正则表达式(grep,awk,sed)和通配符
1. 正则表达式
1. 什么是正则表达式?
正则表达式就是为了处理大量的字符串而定义的一套规则和方法。
通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串。
Linux正则表达式一般以 行 为单位处理。
2. 为什么要学会正则表达式?
工作中会有大量带有字符串的文本配置、程序、命令输出及日志文件等,我们经常会有迫切的需要,从大量的字符串内容中查找符合工作需要的特定的字符串。
这就需要正则表达式。
正则表达式就是为了过滤这样的字符串需求而诞生的。
3. 容易混淆的两个注意事项
正则表达式应用非常广泛,存在于各种语言中,例如:php, python, java等。
- Linux系统运维工作中的正则表达式,即Linux正则表达式,最常应用正则表达式的命令就是grep(egrep),sed,awk,换句话说Linux三剑客要想能工作的更高效,那一定离不开正则表达式配合的。
- 正则表达式和我们常用的通配符特殊字符是有本质区别的。
- 通配符例子:ls *.log 这里的*就是通配符(表示所有),而不是正则表达式。
注意事项:
- linux正则表达式一般以 行 为单位处理
- alias grep='grep --color=auto',让匹配的内容显示颜色
- 注意字符集,export LC_ALL=C
4. 正则表达式实战
实战准备:
- 设置grep别名:颜色自动
[root@oldboy test]# alias grep='grep --color=auto'
[root@oldboy test]# alias grep
alias grep='grep --color=auto'
- 加载LC_ALL=C,设置字符集
[root@oldboy test]# export LC_ALL=C
[root@oldboy test]# echo $LC_ALL
C
- 文本准备:
[root@oldboy test]# cat >>oldboy.log<<EOF
> I am oldboy teacher!
> I teach Linux.
>
> I like badminton ball, billiard ball and chinese chess!
> my blog is http://oldboy.blog.51cto.com
> our site is http://www.etiantian.org
> my qq is 49000448.
>
> not 49000000448
> my god, I am not oldboy,but OLDBOY!
> EOF
基础正则第一波字符说明:
- ^ 以...开头
- ^d 以d开头
- ^word 匹配以word开头的内容
- 在vi/vim编辑器里,^代表一行的开头
- $ 以...结尾
