Spark函数详解系列之RDD基本转换
object Map {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("map")
val sc = new SparkContext(conf)
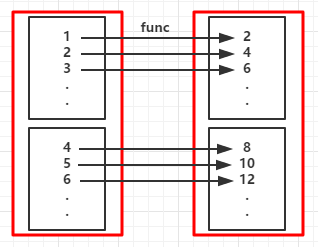
val rdd = sc.parallelize(1 to 10) //创建RDD
val map = rdd.map(_*2) //对RDD中的每个元素都乘于2
map.foreach(x => print(x+" "))
sc.stop()
}
}

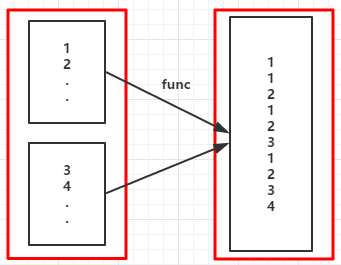
//...省略sc
val rdd = sc.parallelize(1 to 5)
val fm = rdd.flatMap(x => (1 to x)).collect()
fm.foreach( x => print(x + " "))
1 1 2 1 2 3 1 2 3 4 1 2 3 4 5
Range(1) Range(1, 2) Range(1, 2, 3) Range(1, 2, 3, 4) Range(1, 2, 3, 4, 5)
(RDD依赖图)

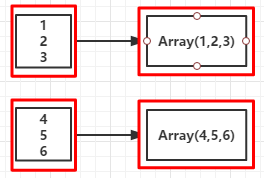
object MapPartitions {
//定义函数
def partitionsFun(/*index : Int,*/iter : Iterator[(String,String)]) : Iterator[String] = {
var woman = List[String]()
while (iter.hasNext){
val next = iter.next()
next match {
case (_,"female") => woman = /*"["+index+"]"+*/next._1 :: woman
case _ =>
}
}
return woman.iterator
}
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("mappartitions")
val sc = new SparkContext(conf)
val l = List(("kpop","female"),("zorro","male"),("mobin","male"),("lucy","female"))
val rdd = sc.parallelize(l,2)
val mp = rdd.mapPartitions(partitionsFun)
/*val mp = rdd.mapPartitionsWithIndex(partitionsFun)*/
mp.collect.foreach(x => (print(x +" "))) //将分区中的元素转换成Aarray再输出
}
}
kpop lucy
val mp = rdd.mapPartitions(x => x.filter(_._2 == "female")).map(x => x._1)

[0]kpop [1]lucy
//省略
val rdd = sc.parallelize(1 to 10)
val sample1 = rdd.sample(true,0.5,3)
sample1.collect.foreach(x => print(x + " "))
sc.stop
//省略sc
val rdd1 = sc.parallelize(1 to 3)
val rdd2 = sc.parallelize(3 to 5)
val unionRDD = rdd1.union(rdd2)
unionRDD.collect.foreach(x => print(x + " "))
sc.stop
1 2 3 3 4 5
//省略sc
val rdd1 = sc.parallelize(1 to 3)
val rdd2 = sc.parallelize(3 to 5)
val unionRDD = rdd1.intersection(rdd2)
unionRDD.collect.foreach(x => print(x + " "))
sc.stop
3 4
//省略sc
val list = List(1,1,2,5,2,9,6,1)
val distinctRDD = sc.parallelize(list)
val unionRDD = distinctRDD.distinct()
unionRDD.collect.foreach(x => print(x + " "))
1 6 9 5 2
//省略
val rdd1 = sc.parallelize(1 to 3)
val rdd2 = sc.parallelize(2 to 5)
val cartesianRDD = rdd1.cartesian(rdd2)
cartesianRDD.foreach(x => println(x + " "))
(1,2)
(1,3)
(1,4)
(1,5)
(2,2)
(2,3)
(2,4)
(2,5)
(3,2)
(3,3)
(3,4)
(3,5)
(RDD依赖图)


