Scrapy爬虫框架基本使用
scrapyhub上有些视频简单介绍scrapy如何学习的(貌似要FQ):https://helpdesk.scrapinghub.com/support/solutions/articles/22000201028-learn-scrapy-video-tutorials-
本博客的源码下载地址(github) :https://github.com/zhaojiedi1992/tutorial
在上一个学习系列一种, 我们简单了解了小scrapy的一些概念和基本环境的搭建,接下来就开始创建工程和爬虫吧。
1 创建工程
1.1先创建一个目录,用于我们后续的scrapy目录(e:\scrapytest)

Win+R 快捷键 输入cmd 启动一个cmd创建,进行一下输入。
C:\Users\Administrator>e: E:\>cd e:\scrapytest e:\scrapytest>scrapy startproject tutorial
New Scrapy project 'tutorial', using template directory 'C:\\Program Files\\Anaconda3\\lib\\site-packages\\scrapy\\templates\\project', created in:
e:\scrapytest\tutorial You can start your first spider with:
cd tutorial
scrapy genspider example example.com e:\scrapytest>
我们发现使用scrapy startproject tutorial 给我们创建了许多文件,文件树结构如下:
e:\scrapytest>tree /f
卷 新加卷 的文件夹 PATH 列表
卷序列号为 0000004B D20B:7155
E:.
└─tutorial
│ scrapy.cfg #开发配置文件
│
└─tutorial #工程模块
│ items.py
│ middlewares.py #定义数据条目的定义,可以理解为一行记录
│ pipelines.py #定义数据导出类,用于数据导出
│ settings.py #工程设置文件
│ __init__.py #空文件
│
├─spiders #爬虫目录,用于放置各种爬虫类文件
│ │ __init__.py #空文件
│ │
│ └─__pycache__ #这个文件不用管它
└─__pycache__ #这个文件不用管它
通过上面的一条简单的命令,我们就创建了一个工程,有了工程,没有爬虫啊,接下里我们就创建一个爬虫吧。
2 创建爬虫
我们使用scrapy genspider quotes quotes.toscrape.com去创建一个爬虫。
