11.经典O(n²)比较型排序算法
关注公号「码哥字节」修炼技术内功心法,完整代码可跳转 GitHub:https://github.com/UniqueDong/algorithms.git
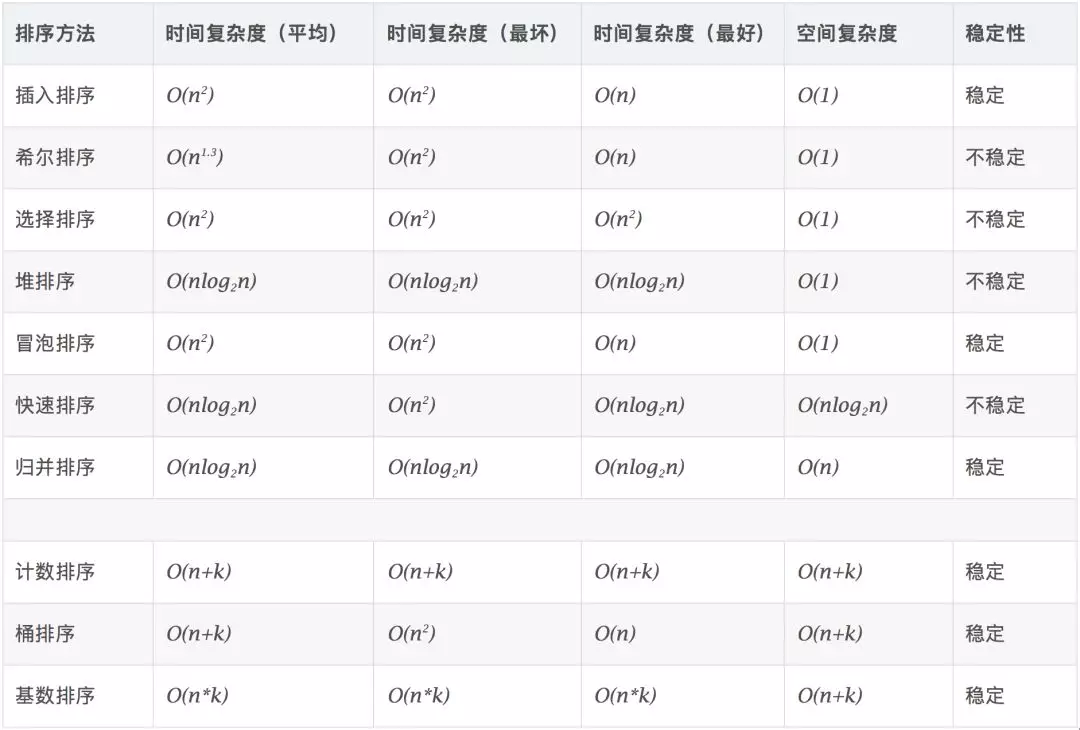
摘要:排序算法提多了,很多甚至连名字你都没听过,比如猴子排序、睡眠排序等。最常用的:冒泡排序、选择排序、插入排序、归并排序、快速排序、计数排序、基数排序、桶排序。根据时间复杂度,我们分三类来学习,今天要讲的就是 冒泡、插入、选择 排序算法。
| 排序算法 | 时间复杂度 | 是否基于比较 |
|---|---|---|
| 冒泡、插入、选择 | O(n²) | 是 |
| 快排、归并 | O(nlogn) | 是 |
| 桶、计数、基数 | O(n) | 否 |
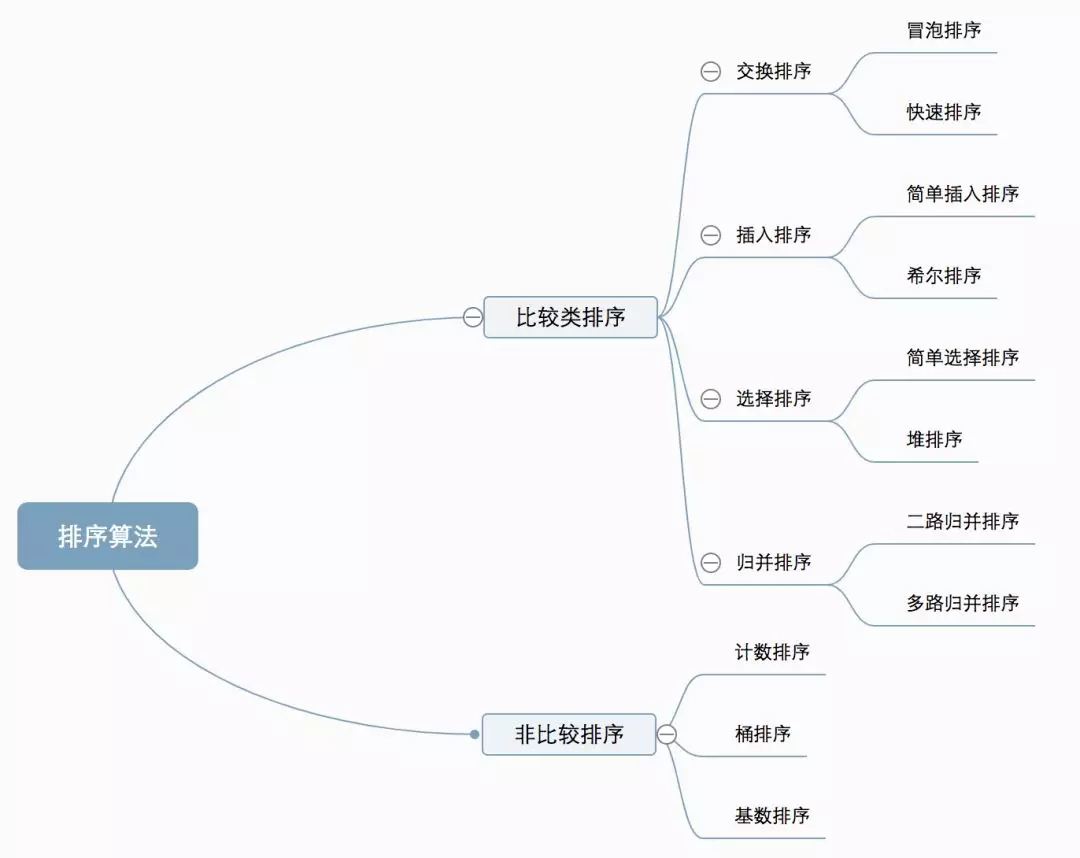
十种常见的的排序算法可以分两大类:
- 比较类排序:通过比较来决定元素的相对次序,由于其时间复杂度无法突破 O(nlogn),因此也叫做非线性时间排序。
- 非比较类排序:不是通过比较元素来决定元素的相对次序,可以突破比较排序的时间下限,线性时间运行,也叫做线性时间非比较类排序。
学会评估一个排序算法
学习算法,除了知道原理以及代码实现以外,还有更重要的是学会如何评价、分析一个排序算法的 执行效率、内存损耗、稳定性。
执行效率
一般通过如下方面衡量:
1.最好、最坏、平均时间复杂度
为何要区分这三种时间复杂度?第一,通过复杂度可以大致判断算法的执行次数。第二,对于要排序的数据有的无序、有的接近有序,有序度不同不同对于执行时间是不一样的,所以我们要只掉不同数据场景下算法的性能。
2. 时间复杂度的系数、常数、低阶