- word$ 匹配以word结尾的内容
- 在vi/vim编辑器里,$代表一行的结尾
- ^$ 表示空行
示例1:
以m开头的行(内容):grep '^m' oldboy.log
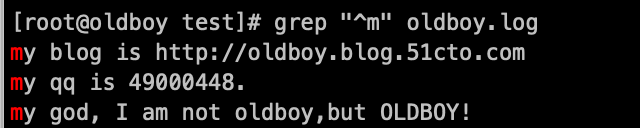
以m为结尾的行(内容 ):grep 'm$' oldboy.log

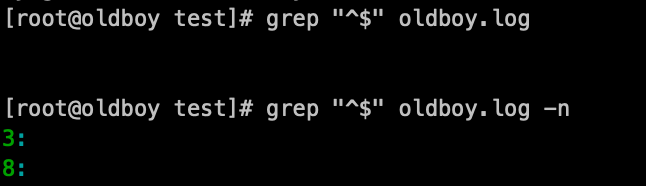
空行,通过-n参数定位到具体的行号:grep '^$' oldboy.log
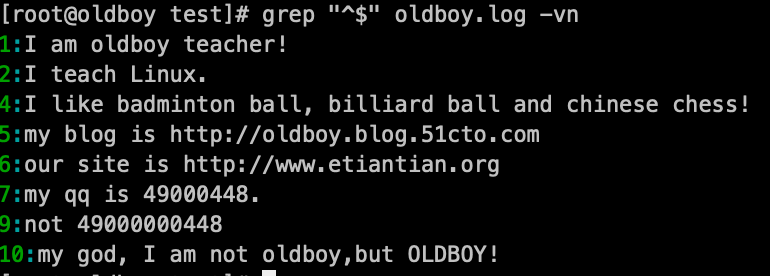
用-v参数,排除空行:grep -v '^$' oldboy.log
基础正则第二波字符说明:
- . 代表且只能代表任意一个字符
- \ 转义符号
- 让特殊符号代表其本身
- * 重复0个或多个前面的一个字符
- 例如:o* 匹配,没有"o",有1个"o",或多个"o"
- .* 匹配所有字符
- 延伸:
- ^.*以任意多个字符开头
- .*$ 以任意多个字符结尾
- 延伸:
点(.)的含义小结:
- 当前目录
- 使得文件生效,相当于source
- 隐藏文件
- 任意一个字符(grep 正则)
示例:
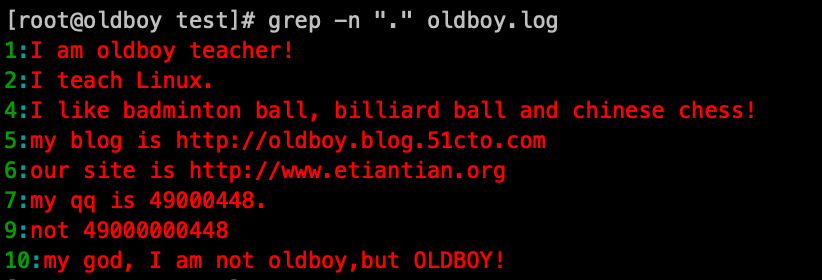
1. 筛选任意一个字符的一行,空行没有字符,所以过滤排除掉了
grep -n '.' oldboy.log
2. "oldb.y"表示"oldb"任意一个字符"y"(不匹配大小写):grep -n 'oldb.y' oldboy.log

3. -i 参数,匹配大小写: grep -ni 'oldb.y' oldboy.log

4. 匹配以"."结尾的行: grep -ni '\.$' oldboy.log

5. 匹配所有:".*": grep '.*' oldboy.log -ni
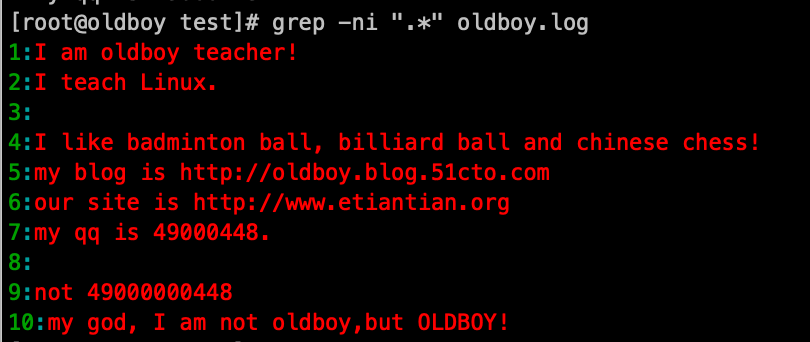
6. -o 参数,只显示匹配的内容,不显示整行: grep -no 'oldb.y' oldboy.log

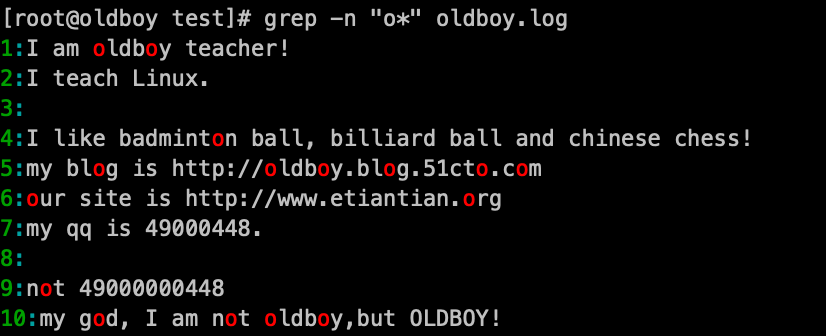
7. 匹配"o*"的内容:grep -n 'o*' oldboy.log
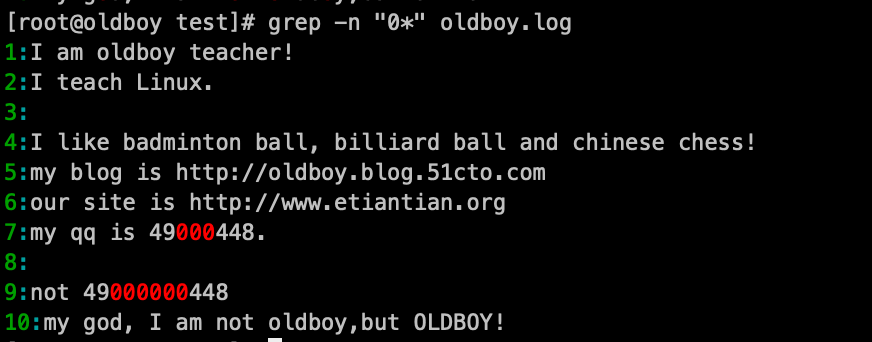
8. 匹配"0*"的内容: grep -n '0*' oldboy.log
基础正则第三波字符说明:
- [abc] 匹配字符集合内的任意一个字符[a-zA-Z],[0-9]。
- [^abc] 匹配不包含^ 后的任意个一个字符的内容 中括号内的^ 为取反,注意和中括号外面的^(以...开头的区别)
- a\{n,m\} 重复n到m次,前一个重复的字符。
- 如果用egrep 或 sed -r 可以去掉斜线