scrapy genspider 使用方法: scrapy genspider [options] <name> <domain>
可以使用scrapy genspider -h 获取详细帮助 或者从官方获取shell帮助https://docs.scrapy.org/en/latest/topics/commands.html
e:\scrapytest\tutorial>scrapy genspider quotes quotes.toscrape.com
Created spider 'quotes' using template 'basic' in module:
tutorial.spiders.quotes
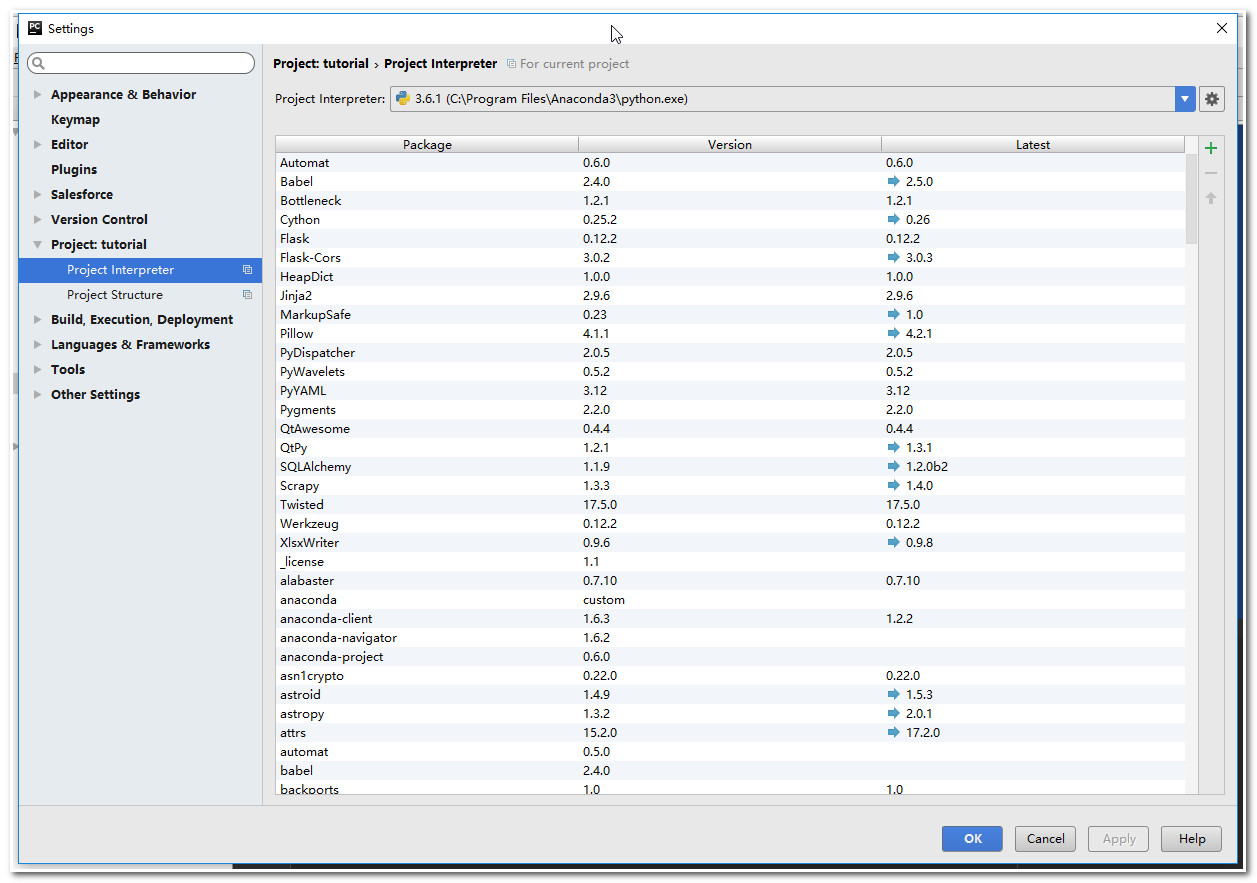
注意:使用pycharm 打开tutorial项目,需要对python的环境进行设置(我机器上python环境太多了),使用File->Settings->Project:tutorial->Project Interpreter 选择我们特定的python.exe。如下图:
3 完善我们的爬虫
修改我们的爬虫文件(quotes.py)内容如下:
# -*- coding: utf-8 -*-
import scrapy class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["http://quotes.toscrape.com/"]
start_urls = ['http://quotes.toscrape.com/page/1/'] def parse(self, response):
filename="source.html"
with open(filename,'wb') as f:
f.write(response.body)
代码简单介绍下吧:
- name:设定了爬虫的名字
- allowed_domains :设定允许域,不是这些域内的网址就会被放弃。
- start_urls:就是爬虫程序初始的url集合。
- parse:默认处理response流的方法,通常会返回一个item或者dict 给pipeline。
现在,工程有了,爬虫也有了。 接下里开始让我们的爬虫进行工作吧。
4 运行爬虫
运行爬虫很简单,使用scrapy crawl quotes 命令就可以里
e:\scrapytest\tutorial>scrapy crawl quotes
2017-08-25 22:50:25 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: tutorial)
