5.使用Redis+Flask维护动态Cookies池
1.为什么要用Cookies池?
- 网站需要登录才可爬取,例如新浪微博
- 爬取过程中如果频率过高会导致封号
- 需要维护多个账号的Cookies池实现大规模爬取
2.Cookies池的要求
- 自动登录更新
- 定时验证筛选
- 提供外部接
3.Cookies池架构
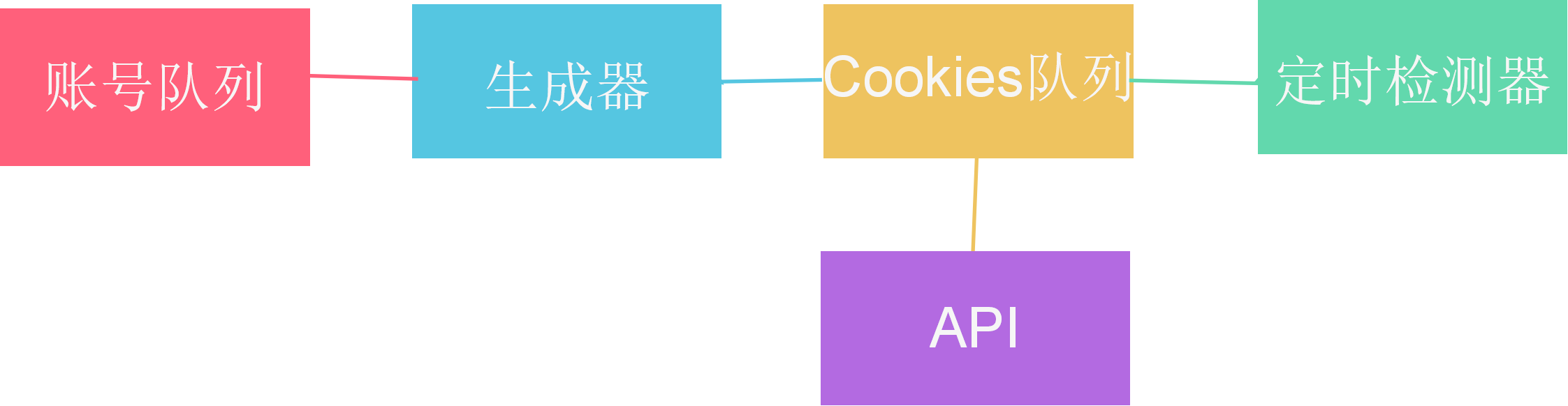
4.github上下载cookie池维护的代码
https://github.com/Germey/CookiesPool
()安装
pip3 install -r requirements.txt ()基础配置
修改cookiespool/config.py ()数据库配置
account:weibo:账号
cookies:weibo:账号 Value分别为密码和Cookies 账号自行某宝购买 Redis连接信息到cookiespool/config文件修改 ()云打码平台配置
到yundama.com注册开发者和普通用户。
开发者申请应用ID和KEY,普通用户用于充值登录。
配置信息到cookiespool/config文件修改 ()进程开关
配置信息到cookiespool/config文件修改 ()运行
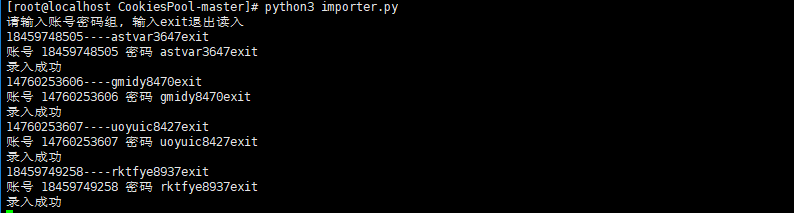
python3 run.py ()批量导入
python3 importer.py 请输入账号密码组, 输入exit退出读入
----astvar3647
----gmidy8470
----uoyuic8427
----rktfye8937
账号 密码 astvar3647
录入成功
账号 密码 gmidy8470
录入成功
账号 密码 uoyuic8427
录入成功
账号 密码 rktfye8937
录入成功
exit
5.修改配置文件
C:\software\phpStudy\PHPTutorial\WWW\python3\maoyantop100\CookiesPool-master\cookiespool\config.py
# Redis数据库地址
REDIS_HOST = '192.168.33.12' # Redis端口