我们知道,时间复杂度反应的是数据规模 n 很大的时候的一个增长趋势,所以它表示的时候会忽略系数、常数、低阶。但是实际的软件开发中,我们排序的可能是 10 个、100 个、1000 个这样规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。
3.比较次数移动(交换)数据次数
基于比较排序的算法执行过程都会涉及两个操作、一个是比较,另一个就是元素交换或者数据移动。所以我们也要把数据交换或者移动次数考虑进来。
内存消耗
算法的内存消耗通过空间复杂度来衡量,不过在这里针对排序算法的内存算好还有一个新概念,原地排序就是特指空间复杂度为 O(1) 的算法,这次所讲的算法都是原地排序算法。
算法的稳定性
如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。** 比如 a 原本在 b 前面,而 a=b ,排序之后 a 仍然在 b 的前面。
比如我们有一组数据 2,9,3,4,8,3,按照大小排序之后就是 2,3,3,4,8,9。
这组数据里有两个 3。经过某种排序算法排序之后,如果两个 3 的前后顺序没有改变,那我们就把这种排序算法叫作稳定的排序算法;如果前后顺序发生变化,那对应的排序算法就叫作不稳定的排序算法。
冒泡排序
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
作为最简单的排序算法之一,冒泡排序给我的感觉就像 Abandon 在单词书里出现的感觉一样,每次都在第一页第一位,所以最熟悉。冒泡排序还有一种优化算法,就是立一个 flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来说并没有什么太大作用。
算法步骤
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
