[转]SparkSQL的自适应执行---Adaptive Execution
1 背景
本文介绍的 Adaptive Execution 将可以根据执行过程中的中间数据优化后续执行,从而提高整体执行效率。核心在于两点
执行计划可动态调整
调整的依据是中间结果的精确统计信息
2 动态设置 Shuffle Partition
2.1 Spark Shuffle 原理
如上图所示,该 Shuffle 总共有 2 个 Mapper 与 5 个 Reducer。每个 Mapper 会按相同的规则(由 Partitioner 定义)将自己的数据分为五份。每个 Reducer 从这两个 Mapper 中拉取属于自己的那一份数据。
2.2 原有 Shuffle 的问题
使用 Spark SQL 时,可通过 spark.sql.shuffle.partitions 指定 Shuffle 时 Partition 个数,也即 Reducer 个数
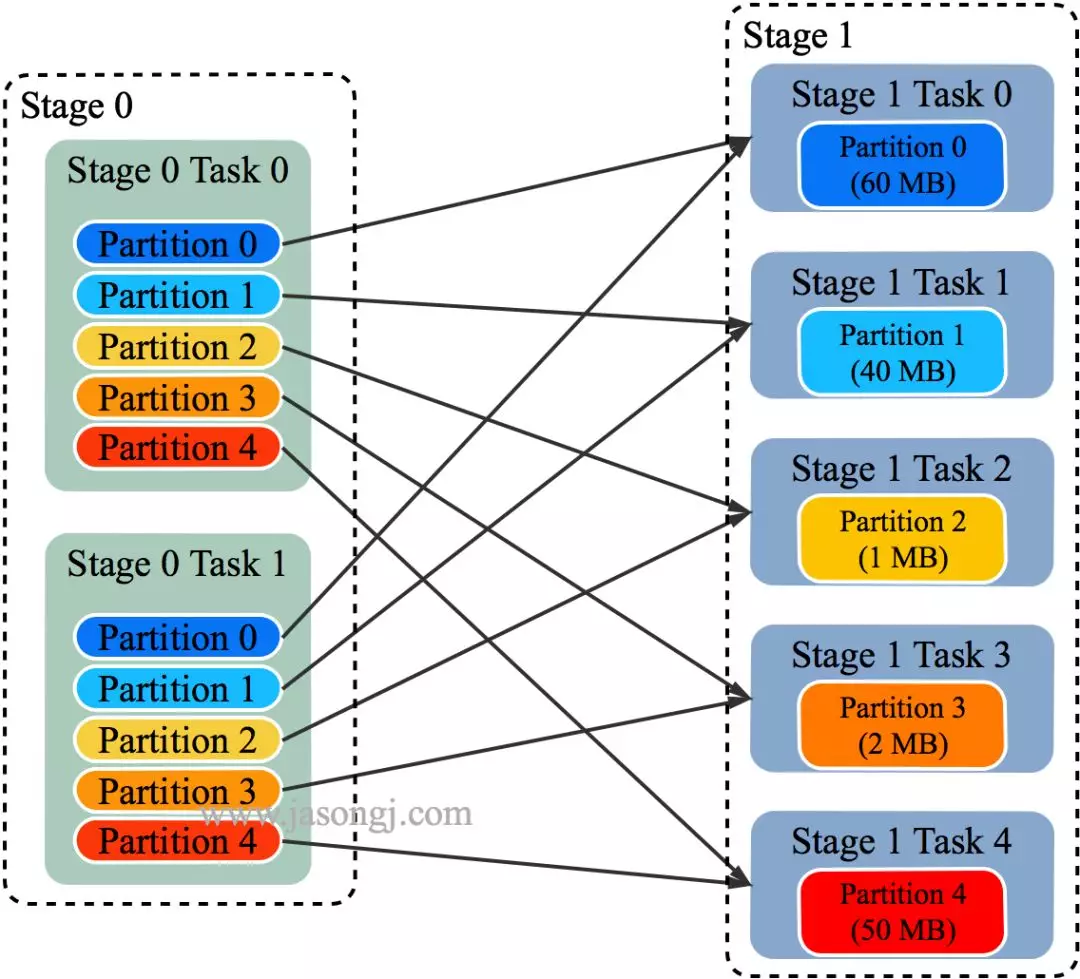
该参数决定了一个 Spark SQL Job 中包含的所有 Shuffle 的 Partition 个数。如下图所示,当该参数值为 3 时,所有 Shuffle 中 Reducer 个数都为 3
这种方法有如下问题
Partition 个数不宜设置过大
Reducer(代指 Spark Shuffle 过程中执行 Shuffle Read 的 Task) 个数过多,每个 Reducer 处理的数据量过小。大量小 Task 造成不必要的 Task 调度开销与可能的资源调度开销(如果开启了 Dynamic Allocation)
Reducer 个数过大,如果 Reducer 直接写 HDFS 会生成大量小文件,从而造成大量 addBlock RPC,Name node 可能成为瓶颈,并影响其它使用 HDFS 的应用
过多 Reducer 写小文件,会造成后面读取这些小文件时产生大量 getBlock RPC,对 Name node 产生冲击
Partition 个数不宜设置过小
每个 Reducer 处理的数据量太大,Spill 到磁盘开销增大
Reducer GC 时间增长
Reducer 如果写 HDFS,每个 Reducer 写入数据量较大,无法充分发挥并行处理优势
很难保证所有 Shuffle 都最优