REDIS_PORT = # Redis密码,如无填None
REDIS_PASSWORD = '' # 配置信息,无需修改
REDIS_DOMAIN = '*'
REDIS_NAME = '*' # 云打码相关配置到yundama.com申请注册
YUNDAMA_USERNAME = '*****'
YUNDAMA_PASSWORD = '*****'
YUNDAMA_APP_ID = ''
YUNDAMA_APP_KEY = '1b586a30bfda5c7fa71c881075ba49d0' YUNDAMA_API_URL = 'http://api.yundama.com/api.php' # 云打码最大尝试次数
YUNDAMA_MAX_RETRY = # 产生器默认使用的浏览器
DEFAULT_BROWSER = 'PhantomJS' # 'Chrome' # 产生器类,如扩展其他站点,请在此配置
GENERATOR_MAP = {
'weibo': 'WeiboCookiesGenerator'
} # 测试类,如扩展其他站点,请在此配置
TESTER_MAP = {
'weibo': 'WeiboValidTester'
} # 产生器和验证器循环周期
CYCLE = # API地址和端口
API_HOST = '127.0.0.1'
API_PORT = # 进程开关
# 产生器,模拟登录添加Cookies
GENERATOR_PROCESS = True
# 验证器,循环检测数据库中Cookies是否可用,不可用删除
VALID_PROCESS = False
# API接口服务
API_PROCESS = True
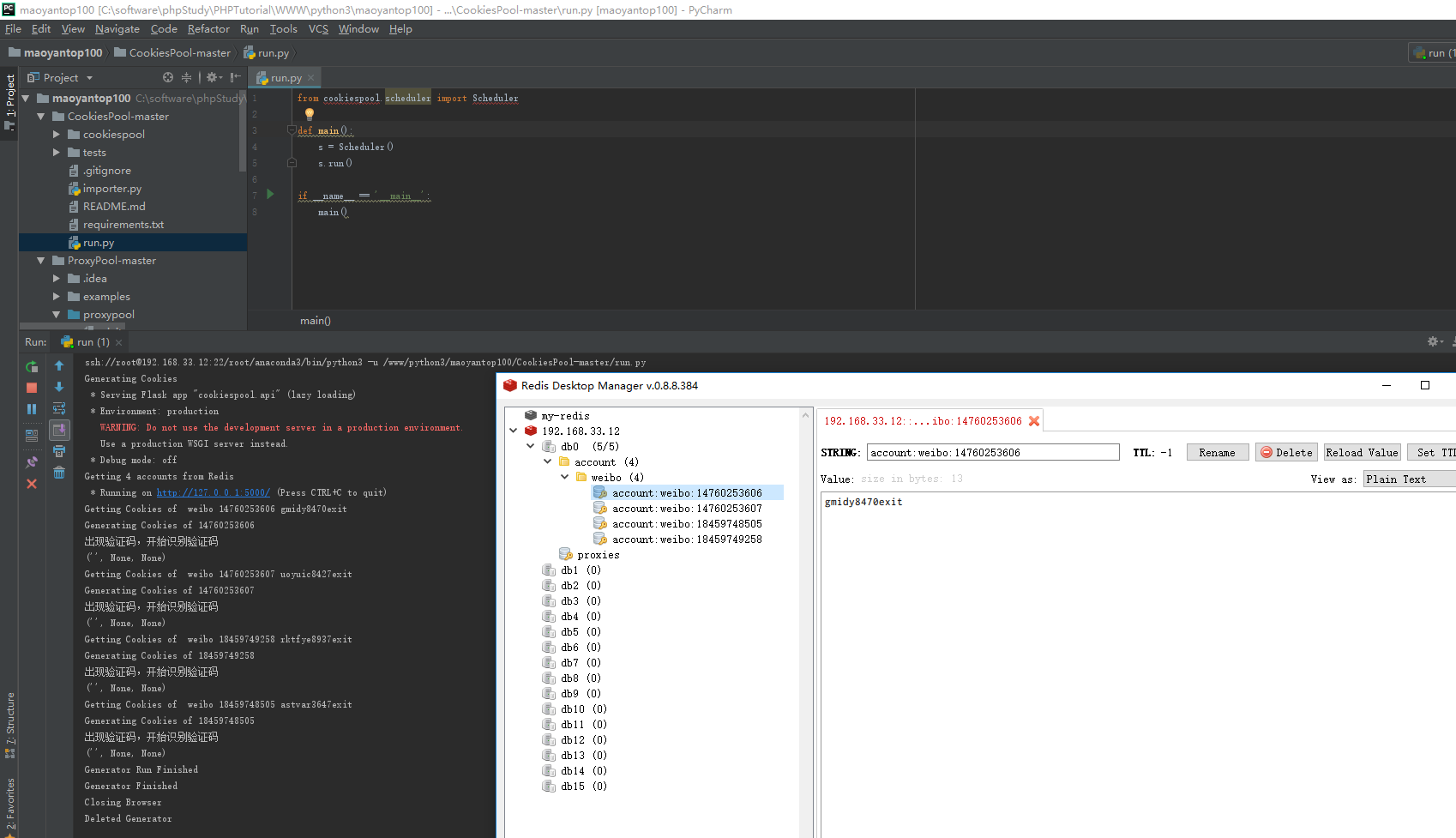
6.运行项目
5.使用Redis+Flask维护动态Cookies池的更多相关文章
- 4.使用Redis+Flask维护动态代理池
1.为什么使用代理池 许多⽹网站有专⻔门的反爬⾍虫措施,可能遇到封IP等问题. 互联⽹网上公开了了⼤大量量免费代理理,利利⽤用好资源. 通过定时的检测维护同样可以得到多个可⽤用代理理. 2.代理池的要 ...
