C++读入XML文件
最近要做一个VRP的算法,测试集都是放在Xml文件中,而我的算法使用C++来写,所以需要用C++来读取Xml文件。
在百度上搜“C++读取Xml文件”,可以出来很多博客,大多数是关于tinyXml的,所以这篇博文也是讲述如何用tinyXML来读取XML文件。
有些内容可能参考到了@marchtea的博文《C++读取XML,tinyXml的使用》:http://www.cnblogs.com/marchtea/archive/2012/11/08/2760593.html。
tinyXml是一个免费开源的C++库,可以到官网上下载:https://sourceforge.net/projects/tinyxml/。
下载下来解压之后,可以看到下面这些文件:
我是在windows下用VS来写C++的,按照@marchtea的说法,只需要直接打开tinyxml.sln就可以,不过我还是用了笨办法:
- 把tinystr.cpp, tinyxml.cpp, tinyxmlerror.cpp, tinyxmlparser.cpp, tinystr.h, tinyxml.h拷贝到工程目录下;
- 然后加入头文件引用:#include "tinystr.h" #include "tinyxml.h"。
接下来就来分享一下我读取VRP问题中的solomon benchmark的方法,这些方法都是参考自tinyXml的官方教程,在下载的文件夹中有"doc"子文件夹,打开它,有一个叫做"tutorial0"的html文件,打开它可以看到详细的教程。
OK,now begins!
我要读取的Xml文件有如下的格式(只列举部分):
<!-- 要读取的Xml文件 -->
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<instance>
<network>
<nodes>
<node id="0" type="0">
<cx>40.0</cx>
<cy>50.0</cy>
</node>
<!-- 有N+1个这样的node节点 -->
</nodes>
</network>
<requests>
<request id="1" node="1">
<tw>
<start>145</start>
<end>175</end>
</tw>
<quantity>20.0</quantity>
<service_time>10.0</service_time>
</request>
<!-- 有N个这样的request节点 -->
</requests>
</instance>
这里稍微解释一下为什么nodes节点的数目会比requests节点多1个。这是因为nodes节点包括了顾客节点(N个)和仓库节点(1个),而requests属性只属于顾客节点。
我是把xml文件中的这些数据读入到类对象数组中,每个类对象代表一个节点,类的定义如下:
// Customer.h
#ifndef _Customer_H
#define _Customer_H class Customer{
public:
Customer(int id=0, float x=0, float y=0, float startTime=0, float endTime=0, float quantity=0, float serviceTime=0);
void setId(int id); // 设置成员id的值
void setX(float x); // 设置成员x的值
void setY(float y); // 设置成员y的值
void setStartTime(float startTime); // 设置成员startTime的值
void setEndTime(float endTime); // 设置成员endTime的值
void setQuantity(float quantity); // 设置成员quantity的值
void setServiceTime(float serviceTime); // 设置成员serviceTime的值
void show(); // 显示顾客节点信息
private:
int id;
float x;
float y;
float startTime;
float endTime;
float quantity;
float serviceTime;
}; #endif
OK,那么现在开始贴一下main.cpp代码(Customer.cpp比较简单,就不贴了)
// main.cpp
#include "Customer.h"
#include "tinystr.h"
#include "tinyxml.h"
#include<iostream>
#include<vector>
#include<string>
#include<stdlib.h>
#include<iomanip> using namespace std;
static const int NUM_OF_CUSTOMER = 51; //顾客数量
static const char* FILENAME = "RC101_050.xml"; //文件名 int main(){
vector<Customer *> customerSet(0); // 顾客集,每个元素是Customer对象的指针
int i,j,k,count;
int temp1; // 存放整型数据
float temp2; // 存放浮点型数据
Customer* customer; // 临时顾客节点指针
for (i=0; i<NUM_OF_CUSTOMER; i++) { // 先初始化顾客集
customer = new Customer();
customerSet.push_back(customer);
}
TiXmlDocument doc(FILENAME); // 读入XML文件
if(!doc.LoadFile()) return -1; // 如果无法读取文件,则返回
TiXmlHandle hDoc(&doc); // hDoc是&doc指向的对象
TiXmlElement* pElem; // 指向元素的指针
