innoDB源码分析--缓冲池
最开始学Oracle的时候,有个概念叫SGA和PGA,是非常重要的概念,其实就是内存中的缓冲池。InnoDB的设计类似于Oracle,也会在内存中开辟一片缓冲池。众所周知,CPU的速度和磁盘的IO速度相差可以用鸿沟来形容,因此聪明的前辈们使用了内存这个ROM来弥补这道鸿沟,那么数据库的设计者们也继承了这个优良的设计理念,在内存中开辟了一片区域,存放缓冲数据,提高数据库效率。
可以将磁盘的缓冲区理解成一个简单的模型--由数据块组成的一片区域,数据块(block/page)默认大小是16KB。那么现在可以画出一个好理解的模型出来了:
这里的每一个格子都代表一个page。在代码里这个区域有两个关键的数据结构:buf_pool_struct和buf_block_struct。其中buf_pool_struct是缓冲池的数据结构,buf_block_struct是数据块的数据结构。
对于缓冲池的管理,InnoDB维护了一个free链表,该链表中记录了没有被使用的内存块,每次申请数据块都是要从free链表中取。但是,一般来说数据库的缓冲池都会比实际数据量小,因此缓冲池总有用完的一天,也就是说free链表的所有页都被分配完了,这个时候另一个数据结构开始发挥作用--LRU链表。
LRU是一个经典的算法,全称是最近最少使用(Lastest Least Used)。使用最频繁的页总是在链表的前面,而最后的页就是要被释放掉的页。然而InnoDB没有采用这种大路货,而是另辟蹊径的搞了个改进版的LRU,有人管他叫做midpoint LRU,是这样的:
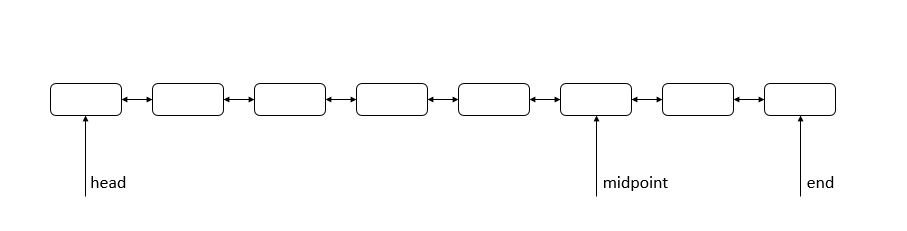
InnoDB的主要改进点在于每次将磁盘上读出的数据不是直接放到链表的头部,而是放在链表的3/8处(该值可配置),只有在下次访问该页时,才会将该页移动到链表头部。这样改进的原因在《MySQL内核--InnoDB存储引擎》一书中有论述(p250)。这个链表就被分为了两部分,midpoint前叫做young list,midpoint后叫做old list。链表尾部的数据块会被释放掉,buf_LRU_search_and_free_block函数会完成这个操作:
block = UT_LIST_GET_LAST(buf_pool->LRU);
while (block != NULL) {
ut_a(block->in_LRU_list);
mutex_enter(&block->mutex);
freed = buf_LRU_free_block(block);
mutex_exit(&block->mutex);
if (freed) {
break;
}
上面代码片段里体现了上面说的释放过程。
之前说的所有都是建立在一个假设上--free链表中的页分配完。那么数据库刚启动的时候,free链表有充足的页可以去分配,InnoDB是如何运作的呢?
buf_LRU_add_block函数的注释中明确写道,该函数用于将block加入LRU list中。因此任何将block加入LRU的操作都是该函数完成的,无论free链表是否还有页可以被分配。在查看这个函数的时候我注意到了一个常量:BUF_LRU_OLD_MIN_LEN。在5.1.73的代码里它被设置成80。该函数会判断block的young标记,在系统初始化时,这个函数会将所有的block置为young,并放在链表头部,直到LRU链表的长度大于等于BUF_LRU_OLD_MIN_LEN。
在LRU长度大于等于BUF_LRU_OLD_MIN_LEN之后,InnoDB会将LRU中所有的页置为old(buf_LRU_old_init),然后调用buf_LRU_old_adjust_len函数去调整位置,直到链表呈现上面的状态。下面是代码:
void
buf_LRU_old_adjust_len(void)
/*========================*/
{
ulint old_len;
ulint new_len; ut_a(buf_pool->LRU_old);
ut_ad(mutex_own(&(buf_pool->mutex)));
ut_ad( * (BUF_LRU_OLD_MIN_LEN / ) > BUF_LRU_OLD_TOLERANCE + ); for (;;) {
old_len = buf_pool->LRU_old_len;
new_len = * (UT_LIST_GET_LEN(buf_pool->LRU) / ); ut_a(buf_pool->LRU_old->in_LRU_list); /* Update the LRU_old pointer if necessary */ if (old_len < new_len - BUF_LRU_OLD_TOLERANCE) { buf_pool->LRU_old = UT_LIST_GET_PREV(
LRU, buf_pool->LRU_old);
(buf_pool->LRU_old)->old = TRUE;
buf_pool->LRU_old_len++; } else if (old_len > new_len + BUF_LRU_OLD_TOLERANCE) { (buf_pool->LRU_old)->old = FALSE;
buf_pool->LRU_old = UT_LIST_GET_NEXT(
LRU, buf_pool->LRU_old);
buf_pool->LRU_old_len--;
} else {
ut_a(buf_pool->LRU_old); /* Check that we did not
fall out of the LRU list */
return;
}
}
}
可以看出来,函数采用了一个无条件循环不停地移动buf_pool->LRU_old的位置,直到满足了条件。
至于LRU链表的插入操作,其实很简单,就是每次将新插入的页放置到buf_pool->LRU_old的next位置,以后再次访问该数据页的时候,调用buf_LRU_make_block_young函数将其移动到链表的头部。