2017-08-25 22:50:25 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'tutorial', 'NEWSPIDER_MODULE': 'tutorial.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tutorial.spiders']}
2017-08-25 22:50:25 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2017-08-25 22:50:26 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-08-25 22:50:26 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-08-25 22:50:26 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-08-25 22:50:26 [scrapy.core.engine] INFO: Spider opened
2017-08-25 22:50:26 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-08-25 22:50:26 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-08-25 22:50:27 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2017-08-25 22:50:27 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None)
2017-08-25 22:50:28 [scrapy.core.engine] INFO: Closing spider (finished)
2017-08-25 22:50:28 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 451,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 2701,
'downloader/response_count': 2,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/404': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 8, 25, 14, 50, 28, 49601),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2017, 8, 25, 14, 50, 26, 788397)}
2017-08-25 22:50:28 [scrapy.core.engine] INFO: Spider closed (finished)
运行爬虫后, 会提示一堆的信息,主要是完成以下几个部分工作:
- 启动爬虫引擎
- 加载设置文件
- 启用扩展
- 启用下载中间件
- 启用爬虫中间件
- 启动pipeline
- 爬虫启动,开始工作
- 爬虫结束, 引擎收集统计信息,清理工作
我们的爬虫代码是简单,就是打开一个sour.html文件,把获取的响应流(response)的页面内容写入进去。
到这这里,我们的爬虫只是获取了网址的源码,可能不是我们真正关心的,我们还需要写一写提取规则,提取网站的有用的信息(比如这个网址,我们只需要提取出作者,他的名言,他的标签),那我们就修改完善下爬虫吧。
5 完善爬虫
5.1 网址分析
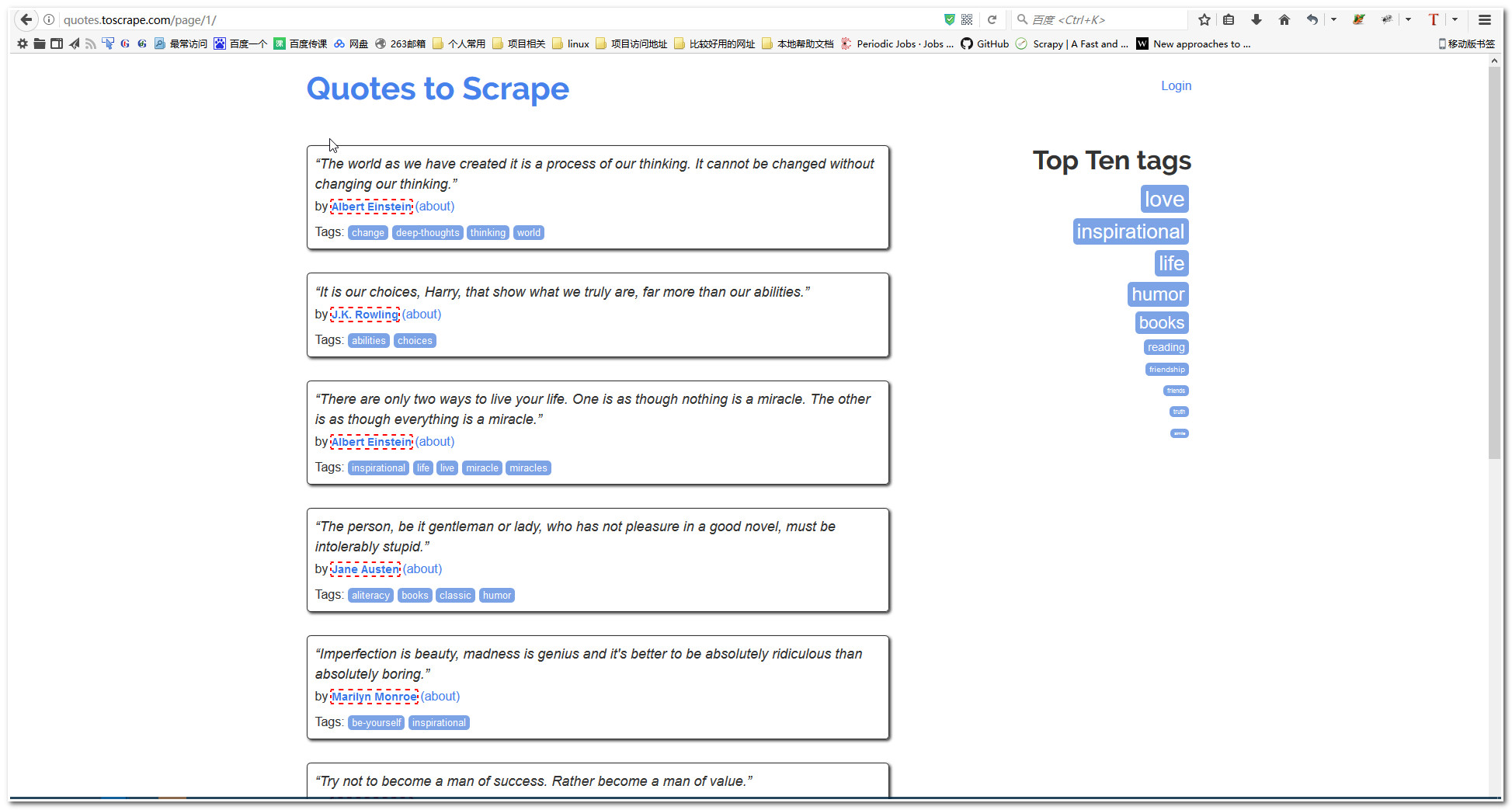
我们自己用浏览器打开http://quotes.toscrape.com/page/1/ 这个网址,发现网页比较规整,核心的内容区域包含3个内容出作者,他的名言,他的标签。
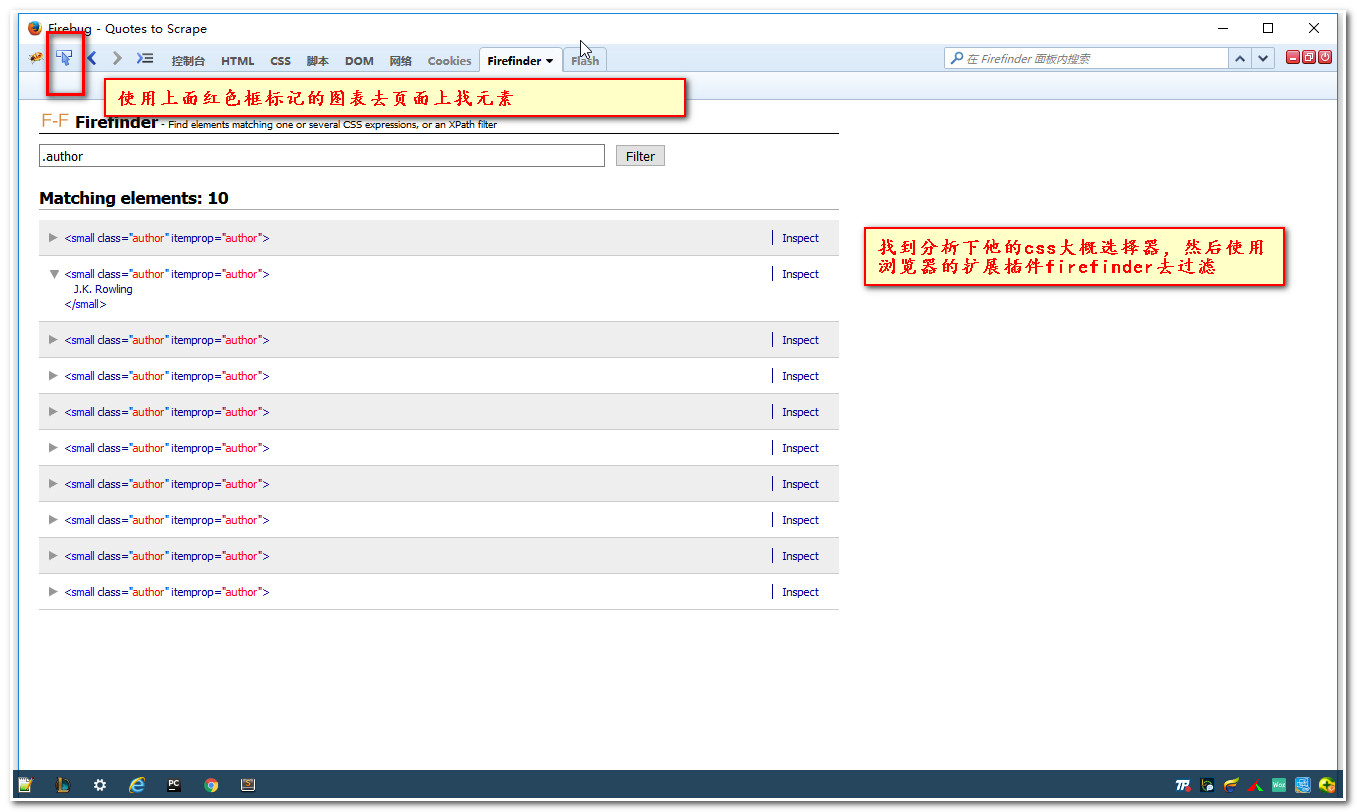
5.2 使用浏览器调试功能(f12)获取元素的css样式。
5.3 在item,py 文件修改为如下的内容
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author=scrapy.Field()
text=scrapy.Field()
tags=scrapy.Field()
pass
代码简介:我们创建了3个字段,分别用于存储网址上的名言,作者和标记信息。
5.4 完善我们的爬虫
修改我们的爬虫为如下代码:
# -*- coding: utf-8 -*-
import scrapy
from ..items import TutorialItem class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["http://quotes.toscrape.com/"]
start_urls = ['http://quotes.toscrape.com/page/1/'] def parse(self, response):
for quote in response.css('div.quote'):
elem=TutorialItem()
elem["text"]=quote.css('span.text::text').extract_first()
elem["author"]=quote.css('small.author::text').extract_first()
elem["tags"]=quote.css('div.tags a.tag::text').extract()