pElem = hDoc.FirstChildElement().Element(); //指向根节点
TiXmlHandle hRoot(pElem); // hRoot是根节点 // 读取x,y,它们放在network->nodes->node节点中
TiXmlElement* nodeElem = hRoot.FirstChild("network").FirstChild("nodes").FirstChild("node").Element(); //当前指向了node节点
count = 0; // 记录移动到了哪个node节点,并且把该node节点的信息录入到顺序对应的customer中
for(nodeElem; nodeElem; nodeElem = nodeElem->NextSiblingElement()) { // 挨个读取node节点的信息
customer = customerSet[count]; // 当前顾客节点,注意不能赋值给一个新的对象,否则会调用复制构造函数
TiXmlHandle node(nodeElem); // nodeElem所指向的节点
TiXmlElement* xElem = node.FirstChild("cx").Element(); // cx节点
TiXmlElement* yElem = node.FirstChild("cy").Element(); // cy节点
nodeElem->QueryIntAttribute("id", &temp1); //把id放到temp1中,属性值读法
customer->setId(temp1);
temp2 = atof(xElem->GetText()); // char转float
customer->setX(temp2);
temp2 = atof(yElem->GetText());
customer->setY(temp2);
count++;
} // 读取其余信息
TiXmlElement* requestElem = hRoot.FirstChild("requests").FirstChild("request").Element(); // 指向了request节点
count = 1;
for(requestElem; requestElem; requestElem = requestElem->NextSiblingElement()) {
customer = customerSet[count]; // 当前顾客节点,注意不能赋值给一个新的对象,否则会调用复制构造函数
TiXmlHandle request(requestElem); // 指针指向的对象
TiXmlElement* startTimeElem = request.FirstChild("tw").FirstChild("start").Element(); // start time
TiXmlElement* endTimeElem = request.FirstChild("tw").FirstChild("end").Element(); // end time
TiXmlElement* quantityElem = request.FirstChild("quantity").Element(); // quantity
TiXmlElement* serviceTimeElem = request.FirstChild("service_time").Element(); // service time
// 分别读取各项数据
temp2 = atof(startTimeElem->GetText());
customer->setStartTime(temp2);
temp2 = atof(endTimeElem->GetText());
customer->setEndTime(temp2);
temp2 = atof(quantityElem->GetText());
customer->setQuantity(temp2);
temp2 = atof(serviceTimeElem->GetText());
customer->setServiceTime(temp2);
count++;
} // 将读取到的信息输出到控制台
cout<<setiosflags(ios_base::left)<<setw(6)<<"id"<<setw(6)<<"x"<<setw(6)<<
"y"<<setw(12)<<"startTime"<<setw(12)<<"endTime"<<setw(12)<<"quantity"<<setw(14)<<"serviceTime"<<endl;
for(i=0; i<NUM_OF_CUSTOMER; i++) {
customer = customerSet[i];
customer->show();
}
system("pause");
return 0;
}
在解释main.cpp的内容之前,先解释一下一些数据类型(只是个人理解,欢迎纠错):
- TiXmlDocument:文件节点,把Xml文件的内容读入到该类型变量中
- TiXmlElement*:指向节点的指针
- TiXmlHandle:节点的实例,也就是TiXmlElement所指向的对象
- FirstChild("nodeName"):第一个名字为“nodeName”的子节点
- NextSiblingElement():下一个兄弟节点元素,它们有相同的父节点
- QueryIntAttribute("attributeName", &var):把节点属性名为attributeName的属性值以int类型赋值给var变量
- GetText():获取当前节点元素的内容,即包含在<node>text</node>中的text
OK,有了以上一些简单的知识积累,就可以很方便地读取Xml文件了,现在截取xml的部分来讲解:
<instance>
<network>
<nodes>
<node id="0" type="0">
<cx>40.0</cx>
<cy>50.0</cy>
</node>
<!-- 有N+1个这样的node节点 -->
</nodes>
</network>
.....