- grep -E 也可以去掉斜线
- a\{n,\} 重复至少n次,前一个重复的字符。
- 如果用egrep 或 sed -r 可以去掉斜线
- grep -E 也可以去掉斜线
- a\{n\} 重复n次,前一个重复的字符。
- 如果用egrep 或 sed -r 可以去掉斜线
- grep -E 也可以去掉斜线
- a\{,m\} 重复最多m次
- grep -E 也可以去掉斜线
注意:egrep 或 sed -r 过滤,一般特殊字符({})可以不转义
- a\{n,m\} 重复n到m次,前一个重复的字符。
示例:
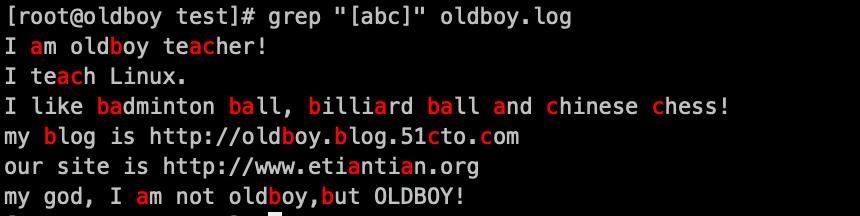
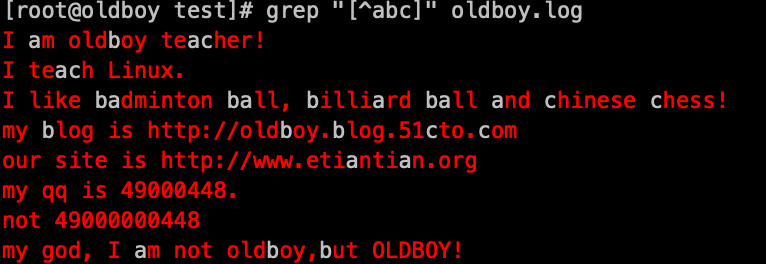
1. 匹配[abc]中任一一个字符 grep '[abc]' oldboy.log
2. 匹配[^abc]中的字符(非a,非b,非c)grep '[^abc]' oldboy.log
3. 匹配"oldboy"或"oldbey",不区分大小写:grep 'oldb[oe]y' oldboy.log -io

4. 匹配含数字的行:grep '[0-9]' oldboy.log

5. 下面分别是:
- 匹配0(重复3次),其中49000000448是匹配了两轮,三个0为一组
- 匹配0 (重复4次)
- 匹配0 (重复2次),其中49000000匹配了三轮,两个0为一组
- 匹配0(重复3到四次)
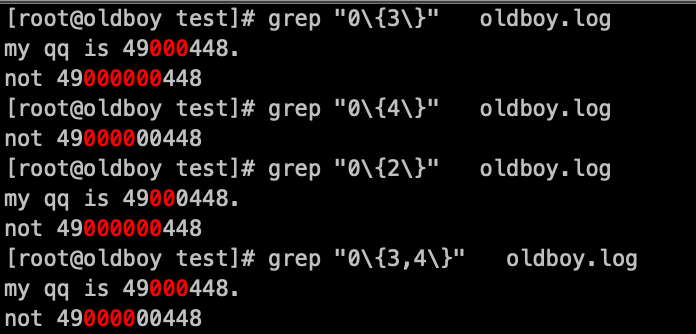
匹配0(重复0次到3次):

基础正则表达式:元字符意义 BRE(basic regular expression)
正则表达式(Regular Expression)实际上就是一些特殊符号,赋予了他特定的含义:
^ 以...开头
- ^d 以d开头
- ^word 匹配以word开头的内容
- 在vi/vim编辑器里,^代表一行的开头
$ 以...结尾
- word$ 匹配以word结尾的内容
- 在vi/vim编辑器里,$代表一行的结尾
^$ 表示空行
- . 代表且只能代表任意一个字符
- \ 转义符号
- 让特殊符号代表其本身
- * 重复0个或多个前面的一个字符
- 例如:o* 匹配,没有"o",有1个"o",或多个"o"
.* 匹配所有字符
- 延伸:
- ^.*以任意多个字符开头
- .*$ 以任意多个字符结尾
- 延伸:
[abc] 匹配字符集合内的任意一个字符[a-zA-Z],[0-9]。
- [^abc] 匹配不包含^ 后的任意个一个字符的内容 中括号内的^ 为取反,注意和中括号外面的^(以...开头的区别)
- a\{n,m\} 重复n到m次,前一个重复的字符。
- 如果用egrep 或 sed -r 可以去掉斜线
- grep -E 也可以去掉斜线
- a\{n,\} 重复至少n次,前一个重复的字符。