yield elem
代码简介: 写一个for循环去遍历,每次提取一个elem,使用css选择器去定位元素。当然你也可以使用xpath去定位元素。
关于css选择器的如何使用:可以参考如下网址
w3cschool :http://www.w3school.com.cn/cssref/css_selectors.asp
官方文档:https://docs.scrapy.org/en/latest/topics/selectors.html
6 存储我们的数据
我们启动爬虫的时候,加入-o选项,可以指定输出, 它可以根据文件后缀判断出你要导出的格式。默认的导出目录是基于工程目录的,也就是说你设置-o quotes.json 会在你的工程目录下生成一个quotes.json文件。
e:\scrapytest\tutorial>scrapy crawl quotes -o quotes.json
e:\scrapytest\tutorial>scrapy crawl quotes -o quotes.xml
e:\scrapytest\tutorial>scrapy crawl quotes -o quotes.csv
e:\scrapytest\tutorial>scrapy crawl quotes -o quotes.jl
这里我是实在命令行指定-o选项,导出的,能不能不在命令行设置就可以导出呢,当然可以了,修改我们的pipeline吧。
7 修改pipeline
pipeline从其名字就知意,管道行用于对输入的数据(item)进行清洗和持久化处理。
修改pipeline.py内容如下:
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class TutorialPipeline(object):
def process_item(self, item, spider):
return item import json class JsonWriterPipeline(object): def open_spider(self, spider):
self.file = open('items.jl', 'w') def close_spider(self, spider):
self.file.close() def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
设置好一个jsonline的pipline后,怎么让他生效呢, 需要在setting文件启用它的。
8 启用指定pipeline
打开setting.py文件
启用如下如下注释行,并稍作修改。
ITEM_PIPELINES = {
'tutorial.pipelines.JsonWriterPipeline': 300,
}
9 再次运行爬虫
