实践GoF的23的设计模式:SOLID原则(下)
摘要:本文将讲述SOLID原则中的接口隔离原则和依赖倒置原则。
本文分享自华为云社区《实践GoF的23的设计模式:SOLID原则(下)》,作者:元闰子。
在《实践GoF的23种设计模式:SOLID原则(上)》中,主要讲了SOLID原则中的单一职责原则、开闭原则、里氏替换原则,接下来在本文中将继续讲述接口隔离原则和依赖倒置原则。
ISP:接口隔离原则
接口隔离原则(The Interface Segregation Principle,ISP)是关于接口设计的一项原则,这里的“接口”并不单指Java或Go上使用interface声明的狭义接口,而是包含了狭义接口、抽象类、具象类等在内的广义接口。它的定义如下:
Client should not be forced to depend on methods it does not use.
也即,一个模块不应该强迫客户程序依赖它们不想使用的接口,模块间的关系应该建立在最小的接口集上。
下面,我们通过一个例子来详细介绍ISP。
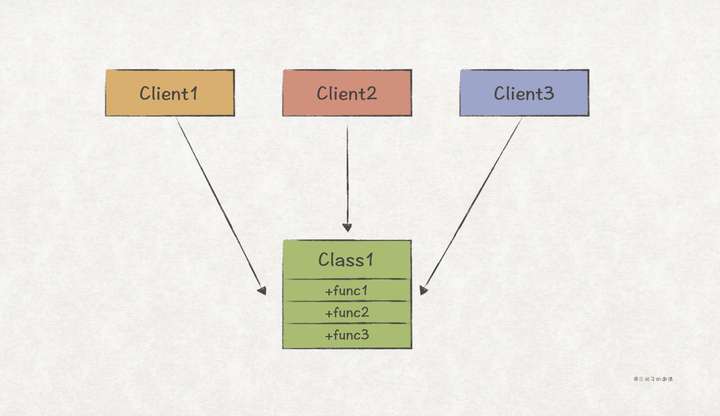
上图中,Client1、Client2、Client3都依赖了Class1,但实际上,Client1只需使用Class1.func1方法,Client2只需使用Class1.func2,Client3只需使用Class1.func3,那么这时候我们就可以说该设计违反了ISP。
违反ISP主要会带来如下2个问题:
- 增加模块与客户端程序的依赖,比如在上述例子中,虽然Client2和Client3都没有调用func1,但是当Class1修改func1还是必须通知Client1~3,因为Class1并不知道它们是否使用了func1。
- 产生接口污染,假设开发Client1的程序员,在写代码时不小心把func1打成了func2,那么就会带来Client1的行为异常。也即Client1被func2给污染了。
为了解决上述2个问题,我们可以把func1、func2、func3通过接口隔离开:
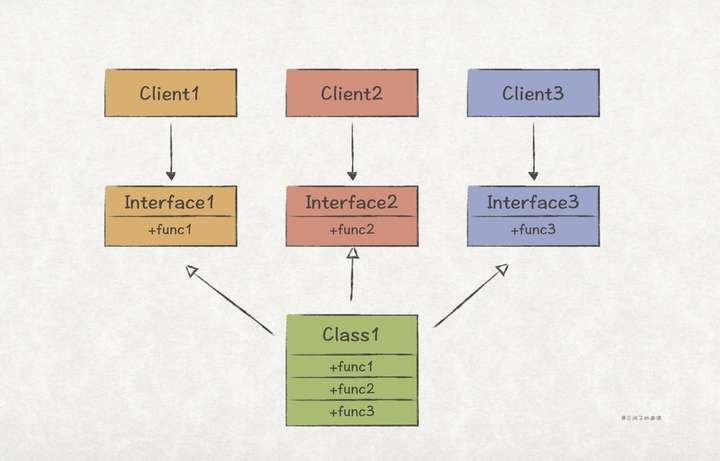
接口隔离之后,Client1只依赖了Interface1,而Interface1上只有func1一个方法,也即Client1不会受到func2和func3的污染;另外,当Class1修改func1之后,它只需通知依赖了Interface1的客户端即可,大大降低了模块间耦合。
实现ISP的关键是将大接口拆分成小接口,而拆分的关键就是接口粒度的把握。想要拆分得好,就要求接口设计人员对业务场景非常熟悉,对接口使用的场景了如指掌。否则孤立地设计接口,很难满足ISP。
下面,我们以分布式应用系统demo为例,来进一步介绍ISP的实现。
一个消息队列模块通常包含生产(produce)和消费(consumer)两种行为,因此我们设计了Mq消息队列抽象接口,包含produce和consume两个方法:
// 消息队列接口
public interface Mq {
Message consume(String topic);
void produce(Message message);
} // demo/src/main/java/com/yrunz/designpattern/mq/MemoryMq.java
// 当前提供MemoryMq内存消息队列的实现
public class MemoryMq implements Mq {...}
当前demo中使用接口的模块有2个,分别是作为消费者的MemoryMqInput和作为生产者的AccessLogSidecar:
public class MemoryMqInput implements InputPlugin {
private String topic;
private Mq mq;
...
@Override
public Event input() {