- 如果用egrep 或 sed -r 可以去掉斜线
- grep -E 也可以去掉斜线
- a\{n\} 重复n次,前一个重复的字符。
- 如果用egrep 或 sed -r 可以去掉斜线
- grep -E 也可以去掉斜线
- a\{,m\} 重复最多m次
- grep -E 也可以去掉斜线
注意:egrep 或 sed -r 过滤,一般特殊字符({})可以不转义
- a\{n,m\} 重复n到m次,前一个重复的字符。
扩展的正则表达式:grep -E 以及egrep(Extend Regular Expression)
- + 表示重复“一个或一个以上”前面的字符(* 是 0 个或多个)
- ? 表示重复 “0个或1个”前面的字符(. 是有且只有1个)
- | 表示同时过滤多个字符串
- () 分组过滤,后向引用
示例:
1. + 表示重复“一个或一个以上”前面的字符(* 是 0 个或多个)
[root@oldboy test]# grep -Eo "go+d" oldboy.log
god
[root@oldboy test]# grep -Eo "go.d" oldboy.log
[root@oldboy test]# grep -Eo "go*d" oldboy.log
god
[root@oldboy test]# grep -Eo "g*d" oldboy.log
d
d
d
d
d
d
d
2. ? 表示重复 “0个或1个”前面的字符(. 是有且只有1个):
[root@oldboy test]# echo good >>oldboy.log
[root@oldboy test]# egrep "goo?d" oldboy.log --color=auto -o
god
good [root@oldboy test]# egrep "htt?p" oldboy.log
my blog is http://oldboy.blog.51cto.com
our site is http://www.etiantian.org
3. | 表示同时过滤多个字符串
[root@oldboy test]# egrep "3306|1521" /etc/services
mysql 3306/tcp # MySQL
mysql 3306/udp # MySQL
ncube-lm 1521/tcp # nCube License Manager
ncube-lm 1521/udp # nCube License Manager
4. () 分组过滤,后向引用:
[root@oldboy test]# egrep "g(o|oo)d" oldboy.log -o
god
good
扩展的正则表达式总结:
- + 表示重复“一个或一个以上”前面的字符(* 是 0 个或多个)
- ? 表示重复 “0个或1个”前面的字符(. 是有且只有1个)
- | 表示同时过滤多个字符串