不同的 Shuffle 对应的数据量不一样,因此最优的 Partition 个数也不一样。使用统一的 Partition 个数很难保证所有 Shuffle 都最优
定时任务不同时段数据量不一样,相同的 Partition 数设置无法保证所有时间段执行时都最优
2.3 自动设置 Shuffle Partition 原理
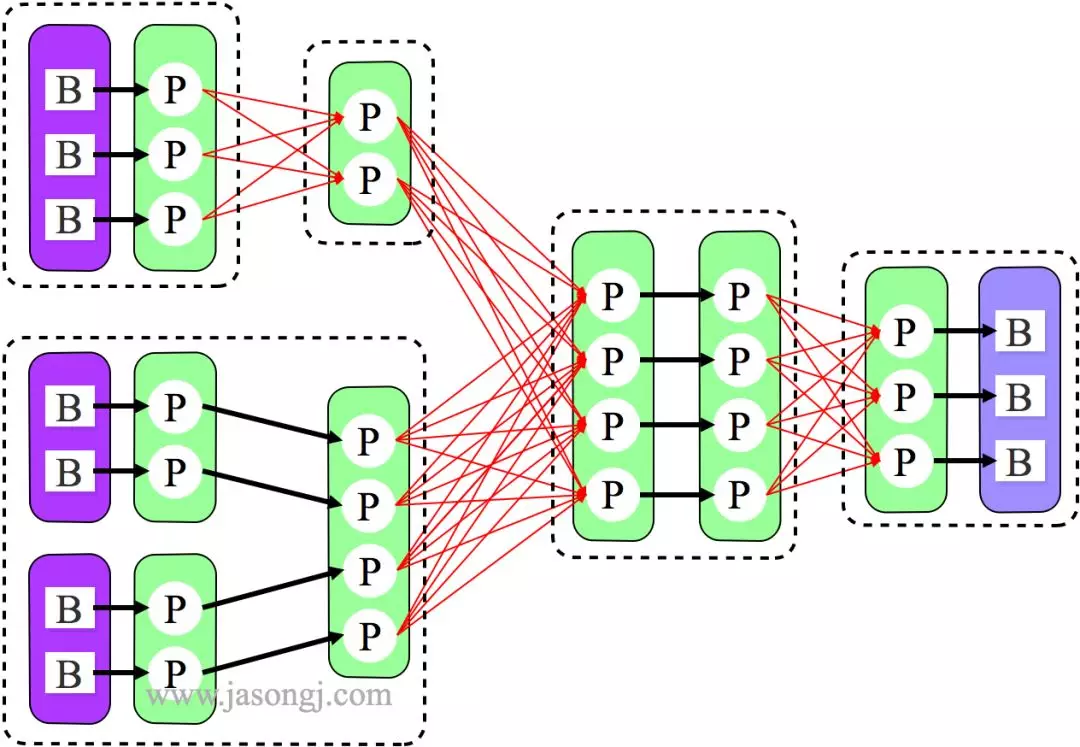
如 Spark Shuffle 原理 一节图中所示,Stage 1 的 5 个 Partition 数据量分别为 60MB,40MB,1MB,2MB,50MB。其中 1MB 与 2MB 的 Partition 明显过小(实际场景中,部分小 Partition 只有几十 KB 及至几十字节)
开启 Adaptive Execution 后
Spark 在 Stage 0 的 Shuffle Write 结束后,根据各 Mapper 输出,统计得到各 Partition 的数据量,即 60MB,40MB,1MB,2MB,50MB
通过 ExchangeCoordinator 计算出合适的 post-shuffle Partition 个数(即 Reducer)个数(本例中 Reducer 个数设置为 3)
启动相应个数的 Reducer 任务
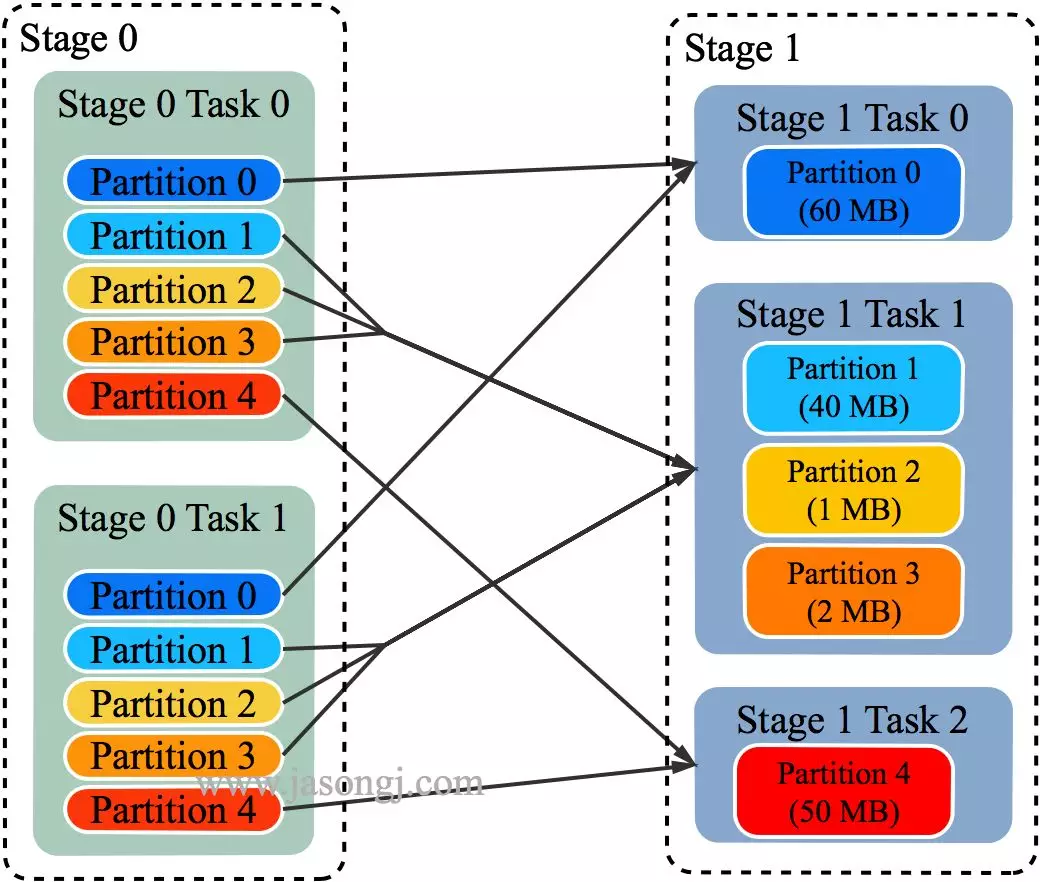
每个 Reducer 读取一个或多个 Shuffle Write Partition 数据(如下图所示,Reducer 0 读取 Partition 0,Reducer 1 读取 Partition 1、2、3,Reducer 2 读取 Partition 4)
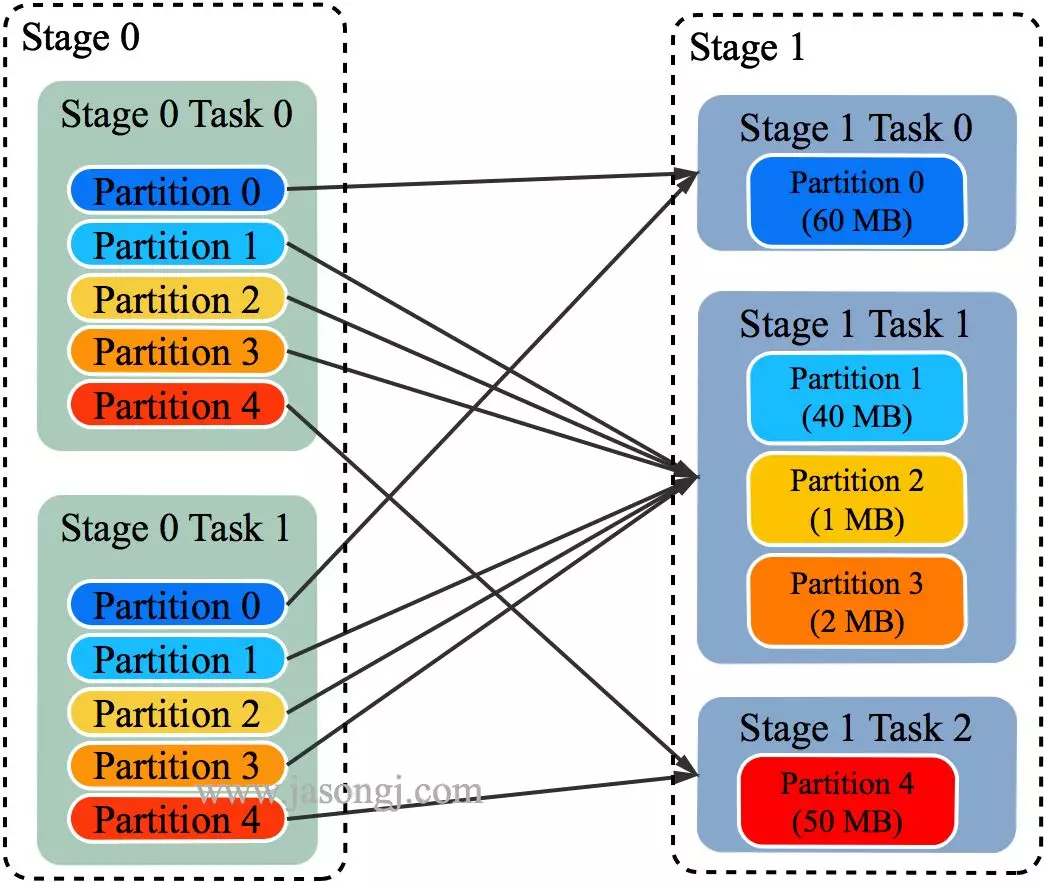
三个 Reducer 这样分配是因为
targetPostShuffleInputSize 默认为 64MB,每个 Reducer 读取数据量不超过 64MB
如果 Partition 0 与 Partition 2 结合,Partition 1 与 Partition 3 结合,虽然也都不超过 64 MB。但读完 Partition 0 再读 Partition 2,对于同一个 Mapper 而言,如果每个 Partition 数据比较少,跳着读多个 Partition 相当于随机读,在 HDD 上性能不高
