数据源管理 | Kafka集群环境搭建,消息存储机制详解
本文源码:GitHub·点这里 || GitEE·点这里
一、Kafka集群环境
1、环境版本
版本:kafka2.11,zookeeper3.4
注意:这里zookeeper3.4也是基于集群模式部署。
2、解压重命名
tar -zxvf kafka_2.11-0.11.0.0.tgz
mv kafka_2.11-0.11.0.0 kafka2.11
创建日志目录
[root@en-master kafka2.11]# mkdir logs
注意:以上操作需要同步到集群下其他服务上。
3、添加环境变量
vim /etc/profile
export KAFKA_HOME=/opt/kafka2.11
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
4、修改核心配置
[root@en-master /opt/kafka2.11/config]# vim server.properties
-- 核心修改如下
# 唯一编号
broker.id=0
# 开启topic删除
delete.topic.enable=true
# 日志地址
log.dirs=/opt/kafka2.11/logs
# zk集群
zookeeper.connect=zk01:2181,zk02:2181,zk03:2181
注意:broker.id安装集群服务个数编排即可,集群下不能重复。
5、启动kafka集群
# 启动命令
[root@node02 kafka2.11]# bin/kafka-server-start.sh -daemon config/server.properties
# 停止命令
[root@node02 kafka2.11]# bin/kafka-server-stop.sh
# 进程查看
[root@node02 kafka2.11]# jps
注意:这里默认启动了zookeeper集群服务,并且集群下的kafka分别启动。
6、基础管理命令
创建topic
bin/kafka-topics.sh --zookeeper zk01:2181 \
--create --replication-factor 3 --partitions 1 --topic one-topic
参数说明:
- replication-factor 定义副本个数
- partitions 定义分区个数
- topic:定义topic名称
查看topic列表
bin/kafka-topics.sh --zookeeper zk01:2181 --list
修改topic分区
bin/kafka-topics.sh --zookeeper zk01:2181 --alter --topic one-topic --partitions 5
查看topic
bin/kafka-topics.sh --zookeeper zk01:2181 \
--describe --topic one-topic
发送消息
bin/kafka-console-producer.sh \
--broker-list 192.168.72.133:9092 --topic one-topic
消费消息
bin/kafka-console-consumer.sh \
--bootstrap-server 192.168.72.133:9092 --from-beginning --topic one-topic
删除topic
bin/kafka-topics.sh --zookeeper zk01:2181 \
--delete --topic first
7、Zk集群用处
Kafka集群中有一个broker会被选举为Controller,Controller依赖Zookeeper环境,管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
二、消息拦截案例
1、拦截器简介
Kafka中间件的Producer拦截器主要用于实现消息发送的自定义控制逻辑。用户可以在消息发送前以及回调逻辑执行前有机会对消息做一些自定义,比如消息修改等,发送状态监控等,用户可以指定多个拦截器按顺序执行拦截。
核心方法
- configure:获取配置信息和初始化数据时调用;
- onSend:消息被序列化以及和计算分区前调用该方法,可以对消息做操作;
- onAcknowledgement:消息发送到Broker之后,或发送过程失败时调用;
- close:关闭拦截器调用,执行一些资源清理工作;
注意:这里说的拦截器是针对消息发送流程。
2、自定义拦截
定义方式:实现ProducerInterceptor接口即可。
拦截器一:在onSend方法中,对拦截的消息进行修改。
@Component
public class SendStartInterceptor implements ProducerInterceptor<String, String> {
private final Logger LOGGER = LoggerFactory.getLogger("SendStartInterceptor");
@Override
public void configure(Map<String, ?> configs) {
LOGGER.info("configs...");
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 修改消息内容
return new ProducerRecord<>(record.topic(), record.partition(),
record.timestamp(), record.key(),
"onSend:{" + record.value()+"}");
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
LOGGER.info("onAcknowledgement...");
}
@Override
public void close() {
LOGGER.info("SendStart close...");
}
}
拦截器二:在onAcknowledgement方法中,判断消息是否发送成功。
@Component
public class SendOverInterceptor implements ProducerInterceptor<String, String> {
private final Logger LOGGER = LoggerFactory.getLogger("SendOverInterceptor");
@Override
public void configure(Map<String, ?> configs) {
LOGGER.info("configs...");
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
LOGGER.info("record...{}", record.value());
return record ;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (exception != null){
LOGGER.info("Send Fail...exe-msg",exception.getMessage());
}
LOGGER.info("Send success...");
}
@Override
public void close() {
LOGGER.info("SendOver close...");
}
}
加载拦截器:基于一个KafkaProducer配置Bean,加入拦截器。
@Configuration
public class KafkaConfig {
@Bean
public Producer producer (){
Properties props = new Properties();
// 省略其他配置...