- 转载:使用redis+flask维护动态代理池
githu源码地址:https://github.com/Germey/ProxyPool更好的代理池维护:https://github.com/Python3WebSpider/ProxyPool ...
- 使用redis+flask维护动态代理池
在进行网络爬虫时,会经常有封ip的现象.可以使用代理池来进行代理ip的处理. 代理池的要求:多站抓取,异步检测.定时筛选,持续更新.提供接口,易于提取. 代理池架构:获取器,过滤器,代理队列,定时检测 ...
- 使用redis所维护的代理池抓取微信文章
搜狗搜索可以直接搜索微信文章,本次就是利用搜狗搜搜出微信文章,获得详细的文章url来得到文章的信息.并把我们感兴趣的内容存入到mongodb中. 因为搜狗搜索微信文章的反爬虫比较强,经常封IP,所以要 ...
- 利用 Flask+Redis 维护 IP 代理池
代理池的维护 目前有很多网站提供免费代理,而且种类齐全,比如各个地区.各个匿名级别的都有,不过质量实在不敢恭维,毕竟都是免费公开的,可能一个代理无数个人在用也说不定.所以我们需要做的是大量抓取这些免费 ...
- 爬虫技术:cookies池的维护
一:为什么要维护cookie 1.登录才能爬取内容 2.爬取频繁会被封号. 3.需要维护多个账号的cookie,实现大规模抓取 二:cookies的要求 1.自动登录更新 2.定期筛选验证 3.提供外 ...
- 小白进阶之Scrapy(基于Scrapy-Redis的分布式以及cookies池)
首先我们更新一下scrapy版本.最新版为1.3 再说一遍Windows的小伙伴儿 pip是装不上Scrapy的.推荐使用anaconda .不然还是老老实实用Linux吧. conda instal ...
- Server-side Sessions with Redis | Flask (A Python Microframework)
Server-side Sessions with Redis | Flask (A Python Microframework) Server-side Sessions with Redis By ...
- Redis 简单使用 and 连接池(python)
Redis 简介 NoSQL(not only sql):非关系型数据库 支持 key-value, list, set, zset, hash 等数据结构的存储:支持主从数据备份,集群:支持 ...
随机推荐
- java 多线程并发问题
问题:50个线程,先查询数据库的一个记录 t,然后对这个记录+1,最后更新到数据库 (更新的时候,不允许使用 update test_concurrent set sum =sum -1 where ...
- opencv python:图像金字塔
图像金字塔原理 expand = 扩大+卷积 拉普拉斯金字塔 PyrDown:降采样 PyrUp:还原 example import cv2 as cv import numpy as np # 图像 ...
- java ArrayList添加元素全部一样
#开始 今天遇到了一个很神奇的事情 也即是我在用ArrayList的add方法循环加入对象的时候 发现添加的元素全部都是一样的 定位错误定位了一个下午.... 错误位置就是哪一个位置 但是就是不知道为 ...
- dropLoad.js移动端分页----Vue数据每次清空累加
dropLoad.js移动端使用 1.需要引入 dropload 必要的两个文件dropload.css .dropload.min.js 此案例在vue项目中使用过程: var vm = ne ...
- 异常的jvm(java虚拟机)与异常处理try catch与throwable
- 6.Python字符串
#header { display: none !important; } } #header-spacer { width: 100%; visibility: hidden; } @media p ...
- 忘记linux下的mysql密码,需要重新创建密码123456
你必须要有操作系统的root权限了. # mysqld_safe --skip-grant-tables & &,表示在后台运行,不再后台运行的话,就再打开一个终端咯. # mysql ...
- 【代码审计】VAuditDemo 前台搜索功能反射型XSS
在 search.php中 $_GET['search']未经过任何过滤就被输出 可能存在反射型XSS
- PyQt5窗口操作大全
1.多窗口交互-使用信号与槽函数'''如果一个窗口和一个窗口交互,尽量不要访问窗口B的控件:应该访问与信号绑定的槽函数,从而降低窗口之间的耦合度 例:如果A直接访问B窗口的控件,一旦B窗口的控件发生改 ...
- docker环境下mysql数据库的备份
#! /bin/bash DATE=`date +%Y%m%d%H%M%S` BACK_DATA=erp-${DATE}.sql #导出表结构,不包括表数据 #docker exec -i xin-m ...