目前的做法是只结合相临的 Partition,从而保证顺序读,提高磁盘 IO 性能
该方案只会合并多个小的 Partition,不会将大的 Partition 拆分,因为拆分过程需要引入一轮新的 Shuffle
基于上面的原因,默认 Partition 个数(本例中为 5)可以大一点,然后由 ExchangeCoordinator 合并。如果设置的 Partition 个数太小,Adaptive Execution 在此场景下无法发挥作用
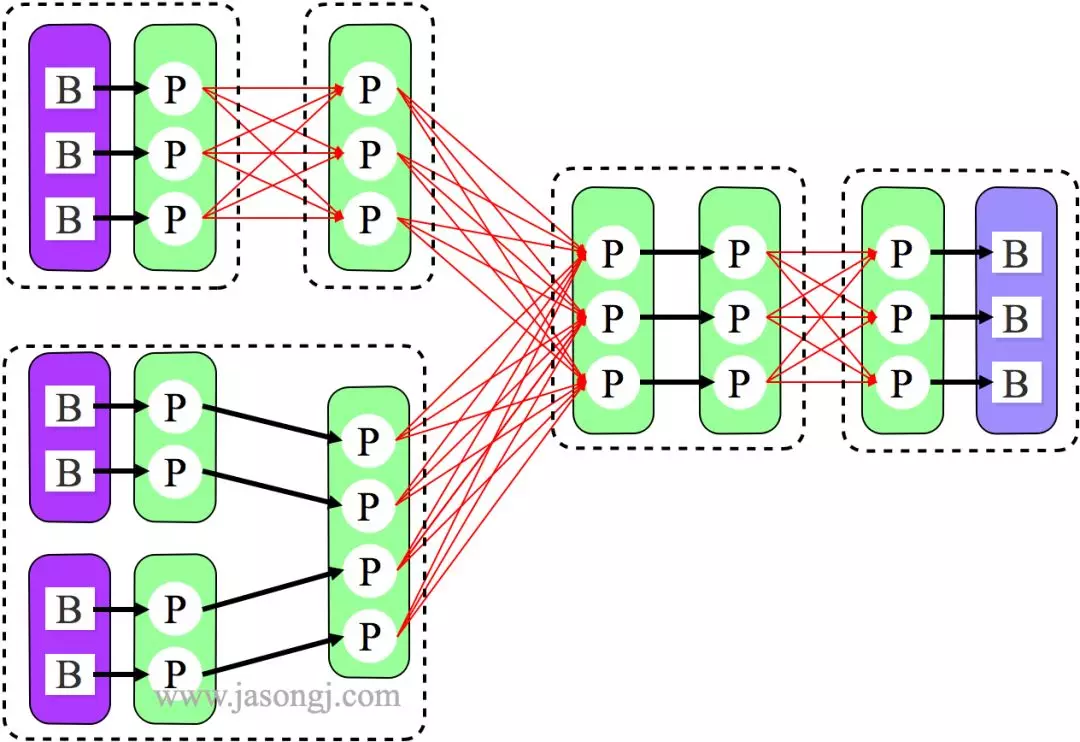
由上图可见,Reducer 1 从每个 Mapper 读取 Partition 1、2、3 都有三根线,是因为原来的 Shuffle 设计中,每个 Reducer 每次通过 Fetch 请求从一个特定 Mapper 读数据时,只能读一个 Partition 的数据。也即在上图中,Reducer 1 读取 Mapper 0 的数据,需要 3 轮 Fetch 请求。对于 Mapper 而言,需要读三次磁盘,相当于随机 IO。
为了解决这个问题,Spark 新增接口,一次 Shuffle Read 可以读多个 Partition 的数据。如下图所示,Task 1 通过一轮请求即可同时读取 Task 0 内 Partition 0、1 和 2 的数据,减少了网络请求数量。同时 Mapper 0 一次性读取并返回三个 Partition 的数据,相当于顺序 IO,从而提升了性能。
由于 Adaptive Execution 的自动设置 Reducer 是由 ExchangeCoordinator 根据 Shuffle Write 统计信息决定的,因此即使在同一个 Job 中不同 Shuffle 的 Reducer 个数都可以不一样,从而使得每次 Shuffle 都尽可能最优。
上文 原有 Shuffle 的问题 一节中的例子,在启用 Adaptive Execution 后,三次 Shuffle 的 Reducer 个数从原来的全部为 3 变为 2、4、3。
2.4 使用与优化方法
可通过 spark.sql.adaptive.enabled=true 启用 Adaptive Execution 从而启用自动设置 Shuffle Reducer 这一特性
