T-SQL总结
先简单说一下
SQL是国际组织订的统一标准,各数据库厂商根据该标准开发自己的数据库及语言
T-SQL就是Microsoft公司的
oracle的是PL/SQL
下面我们主要总结T-SQL:
1.T-SQL的语句类型
1.1 数据定义语言
create table (创建表)
比如:create table Student
(
id int,
name nvarchar(20)
)
alter table (修改表)
drop table (删除表)
1.2 数据控制语言
grant(授权)
deny(拒绝)
revoke(取消)
1.3 数据操作语句
insert
delete
update
select
2.批处理命令
2.1 批处理分段命令 go
2.2 存储过程执行命令 exec
3.标识符
3.1 [],创建表名称可以加[],中间可以有空格;例如:create table [my table]
3.2 "", 创建表名称可以加“”,中间可以有空格;例如:create table "my table",但这必要开启一个属性
4.数据类型
int,datetime等,需要注意的是char,varchar,nvarchar的区别和使用
char和varchar的区别:char是固定长度,varchar是可变长度,例如:列存储“dachuang”数据,如果类型为char(10),存储占10个字节长度(包含2个空字节)当然如果存储的字符长度大于10,它会截取,但varchar(10) 则只占8个字节长度。但char的效率比varchar高
varchar和nvarchar区别:varchar每个字符占一个字节长度,而nvarhcar每个字符占二个字节长度,因为nvarchar是用来解决存储中英文混乱的,大部分中文都是二个字节所以nvarchar每个字符都按两个字节存储。varchar(10)能存储10个英文字符,但nvarchar(10)能存储10个中文,也就是相当于20个字符的长度。
5.变量、函数
5.1 变量
declarre @name varchar(10),@age int
set @name=‘’张三’ 也可以用 select @age=25
select @name
5.2 函数
dateadd(yy,2,getdate()), 当前年份+2,比如:当前是2017年,能显示为2019年
datepart(yyyy,getdate()), 得到年部分如:2017
datediff(dd,'2017-02-06','2017-03-22'), 得到日期差
isnull:isnull(列名,0),如果列为null,则转换为0
left:left(列名,3),返回列左边头3个字符
right:right(列名,3),返回列右边头3个
mid(列名,2,5),返回从第2个字符开始,长度为5的
随机函数:rand()随机一个0-1内的随机数,可以这样用rand()*100,这个是0-99的数据
5.3 条件语句
(1).例子:if.....else...
declare @score decimal
set @score=50+rand()*50
if(@score>60)
print '及格'
else
print '不及格'
--还可以如下这样用
if(@score>60)
begin
--可以放多条sql语句
print '成绩过了及格线'
print '及格'
end
else
print '不及格'
结果:

(2).例子:case ..... when.... then... end 或case when ... then... end
declare @score decimal
set @score=(50+rand()*50)/10
select case @score when 5 then '不及格'
when 6 then '及格'
when 7 then '良'
else '优秀'
end
结果:
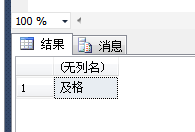
也可以这样用:
select case when @score<60 then '不及格' when @score>=60 then '及格'end as '成绩'
结果如下:

(3).循环语句
while(条件)begin....end
5.4 动态创建sql语句
declare @tablename nvarchar(20)
set @tablename='T'+convert(varchar(4), YEAR(GETDATE()))+'年'+CONVERT(varchar(2), MONTH(GETDATE()))+'月'
+CONVERT(varchar(2), DAY(GETDATE()))+'日'
execute('create table '+@tablename+'(studentid int ,studentname nvarchar(20))')
6 查询
6.1单表查询
(1)模糊查询,关键词:like
