsearch 核心插件Kibana 本地文件包含漏洞分析(CVE-2018-17246)
不久前Elasticsearch发布了最新安全公告, Elasticsearch Kibana 6.4.3之前版本和5.6.13之前版本中的Console插件存在严重的本地文件包含漏洞可导致拒绝服务攻 ...
随机推荐
- Prometheus组件构成及介绍
Prometheus是一个开源的监控和告警工具包,其常用的组件主要包括以下几个部分: Prometheus Server 功能:Prometheus Server是Prometheus的核心组件,负责 ...
- 使用gitee
git全局设置 git config --global user.name "张xx" git config --global user.email "xxx@qq.co ...
- 如何在UE4中播放本地视频文件?
在UE4中有一套媒体框架方法,它根据视频源的不同,对应的播放方式也不一样,支持的视频源有本地视频文件.影像序列.视频流.实时视频截图.播放形式可选择在场景内的静态网格上播放或者以UI的形式播放.本文主 ...
- ViewStub你真的了解吗
目录介绍 01.什么是ViewStub 02.ViewStub构造方法 03.inflate()方法解析 04.WeakReference使用 05.ViewStub为何无大小 06.ViewStub ...
- 记录--这样封装列表 hooks,一天可以开发 20 个页面
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 这样封装列表 hooks,一天可以开发 20 个页面 前言 在做移动端的需求时,我们经常会开发一些列表页,这些列表页大多数有着相似的功能: ...
- 聊聊ShareGPT格式的微调数据集
转载请注明住处:https://www.cnblogs.com/zhiyong-ITNote 概述 ShareGPT格式的数据集中,一般是如下格式: [ { "conversations&q ...
- 学习笔记-安装kafka集群
官网地址:https://kafka.apache.org/ 1.下载解压 #下载 wget https://mirror.bit.edu.cn/apache/kafka/2.6.0/kafka_2. ...
- .net 开源混淆器 ConfuserEx
官网:http://yck1509.github.io/ConfuserEx/ 下载地址:https://github.com/yck1509/ConfuserEx/releases 使用参考:htt ...
- KingbaseES 等待事件之 - Client ClientWrite
等待事件含义 Client:ClientWrite等待事件指数据库等待向客户端写入数据. 在正式业务系统中,客户端必然和数据库集群之间有数据交互,这里指的是数据接收,发送.数据库集群在向客户端发送更多 ...
- sql分页遍历出现重复数据原因与解决方案
1. 问题描述 有同时反馈,直接通过如下的sql进行分页查询,分页会出现重复数据,于是乎我专门查了相关了资料,整理了一下. -- 根据sort字段对dbname进行排序,每五百条数据一页 SELECT ...