- () 分组过滤,后向引用
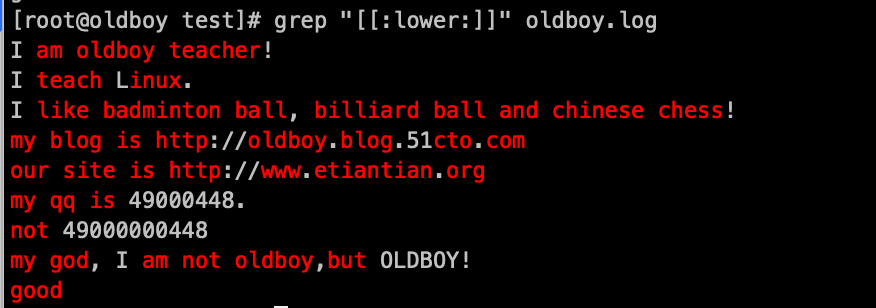
另外一个需要了解的知识:posix 方括号字符集(挺鸡肋的知道就行)
- [:alnum:] 匹配任意一个字母或数字字符
- [:lower:] 匹配小写字母
- [:xdigit:] 任何一个十六进制数0-9, a-f, A-F
- [:digit:] 匹配任意一个数字字符
- [:alpha:] 匹配任意一个字母字符(包含大小写)
- [:print:] 任何一个可以打印的字符
- [:blank:] 空格与制表符
- [:punct:] 匹配标点符号
- [:cntrl:] 任何一个控制字符
- [:space:] 匹配一个包括换行符、回车等在内的所有空白符
- [:graph:] 匹配任何一个可以看得见的且可以打印的字符
- [:upper:] 匹配大写字母
过滤小写字母:
元字符
元字符(meta character)是一种Perl风格的正则表达式,只有一部分文本处理工具支持它,并不是所有的文本处理工具都支持。
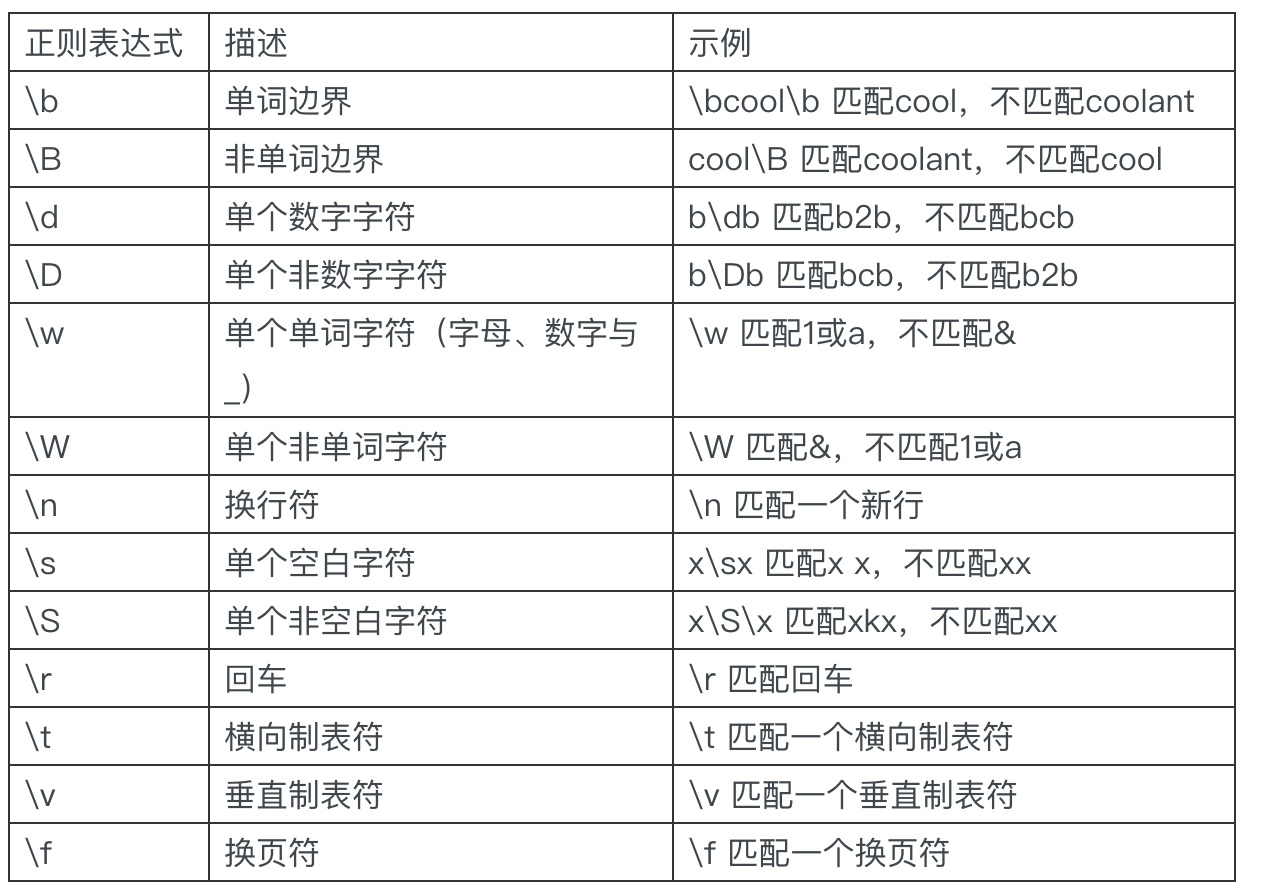
示例:\b 单词边界

2. 通配符
Linux通配符和三剑客的正则表达式是不一样的,因此,代表的意义也有较大的区别。
通配符一般用户命令行bash环境,而linux正则表达式用于grep, sed, awk场景。
通配符
- * 代表任意0-N个字符,代表所有字符
- ? 代表任意1个字符
- ; 连续不同命令的分隔符
- # 配置文件注释
- | 管道:效率并不高
- ~ 当前用户的家目录
- - 上一次的目录
- 例如:cd - 进入上一次的目录
- $ 变量前需要加的符号
- 例如:echo $LANG 输出变量的内容
- / 路径分隔符号,也是根
- > 1> 重定向,覆盖
- >> 追加重定向,追加内容到文件尾部
- < 输入重定向(xargs,tr)
- << 追加输入重定向(cat)
示例:* 的使用:代表任意0-N个字符,代表所有字符
[root@oldboy /]# mkdir /test
[root@oldboy /]# cd /test
[root@oldboy test]# touch test.sh oldboy.sh oldgirl.sh
[root@oldboy test]# ls
oldboy.sh oldgirl.sh test.sh [root@oldboy test]# ls *.sh
oldboy.sh oldgirl.sh test.sh [root@oldboy test]# touch gongli.txt
[root@oldboy test]# ls *
gongli.txt oldboy.sh oldgirl.sh test.sh
[root@oldboy test]# ls ????.sh
test.sh