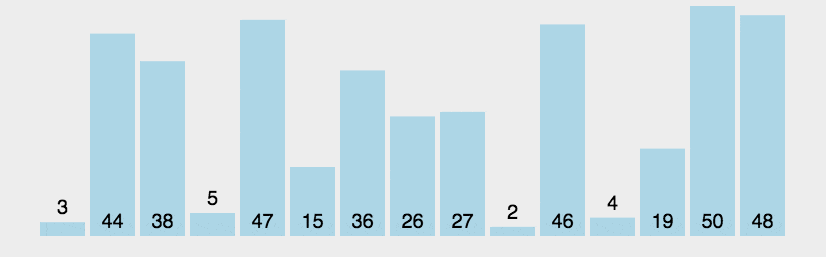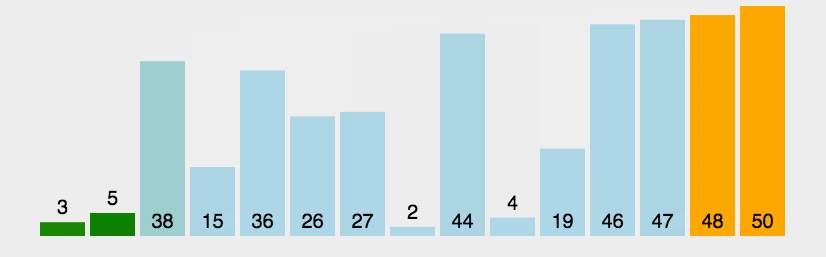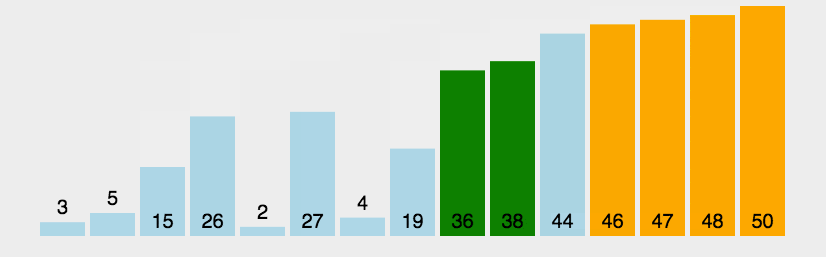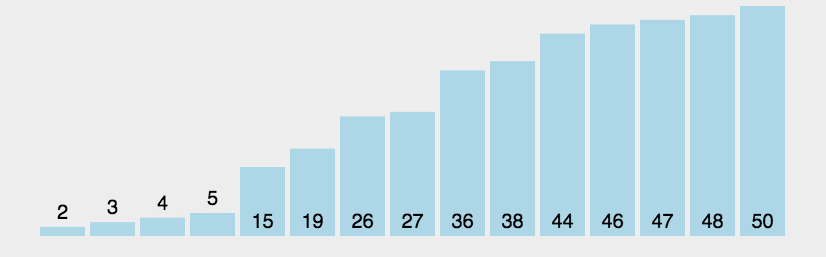
/**
* 冒泡排序: 时间复杂度 O(n²),最坏时间复杂度 O(n²),最好时间复杂度 O(n),平均时间复杂度 O(n²)
* 空间复杂度 O(1),稳定排序算法
*/
public class BubbleSort implements ComparisonSort {
@Override
public int[] sort(int[] sourceArray) {
// 复制数组,不改变参数内容
int[] result = Arrays.copyOf(sourceArray, sourceArray.length);
if (sourceArray.length <= 1) {
return result;
}
int length = result.length;
for (int i = 0; i < length; i++) {
// 设定标记,当没有数据需要交换的时候则说明已经有序,提前退出外部循环
boolean hasChange = false;
for (int j = 0; j < (length - 1) - i ; j++) {
if (result[j] > result[j + 1]) {
// 数据交换
int temp = result[j];
result[j] = result[j + 1];
result[j + 1] = temp;
hasChange = true;
}
}
if (!hasChange) {
// 没有数据交换,已经有序,提前退出
break;
}
}
return result;
}
}
那么问题来了,我们来分析下这个算法的效率如何,教大家学会如何评估一个算法:
1.冒泡是原地排序算法么?