// 添加拦截器
List<String> interceptors = new ArrayList<>();
interceptors.add("com.kafka.cluster.interceptor.SendStartInterceptor");
interceptors.add("com.kafka.cluster.interceptor.SendOverInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
return new KafkaProducer<>(props) ;
}
}
3、代码案例
@RestController
public class SendMsgWeb {
@Resource
private KafkaProducer<String,String> producer ;
@GetMapping("/sendMsg")
public String sendMsg (){
producer.send(new ProducerRecord<>("one-topic", "msgKey", "msgValue"));
return "success" ;
}
}
基于上述自定义Bean类型,进行消息发送,关注拦截器中打印日志信息。
三、Kafka存储分析
说明:该过程基于上述案例producer.send方法追踪的源码执行流程,源码中的过程相对清楚,涉及的核心流程如下。
1、消息生成过程
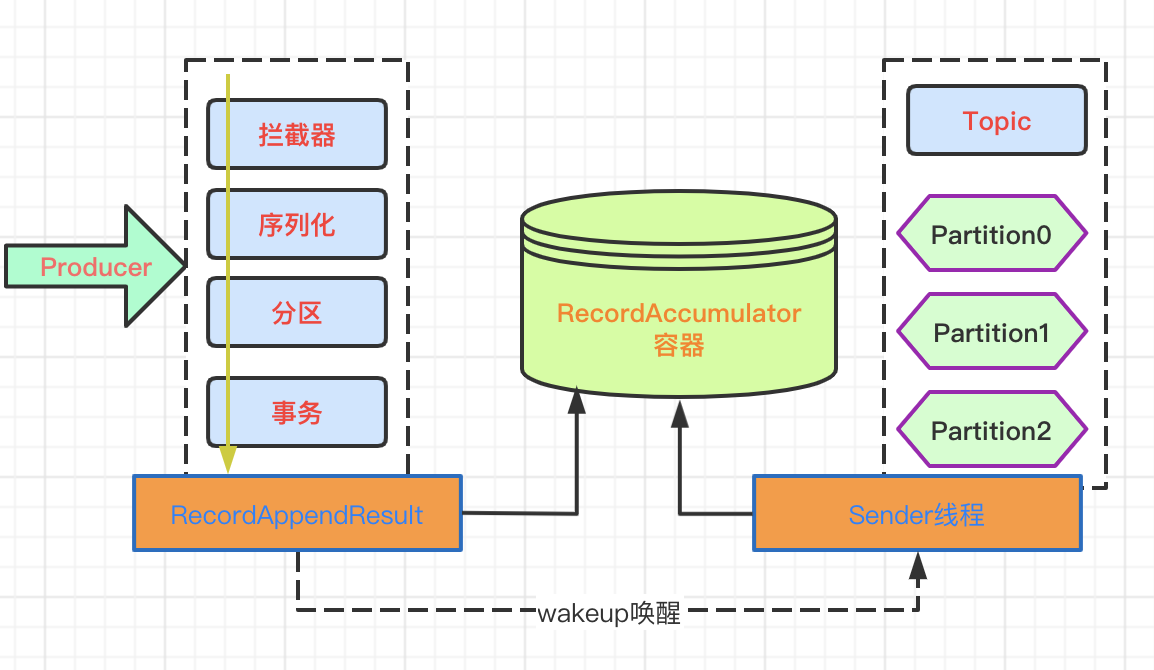
Producer发送消息采用的是异步发送的方式,消息发送过程如下:
- Producer发送消息之后,经过拦截器,序列化,事务判断;
- 流程执行后,消息内容放入容器中;
- 容器在指定时间内如果装满(size),会唤醒Sender线程;
- 容器如果在指定时间内没有装满,也会执行一次Sender线程唤醒;
- 唤醒Sender线程之后,把容器数据拉取到topic中;
絮叨一句:读这些中间件的源码,不仅能开阔思维,也会让自己意识到平时写的代码可能真的叫搬砖。
2、存储机制
Kafka中消息是以topic进行标识分类,生产者面向topic生产消息,topic分区(partition)是物理上的存储,基于消息日志文件的方式。
