多智能体强化学习算法【一】【MAPPO、MADDPG、QMIX】
相关文章:
多智能体强化学习算法【一】【MAPPO、MADDPG、QMIX】
多智能体强化学习算法【二】【MADDPG、QMIX、MAPPO】
多智能体强化学习算法【三】【QMIX、MADDPG、MAPPO】
近些年,多智能体强化学习(Multi-Agent Reinforcement Learning,MARL)取得了突破性进展,例如 DeepMind 开发的 AlphaStar 在星际争霸 II 中打败了职业星际玩家,超过了 99.8% 的人类玩家;OpenAI Five 在 DOTA2 中多次击败世界冠军队伍,是首个在电子竞技比赛中击败冠军的人工智能系统;以及在仿真物理环境 hide-and-seek 中训练出像人一样可以使用工具的智能体。我们提到的这些智能体大多是采用 on-policy 算法(例如 IMPALA[8])训练得到的,这就意味着需要很高的并行度和庞大的算力支持,例如 OpenAI Five 消耗了 12.8 万块 CPU 和 256 块 P100 GPU 来收集数据样本和训练网络
然而,大多数的学术机构很难配备这个量级的计算资源。因此,MARL 领域几乎已经达成共识:与 on-policy 算法(例如 PPO[3])相比,在计算资源有限的情况下,off-policy 算法(例如 MADDPG[5],QMix[6])因其更高的采样效率更适合用来训练智能体,并且也演化出一系列解决某些具体问题(domain-specific)的 SOTA 算法(例如 SAD[9],RODE[7])。
但是,来自清华大学与 UC 伯克利的研究者在一篇论文中针对这一传统认知提出了不同的观点:MARL 算法需要综合考虑数据样本效率(sample efficiency)和算法运行效率(wall-clock runtime efficiency)。在有限计算资源的条件下,与 off-policy 算法相比,on-policy 算法 --MAPPO(Multi-Agent PPO)具有显著高的算法运行效率和与之相当(甚至更高)的数据样本效率。有趣的是,研究者发现只需要对 MAPPO 进行极小的超参搜索,在不进行任何算法或者网络架构变动的情况下就可以取得与 SOTA 算法相当的性能。更进一步地,还贴心地给出了 5 条可以提升 MAPPO 性能的重要建议,并且开源了一套优化后的 MARL 算法源码
(代码地址:https://github.com/marlbenchmark/on-policy)。
所以,如果你的 MARL 算法一直不 work,不妨参考一下这项研究,有可能是你没有用对算法;如果你专注于研究 MARL 算法,不妨尝试将 MAPPO 作为 baseline,说不定可以提高任务基准;如果你处于 MARL 研究入门阶段,这套源码值得拥有,据说开发完备,简单易上手。这篇论文由清华大学的汪玉、吴翼等人与 UC 伯克利的研究者合作完成。研究者后续会持续开源更多优化后的算法及任务(仓库指路:https://github.com/marlbenchmark)
1.MAPPO

论文链接:https://arxiv.org/abs/2103.01955
PPO(Proximal Policy Optimization)[4]是一个目前非常流行的单智能体强化学习算法,也是 OpenAI 在进行实验时首选的算法,可见其适用性之广。PPO 采用的是经典的 actor-critic 架构。其中,actor 网络,也称之为 policy 网络,接收局部观测(obs)并输出动作(action);critic 网络,也称之为 value 网络,接收状态(state)输出动作价值(value),用于评估 actor 网络输出动作的好坏。可以直观理解为评委(critic)在给演员(actor)的表演(action)打分(value)。MAPPO(Multi-agent PPO)是 PPO 算法应用于多智能体任务的变种,同样采用 actor-critic 架构,不同之处在于此时 critic 学习的是一个中心价值函数(centralized value function),简而言之,此时 critic 能够观测到全局信息(global state),包括其他 agent 的信息和环境的信息。
1.1 实验环境
接下来介绍一下论文中的实验环境。论文选择了 3 个具有代表性的协作 Multi-agent 任务,之所以选择协作任务的一个重要原因是合作任务具有明确的评价指标,便于对不同的算法进行比较。
1.1.1 Multi-agent Particle World(MPE)
第一个环境是 OpenAI 开源的 Multi-agent Particle World(MPE)任务(源代码指路:https://github.com/openai/multiagent-particle-envs)[1],轻量级的环境和抽象多样的任务设定使之成为快速验证 MARL 算法的首选测试平台。在 MPE 中有 3 个协作任务,分别是 Spread,Comm 和 Reference,如图 1 所示。