通过 spark.sql.adaptive.shuffle.targetPostShuffleInputSize 可设置每个 Reducer 读取的目标数据量,其单位是字节,默认值为 64 MB。上文例子中,如果将该值设置为 50 MB,最终效果仍然如上文所示,而不会将 Partition 0 的 60MB 拆分。具体原因上文已说明
3 动态调整执行计划
3.1 固定执行计划的不足
在不开启 Adaptive Execution 之前,执行计划一旦确定,即使发现后续执行计划可以优化,也不可更改。如下图所示,SortMergJoin 的 Shuffle Write 结束后,发现 Join 一方的 Shuffle 输出只有 46.9KB,仍然继续执行 SortMergeJoin
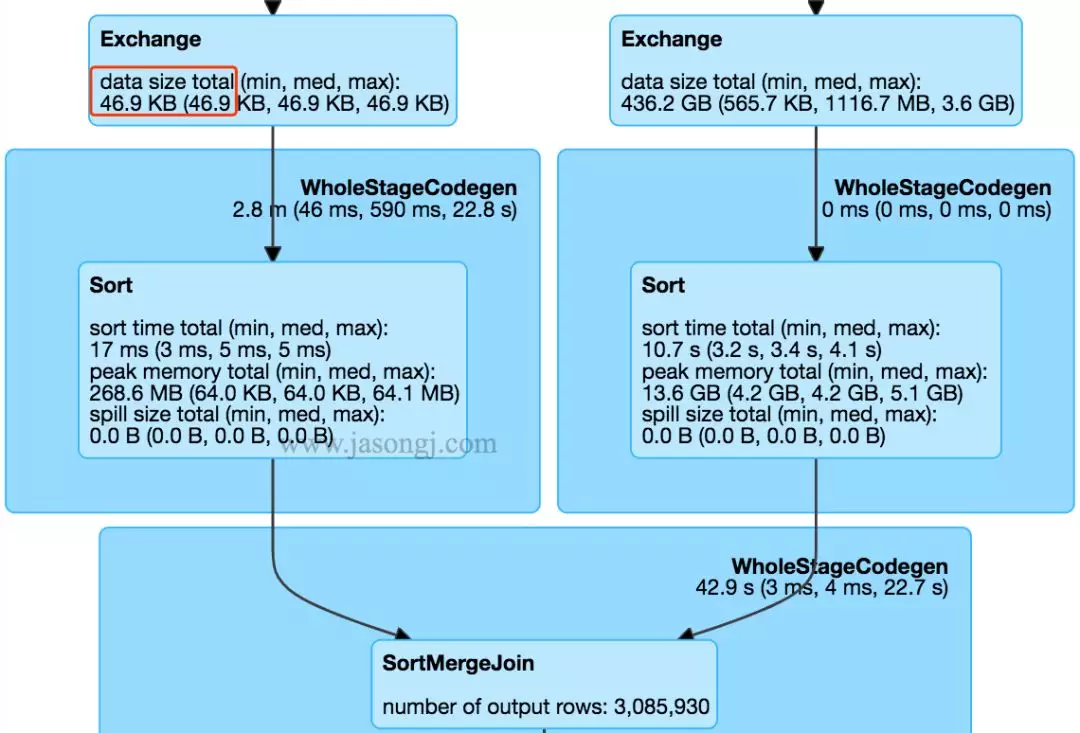
此时完全可将 SortMergeJoin 变更为 BroadcastJoin 从而提高整体执行效率。
3.2 SortMergeJoin 原理
SortMergeJoin 是常用的分布式 Join 方式,它几乎可使用于所有需要 Join 的场景。但有些场景下,它的性能并不是最好的。
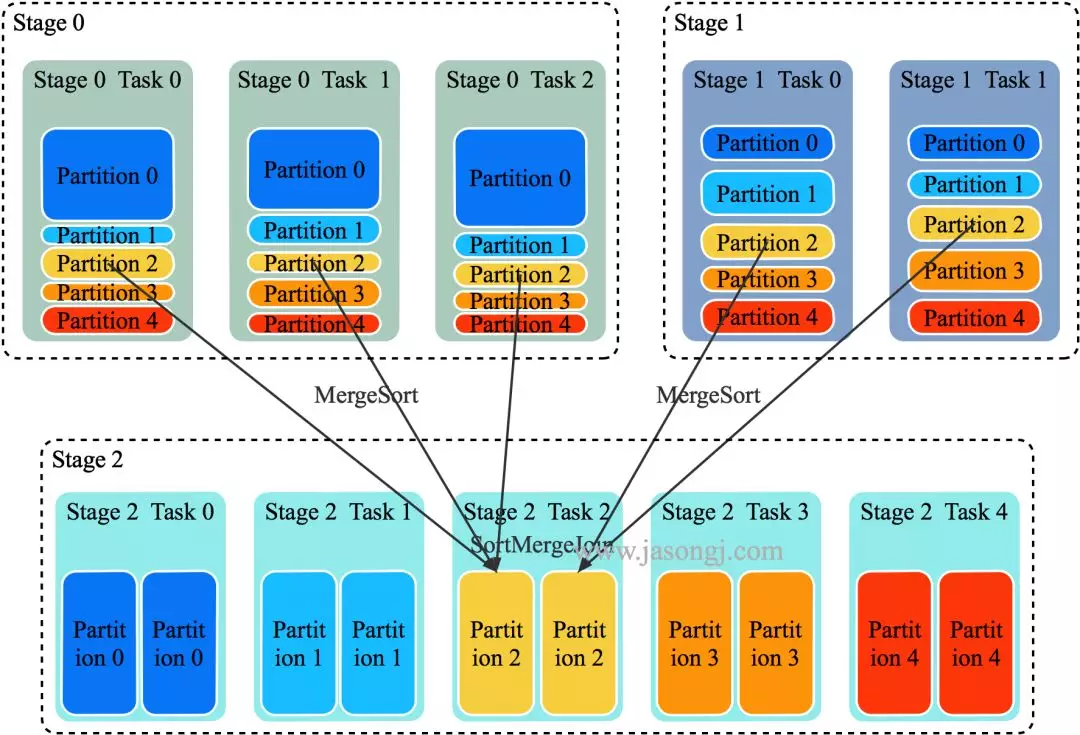
SortMergeJoin 的原理如下图所示
将 Join 双方以 Join Key 为 Key 按照 HashPartitioner 分区,且保证分区数一致
Stage 0 与 Stage 1 的所有 Task 在 Shuffle Write 时,都将数据分为 5 个 Partition,并且每个 Partition 内按 Join Key 排序
Stage 2 启动 5 个 Task 分别去 Stage 0 与 Stage 1 中所有包含 Partition 分区数据的 Task 中取对应 Partition 的数据。(如果某个 Mapper 不包含该 Partition 的数据,则 Redcuer 无须向其发起读取请求)。
Stage 2 的 Task 2 分别从 Stage 0 的 Task 0、1、2 中读取 Partition 2 的数据,并且通过 MergeSort 对其进行排序
Stage 2 的 Task 2 分别从 Stage 1 的 Task 0、1 中读取 Partition 2 的数据,且通过 MergeSort 对其进行排序