</instance>
在这部分我们会把顾客的id,坐标x,y都读入到Customer对象中。
1. 首先我们得到了文件节点hDoc,现在我们要进入根节点"instance":
TiXmlElement* pElem; // 指向元素的指针
pElem = hDoc.FirstChildElement().Element(); //指向根节点
TiXmlHandle hRoot(pElem); // hRoot是根节点
根节点"instance"是文件节点的第一个子节点,所以用 pElem = hDoc.FirstChildElement().Element() 就可以使得指针pElem指向"instance",hRoot是pElem所指向的对象。
2. 现在我们需要进入到“node”节点中,遍历其兄弟节点,将所有数据读入。下面的语句可以将第一个“node”节点的指针赋值给nodeElem:
TiXmlElement* nodeElem = hRoot.FirstChild("network").FirstChild("nodes").FirstChild("node").Element(); //当前指向了node节点
节点的id值放在"node"节点的属性"id"中:
nodeElem->QueryIntAttribute("id", &temp1); //把id放到temp1中,属性值读法
然后坐标x, y的值放在“node”节点的子节点"cx"和"cy"的内容(text)中,所以我们这样来读取:
TiXmlElement* xElem = node.FirstChild("cx").Element(); // cx节点
temp2 = atof(xElem->GetText()); // char转float
函数atof在库<stdlib>中,用以将char数组转化为浮点数。
通过1,2两步,我们已经把第一个“node”节点的id, x, y的值读入到对象中,然后只需要把遍历所有的兄弟节点即可:
for(nodeElem; nodeElem; nodeElem = nodeElem->NextSiblingElement()) {
......
}
读入requests节点下的startTime, endTime, quantity, serviceTime等值的方法也是一样的,详情参考main.cpp代码。
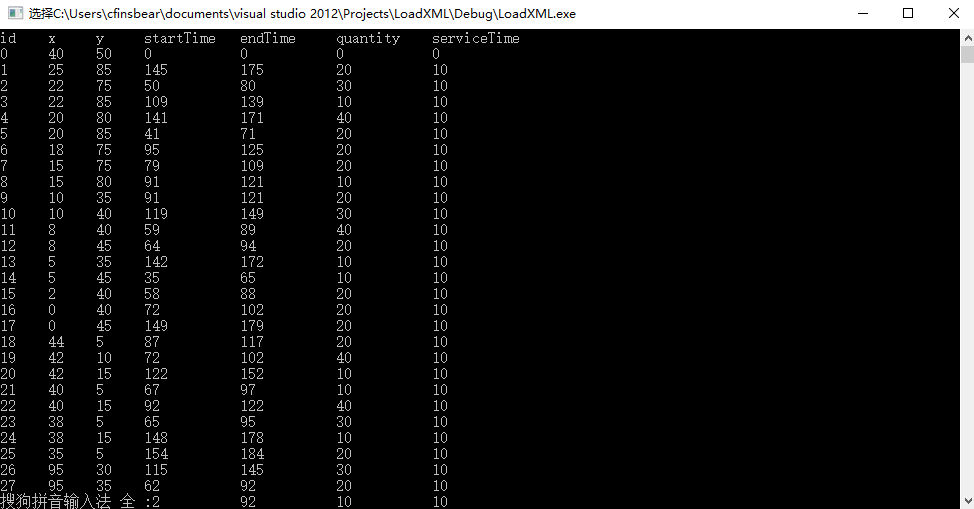
运行结果如下:
总结:
其实说白了读取Xml文件的关键在于:
- 移动指针到所要读取数据的节点中;
- 若是读取属性值,则使用QueryIntAttribute方法直接读取;
- 若读取的是节点的内容,则使用getText()方法读取;
- 连续的数据具有兄弟节点关系,使用NextSiblingElement()方法来指向下一个兄弟节点
后记:
这篇博文只介绍了如何读取Xml文件,至于如何写入Xml文件,请参考tinyXml的官方教程,讲的特别清楚,特别良心。
希望大家看了之后有所收获,欢迎交流。
C++读入XML文件的更多相关文章
- 将字符串以用二进制流的形式读入XML文件
其实将字符串写入XML文件本身并不复杂,这里只是写一些需要注意的地方,特别是编码格式,这里需要的是XML默认的编码方式是UTF-8,在对字符串进行编码的时候一定要注意, string strRecei ...
- 按行读入xml文件,删除不需要的行 -Java
删除挺麻烦的,这里其实只是把需要的行存到arraylist中再存到另一个文件中 import java.io.BufferedReader;import java.io.BufferedWriter; ...
- matlab xml文件交互
xml文件以文档对象模型表示,简称DOM(Document Object Model).在Matlab中,使用xmlread读取xml文件成DOM节点,对xml文件的操作转化成对DOM节点的操作,使用 ...