因为冒泡的过程只有相邻数据的交换操作,属于常量级别的临时空间,所以空间复杂度是 O(1),属于原地排序算法。
2.是稳定排序算法?
只有交换才改变两个元素的前后顺序,当相邻数据相等,不做交换,所以相同大小的数据在排序前后都不会改变顺序,属于稳定排序算法。
3.时间复杂度
最好时间复杂度:当数据已经有序,只需要一次冒泡,所以是 O(1)。(ps:都已经是正序了,还要你冒泡何用)
最坏时间复杂度: 数据是倒序的,我们需要进行 n 次冒泡操作,所以最坏情况时间复杂度为 O(n2)。(ps:写一个 for 循环反序输出数据不就行了,干嘛要用你冒泡排序呢,我是闲的吗)
插入排序
我们先来看一个问题。一个有序的数组,我们往里面添加一个新的数据后,如何继续保持数据有序呢?很简单,我们只要遍历数组,找到数据应该插入的位置将其插入即可。
插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
插入排序也包含两种操作,一种是元素的比较,一种是元素的移动。当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入。
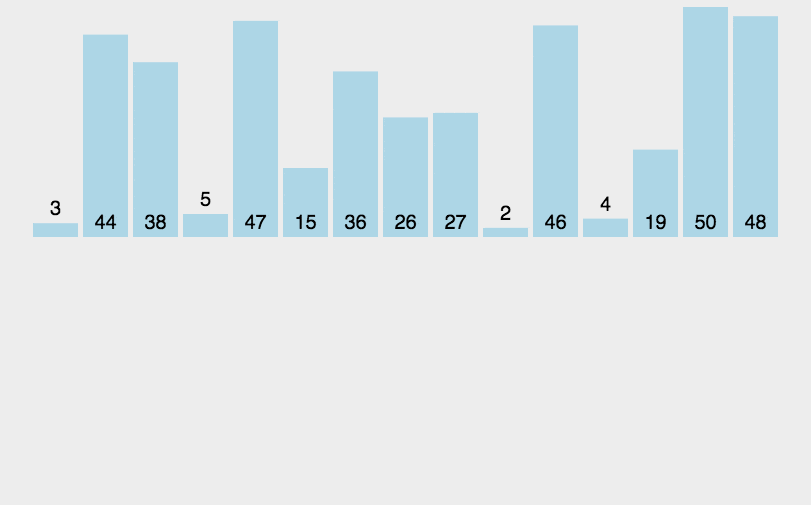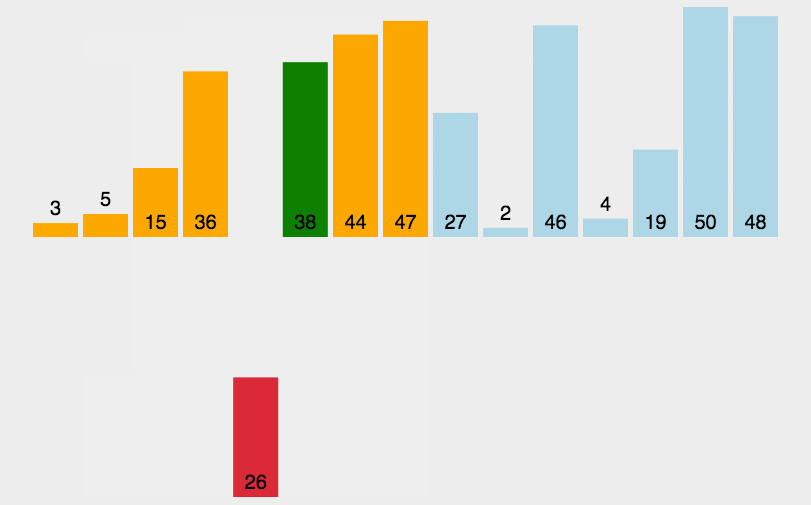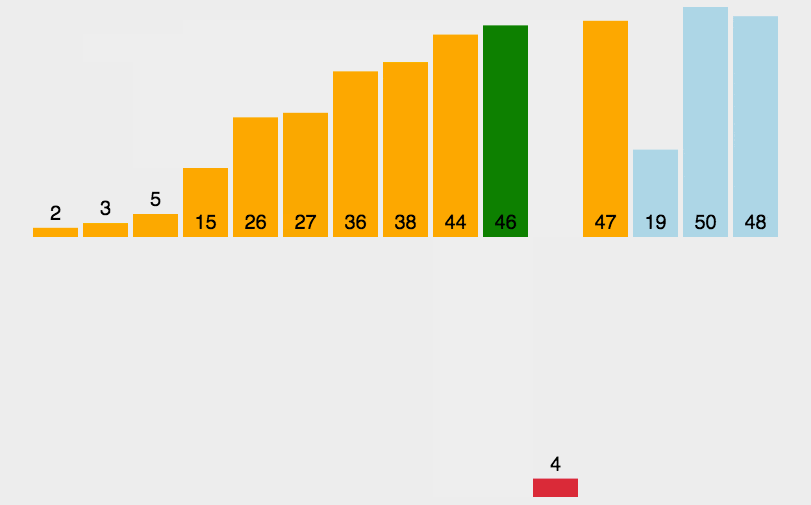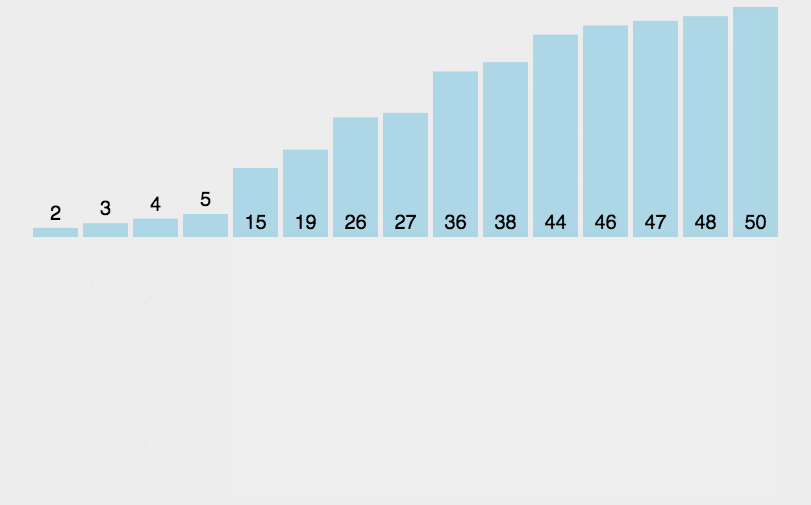
代码如下所示:
/**
* 插入排序:时间复杂度 O(n²),平均时间复杂度 O(n²),最好时间复杂度 O(n),
* 最坏时间复杂度 O(n²),空间时间复杂度 O(1).稳定排序算法。
*/
public class InsertionSort implements ComparisonSort {
@Override
public int[] sort(int[] sourceArray) {
int[] result = Arrays.copyOf(sourceArray, sourceArray.length);
if (sourceArray.length <= 1) {
return result;
}
// 从下标为 1 开始比较选择合适位置插入,因为下标 0 只有一个元素,默认是有序
int length = result.length;
for (int i = 1; i < length; i++) {
// 待插入数据
int insertValue = result[i];