配合下面使用:
%:0-多个字符串
_:任何单个字符
[]:匹配区域内任何单个字符
[^]或[!]:匹配不在指定区域内的任何字符
not:not like
(2)between... and... 区间取值,包含两个边界的值 例如:between 70 and 80 取得70-80之间的数值,包含70和80
not...between...and... 不在区域内的值 例如:not between 70 and 80 不包含70-80的其他值
注意:

(3)in() :包含在区域内的 比如:select * from student where name in ('张三','李四','小明')
not in()不包含在区域内的值
(4)is null :查询列值为null的
is not null
(5)排序
order by 排序默认asc升序,降序为desc
注意:
查询尽量少用not between,not in 等,这样会降低查询效率;
还有能精确查询的,尽量少用like模糊查询,会降低查询速度;
order by 也会降低查询速度因为是先查询再在内存中排序
6.2 多表查询
(1).内连接 (inner)join...on
select a.* ,b.* from student a inner join score b on a.studentid=b.studentid, inner可以省略
(2).外连接
左外连接:left join...on...,右外连接:right join...on ,全连接:full join...on
左连接就是以左侧的表为主,和右侧的表一一匹配,没有匹配的用null补充显示
右连接和左连接相反,以右侧表为主
全连接:左右两个表中数值都有
(3).合并多个结果集
关键字:union 请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
另外union会自动去除重复行,如果要重复行,用union all
比如:
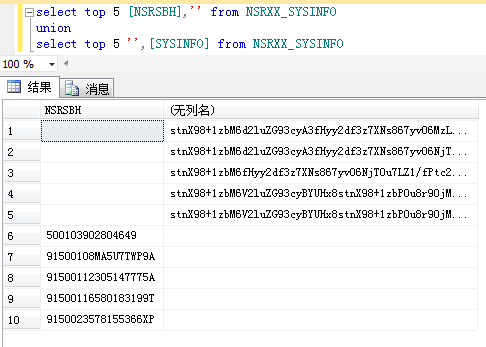
7.插入
(1).select ... into... from 从一个表中取数据插入到一张新建表中,一般用作备份表
例如:select p.lastname,od.orderno into Persons_Order_Backup from Persons as p inner join Orders as od on Persons.Id_P=Orders.Id_P
(2).insert (into) 表名(列名1,列名2) values(值1,值2)
(3).把查询出来的数据插入到现有表中
insert 表1 select * from 表2
8.创建索引
create index 索引名 on 表名(列1,列2)
CREATE [UNIQUE] [CLUSTERED| NONCLUSTERED ]
INDEX index_name ON { table | view } ( column [ ASC | DESC ] [ ,...n ] )
UNIQUE:用于指定为表或视图创建唯一索引,即不允许存在索引值相同的两行。
CLUSTERED:用于指定创建的索引为聚集索引。解释:聚集索引是一种对磁盘上实际数据重新组织以按指定的一列或多列值排序。像我们用到的汉语字典,就是一个聚集索引。由于聚集索引是给数据排序,不可能有多种排法,所以一个表只能建立一个聚集索引。科学统计建立这样的索引需要至少相当与该表120%的附加空间,用来存放该表的副本和索引中间页,但是他的性能几乎总是比其它索引要快。
NONCLUSTERED:用于指定创建的索引为非聚集索引。解释:sqlserver默认情况下建立的索引是非聚集索引,他不重新组织表中的数据,而是对每一行存储索引列值并用一个指针指向数据所在的页面。他像汉语字典中的根据‘偏旁部首’查找要找的字,即便对数据不排序,然而他拥有的目录更像是目录,对查取数据的效率也是具有的提升空间,而不需要全表扫描。
一个表可以拥有多个非聚集索引,每个非聚集索引根据索引列的不同提供不同的排序顺序。
删除索引 drop index 索引 on 表名
9.创建视图
create view 视图名 as select * from 表名 where 条件
10.删除记录
delete from 表名
11.更新记录
update 表 set 列1=‘123’,列2=100
update 表 set ... from 表 join 表2 on 条件
T-SQL总结的更多相关文章
- 最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目
最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目 最近一个来自重庆的客户找到走起君,客户的业务是做移动互联网支付,是微信支付收单渠道合作伙伴,数据库里存储的是支付流水和交易流水 ...