图 1:MPE 环境中的 3 个子任务:Spread,Comm 和 Reference
1.1.2 StarCraftII(星际争霸 II)任务
第二个环境是 MARL 领域著名的 StarCraftII(星际争霸 II)任务(源代码:https://github.com/oxwhirl/smac),如图 2 所示。这一任务最初由 M. Samvelyan 等人提出 [2],提供了 23 个实验地图,agent 数量从 2 到 27 不等,我方 agent 需要进行协作来打败敌方 agent 以赢得游戏。自该任务发布以来,有很多研究人员针对其特点进行了算法研究,例如经典算法 QMix[6] 以及最新发表的 RODE[7]等等。由于 StarCraftII 经过了版本迭代,并且不同版本之间性能有差距,特别说明,这篇论文采用的是最新版本 SC2.4.10。

图 2:StarCraftII 环境中的 2 个代表性地图:Corridor 和 2c vs. 64zg
1.1.3 协作任务 Hanabi
第三个环境是由 Nolan Bard 等人 [3] 在 2019 年提出的一个纯协作任务 Hanabi(源代码:https://github.com/deepmind/hanabi-learning-environment),Hanabi 是一个 turn-based 的纸牌类游戏,也就是每一轮只有一个玩家可以出牌,相较于之前的多智能体任务,Hanabi 的一个重要特点是纯合作,每个玩家需要对其他玩家的意图进行推理,完成协作才能获得分数,Hanabi 的玩家数可以是 2-5 个,图 3 是 4 个玩家的任务示意图,感兴趣的读者可以自己尝试玩一下。

图 3:4 个玩家的 Hanabi-Full 任务示意图
1.2 实验结果
首先来看一下论文给出的实验结果,特别注意,论文所有的实验都在一台主机中完成,该主机的配置是 256 GB 内存, 一块 64 核 CPU 和一块 GeForce RTX 3090 24GB 显卡。另外,研究者表示,本文的所有的算法都进行了微调(fine-tune),所以本文中的复现的某些实验结果会优于原论文。
(1)MPE 环境
图 4 展示了在 MPE 中不同算法的数据样本效率和算法运行效率对比,其中 IPPO(Independent PPO)表示的是 critic 学习一个分布式的价值函数(decentralized value function),即 critic 与 actor 的输入均为局部观测,IPPO 和 MAPPO 超参保持一致;MADDPG[5]是 MARL 领域十分流行的 off-policy 算法,也是针对 MPE 开发的一个算法,QMix[6]是针对 StarCraftII 开发的 MARL 算法,也是 StarCraftII 中的常用 baseline。
从图 4 可以看出与其他算法相比,MAPPO 不仅具有相当的数据样本效率和性能表现(performance)(图(a)),同时还具有显著高的算法运行效率(图(b))。

图 4:在 MPE 中不同算法的数据样本效率和算法运行效率对比
(2)StarCraftII 环境
表 1 展示了 MAPPO 与 IPPO,QMix 以及针对 StarCraftII 的开发的 SOTA 算法 RODE 的胜率对比,在截断至 10M 数据的情况下,MAPPO 在 19/23 个地图的胜率都达到了 SOTA,除了 3s5z vs. 3s6z,其他地图与 SOTA 算法的差距小于 5%,而 3s5z vs. 3s6z 在截断至 10M 时并未完全收敛,如果截断至 25M,则可以达到 91% 的胜率。
图 5 表示在 StarCraftII 中不同算法的数据样本效率和算法运行效率对比。可以看出 MAPPO 实际上与 QMix 和 RODE 具有相当的数据样本效率,以及更快的算法运行效率。由于在实际训练 StarCraftII 任务的时候仅采用 8 个并行环境,而在 MPE 任务中采用了 128 个并行环境,所以图 5 的算法运行效率没有图 4 差距那么大,但是即便如此,依然可以看出 MAPPO 惊人的性能表现和运行效率。