//省略
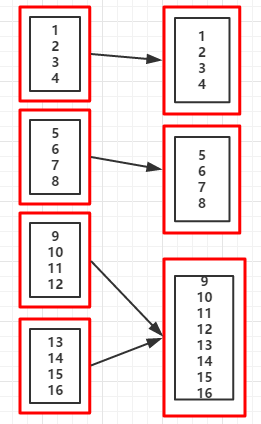
val rdd = sc.parallelize(1 to 16,4)
val coalesceRDD = rdd.coalesce(3) //当suffle的值为false时,不能增加分区数(即分区数不能从5->7)
println("重新分区后的分区个数:"+coalesceRDD.partitions.size)
重新分区后的分区个数:3
//分区后的数据集
List(1, 2, 3, 4)
List(5, 6, 7, 8)
List(9, 10, 11, 12, 13, 14, 15, 16)
//...省略
val rdd = sc.parallelize(1 to 16,4)
val coalesceRDD = rdd.coalesce(7,true)
println("重新分区后的分区个数:"+coalesceRDD.partitions.size)
println("RDD依赖关系:"+coalesceRDD.toDebugString)
重新分区后的分区个数:5
RDD依赖关系:(5) MapPartitionsRDD[4] at coalesce at Coalesce.scala:14 []
| CoalescedRDD[3] at coalesce at Coalesce.scala:14 []
| ShuffledRDD[2] at coalesce at Coalesce.scala:14 []
+-(4) MapPartitionsRDD[1] at coalesce at Coalesce.scala:14 []
| ParallelCollectionRDD[0] at parallelize at Coalesce.scala:13 []
//分区后的数据集
List(10, 13)
List(1, 5, 11, 14)
List(2, 6, 12, 15)
List(3, 7, 16)
List(4, 8, 9)
(RDD依赖图:coalesce(3,flase))

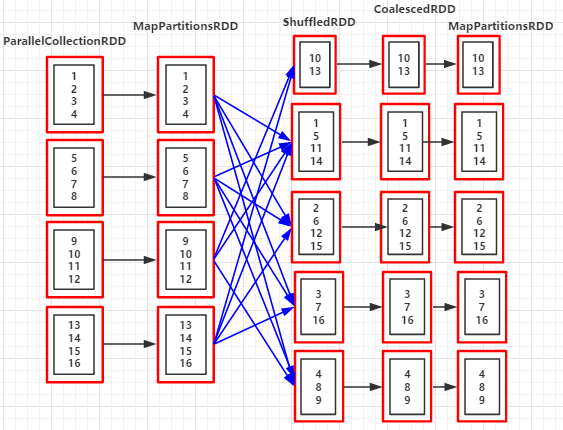
//省略
val rdd = sc.parallelize(1 to 16,4)
val glomRDD = rdd.glom() //RDD[Array[T]]
glomRDD.foreach(rdd => println(rdd.getClass.getSimpleName))
sc.stop
int[] //说明RDD中的元素被转换成数组Array[Int]