// 从已排序的序列最右边元素开始比较,找到比待插入树更小的数位置
int j = i - 1;
for (; j >= 0; j--){
if (result[j] > insertValue) {
// 向后移动数据,腾出待插入位置
result[j + 1] = result[j];
} else {
// 找到待插入位置,跳出循环
break;
}
}
// 插入数据,因为前面多执行了 j--,
result[j + 1] = insertValue;
}
return result;
}
}
依然继续分析该算法的性能。
1.是否是原地排序算法
从实现过程就知道,插入排序不需要额外的存储空间,所以空间复杂度是 O(1),属于原地排序。
2.是否是稳定排序算法
对于值相等的元素,我们选择将数据插入到前面元素的侯娜,这样就保证原有的前后顺序不变,属于稳定排序算法。
3.时间复杂度
如果要排序的数据已经是有序的,我们并不需要搬移任何数据。如果我们从尾到头在有序数据组里面查找插入位置,每次只需要比较一个数据就能确定插入的位置。所以这种情况下,最好是时间复杂度为 O(n)。注意,这里是从尾到头遍历已经有序的数据。
如果数组是倒序的,每次插入都相当于在数组的第一个位置插入新的数据,所以需要移动大量的数据,所以最坏情况时间复杂度为 O(n²)。
还记得我们在数组中插入一个数据的平均时间复杂度是多少吗?没错,是 O(n)。所以,对于插入排序来说,每次插入操作都相当于在数组中插入一个数据,循环执行 n 次插入操作,所以平均时间复杂度为 O(n²)。
选择排序
选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n²) 的时间复杂度。所以用到它的时候,数据规模越小越好。
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
算法步骤
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
代码如下:
public class SelectionSort implements ComparisonSort {
@Override
public int[] sort(int[] sourceArray) {
int length = sourceArray.length;
int[] result = Arrays.copyOf(sourceArray, length);
if (length <= 0) {
return result;
}
// 一共需要 length - 1 轮比较