Message message = mq.consume(topic);
Map<String, String> header = new HashMap<>();
header.put("topic", topic);
return Event.of(header, message.payload());
}
...
}
public class AccessLogSidecar implements Socket {
private final Mq mq;
private final String topic
...
@Override
public void send(Packet packet) {
if ((packet.payload() instanceof HttpReq)) {
String log = String.format("[%s][SEND_REQ]send http request to %s",
packet.src(), packet.dest());
Message message = Message.of(topic, log);
mq.produce(message);
}
...
}
...
}
从领域模型上看,Mq接口的设计确实没有问题,它就应该包含consume和produce两个方法。但是从客户端程序的角度上看,它却违反了ISP,对MemoryMqInput来说,它只需要consume方法;对AccessLogSidecar来说,它只需要produce方法。
一种设计方案是把Mq接口拆分成2个子接口Consumable和Producible,让MemoryMq直接实现Consumable和Producible:
// demo/src/main/java/com/yrunz/designpattern/mq/Consumable.java
// 消费者接口,从消息队列中消费数据
public interface Consumable {
Message consume(String topic);
} // demo/src/main/java/com/yrunz/designpattern/mq/Producible.java
// 生产者接口,向消息队列生产消费数据
public interface Producible {
void produce(Message message);
} // 当前提供MemoryMq内存消息队列的实现
public class MemoryMq implements Consumable, Producible {...}
仔细思考一下,就会发现上面的设计不太符合消息队列的领域模型,因为Mq的这个抽象确实应该存在的。
更好的设计应该是保留Mq抽象接口,让Mq继承自Consumable和Producible,这样的分层设计之后,既能满足ISP,又能让实现符合消息队列的领域模型:
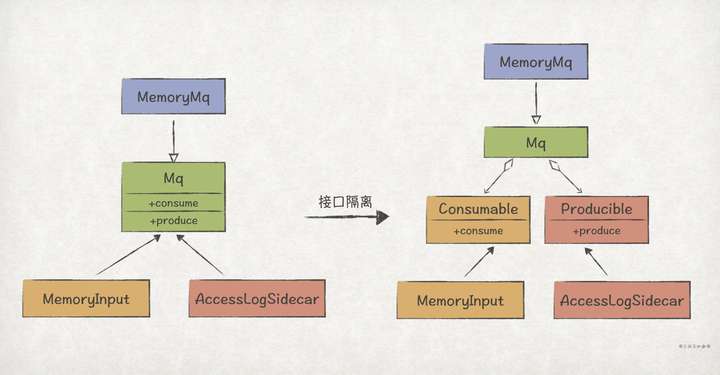
具体实现如下:
// demo/src/main/java/com/yrunz/designpattern/mq/Mq.java
// 消息队列接口,继承了Consumable和Producible,同时又consume和produce两种行为
public interface Mq extends Consumable, Producible {} // 当前提供MemoryMq内存消息队列的实现
public class MemoryMq implements Mq {...} // demo/src/main/java/com/yrunz/designpattern/monitor/input/MemoryMqInput.java
public class MemoryMqInput implements InputPlugin {
private String topic;
// 消费者只依赖Consumable接口
private Consumable consumer;
...