UT_LIST_INSERT_AFTER(LRU, buf_pool->LRU, buf_pool->LRU_old,
block);
UT_LIST_INSERT_AFTER的注释里写的很明白:Inserts a NODE2 after NODE1 in a list. 这里的node1是指buf_pool->LRU_old,node2是指block。而buf_LRU_make_block_young函数中关键的一步:
UT_LIST_ADD_FIRST(LRU, buf_pool->LRU, block);
UT_LIST_ADD_FIRST的注释里这么写道:Adds the node as the first element in a two-way linked list.
至此基本上了解了一个数据页是如何被读取到内存中的。总结一下,从启动开始的过程如下:
1 系统初始化时,free链表中的所有页都可以被分配。
2 有数据请求的时候,将从磁盘读取到的block放入LRU链表中,该操作直接将所有的block置为young并插入链表头部,直到LRU长度达到BUF_LRU_OLD_MIN_LEN。
3 当LRU长度达到BUF_LRU_OLD_MIN_LEN时,InnoDB会做如下操作:
3.1 将所有的LRU块都置为old(buf_LRU_old_init)
3.2 调度buf_LRU_old_adjust_len函数,将buf_pool->LRU_old调整到合适的位置。
4 之后,每次有新的页要插入LRU时,调度buf_LRU_add_block函数,并将old标记为true,将该页插入到buf_pool->LRU_old的next位置
5 若第四步中的数据页再次被访问,InnoDB调度buf_LRU_make_block_young函数将该页放到LRU链表头部。
6 free链表分配完,此时需要从LRU尾部寻找可以释放的block,该操作由buf_LRU_search_and_free_block执行。
tips:
这里需要注意一点,LRU链表尾部的block确实可以被释放,但是要满足两个前提:页不是脏的;页没有被其他线程使用。因为脏页总是要刷新到磁盘的,所以当脏页要被替换的时候,需要首先将其刷入磁盘中。用于释放尾部block的函数buf_LRU_free_block中有一个约束:
if (!buf_flush_ready_for_replace(block)) {
return(FALSE);
}
如果该页不满足条件,就会返回false,那么这个时候,buf_LRU_search_and_free_block函数就会继续寻找尾部block的上一个block:
block = UT_LIST_GET_PREV(LRU, block)
然后继续判断该block是否能被释放。完整的代码如下,我自己加了部分注释:
ibool
buf_LRU_search_and_free_block(
/*==========================*/
/* out: TRUE if freed */
ulint n_iterations) /* in: how many times this has been called
repeatedly without result: a high value means
that we should search farther; if value is
k < 10, then we only search k/10 * [number
of pages in the buffer pool] from the end
of the LRU list */
{
buf_block_t* block;
ulint distance = ;
ibool freed; mutex_enter(&(buf_pool->mutex)); freed = FALSE;
block = UT_LIST_GET_LAST(buf_pool->LRU); while (block != NULL) {
ut_a(block->in_LRU_list); mutex_enter(&block->mutex);
freed = buf_LRU_free_block(block); //该函数会首先判断block能否被释放
mutex_exit(&block->mutex); if (freed) { //如果上面判断页不能被释放,这里的循环就不能跳出
break;
} block = UT_LIST_GET_PREV(LRU, block); //尾部的页不能被释放,寻找其前面的block,继续循环
distance++; if (!freed && n_iterations <=
&& distance > + (n_iterations * buf_pool->curr_size)
/ ) {
buf_pool->LRU_flush_ended = ; mutex_exit(&(buf_pool->mutex)); return(FALSE);
}
}
if (buf_pool->LRU_flush_ended > ) {
buf_pool->LRU_flush_ended--;
}
if (!freed) {
buf_pool->LRU_flush_ended = ;
}
mutex_exit(&(buf_pool->mutex)); return(freed);
}
这两天都在看InnoDB的缓冲池源码,暂时来说只有这一点收获。这里使用的C语言虽然超过了我的认识水平(我基本上只能看懂简单的C代码,有指针勉强能懂),但是加上注释和参考资料,还是感觉比简单的看文档要来的痛快的多。
http://www.cnblogs.com/wingsless/p/5571292.html
innoDB源码分析--缓冲池的更多相关文章
- InnoDB源码分析--缓冲池(三)
转载请附原文链接:http://www.cnblogs.com/wingsless/p/5582063.html 昨天写到了InnoDB缓冲池的预读:<InnoDB源码分析--缓冲池(二)> ...