for (int i = 0; i < length - 1; i++) {
// 每轮需要比较的次数 length - i,找出最小元素下标
int minIndex = i;
for (int j = i + 1; j < length; j++) {
if (result[j] < result[minIndex]) {
// 查出每次最小远元素下标
minIndex = j;
}
}
// 将当前 i 位置的数据与最小值交换数据
if (i != minIndex) {
int temp = result[i];
result[i] = result[minIndex];
result[minIndex] = temp;
}
}
return result;
}
}
首先,选择排序空间复杂度为 O(1),是一种原地排序算法。选择排序的最好情况时间复杂度、最坏情况和平均情况时间复杂度都为 O(n²)。
那选择排序是稳定的排序算法吗?
答案是否定的,选择排序是一种不稳定的排序算法。从我前面画的那张图中,你可以看出来,选择排序每次都要找剩余未排序元素中的最小值,并和前面的元素交换位置,这样破坏了稳定性。
比如 5,8,5,2,9 这样一组数据,使用选择排序算法来排序的话,第一次找到最小元素 2,与第一个 5 交换位置,那第一个 5 和中间的 5 顺序就变了,所以就不稳定了。正是因此,相对于冒泡排序和插入排序,选择排序就稍微逊色了。
总结
这三种时间复杂度为 O(n²) 的排序算法中,冒泡排序、选择排序,可能就纯粹停留在理论的层面了,学习的目的也只是为了开拓思维,实际开发中应用并不多,但是插入排序还是挺有用的。后面讲排序优化的时候,我会讲到,有些编程语言中的排序函数的实现原理会用到插入排序算法。(希尔排序就是插入排序的一种优化)
今天讲的这三种排序算法,实现代码都非常简单,对于小规模数据的排序,用起来非常高效。但是在大规模数据排序的时候,这个时间复杂度还是稍微有点高,所以我们更倾向于用下一节要讲的时间复杂度为 O(nlogn) 的排序算法。
课后思考
最后给大家一个问题,答案可在后台发送 「插入」获取答案,也可以加群跟我们一起讨论。
问题是:插入排序和冒泡排序时间复杂度相同,都是 O(n²),实际开发中更倾向于插入排序而不是冒泡排序

11.经典O(n²)比较型排序算法的更多相关文章
- 常用排序算法的Java实现与分析
由于需要分析算法的最好时间复杂度和最坏时间复杂度,因此这篇文章中写的排序都是从小到大的升序排序. 带排序的数组为arr,arr的长度为N.时间复杂度使用TC表示,额外空间复杂度使用SC表示. 好多代码 ...