@Override
public Event input() {
Message message = consumer.consume(topic);
Map<String, String> header = new HashMap<>();
header.put("topic", topic);
return Event.of(header, message.payload());
}
...
} // demo/src/main/java/com/yrunz/designpattern/sidecar/AccessLogSidecar.java
public class AccessLogSidecar implements Socket {
// 生产者只依赖Producible接口
private final Producible producer;
private final String topic
...
@Override
public void send(Packet packet) {
if ((packet.payload() instanceof HttpReq)) {
String log = String.format("[%s][SEND_REQ]send http request to %s",
packet.src(), packet.dest());
Message message = Message.of(topic, log);
producer.produce(message);
}
...
}
...
}
接口隔离可以减少模块间耦合,提升系统稳定性,但是过度地细化和拆分接口,也会导致系统的接口数量的上涨,从而产生更大的维护成本。接口的粒度需要根据具体的业务场景来定,可以参考单一职责原则,将那些为同一类客户端程序提供服务的接口合并在一起。
DIP:依赖倒置原则
《Clean Architecture》中介绍OCP时有提过:如果要模块A免于模块B变化的影响,那么就要模块B依赖于模块A。这句话貌似是矛盾的,模块A需要使用模块B的功能,怎么会让模块B反过来依赖模块A呢?这就是依赖倒置原则(The Dependency Inversion Principle,DIP)所要解答的问题。
DIP的定义如下:
- High-level modules should not import anything from low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
翻译过来,就是:
- 高层模块不应该依赖低层模块,两者都应该依赖抽象
- 抽象不应该依赖细节,细节应该依赖抽象
在DIP的定义里,出现了高层模块、低层模块、抽象、细节等4个关键字,要弄清楚DIP的含义,理解者4个关键字至关重要。
(1)高层模块和低层模块
一般地,我们认为高层模块是包含了应用程序核心业务逻辑、策略的模块,是整个应用程序的灵魂所在;低层模块通常是一些基础设施,比如数据库、Web框架等,它们主要为了辅助高层模块完成业务而存在。
(2)抽象和细节
在前文“OCP:开闭原则”一节中,我们可以知道,抽象就是众多细节中的共同点,抽象就是不断忽略细节的出来的。
现在再来看DIP的定义,对于第2点我们不难理解,从抽象的定义来看,抽象是不会依赖细节的,否则那就不是抽象了;而细节依赖抽象往往都是成立的。
理解DIP的关键在于第1点,按照我们正向的思维,高层模块要借助低层模块来完成业务,这必然会导致高层模块依赖低层模块。但是在软件领域里,我们可以把这个依赖关系倒置过来,这其中的关键就是抽象。我们可以忽略掉低层模块的细节,抽象出一个稳定的接口,然后让高层模块依赖该接口,同时让低层模块实现该接口,从而实现了依赖关系的倒置:
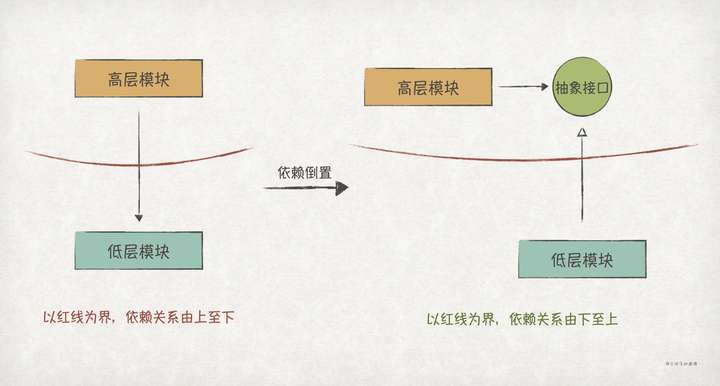
之所以要把高层模块和底层模块的依赖关系倒置过来,主要是因为作为核心的高层模块不应该受到低层模块变化的影响。高层模块的变化原因应当只能有一个,那就是来自软件用户的业务变更需求。
下面,我们通过分布式应用系统demo来介绍DIP的实现。
对于服务注册中心Registry来说,当有新的服务注册上来时,它需要把服务信息(如服务ID、服务类型等)保存下来,以便在后续的服务发现中能够返回给客户端。因此,Registry需要一个数据库来辅助它完成业务。刚好,我们的数据库模块实现了一个内存数据库MemoryDb,于是我们可以这么实现Registry:
// 服务注册中心
public class Registry implements Service {
...