- InnoDB源码分析--缓冲池(二)
转载请附原文链接:http://www.cnblogs.com/wingsless/p/5578727.html 上一篇中我简单的分析了一下InnoDB缓冲池LRU算法的相关源码,其实说不上是分析,应 ...
- InnoDB源码分析--事务日志(一)
原创文章,转载请注明原文链接(http://www.cnblogs.com/wingsless/p/5705314.html) 在之前的文章<InnoDB的WAL方式学习>(http:// ...
- innodb 源码分析 --锁
innodb引擎中的锁分两种 1)针对数据结构, 如链表 互斥锁 读写锁 http://mysqllover.com/?p=425 http://www.cnblogs.com/justfortast ...
- InnoDB源码分析--事务日志(二)
原创文章,转载请标明原文链接:http://www.cnblogs.com/wingsless/p/5708992.html 昨天写了有关事务日志的一些基本点(http://www.cnblogs.c ...
- MySQL系列:innodb源码分析之内存管理
http://blog.csdn.net/yuanrxdu/article/details/40985363 http://book.2cto.com/201402/40307.html 从MySQL ...
- MySQL系列:innodb源码分析 图 ---zerok的专栏
http://blog.csdn.net/yuanrxdu/article/details/40985363
- 设计模式(十二)——享元模式(Integer缓冲池源码分析)
1 展示网站项目需求 小型的外包项目,给客户 A 做一个产品展示网站,客户 A 的朋友感觉效果不错,也希望做这样的产品展示网站,但是要求都有些不同: 1) 有客户要求以新闻的形式发布 2) 有客户人要 ...
- MySQL源码分析以及目录结构 2
原文地址:MySQL源码分析以及目录结构作者:jacky民工 主要模块及数据流经过多年的发展,mysql的主要模块已经稳定,基本不会有大的修改.本文将对MySQL的整体架构及重要目录进行讲述. 源码结 ...
随机推荐
- 改变 TMemo 的背景颜色 (Firemonkey)
说明:展示使用程序码改变 Firemonkey TMemo 的背景颜色. 适用:XE6 源码下载:[原創]Memo改背景色_XE6.zip //---------------------------- ...
- 优秀的技术Leader
在一个"情怀"已经泛滥的年代里,任何拿着"情怀"出来说事的人都不太受待见.犀利者会吐槽:"我早已看穿了一切". 但你是否想过,如果这世界所有 ...
- python验证登录
一个web2.0时代的网站,自然少不了用户注册,登录,验证的功能,那么python可以怎样实现登录验证呢 这里我们使用装饰器来做登录验证 网站构成 假设我们有这样一个网站,是一个类似与博客园这种多个用 ...
- ahjesus自定义隐式转换和显示转换
implicit 关键字用于声明隐式的用户定义类型转换运算符. 如果可以确保转换过程不会造成数据丢失,则可使用该关键字在用户定义类型和其他类型之间进行隐式转换. 参考戳此 explicit ...
- js undefine,null 和NaN
undefined 类型只有一个值,即 undefined. null 类型也只有一个值,即 null. null 指空值(empty value)或指曾赋过值,但是目前没有值 undefined 指 ...
- opencart二次开发小记
在controller中如果要调用model中数据或说方法可以这样写 $this->load->model('catalog/information');//model中的informat ...
- [小北De编程手记] : Lesson 01 玩转 xUnit.Net 之 概述
谈到单元测试,任何一个开发或是测试人员都不会觉得陌生.我想大多数的同学也都是接触过各种单元测试框架.关于单元测试的重要性,应该不会有太多的质疑.这个系列,我向大家介绍一下xUnit.Net的使用.就让 ...
- servletcontext监听器的启动位置以及tomcat和eclipse的目录结构
情景: 想在应用启动的时候就加载spring容器 在ServletContextListener.contextInitialized()中加载spring容器 ApplicationContext ...
- 过去几个月出炉的30款最喜欢的 jQuery 插件
在这篇文章中,我们收集了一些在过去的几个月里最喜欢的 jQuery 插件.为了使您更容易搜索到自己喜欢的 jQuery 插件,我们已经对插件进行了分类: 页面布局插件,图片和视频插件,滑块和画廊,排版 ...
- js之如何获取css样式
js之如何获取css样式 一.获取内联样式 1 <div id ="myDiv" style="width:100px;height:100px; border ...