- Java循环语句怎么用?经典排序算法见真知
Java中循环语句的使用,莫过于在排序算法中使用得最为经典. 排序算法非常的多,不过大体可以分为两种: 一种是比较排序,主要有:冒泡排序,选择排序,插入排序,归并排序,堆排序,快速排序等. 另一种是非 ...
- Java数据结构和算法(三):常用排序算法与经典题型
常用的八种排序算法 1.直接插入排序 我们经常会到这样一类排序问题:把新的数据插入到已经排好的数据列中.将第一个数和第二个数排序,然后构成一个有序序列将第三个数插入进去,构成一个新的有序序列.对第四个 ...
- JavaScript 数据结构与算法之美 - 十大经典排序算法汇总(图文并茂)
1. 前言 算法为王. 想学好前端,先练好内功,内功不行,就算招式练的再花哨,终究成不了高手:只有内功深厚者,前端之路才会走得更远. 笔者写的 JavaScript 数据结构与算法之美 系列用的语言是 ...
- 五种C语言非数值计算的常用经典排序算法
摘要:排序是计算机的一种操作方法,其目的是将一组"无序"的记录序列调整为"有序"的记录序列,主要分为内部排序和外部排序. 排序 排序是计算机的一种操作方法,其目 ...
- python基础__十大经典排序算法
用Python实现十大经典排序算法! 排序算法是<数据结构与算法>中最基本的算法之一.排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大, ...
- 基于python的七种经典排序算法
参考书目:<大话数据结构> 一.排序的基本概念和分类 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法. ...
- 经典排序算法总结与实现 ---python
原文:http://wuchong.me/blog/2014/02/09/algorithm-sort-summary/ 经典排序算法在面试中占有很大的比重,也是基础,为了未雨绸缪,在寒假里整理并用P ...
- C# 经典排序算法大全
C# 经典排序算法大全 选择排序 using System; using System.Collections.Generic; using System.Linq; using System.Tex ...
随机推荐
- urldecode二次编码
0x01 <?php if(eregi("hackerDJ",$_GET[id])) { echo("not allowed!"); exit(); } ...
- AFNetworking 3.0 使用详解 和 源码解析实现原理
AFN原理&& AFN如何使用RunLoop来实现的: 让你介绍一下AFN源码的理解,首先要说说封装里面主要做了那些重要的事情,有那些重要的类(XY题) 一.AFN的实现步骤: NSS ...
- android LoaderManger加载数据Tip
要查看LoaderManager的具体介绍请看博客: LoaderManager介绍 使用时发现不管怎么调用getLoaderManager().restartLoader(LOADER_TYPE_Q ...
- SpringMVC中参数的传递(一)
前言 1.首先,我们在web.xml里面配置前端控制器DispatcherServlet以及字符编码过滤器(防止中文乱码),配置如下: <?xml version="1.0" ...
- python-经典类和新式类区别
经典类和新式类区别 Eg: class A(object): def x(self): print('A')class B(A): def x(self): p ...
- 9.5 Go 依赖管理
9.5 Go 依赖管理 godep是解决包依赖的管理工具,目前最主流的一种,原理是扫描记录版本控制的信息. A. 所有的第三方包都放在$GOPATH的src目录下. B. 如果不同程序依赖的版本不一样 ...
- MYSQL LOCK IN SHARE MODE&FOR UPDATE
SELECT ... LOCK IN SHARE MODE sets a shared mode lock on the rows read. A shared mode lock enables o ...
- Istio-架构
读书笔记整理 工作机制:分为控制面和数据面 控制面:Pilot, Mixer(接收来自Envoy上报的数据), Citadel(证书和密钥管理) 数据面:Envoy 工作流程: 自动注入 应用程序启动 ...
- JavaScript实现栈结构
参考资料 一.什么是栈(stack)? 1.1.简介 首先我们需要知道数组是一种线性结构,并且可以在数组的任意位置插入和删除数据,而栈(stack)是一种受限的线性结构.以上可能比较难以理解,什么是受 ...
- CSS3新子代选择器
:nth-child(n) 选择器匹配属于其父元素的第 N 个子元素,不论元素的类型,除了<h>标签. n 可以是数字.关键词或公式 例子一 <!DOCTYPE html> & ...