// 直接依赖MemoryDb
private final MemoryDb db;
private final SvcManagement svcManagement;
private final SvcDiscovery svcDiscovery; private Registry(...) {
...
// 初始化MemoryDb
this.db = MemoryDb.instance();
this.svcManagement = new SvcManagement(localIp, this.db, sidecarFactory);
this.svcDiscovery = new SvcDiscovery(this.db);
}
...
} // 内存数据库
public class MemoryDb {
private final Map<String, Table<?, ?>> tables;
...
// 查询表记录
public <PrimaryKey, Record> Optional<Record> query(String tableName, PrimaryKey primaryKey) {
Table<PrimaryKey, Record> table = (Table<PrimaryKey, Record>) tableOf(tableName);
return table.query(primaryKey);
}
// 插入表记录
public <PrimaryKey, Record> void insert(String tableName, PrimaryKey primaryKey, Record record) {
Table<PrimaryKey, Record> table = (Table<PrimaryKey, Record>) tableOf(tableName);
table.insert(primaryKey, record);
}
// 更新表记录
public <PrimaryKey, Record> void update(String tableName, PrimaryKey primaryKey, Record record) {
Table<PrimaryKey, Record> table = (Table<PrimaryKey, Record>) tableOf(tableName);
table.update(primaryKey, record);
}
// 删除表记录
public <PrimaryKey> void delete(String tableName, PrimaryKey primaryKey) {
Table<PrimaryKey, ?> table = (Table<PrimaryKey, ?>) tableOf(tableName);
table.delete(primaryKey);
}
...
}
按照上面的设计,模块间的依赖关系是Registry依赖于MemoryDb,也即高层模块依赖于低层模块。这种依赖关系是脆弱的,如果哪天需要把存储服务信息的数据库从MemoryDb改成DiskDb,那么我们也得改Registry的代码:
// 服务注册中心
public class Registry implements Service {
...
// 改成依赖DiskDb
private final DiskDb db;
...
private Registry(...) {
...
// 初始化DiskDb
this.db = DiskDb.instance();
this.svcManagement = new SvcManagement(localIp, this.db, sidecarFactory);
this.svcDiscovery = new SvcDiscovery(this.db);
}
...
}
更好的设计应该是把Registry和MemoryDb的依赖关系倒置过来,首先我们需要从细节MemoryDb抽象出一个稳定的接口Db:
// demo/src/main/java/com/yrunz/designpattern/db/Db.java
// DB抽象接口
public interface Db {
<PrimaryKey, Record> Optional<Record> query(String tableName, PrimaryKey primaryKey);
<PrimaryKey, Record> void insert(String tableName, PrimaryKey primaryKey, Record record);
<PrimaryKey, Record> void update(String tableName, PrimaryKey primaryKey, Record record);
<PrimaryKey> void delete(String tableName, PrimaryKey primaryKey);
...