这次在运行爬虫,我们发现生成了一个items.jl文件。当然了,我们这里是把items持久化到文件中去了,我们也是可以修改pipeline添加一个pipeline让item数据持久化到数据库中去。官方的一个样例:https://docs.scrapy.org/en/latest/topics/item-pipeline.html#write-items-to-mongodb
如果想生成各种格式的,处理feedback技术,可以参考我另一篇文章: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_005_scrapy.html
10 链接追踪
可以看到我们的爬虫只是爬取了page=1的内容,我要是想提取所有page的内容呢。如果你仔细分析下网页,可以看到page=1的页面最下面有个next的超链接指向下一页的。
那我们修改我们的爬虫代码为如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import TutorialItem class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["http://quotes.toscrape.com/"]
start_urls = ['http://quotes.toscrape.com/page/1/'] def parse(self, response):
for quote in response.css('div.quote'):
elem=TutorialItem()
elem["text"]=quote.css('span.text::text').extract_first()
elem["author"]=quote.css('small.author::text').extract_first()
elem["tags"]=quote.css('div.tags a.tag::text').extract()
yield elem
next_page = response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse,dont_filter=True)
代码简介:
next_page是我们从页面提取的下一页的网址,然后urljoin去拼接完整url,然后使用request去请求下一页,还是使用parse去解析响应流,当然我们可以在写一个parse的。
11 在次运行爬虫
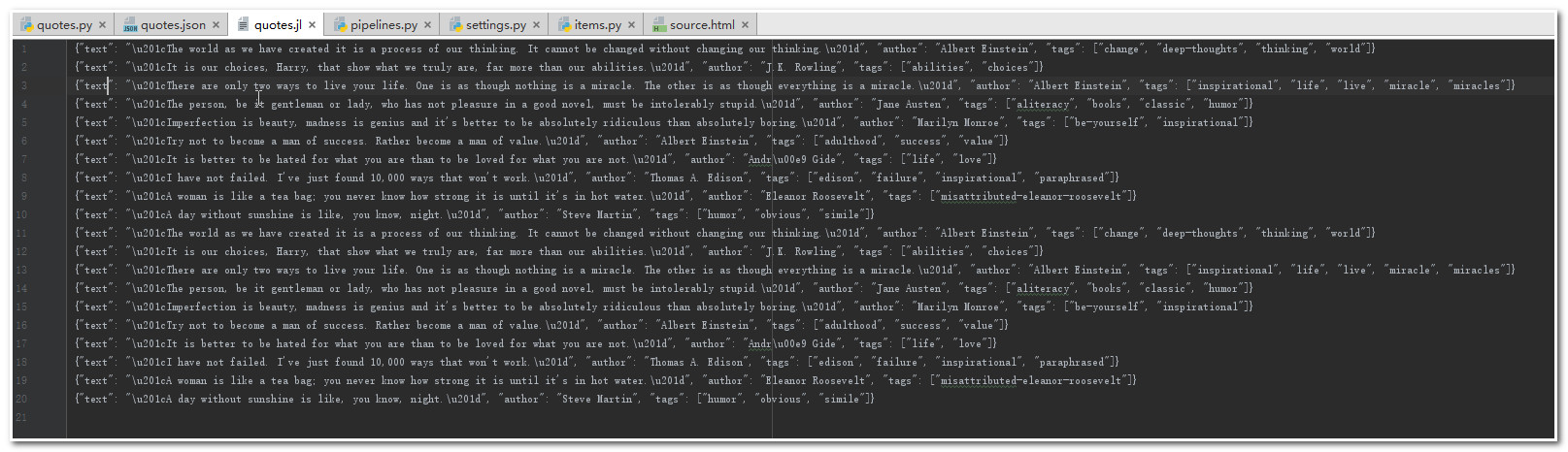
我们可以发现page1,page2的页面的数据都提取出来,如下图
12 给爬虫添加参数
我们想运行爬虫的时候,想给他指定一个参数,比如传递一个page号,让他动态去设置一个startul 可以吗?