表 1:不同算法在 StarCraftII 的 23 个地图中的胜率对比,其中 cut 标记表示将 MAPPO 和 QMix 截断至与 RODE 相同的步数,目的是为了与 SOTA 算法公平对比。

(3)Hanabi 环境
SAD 是针对 Hanabi 任务开发的一个 SOTA 算法,值得注意的是,SAD 的得分取自原论文,原作者跑了 13 个随机种子,每个种子需要约 10B 数据,而由于时间限制,MAPPO 只跑了 4 个随机种子,每个种子约 7.2B 数据。从表 2 可以看出 MAPPO 依然可以达到与 SAD 相当的得分。
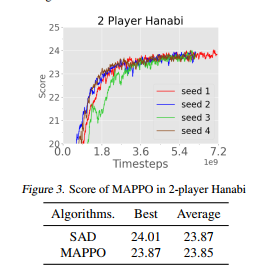
表 2:MAPPO 和 SAD 在 2 个玩家的 Hanabi-Full 任务的得分对比。
1.3 相关建议
研究者发现,即便多智能体任务与单智能体任务差别很大,但是之前在其他单智能体任务中的给出的 PPO 实现建议依然很有用,例如 input normalization,value clip,max gradient norm clip,orthogonal initialization,GAE normalization 等。但是除此之外,研究者额外给出了针对 MARL 领域以及其他易被忽视的因素的 5 条建。:
- Value normalization: 研究者采用 PopArt 对 value 进行 normalization,并且指出使用 PopArt 有益无害。
- Agent Specific Global State: 采用 agent-specific 的全局信息,避免全局信息遗漏以及维度过高。值得一提的是,研究者发现 StarCraftII 中原有的全局信息存在信息遗漏,甚至其所包含的信息少于 agent 的局部观测,这也是直接将 MAPPO 应用在 StarCraftII 中性能表现不佳的重要原因。
- Training Data Usage: 简单任务中推荐使用 15 training epochs,而对于较难的任务,尝试 10 或者 5 training epochs。除此之外,尽量使用一整份的训练数据,而不要切成很多小份(mini-batch)训练。
- Action Masking: 在多智能体任务中经常出现 agent 无法执行某些 action 的情况,建议无论前向执行还是反向传播时,都应将这些无效动作屏蔽掉,使其不参与动作概率计算。
- Death Masking: 在多智能体任务中,也经常会出现某个 agent 或者某些 agents 中途死掉的情况(例如 StarCraftII)。当 agent 死亡后,仅保留其 agent id,将其他信息屏蔽能够学得更加准确的状态价值函数。
更多的实验细节和分析可以查看论文原文。
1.4 文献参考
[1] Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, P., and Mor-datch, I. Multi-agent actor-critic for mixed cooperative-competitive environments.Neural Information Process-ing Systems (NIPS), 2017.
[2] M. Samvelyan, T. Rashid, C. Schroeder de Witt, G. Farquhar, N. Nardelli, T.G.J. Rudner, C.-M. Hung, P.H.S. Torr, J. Foerster, S. Whiteson. The StarCraft Multi-Agent Challenge, CoRR abs/1902.04043, 2019.
[3] Bard, N., Foerster, J. N., Chandar, S., Burch, N., Lanctot,M., Song, H. F., Parisotto, E., Dumoulin, V., Moitra, S.,Hughes, E., et al. The Hanabi challenge: A new frontierfor AI research.Artificial Intelligence, 280:103216, 2020.
[4] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., andKlimov, O. Proximal policy optimization algorithms.CoRR, abs/1707.06347, 2017.
[5] Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, P., and Mor-datch, I. Multi-agent actor-critic for mixed cooperative-competitive environments.Neural Information Process-ing Systems (NIPS), 2017.
[6] Rashid, T., Samvelyan, M., Schroeder, C., Farquhar, G.,Foerster, J., and Whiteson, S. QMIX: Monotonic valuefunction factorisation for deep multi-agent reinforcementlearning. volume 80 ofProceedings of Machine LearningResearch, pp. 4295–4304. PMLR, 10–15 Jul 2018.