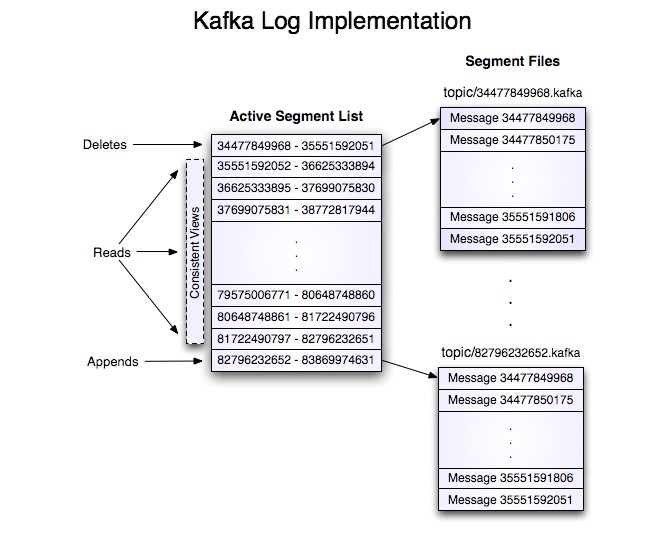
- 每个partition对应于一个log文件,发送的消息不断追加到该log文件末端;
- log文件中存储的就是producer生产的消息数据,采用分片和索引机制;
- partition分为多个segment。每个segment对应两个(.index)和(.log)文件;
- index文件类型存储的索引信息;
- log文件存储消息的数据;
- 索引文件中的元数据指向对应数据文件中message的物理偏移地址;
- 消费者组中的每个消费者,都会实时记录消费的消息offset位置;
- 当然消息消费出错时,恢复是从上次的记录位置继续消费;
3、事务控制机制
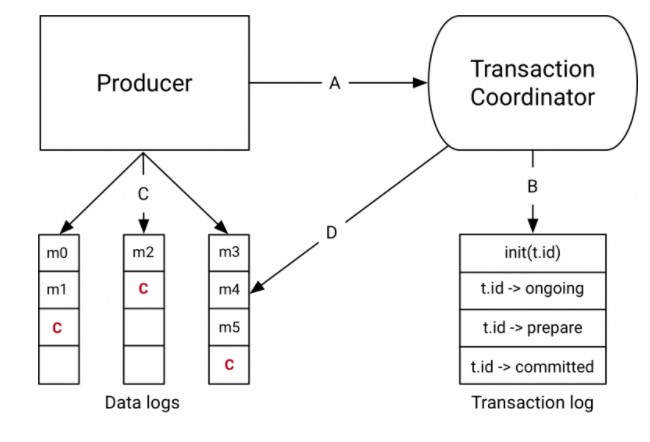
Kafka支持消息的事务控制
Producer事务
跨分区跨会话的事务原理,引入全局唯一的TransactionID,并将Producer获得的PID和TransactionID绑定。Producer重启后可以通过正在进行的TransactionID获得原来的PID。
Kafka基于TransactionCoordinator组件管理Transaction,Producer通过和TransactionCoordinator交互获得TransactionID对应的任务状态。TransactionCoordinator将事务状态写入Kafka的内部Topic,即使整个服务重启,进行中的事务状态可以得到恢复。
Consumer事务
Consumer消息消费,事务的保证强度很低,无法保证消息被精确消费,因为同一事务的消息可能会出现重启后已经被删除的情况。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent

推荐关联阅读:数据源管理系列
数据源管理 | Kafka集群环境搭建,消息存储机制详解的更多相关文章
- kafka 集群环境搭建 java
简单记录下kafka集群环境搭建过程, 用来做备忘录 安装 第一步: 点击官网下载地址 http://kafka.apache.org/downloads.html 下载最新安装包 第二步: 解压 t ...