示例:; 是命令之间的分隔符
[root@oldboy test]# whoami;pwd
root
/test
其他符号
- ' 单引号,不具有变量置换功能,输出时,所见即所得
- " 双引号,具有变量置换功能,解析变量后输出,不加引号相当于双引号。常用双引号
- ` tab键上面的键,反引号,两个``中间为命令,会先执行,等价$()。
- {} 中间为命令区块组合或内容序列
- ! 逻辑运算中的“非”NOT
- && 相当于and,当前一个指令执行成功时,执行后一个指令
- || 相当于or,当前一个指令执行失败时,执行后一个指令
- .. 上一级目录
- . 当前目录
示例:单引号,双引号和反引号
# 单引号:所见即所得
[root@oldboy test]# echo 'date'
date # 双引号会解析,但是要加上反引号
[root@oldboy test]# echo "date"
date # 双引号内部反引号执行的命令,会解析变量后输出
[root@oldboy test]# echo "`date`"
Fri Sep 6 05:26:49 CST 2019 # 单引号:所见即所得,即使内部是反引号的命令,输出仍然是所见即所得。
[root@oldboy test]# echo '`date`'
`date`
示例:{}
# 文件备份
[root@oldboy test]# cp test.sh{,.ori}
[root@oldboy test]# ls test.sh*
test.sh test.sh.ori # 批量创建文件
[root@oldboy test]# touch stu{1..5}
[root@oldboy test]# ls stu*
stu1 stu2 stu3 stu4 stu5 # 批量创建目录,目录下的子文件等
[root@oldboy test]# mkdir /test/a/{A..C}/{1..3}/end -p
[root@oldboy test]# tree /test/ -d
/test/
└── a
├── A
│ ├── 1
│ │ └── end
│ ├── 2
│ │ └── end
│ └── 3
│ └── end
├── B
│ ├── 1
│ │ └── end
│ ├── 2
│ │ └── end
│ └── 3
│ └── end
└── C
├── 1
│ └── end
├── 2
│ └── end
└── 3
└── end
正则表达式(grep,awk,sed)和通配符的更多相关文章
- linux的文件处理(匹配 正则表达式 egrep awk sed)和系统、核心数据备份
文件处理 1.处理方式 匹配 正则表达式 egrep awk sed 2.文件中的处理字符 \n 新行符 换行 \t 制表符 tab键 缺省8个空格 \b 退格符 backspace键 退格键 ...