- DOM、SAX、JDOM、DOM4J以及PULL在XML文件解析中的工作原理以及优缺点对比
1. DOM(Document Object Model)文档对象模型1. DOM是W3C指定的一套规范标准,核心是按树形结构处理数据,DOM解析器读入XML文件并在内存中建立一个结构一模一样的&qu ...
- 使用SAXReader读取ftp服务器上的xml文件(原创)
根据项目需求,需要监测ftp服务器上的文件变化情况,并将新添加的文件读入项目系统(不需要下载). spring配置定时任务就不多说了,需要注意的一点就是,现在的项目很多都是通过maven构建的,分好多 ...
- Qt Write and Read XML File 读写XML文件
在Qt中,我们有时候需要把一些参数写入xml文件,方便以后可以读入,类似一种存档读档的操作,例如,我们想生成如下的xml文件: <?xml version="1.0" enc ...
- # java对xml文件的基本操作
下面是简单的总结三种常用的java对xml文件的操作 1. dom方式对xml进行操作,这种操作原理是将整个xml文档读入内存总,在内存中进行操作,当xml文档非常庞大的时候就会出现内存溢出的异常,这 ...
- 转:VC解析XML文件-CMarkup的使用详解
本篇文章是对VC解析XML文件-CMarkup的使用进行了详细的分析介绍,需要的朋友参考下 VC解析XML文件的工具有很多,CMarkup, tinyXML,还有IBM的,MS的等等. 据说tinyX ...
- NSXMLParser读取XML文件并将数据显示到TableView上
关于XML,有两种解析方式,分别是SAX(Simple API for XML,基于事件驱动的解析方式,逐行解析数据,采用协议回调机制)和DOM(Document Object Model ,文档对象 ...
随机推荐
- 3-HOP: A High-Compression Indexing Scheme for Reachability Query
title: 3-HOP: A High-Compression Indexing Scheme for Reachability Query venue: SIGMOD'09 author: Ruo ...
- NPOI读取Excel
项目环境:Webform framework4.0 dll版本:NPOI2.0 dotnet2.0版本 这两天要做个excel导入的功能,想到以前用过NPOI,感觉很给力,今天写了个DEMO,写的时 ...
- Amazon验证码机器算法识别
Amazon验证码识别 在破解Amazon的验证码的时候,利用机器学习得到验证码破解精度超过70%,主要是训练样本不够,如果在足够的样本下达到90%是非常有可能的. update后,样本数为2800多 ...
- 富文本编辑器防止xss注入javascript版
富文本编辑器:ueditor 其实富文本编辑器已经有防止xss注入功能,但是你服务端程序在接收的时候在做一次转义,否则有可能然后前端验证直接提交数据导致被xss攻击. 为了节省后端程序开销则在前端 显 ...
- C# Marshal.GetActiveObject() 遭遇 HRESULT:0x800401E3 (MK_E_UNAVAILABLE))
解决办法: 勿以管理员权限运行Visual Studio
- ecmobile-ios笔记
col或者row里的v-align:bottom会导致里面所有的元素都到bottom,如果有一个元素还好,多个元素,第一个会到底.
- VR定制开发、AR定制开发(长年承接虚拟现实、增强现实应用、VR游戏定制开发,北京公司,可签合同)
Cardboard SDK for Unity的使用 上一篇文章作为系列的开篇,主要是讲了一些虚拟现实的技术和原理,本篇就会带领大家去看一看谷歌的Cardboard SDK for Unity,虽然目 ...
- Install NukeX v7.0v6 in CentOS 7
- download THE_FOUNDRY_NUKEX_V7.0V6_LNX64-XFORCE - unzip and untar to /home/user0/tools/foundry/nuke ...
- IOS WebView修改contentInset 导致webview长按弹出菜单跳动的解决方法
最近在项目中需要用到webview 加载H5 并且在webview 底部使用原生UI添加其他空间比如广告.或者评论(Scrollview) 最初使用修改webview中scrollview 的cont ...
- Python第八天
Python面向对象进阶 一.静态方法 通过@staticmethod装饰器即可把其装饰的方法变为一个静态方法,什么是静态方法呢?其实不难理解,普通的方法,可以在实例化后直接调用,并且在方法里可以通过 ...