//省略sc
val rdd = sc.parallelize(1 to 10)
val randomSplitRDD = rdd.randomSplit(Array(1.0,2.0,7.0))
randomSplitRDD(0).foreach(x => print(x +" "))
randomSplitRDD(1).foreach(x => print(x +" "))
randomSplitRDD(2).foreach(x => print(x +" "))
sc.stop
2 4
3 8 9
1 5 6 7 10
5.
Spark函数详解系列之RDD基本转换的更多相关文章
- ThinkPHP函数详解系列
为了能方便大家学习和掌握,在这里汇总下ThinkPHP中的经典函数用法 A 函数:实例化控制器R 函数:直接调用控制器的操作方法C 函数:设置和获取配置参数L 函数:设置和获取语言变量D 函数:实例化 ...
- spark wordcont Spark: sortBy和sortByKey函数详解
//统计单词top10def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("tst&q ...
- PHP输出缓存ob系列函数详解
PHP输出缓存ob系列函数详解 ob,输出缓冲区,是output buffering的简称,而不是output cache.ob用对了,是能对速度有一定的帮助,但是盲目的加上ob函数,只会增加CPU额 ...
- C++ list容器系列功能函数详解
C++ list函数详解 首先说下eclipse工具下怎样debug:方法:你先要设置好断点,然后以Debug方式启动你的应用程序,不要用run的方式,当程序运行到你的断点位置时就会停住,也会提示你进 ...
- Spark:常用transformation及action,spark算子详解
常用transformation及action介绍,spark算子详解 一.常用transformation介绍 1.1 transformation操作实例 二.常用action介绍 2.1 act ...
- JDBC详解系列(三)之建立连接(DriverManager.getConnection)
在JDBC详解系列(一)之流程中,我将数据库的连接分解成了六个步骤. JDBC流程: 第一步:加载Driver类,注册数据库驱动: 第二步:通过DriverManager,使用url,用户名和密码 ...
- Android高效率编码-第三方SDK详解系列(三)——JPush推送牵扯出来的江湖恩怨,XMPP实现推送,自定义客户端推送
Android高效率编码-第三方SDK详解系列(三)--JPush推送牵扯出来的江湖恩怨,XMPP实现推送,自定义客户端推送 很久没有更新第三方SDK这个系列了,所以更新一下这几天工作中使用到的推送, ...
- Spark参数详解 一(Spark1.6)
Spark参数详解 (Spark1.6) 参考文档:Spark官网 在Spark的web UI在"Environment"选项卡中列出Spark属性.这是一个很有用的地方,可以检查 ...
- 【转载】C语言itoa()函数和atoi()函数详解(整数转字符C实现)
本文转自: C语言itoa()函数和atoi()函数详解(整数转字符C实现) 介绍 C语言提供了几个标准库函数,可以将任意类型(整型.长整型.浮点型等)的数字转换为字符串. int/float to ...
随机推荐
- PhoneGap 和 PhoneGap Build 是什么?
PhoneGap是目前唯一支持7种平台的开源移动开发框架,支持的平台包括iOS.Android.BlackBerry OS.Palm WebOS.Windows Phone 7.Symbian和Bad ...
- Dynamics CRM 2016 使用Plug-in Trace Log调试插件
1.写插件 首先,让我们写一个简单的插件来测试新插件跟踪日志功能.请注意,在下面的示例代码中,我们增加ITracingService的一个实例,以及记录有关插件的执行信息记录的一些键值: 2.注册插件 ...
- DataBindings 与 INotifyPropertyChanged 实现自动刷新 WinForm 界面
--首发于博客园, 转载请保留此链接 博客原文地址 业务逻辑与界面的分离对于维护与迁移是非常重要的,在界面上给某属性赋值,后台要检测到其已经发生变化 问题: 输入某物品 单价 Price, 数量Am ...
- ASP.NET中过滤HTML字符串的两个方法
先记下来,以作备用! /// <summary>去除HTML标记 /// /// </summary> /// <param name="Htmlstring& ...
- Java数据结构漫谈-Stack
Stack(栈)是一种比较典型的数据结构,其元素满足后进先出(LIFO)的特点. Java中Stack的实现继承自Vector,所以其天然的具有了一些Vector的特点,所以栈也是线程安全的. cla ...
- cxf的使用及安全校验-02创建简单的客户端接口
上一篇文章中,我们已经讲了如果简单的创建一个webservice接口 http://www.cnblogs.com/snowstar123/p/3395568.html 现在我们创建一个简单客户端接口 ...
- C语言中的结构体和C++中的结构体以及C++中类的区别
c++中结构体可以定义一个函数 C中的结构体和C++中结构体的不同之处:在C中的结构体只能自定义数据类型,结构体中不允许有函数,而C++中的结构体可以加入成员函数. C++中的结构体和类的异同: 一. ...
- c++11-bind的用法
bind函数 在c++11之前,要绑定某个函数.函数对象或者成员函数的不同参数值需要用到不同的转换器,如bind1st.bind2nd.fun_ptr.mem_fun和mem_fun_ref等.在c+ ...
- freemarker中遍历list<map<String,String>>
<#list var as map><tr> <#list map?keys as itemKey> //关键点 <#if itemKey=" ...
- CSS的一些思考(一)
迈入前端行业已经8个多月了,从之前懵懵懂懂到现在的能根据设计图迅速成型页面,自我感觉良好.最近看到张大牛的一篇博客<说说CSS学习中的瓶颈>,突然意识到,自己不就处在快速学习和成长后的一个 ...