Stage 2 的 Task 2 在上述两步 MergeSort 的同时,使用 SortMergeJoin 对二者进行 Join
3.3 BroadcastJoin 原理
当参与 Join 的一方足够小,可全部置于 Executor 内存中时,可使用 Broadcast 机制将整个 RDD 数据广播到每一个 Executor 中,该 Executor 上运行的所有 Task 皆可直接读取其数据。(本文中,后续配图,为了方便展示,会将整个 RDD 的数据置于 Task 框内,而隐藏 Executor)
对于大 RDD,按正常方式,每个 Task 读取并处理一个 Partition 的数据,同时读取 Executor 内的广播数据,该广播数据包含了小 RDD 的全量数据,因此可直接与每个 Task 处理的大 RDD 的部分数据直接 Join
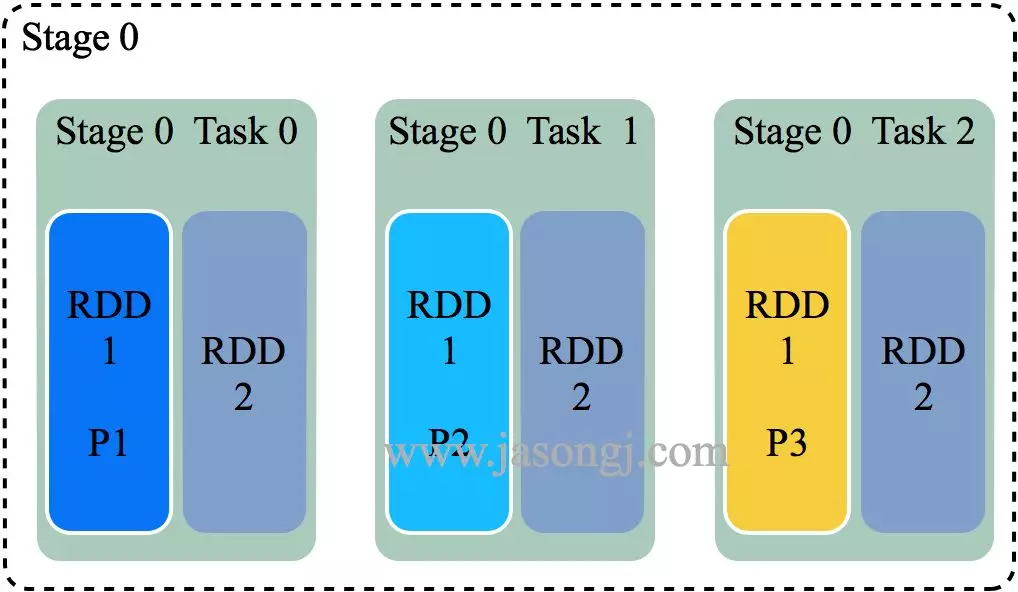
根据 Task 内具体的 Join 实现的不同,又可分为 BroadcastHashJoin 与 BroadcastNestedLoopJoin。后文不区分这两种实现,统称为 BroadcastJoin
与 SortMergeJoin 相比,BroadcastJoin 不需要 Shuffle,减少了 Shuffle 带来的开销,同时也避免了 Shuffle 带来的数据倾斜,从而极大地提升了 Job 执行效率
同时,BroadcastJoin 带来了广播小 RDD 的开销。另外,如果小 RDD 过大,无法存于 Executor 内存中,则无法使用 BroadcastJoin
对于基础表的 Join,可在生成执行计划前,直接通过 HDFS 获取各表的大小,从而判断是否适合使用 BroadcastJoin。但对于中间表的 Join,无法提前准确判断中间表大小从而精确判断是否适合使用 BroadcastJoin
《Spark SQL 性能优化再进一步 CBO 基于代价的优化》一文介绍的 CBO 可通过表的统计信息与各操作对数据统计信息的影响,推测出中间表的统计信息,但是该方法得到的统计信息不够准确。同时该方法要求提前分析表,具有较大开销
而开启 Adaptive Execution 后,可直接根据 Shuffle Write 数据判断是否适用 BroadcastJoin