}
接着,我们让Registry依赖Db接口,而MemoryDb实现Db接口,以此来完成依赖倒置:
// demo/src/main/java/com/yrunz/designpattern/service/registry/Registry.java
// 服务注册中心
public class Registry implements Service {
...
// 只依赖于Db抽象接口
private final Db db;
private final SvcManagement svcManagement;
private final SvcDiscovery svcDiscovery; private Registry(..., Db db) {
...
// 依赖注入Db
this.db = db;
this.svcManagement = new SvcManagement(localIp, this.db, sidecarFactory);
this.svcDiscovery = new SvcDiscovery(this.db);
}
...
} // demo/src/main/java/com/yrunz/designpattern/db/MemoryDb.java
// 内存数据库,实现Db抽象接口
public class MemoryDb implements Db {
private final Map<String, Table<?, ?>> tables;
...
// 查询表记录
@Override
public <PrimaryKey, Record> Optional<Record> query(String tableName, PrimaryKey primaryKey) {...}
// 插入表记录
@Override
public <PrimaryKey, Record> void insert(String tableName, PrimaryKey primaryKey, Record record) {...}
// 更新表记录
@Override
public <PrimaryKey, Record> void update(String tableName, PrimaryKey primaryKey, Record record) {...}
// 删除表记录
@Override
public <PrimaryKey> void delete(String tableName, PrimaryKey primaryKey) {...}
...
} // demo/src/main/java/com/yrunz/designpattern/Example.java
public class Example {
// 在main函数中完成依赖注入
public static void main(String[] args) {
...
// 将MemoryDb.instance()注入到Registry上
Registry registry = Registry.of(..., MemoryDb.instance());
registry.run();
}
}
当高层模块依赖抽象接口时,总得在某个时候,某个地方把实现细节(低层模块)注入到高层模块上。在上述例子中,我们选择在main函数上,在创建Registry对象时,把MemoryDb注入进去。
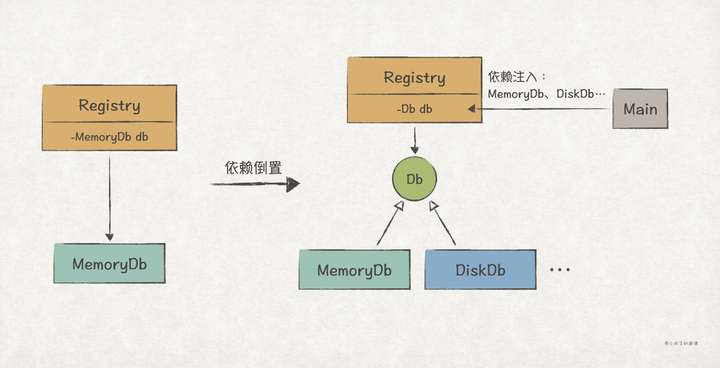
一般地,我们都会在main/启动函数上完成依赖注入,常见的注入的方式有以下几种:
- 构造函数注入(Registry所使用的方法)
- setter方法注入
- 提供依赖注入的接口,客户端直调用该接口即可