- 大数据 -- zookeeper和kafka集群环境搭建
一 运行环境 从阿里云申请三台云服务器,这里我使用了两个不同的阿里云账号去申请云服务器.我们配置三台主机名分别为zy1,zy2,zy3. 我们通过阿里云可以获取主机的公网ip地址,如下: 通过secu ...
- Kafka集群环境搭建
Kafka是一个分布式.可分区.可复制的消息系统.Kafka将消息以topic为单位进行归纳:Kafka发布消息的程序称为producer,也叫生产者:Kafka预订topics并消费消息的程序称为c ...
- kafka集群环境搭建(Linux)
一.准备工作 centos6.8和jvm需要准备64位的,如果为32位,服务启动的时候报java.lang.OutOfMemoryError: Map failed 的错误. 链接:http://pa ...
- Kafka集群环境搭建(2.9.2-0.8.2.2)
Kafka是一个分布式.可分区.可复制的消息系统.Kafka将消息以topic为单位进行归纳:Kafka发布消息的程序称为producer,也叫生产者:Kafka预订topics并消费消息的程序称为c ...
- Ubuntu下kafka集群环境搭建及测试
kafka介绍: Kafka[1是一种高吞吐量[2] 的分布式发布订阅消息系统,有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能 ...
- 【Kafka】Kafka集群环境搭建
目录 一.初始环境准备 二.下载安装包并上传解压 三.修改配置文件 四.启动ZooKeeper 五.启动Kafka集群 一.初始环境准备 必须安装了JDK和ZooKeeper,并保证Zookeeper ...
- 深入剖析Redis系列: Redis集群模式搭建与原理详解
前言 在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态.Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 ...
- java架构之路-(分布式zookeeper)zookeeper集群配置和选举机制详解
上次博客我们说了一下zookeeper的配置文件,以及命令的使用https://www.cnblogs.com/cxiaocai/p/11597465.html.我们这次来说一下我们的zookeepe ...
随机推荐
- 手把手教你用Python网络爬虫获取网易云音乐歌曲
前天给大家分享了用Python网络爬虫爬取了网易云歌词,在文尾说要爬取网易云歌曲,今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将 ...
- webpack指南(三)缓存
缓存 把 /dist 目录中的内容部署到服务器上,客户端(通常是浏览器)就能够访问网站此服务器的网站及其资源.而通过网络获取资源是比较耗时的,这就是为什么浏览器要使用缓存这种技术.可以通过命中缓存,以 ...
- 函数的不同调用方式决定了this的指向不同
一.函数的不同调用方式决定了this的指向不同,一般指向调用者 1.普通函数 this指向window的调用者 function fn(){ console.l ...
- HDU6440 Dream
题目链接:https://vjudge.net/problem/HDU-6440 知识点: 构造.费马小定理 题目大意: 给定一个素数 $p$,要求定义一个加法运算表和一个乘法运算表,尺寸都为 $p ...
- 不可不知的 7 个 JDK 命令
这篇文章主要来介绍下 JDK 内置的命令,话不多说,让我们开始吧! javap 使用 javap 可以查看 Java 字节码反编译的源文件,javap 的命令格式如下: 下面来演示下用 javap - ...
- Java获取主板序列号、MAC地址、CPU序列号工具类
import java.io.File; import java.io.FileWriter; import java.io.BufferedReader; import java.io.IOExce ...
- [Objective-C] 019_UIVIewController
UIViewController是iOS程序中的一个重要组成部分,对应MVC设计模式的C,它管理着程序中的众多视图,何时加载视图,视图何时消,界面的旋转等. 1.UIViewController 创建 ...
- Python 每日一练 | Flask 实现半成品留言板
留言板Flask实现 引言 看了几天网上的代码,终于写出来一个半成品的Flask的留言板项目,为什么说是半成品呢?因为没能实现留言板那种及时评论刷新的效果,可能还是在重定向上有问题 或者渲染写的存在问 ...
- 06 . Python3入门之IO编程(文件操作)
IO编程简介 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口 ...
- leetcode976之三角形最大周长
题目描述: 给定由一些正数(代表长度)组成的数组 A,返回由其中三个长度组成的.面积不为零的三角形的最大周长. 如果不能形成任何面积不为零的三角形,返回 0. def largePara(A): A. ...