- Linux三剑客-grep || awk || sed
grep是一个强大的文本搜索工具 命令格式: grep [option] pattren file -a 将二进制文档以文本方式处理 -c 计算找到的符合行的次数 -i 忽略大小写 -n 顺便 ...
- 【linux系统】命令学习(五)linux三剑客 grep \ awk \ sed
grep----基于正则表达式查找满足条件的行 1.内容检索 获取行 grep pattern file 获取内容 grep -o pattern file 获取上下文grep -A -B -C pa ...
- Linux四剑客find/grep/awk/sed
find ./ -name "*txt" -maxdepth 1 -type f -mtime -2 -exec mv {} ./bbb.txt \; 这条命令表示找当前目录(-m ...
- Linux查找命令:grep,awk,sed
grep grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具 ...
- 【Linux】linux中文本操作利器grep,awk,sed
grep命令 grep(global search regular expression)是一种强大的文本搜索工具,它可以使用正则表达式搜索文本,并把匹配的行打印出来.平时搜索文本中内容的时候是非常方 ...
- linux shell grep/awk/sed 匹配tab
处理文件的命令实在是多, sed, awk, grep等.遇到了需要匹配tab的情况, 记录一下. 例子如下:找出文本中第一列是1的行. 文本a 解法1 : 直接使用正则表达式, ^表示开头, \t表 ...
- linux相关(find/grep/awk/sed/rpm)
如何查找特定的文件: find :在指定目录下查找文件 find -name "filename" :从当前目录查找文件 find / -name "filename&q ...
- grep/awk/sed 或者 并且 否定
Grep 'OR' Operator Find all the lines in a file, that match any of the following patterns. Using GRE ...
随机推荐
- python:匿名函数lambda
看个例子: a=list(map(lambda x:x*x,(1,2,3))) print(a) 输出:[1, 4, 9] lambda实际上就是匿名函数,相当于: def f(x): return ...
- Three中的动画实现-[three.js]
Table Of Content 动画原理 js中动画实现原理setInterval js中动画实现新方法requestAnimationFrame 一个示例 动画原理 动画的本质实际上就是快速地不断 ...
- css进阶选择器
后代选择器 用空格隔开 选择div标签下的p标签下的a标签 div p a 选择class为parent标签下的p标签下的a标签 .parent p a 后代选择器可以是标签.类.id的混合体 后代选 ...
- C语言学生管理系统完善版
#include<stdio.h>#include<string.h>#include <stdlib.h>#define M 100struct score ...
- idle中上传jar包并使用的方法
创建一个lib目录,将jar包拉到该目录下. 需要导入的Jar包上,点击右键,选择Add as Library…
- "着重内容"组件:<strong> —— 快应用组件库H-UI
 <import name="strong" src="../Common/ui/h-ui/text/c_tag_b"></import&g ...
- k8s~helm镜像版本永远不要用latest
对于容器编排工具k8s来说,你可以使用它规定的yaml格式的脚本,使用客户端kubectl来与k8s进行通讯,将你定义好的yaml部署脚本应用到k8s集群上,而这对yaml脚本一般来说都是很像的,就是 ...
- 动手学Transformer
动手实现Transformer,所有代码基于tensorflow2.0,配合illustrated-transformer更香. 模型架构 Encoder+Decoder Encoder Decode ...
- centos7用户管理及root忘记密码恢复
查看用户相关命令:#id 用户和组的信息#whoami #查看当前有效用户名#who #显示目前登入系统的用户信息.#w # w 命令用于显示已经登陆系统的用户列表#users #用于显示当前登录系统 ...
- 从前端到后端实现弹幕的过程(jsp/Jquery.barrager.js)
Jquery.barrager.js插件,可以去网上下载!下载完后,就把下载文件中的js文件.css文件.图片文件.等等等文件全部拷贝到你们自己的项目中去,千万别拷贝漏了,如果你怕拷贝漏了什么,那就把 ...