- 通过框架进行注入,比如Spring框架中的注解注入能力
另外,DIP不仅仅适用于模块/类/接口设计,在架构层面也同样适用,比如DDD的分层架构和Uncle Bob的整洁架构,都是运用了DIP:
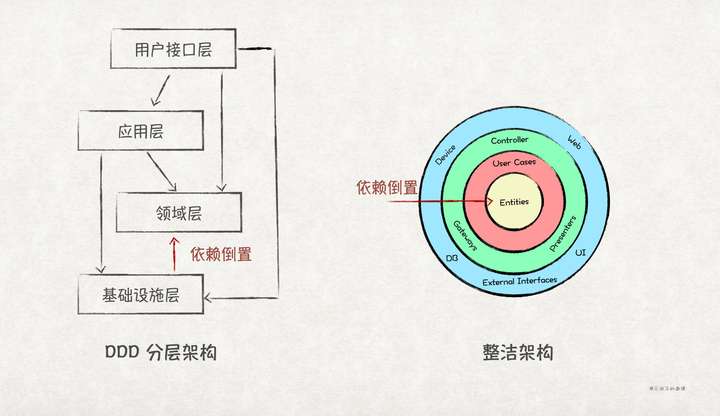
当然,DIP并不是说高层模块是只能依赖抽象接口,它的本意应该是依赖稳定的接口/抽象类/具象类。如果一个具象类是稳定的,比如Java中的String,那么高层模块依赖它也没有问题;相反,如果一个抽象接口是不稳定的,经常变化,那么高层模块依赖该接口也是违反DIP的,这时候应该思考下接口是否抽象合理。
最后
本文花了很长的篇幅讨论了23种设计模式背后的核心思想 —— SOLID原则,它能指导我们设计出高内聚、低耦合的软件系统。但是它毕竟只是原则,如何落地到实际的工程项目上,还是需要参考成功的实践经验。而这些实践经验正是接下来我们要探讨的设计模式。
学习设计模式最好的方法就是实践,在《实践GoF的23种设计模式》后续的文章里,我们将以本文介绍的分布式应用系统demo作为实践示范,介绍23种设计模式的程序结构、适用场景、实现方法、优缺点等,让大家对设计模式有个更深入的理解,能够用对、不滥用设计模式。
参考
- Clean Architecture, Robert C. Martin (“Uncle Bob”)
- 敏捷软件开发:原则、模式与实践, Robert C. Martin (“Uncle Bob”)
- 使用Go实现GoF的23种设计模式, 元闰子
- SOLID原则精解之里氏替换原则LSP, 人民副首席码仔
实践GoF的23的设计模式:SOLID原则(下)的更多相关文章
- 实践GoF的23种设计模式:SOLID原则(上)
摘要:本文以我们日常开发中经常碰到的一些技术/问题/场景作为切入点,示范如何运用设计模式来完成相关的实现. 本文分享自华为云社区<实践GoF的23种设计模式:SOLID原则(上)>,作者: ...
- 实践GoF的23种设计模式:建造者模式
摘要:针对这种对象成员较多,创建对象逻辑较为繁琐的场景,非常适合使用建造者模式来进行优化. 本文分享自华为云社区<[Go实现]实践GoF的23种设计模式:建造者模式>,作者: 元闰子. 简 ...
- 实践GoF的23种设计模式:观察者模式
摘要:当你需要监听某个状态的变更,且在状态变更时通知到监听者,用观察者模式吧. 本文分享自华为云社区<[Go实现]实践GoF的23种设计模式:观察者模式>,作者: 元闰子 . 简介 现在有 ...
- 实践GoF的23种设计模式:命令模式
摘要:命令模式可将请求转换为一个包含与请求相关的所有信息的对象, 它能将请求参数化.延迟执行.实现 Undo / Redo 操作等. 本文分享自华为云社区<[Go实现]实践GoF的23种设计模式 ...
- 实践GoF的23种设计模式:装饰者模式
摘要:装饰者模式通过组合的方式,提供了能够动态地给对象/模块扩展新功能的能力.理论上,只要没有限制,它可以一直把功能叠加下去,具有很高的灵活性. 本文分享自华为云社区<[Go实现]实践GoF的2 ...
- java设计模式:概述与GoF的23种设计模式
软件设计模式的产生背景 设计模式这个术语最初并不是出现在软件设计中,而是被用于建筑领域的设计中. 1977 年,美国著名建筑大师.加利福尼亚大学伯克利分校环境结构中心主任克里斯托夫·亚历山大(Chri ...
- 2.GoF 的 23 种设计模式的分类和功能
1. 根据目的来分 根据模式是用来完成什么工作来划分,这种方式可分为创建型模式.结构型模式和行为型模式 3 种. 创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”.GoF ...