3.4 动态调整执行计划原理
如上文 SortMergeJoin 原理 中配图所示,SortMergeJoin 需要先对 Stage 0 与 Stage 1 按同样的 Partitioner 进行 Shuffle Write
Shuffle Write 结束后,可从每个 ShuffleMapTask 的 MapStatus 中统计得到按原计划执行时 Stage 2 各 Partition 的数据量以及 Stage 2 需要读取的总数据量。(一般来说,Partition 是 RDD 的属性而非 Stage 的属性,本文为了方便,不区分 Stage 与 RDD。可以简单认为一个 Stage 只有一个 RDD,此时 Stage 与 RDD 在本文讨论范围内等价)
如果其中一个 Stage 的数据量较小,适合使用 BroadcastJoin,无须继续执行 Stage 2 的 Shuffle Read。相反,可利用 Stage 0 与 Stage 1 的数据进行 BroadcastJoin,如下图所示
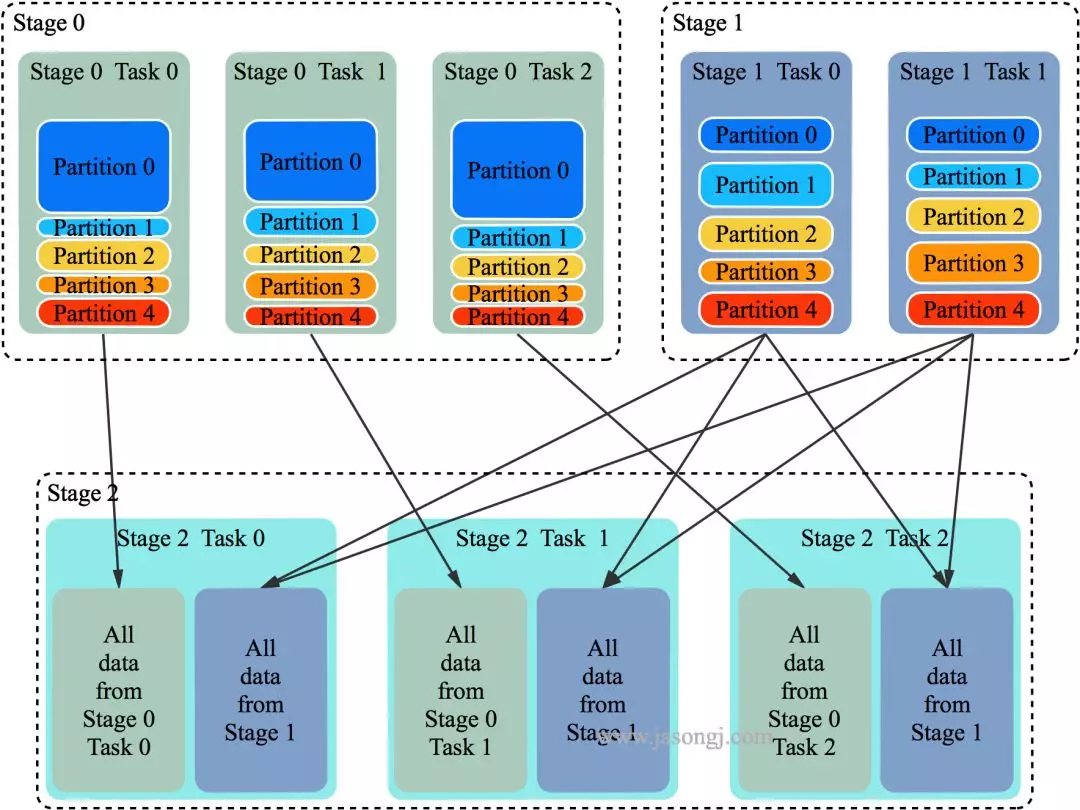
具体做法是
将 Stage 1 全部 Shuffle Write 结果广播出去
启动 Stage 2,Partition 个数与 Stage 0 一样,都为 3
每个 Stage 2 每个 Task 读取 Stage 0 每个 Task 的 Shuffle Write 数据,同时与广播得到的 Stage 1 的全量数据进行 Join
注:广播数据存于每个 Executor 中,其上所有 Task 共享,无须为每个 Task 广播一份数据。上图中,为了更清晰展示为什么能够直接 Join 而将 Stage 2 每个 Task 方框内都放置了一份 Stage 1 的全量数据
虽然 Shuffle Write 已完成,将后续的 SortMergeJoin 改为 Broadcast 仍然能提升执行效率
SortMergeJoin 需要在 Shuffle Read 时对来自 Stage 0 与 Stage 1 的数据进行 Merge Sort,并且可能需要 Spill 到磁盘,开销较大