[7] Wang, T., Gupta, T., Mahajan, A., Peng, B., Whiteson, S.,and Zhang, C. RODE: Learning roles to decompose multi-agent tasks. InInternational Conference on LearningRepresentations, 2021.
[8] Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V., Ward, T., Doron, Y., Firoiu, V., Harley, T., Dunning,I., et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. In International Conference on Machine Learning, pp. 1407–1416, 2018.
[9] Hu, H. and Foerster, J. N. Simplified action decoder for deep multi-agent reinforcement learning. In International Conference on Learning Representations, 2020.
多智能体强化学习算法【一】【MAPPO、MADDPG、QMIX】的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- 强化学习算法Policy Gradient
1 算法的优缺点 1.1 优点 在DQN算法中,神经网络输出的是动作的q值,这对于一个agent拥有少数的离散的动作还是可以的.但是如果某个agent的动作是连续的,这无疑对DQN算法是一个巨大的挑战 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- DRL 教程 | 如何保持运动小车上的旗杆屹立不倒?TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
随机推荐
- AIGC
博客目录 本地部署modelscope-agent python 使用 Google Gemini API MetaGPT MetaGPT day01: MetaGPT作者代码走读.软件公司初始示例
- hyper-v虚拟机中ubuntu连不上网络的解决办法
首先重启下hyper-v的服务,看下情况: 1.检查hyper-v相关的服务有没有开启 2.如果开启了服务,unbuntu仍然不能连网,则在ubtuntu中进行接下来的步骤: 2.1 设置网络连接为N ...
- OOALV总结
1.1ALV屏幕 1.1.1定义无CONTAINER屏幕 1.屏幕中可以不使用定制控制控件画范围,直接定义一个屏幕即可. "--------------------------------- ...
- C# Task 多任务:C# 扩展TaskScheduler实现独立线程池,支持多任务批量处理,互不干扰,无缝兼容Task
先上源码: https://gitee.com/s0611163/TaskSchedulerEx 为什么编写TaskSchedulerEx类? 因为.NET默认线程池只有一个线程池,如果某个批 ...
- 在 Ubuntu 20.04 上安装 Visual Studio Code
Visual Studio Code 是一个由微软开发的强大的开源代码编辑器.它包含内建的调试支持,嵌入的 Git 版本控制,语法高亮,代码自动完成,集成终端,代码重构以及代码片段功能. Visual ...
- AtCoder Beginner Contest 216 个人题解
比赛链接:Here AB水题, C - Many Balls 题意: 现在有一个数初始为 \(0(x)\) 以及两种操作 操作 \(A:\) \(x + 1\) 操作 \(B: 2\times x\) ...
- iviews Radio组件如何获取key而不是value
iviews RadioGroup 官网里介绍Radio组件获取的值都是name属性没有value 例如: <template> <Space wrap size="lar ...
- Git | git branch 分支操作
假设我们已经有了稳定的代码,现在我想整一些花活.比较安全的一个方式是,在新的分支上整活. 新建 vga 分支:git branch vga,然后切换到 vga 分支:git switch vga,或者 ...
- docker查看日志:docker service logs 与 docker container logs
转载请注明出处: docker service logs 和 docker container logs 是两个不同的命令,用于查看 Docker 服务和容器的日志.以下是它们之间的区别: 1.doc ...
- spring cloud feign 调用一直fallback
本文为博主原创,转载请注明出处: 功能在本地调试的时候一直是正常可以调用的,当服务发布到 dev 环境的时候,调用的时候一直 fallback,且由于服务调用的时候,对 Feign 配置了 fallb ...