- GoF 的 23 种设计模式的分类和功能
1. 根据目的来分 根据模式是用来完成什么工作来划分,这种方式可分为创建型模式.结构型模式和行为型模式 3 种. 创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”.GoF ...
- GoF的23种设计模式的功能
GoF的23种设计模式的功能 前面说明了 GoF 的 23 种设计模式的分类,现在对各个模式的功能进行介绍. 单例(Singleton)模式:某个类只能生成一个实例,该类提供了一个全局访问点供外部获取 ...
- GoF的23种设计模式之创建型模式的特点和分类
创建型模式的主要关注点是“怎样创建对象?”,它的主要特点是“将对象的创建与使用分离”.这样可以降低系统的耦合度,使用者不需要关注对象的创建细节,对象的创建由相关的工厂来完成.就像我们去商场购买商品时, ...
随机推荐
- select...for update到底是加了行锁,还是表锁?
前言 前几天,知识星球中的一个小伙伴,问了我一个问题:在MySQL中,事务A中使用select...for update where id=1锁住了,某一条数据,事务还没提交,此时,事务B中去用sel ...
- 自编码器AE全方位探析:构建、训练、推理与多平台部署
本文深入探讨了自编码器(AE)的核心概念.类型.应用场景及实战演示.通过理论分析和实践结合,我们详细解释了自动编码器的工作原理和数学基础,并通过具体代码示例展示了从模型构建.训练到多平台推理部署的全过 ...
- acwing第75场周赛
这次题比较水,但是还是没能ak,自己小结一下吧 第一道题就是自己枚举相加就行 第二道题是一个多关键字排序,wa了几次,是因为优先级有两个是相同的需要特判一下,然后可以把字符转化为数字的优先级,我用了一 ...
- 创建CI/CD流水线中的IaC前,需要考虑哪些事项?
许多软件工程团队通常会遵循相似的方法来交付基础设施以支持软件开发生命周期.为了缩小基础设施配置方式与应用程序环境部署方式之间的差距,许多 DevOps 团队将其基础设施即代码(IaC)模块直接连接到其 ...
- APP攻防--安卓逆向&JEB动态调试&LSPosed模块&算法提取&Hook技术
JEB环境配置 安装java环境变量(最好jdk11) 安装adb环境变量 设置adb环境变量最好以Android命名 启动开发者模式 设置-->关于平板电脑-->版本号(单机五次) 开启 ...
- Redis Functions 介绍之二
首先,让我们先回顾一下上一篇讲的在Redis Functions中关于将key的名字作为参数和非key名字作为参数的区别,先看下面的例子.首先,我们先在一个Lua脚本文件mylib.lua中定义如下的 ...
- 【MySQL】MySQL中的锁
全局锁 全局锁是对整个数据库实例加锁,整个库处于只读状态. flush tables with read lock 适用场景 全局锁适用于做全库逻辑备份,但是整个库处于只读状态,在备份期间,所有的更新 ...
- 查看API官方文档
盛年不重来,一日难再晨.及时宜自勉,岁月不待人. 学习一门语言, 了解其开发文档必不可少.开发文档就是我们在编程开发.维护.升级过程中的参考最全面.最权威的资料.我认为就是开发者为后人方便理解留下 ...
- 3款高评价的.Net开发的WMS系统推荐
本文简介 WMS仓库管理系统是一款专业的仓库管理系统,旨在帮助企业实现仓储管理的智能化.信息化和自动化.通过该系统,企业可以实现对仓库的进货.出货.库存等各个环节的全面把控,提高仓储管理水平,降低运营 ...
- SpringBoot实现Flyway的Callback回调钩子
背景 产品迭代使用CI/CD升级过程中,需要对不同发布环境的不同产品版本进行数据库迭代升级,我们在中间某次产品迭代时加入了Flyway中间件以实现数据库结构的自动化升级. 需求 由于是迭代过程中加入的 ...