SortMergeJoin 时,Stage 2 的所有 Task 需要取 Stage 0 与 Stage 1 的所有 Task 的输出数据(如果有它要的数据 ),会造成大量的网络连接。且当 Stage 2 的 Task 较多时,会造成大量的磁盘随机读操作,效率不高,且影响相同机器上其它 Job 的执行效率
SortMergeJoin 时,Stage 2 每个 Task 需要从几乎所有 Stage 0 与 Stage 1 的 Task 取数据,无法很好利用 Locality
Stage 2 改用 Broadcast,每个 Task 直接读取 Stage 0 的每个 Task 的数据(一对一),可很好利用 Locality 特性。最好在 Stage 0 使用的 Executor 上直接启动 Stage 2 的 Task。如果 Stage 0 的 Shuffle Write 数据并未 Spill 而是在内存中,则 Stage 2 的 Task 可直接读取内存中的数据,效率非常高。如果有 Spill,那可直接从本地文件中读取数据,且是顺序读取,效率远比通过网络随机读数据效率高
3.5 使用与优化方法
该特性的使用方式如下
当
spark.sql.adaptive.enabled与spark.sql.adaptive.join.enabled都设置为true时,开启 Adaptive Execution 的动态调整 Join 功能spark.sql.adaptiveBroadcastJoinThreshold设置了 SortMergeJoin 转 BroadcastJoin 的阈值。如果不设置该参数,该阈值与spark.sql.autoBroadcastJoinThreshold的值相等除了本文所述 SortMergeJoin 转 BroadcastJoin,Adaptive Execution 还可提供其它 Join 优化策略。部分优化策略可能会需要增加 Shuffle。
spark.sql.adaptive.allowAdditionalShuffle参数决定了是否允许为了优化 Join 而增加 Shuffle。其默认值为 false
[转]SparkSQL的自适应执行---Adaptive Execution的更多相关文章
- [转]Spark SQL2.X 在100TB上的Adaptive execution(自适应执行)实践
Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇 ...
- SparkSQL Adaptive Execution
转自 https://mp.weixin.qq.com/s/Oq9L3Cmc-8G9oL8dvZ5OHQ 1 背景 本文介绍的 Adaptive Execution 将可以根据执行过程中的中间数据优化 ...
- Spark SQL在100TB上的自适应执行实践(转载)
Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇 ...
- Adaptive Execution如何让Spark SQL更高效更好用
1 背 景 Spark SQL / Catalyst 和 CBO 的优化,从查询本身与目标数据的特点的角度尽可能保证了最终生成的执行计划的高效性.但是 执行计划一旦生成,便不可更改,即使执行过程中发 ...
- Javascript 的执行环境(execution context)和作用域(scope)及垃圾回收
执行环境有全局执行环境和函数执行环境之分,每次进入一个新执行环境,都会创建一个搜索变量和函数的作用域链.函数的局部环境不仅有权访问函数作用于中的变量,而且可以访问其外部环境,直到全局环境.全局执行环境 ...
- sql server 执行计划(execution plan)介绍
大纲:目的介绍sql server 中执行计划的大致使用,当遇到查询性能瓶颈时,可以发挥用处,而且带有比较详细的学习文档和计划,阅读者可以按照我计划进行,从而达到对执行计划一个比较系统的学习. 什么是 ...
- 自适应增强(Adaptive Boosting)
简介 AdaBoost,是英文”Adaptive Boosting“(自适应增强)的缩写,是一种迭代提升算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成 ...
- LINQ之路 6:延迟执行(Deferred Execution)
LINQ中大部分查询运算符都有一个非常重要的特性:延迟执行.这意味着,他们不是在查询创建的时候执行,而是在遍历的时候执行(换句话说,当enumerator的MoveNext方法被调用时).让我们考虑下 ...
- 理解Javascript之执行上下文(Execution Context)
1>什么是执行上下文 Javascript中代码的运行环境分为以下三种: 全局级别的代码 - 这个是默认的代码运行环境,一旦代码被载入,引擎最先进入的就是这个环境. 函数级别的代码 - 当执行一 ...
随机推荐
- css选择器优先级排序
浏览器默认属性 < 继承自父元素的属性 < 通配符选择器 < 标签选择器 < 类选择器 < 结构伪类选择器 < id选择器 < 行内样式 < !impo ...
- 【剑指Offer面试编程题】题目1519:合并两个排序的链表--九度OJ
题目描述: 输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则. (hint: 请务必使用链表.) 输入: 输入可能包含多个测试样例,输入以EOF结束. 对于每 ...
- vue配置config ‘./.../.../***/**.vue’路径别名
cli-4的脚手架配置 因为组件的引用,经常会遇到import * from '../../../components/common/***.vue‘这样的引入格式,太复杂了,所以可以在vue里面配 ...
- re模块补充 configparse模块
import rere.findall("(?:abc)+","abcabcabc")--->['abcabcabc'] import configpar ...
- C# 篇基础知识3——面向对象编程
面向过程的结构化编程,例如1972年美国贝尔研究所推出的C语言,这类编程方式重点放在在定函数上,将较大任务分解成若干小任务,每个小任务由函数实现,分而治之的思想,然而随着软件规模的不断扩张,软件的复杂 ...
- vue 父组件向子组件传参(笔记)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- JuJu团队1月4号工作汇报
JuJu团队1月4号工作汇报 JuJu Scrum 团队成员 今日工作 剩余任务 困难 飞飞 将model嵌入GUI 美化UI 无 婷婷 调试代码 提升acc 无 恩升 -- 写python版本的 ...
- MQTT 协议学习:006-订阅主题 与 对应报文(SUBSCRIBE、SUBACK、UNSUBSCRIBE、UNSUBACK)
背景 之前我们提到了怎么发布消息对应的报文:现在我们来看,订阅一个主题的报文是怎么样的. SUBSCRIBE - 订阅主题 客户端向服务端发送SUBSCRIBE报文用于创建一个或多个订阅.每个订阅注册 ...
- 在线关闭 CLOSE_WAIT状态TCP连接
1.查看某个端口的所有TCP连接: [root@Centos projects]# netstat -anp | tcp6 ::: :::* LISTEN /java tcp6 CLOSE_WAIT ...
- GNS3 模拟DHCP之地址请求
R1: conf t int f0/0 no shutdown ip address dhcp end R2: conf t int f0/0 no shutdown ip add 12.1.1.2 ...