- SQL Server 大数据搬迁之文件组备份还原实战
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 解决方案(Solution) 搬迁步骤(Procedure) 搬迁脚本(SQL Codes) ...
- Sql Server系列:分区表操作
1. 分区表简介 分区表在逻辑上是一个表,而物理上是多个表.从用户角度来看,分区表和普通表是一样的.使用分区表的主要目的是为改善大型表以及具有多个访问模式的表的可伸缩性和可管理性. 分区表是把数据按设 ...
- SQL Server中的高可用性(2)----文件与文件组
在谈到SQL Server的高可用性之前,我们首先要谈一谈单实例的高可用性.在单实例的高可用性中,不可忽略的就是文件和文件组的高可用性.SQL Server允许在某些文件损坏或离线的情况下,允 ...
- EntityFramework Core Raw SQL
前言 本节我们来讲讲EF Core中的原始查询,目前在项目中对于简单的查询直接通过EF就可以解决,但是涉及到多表查询时为了一步到位就采用了原始查询的方式进行.下面我们一起来看看. EntityFram ...
- 从0开始搭建SQL Server AlwaysOn 第一篇(配置域控)
从0开始搭建SQL Server AlwaysOn 第一篇(配置域控) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www.cnb ...
- 从0开始搭建SQL Server AlwaysOn 第二篇(配置故障转移集群)
从0开始搭建SQL Server AlwaysOn 第二篇(配置故障转移集群) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www ...
- 从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn)
从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://w ...
- 从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点)
从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www ...
- SQL Server on Linux 理由浅析
SQL Server on Linux 理由浅析 今天的爆炸性新闻<SQL Server on Linux>基本上在各大科技媒体上刷屏了 大家看到这个新闻都觉得非常震精,而美股,今天微软开 ...
随机推荐
- (转)out.writer和out.print
JSP中out.write()和out.print()的区别 out对象的类型是JspWriter.JspWriter继承了java.io.Writer类. 1)print方法是子类JspWriter ...
- 吴裕雄--天生自然 JAVASCRIPT开发学习: 错误 - throw、try 和 catch
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- [Python Cookbook]Pandas: How to increase columns for DataFrame?Join/Concat
1. Combine Two Series series1=pd.Series([1,2,3],name='s1') series2=pd.Series([4,5,6],name='s2') df = ...
- 00java语法基础和课后实践
一:运行代码,并分析结果 代码1: package reserve; public class Main { public static void main(String[] args) { Size ...
- runlevel 运行级别
linux启动过程 关于Ubuntu 12.04修改默认运行级别,启动字符界面的个人理解 网上通常的做法是:(亲自试验,不管用),如果想直接操作请看绿色字体部分 (1)第一种方法: 由于Red ...
- cmd执行jmeter命令生成报告的问题。
现有几个jmeter脚本,准备以命令行的方式执行jmeter脚本,并生成报告. 一.使用python语言处理 1.目录结构 2.说明 jmx目录下是jmeter脚本 result目录下是生成的报告及文 ...
- 201509-1 数列分段 Java
思路: 后一个和前一个不相等就算一段 import java.util.Scanner; public class Main { public static void main(String[] ar ...
- 吴裕雄--天生自然 JAVA开发学习:基本数据类型
public class PrimitiveTypeTest { public static void main(String[] args) { // byte System.out.println ...
- MyBatis从入门到精通(第6章):MyBatis 高级查询->6.1.1高级结果映射之一对一映射
jdk1.8.MyBatis3.4.6.MySQL数据库5.6.45.IntelliJ IDEA 2019.2.4 本章主要包含的内容为 MyBatis 的高级结果映射,主要处理数据库一对一.一对多的 ...
- ubuntu编译caffe遇到的问题及解决方案
问题1 /usr/include/boost/python/detail/wrap_python.hpp:50:23: fatal error: pyconfig.h: No such file or ...