修改quotes.py文件为如下内容:
# -*- coding: utf-8 -*-
import scrapy
from ..items import TutorialItem class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["http://quotes.toscrape.com/"]
#start_urls = ['http://quotes.toscrape.com/page/1/']
def __init__(self, page=None, *args, **kwargs):
super(QuotesSpider, self).__init__(*args, **kwargs)
if isinstance(page, str):
self.start_urls = [
'http://quotes.toscrape.com/page/%s/' % page]
self.page = page def parse(self, response):
for quote in response.css('div.quote'):
elem=TutorialItem()
elem["text"]=quote.css('span.text::text').extract_first()
elem["author"]=quote.css('small.author::text').extract_first()
elem["tags"]=quote.css('div.tags a.tag::text').extract()
yield elem
next_page = response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse ,dont_filter=True)
代码简介: 添加一个init方法,完成了page参数的赋值接受,设置了startu_urls。这样就可以接受参数动态的生成start_urls了。
13 运行爬虫
e:\scrapytest\tutorial>scrapy crawl quotes -a page=1
注: page=1,1就是参数,如果有空格使用双引号引起来。
通过本文的学习,你应该了解了。 scrapy框架的大概流程了吧,items,pipeline,spider.py,settings 这些文件是如何协同工作的。
14 相关的参考
css学习: http://www.w3school.com.cn/cssref/css_selectors.asp,https://www.w3.org/TR/selectors
xpath学习: http://www.w3school.com.cn/xpath/xpath_functions.asp , https://www.w3.org/TR/xpath
浏览器调试: https://docs.scrapy.org/en/latest/topics/firefox.html
浏览器插件推荐: chrom下cssfinder,xpathfinder ,selectorGadget , firefox下xpathfinder。 强烈推荐selectorGadget。
注意: 有时候设置css或者xpath表达式的时候建议在scrapy shell环境中先测试。
Scrapy爬虫框架基本使用的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
随机推荐
- HBase协处理器加载的三种方式
本文主要给大家罗列了HBase协处理器加载的三种方式:Shell加载(动态).Api加载(动态).配置文件加载(静态).其中静态加载方式需要重启HBase. 我们假设我们已经有一个现成的需要加载的协处 ...
- AJ学IOS(11)UI之图片自动轮播
AJ分享,必须精品 先看效果 代码 #import "NYViewController.h" #define kImageCount 5 @interface NYViewCont ...
- Linux相关操作
ssh配置秘钥 连接远程服务器时:需要用户持有“公钥/私钥对”,远程服务器持有公钥,本地持有私钥. 客户端向服务器发出请求.服务器收到请求之后,先在用户的主目录下找到该用户的公钥,然后对比用户发送过来 ...
- (转载)基于BIGINT溢出错误的SQL注入
我对于通过MySQL错误提取数据的新技术非常感兴趣,而本文中要介绍的就是这样一种技术.当我考察MySQL的整数处理方式的时候,突然对如何使其发生溢出产生了浓厚的兴趣.下面,我们来看看MySQL是如何存 ...
- 常用的python开发工具对比
一名优秀的Python开发人员都有一套好用的Python开发工具,好的开发工具可以使Python开发人员的工作更高效,以下是几款比较好用的Python开发工具,Python开发人员,尤其是初学者,可以 ...
- ES6新增的Map和WeakMap 又是什么玩意?非常详细的解释
上一篇文章讲了set和weakSet,这节咱就讲Map和weakMap是什么?这两篇文章并没有什么联系,主要知识用法类似而已.嘿嘿,是不是感觉舒服多了. 什么是Map 介绍什么是Map,就不得不说起O ...
- php sprintf() 函数把格式化的字符串写入一个变量中。
来源:https://blog.csdn.net/zxh1220/article/details/79709207 HP sprintf() 函数用到的参数 printf — 输出格式化字符串 spr ...
- php正则匹配到字符串里面的a标签
$cont = preg_replace('/<a href=\"(.*?)\".*?>(.*?)<\/a>/i','',$cont);
- 2019-2020-1 20199325《Linux内核原理与分析》第二周作业
冯诺依曼计算机硬件框图: 下面是一个简单的程序example.c. intadd_a_and_b(int a,int b){returna+b;}intmain(){returnadd_a_and_b ...
- mysql闪回工具--binlog2sql实践
DBA或开发人员,有时会误删或者误更新数据,如果是线上环境并且影响较大,就需要能快速回滚.传统恢复方法是利用备份重搭实例,再应用去除错误sql后的binlog来恢复数据.此法费时费力,甚至需要停机维护 ...