OpenCV-Python 理解K近邻 | 五十三
目标
在本章中,我们将了解k近邻(kNN)算法的原理。
理论
kNN是可用于监督学习的最简单的分类算法之一。这个想法是在特征空间中搜索测试数据的最近邻。我们将用下面的图片来研究它。
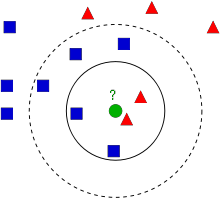
在图像中,有两个族,蓝色正方形和红色三角形。我们称每一种为类。他们的房屋显示在他们的城镇地图中,我们称之为特征空间。 (你可以将要素空间视为投影所有数据的空间。例如,考虑一个2D坐标空间。每个数据都有两个要素,x和y坐标。你可以在2D坐标空间中表示此数据,对吧?现在假设如果有三个要素,则需要3D空间;现在考虑N个要素,需要N维空间,对吗?这个N维空间就是其要素空间。在我们的图像中,你可以将其视为2D情况。有两个功能)。
现在有一个新成员进入城镇并创建了一个新房屋,显示为绿色圆圈。他应该被添加到这些蓝色/红色家族之一中。我们称该过程为分类。我们所做的?由于我们正在处理kNN,因此让我们应用此算法。
一种方法是检查谁是他的最近邻。从图像中可以明显看出它是红色三角形家族。因此,他也被添加到了红色三角形中。此方法简称为“最近邻”,因为分类仅取决于最近邻。
但这是有问题的。红三角可能是最近的。但是,如果附近有很多蓝色方块怎么办?然后,蓝色方块在该地区的权重比红色三角更大。因此,仅检查最接近的一个是不够的。相反,我们检查一些k近邻的族。那么,无论谁占多数,新样本都属于那个族。在我们的图像中,让我们取k=3,即3个最近族。他有两个红色和一个蓝色(有两个等距的蓝色,但是由于k = 3,我们只取其中一个),所以他又应该加入红色家族。但是,如果我们取k=7怎么办?然后,他有5个蓝色族和2个红色族。太好了!!现在,他应该加入蓝色族。因此,所有这些都随k的值而变化。更有趣的是,如果k=4怎么办?他有2个红色邻居和2个蓝色邻居。这是一个平滑!因此最好将k作为奇数。由于分类取决于k个最近的邻居,因此该方法称为k近邻。
同样,在kNN中,我们确实在考虑k个邻居,但我们对所有人都给予同等的重视,对吧?这公平吗?例如,以k=4的情况为例。我们说这是平局。但是请注意,这两个红色族比其他两个蓝色族离他更近。因此,他更应该被添加到红色。那么我们如何用数学解释呢?我们根据每个家庭到新来者的距离来给他们一些权重。对于那些靠近他的人,权重增加,而那些远离他的人,权重减轻。然后,我们分别添加每个族的总权重。谁得到的总权重最高,新样本归为那一族。这称为modified kNN。
那么你在这里看到的一些重要内容是什么?
- 你需要了解镇上所有房屋的信息,对吗?因为,我们必须检查新样本到所有现有房屋的距离,以找到最近的邻居。如果有许多房屋和家庭,则需要大量的内存,并且需要更多的时间进行计算。
- 几乎没有时间进行任何形式的训练或准备。
现在让我们在OpenCV中看到它。
OpenCV中的kNN
就像上面一样,我们将在这里做一个简单的例子,有两个族(类)。然后在下一章中,我们将做一个更好的例子。
因此,在这里,我们将红色系列标记为Class-0(因此用0表示),将蓝色系列标记为Class-1(用1表示)。我们创建25个族或25个训练数据,并将它们标记为0类或1类。我们借助Numpy中的Random Number Generator来完成所有这些工作。
然后我们在Matplotlib的帮助下对其进行绘制。红色系列显示为红色三角形,蓝色系列显示为蓝色正方形。
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
# 包含(x,y)值的25个已知/训练数据的特征集
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# 用数字0和1分别标记红色或蓝色
responses = np.random.randint(0,2,(25,1)).astype(np.float32)
# 取红色族并绘图
red = trainData[responses.ravel()==0]
plt.scatter(red[:,0],red[:,1],80,'r','^')
# 取蓝色族并绘图
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
plt.show()你会得到与我们的第一张图片相似的东西。由于你使用的是随机数生成器,因此每次运行代码都将获得不同的数据。
接下来启动kNN算法,并传递trainData和响应以训练kNN(它会构建搜索树)。
然后,我们将在OpenCV中的kNN的帮助下将一个新样本带入一个族并将其分类。在进入kNN之前,我们需要了解测试数据(新样本数据)上的知识。我们的数据应为浮点数组,其大小为$number\ of\ testdata\times number\ of\ features$。然后我们找到新加入的最近邻。我们可以指定我们想要多少个邻居。它返回:
- 给新样本的标签取决于我们之前看到的kNN理论。如果要使用“最近邻居”算法,只需指定k=1即可,其中k是邻居数。
- k最近邻的标签。
- 衡量新加入到每个最近邻的相应距离。
因此,让我们看看它是如何工作的。新样本被标记为绿色。
newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
knn = cv.ml.KNearest_create()
knn.train(trainData, cv.ml.ROW_SAMPLE, responses)
ret, results, neighbours ,dist = knn.findNearest(newcomer, 3)
print( "result: {}\n".format(results) )
print( "neighbours: {}\n".format(neighbours) )
print( "distance: {}\n".format(dist) )
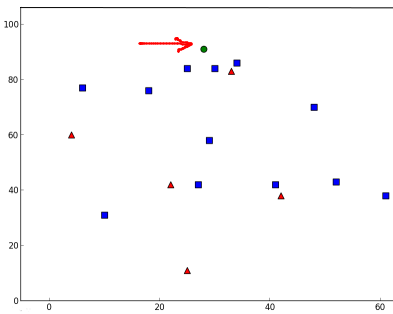
plt.show()我得到了如下的结果:
result: [[ 1.]]
neighbours: [[ 1. 1. 1.]]
distance: [[ 53. 58. 61.]]它说我们的新样本有3个近邻,全部来自Blue家族。因此,他被标记为蓝色家庭。从下面的图可以明显看出:
如果你有大量数据,则可以将其作为数组传递。还获得了相应的结果作为数组。
# 10个新加入样本
newcomers = np.random.randint(0,100,(10,2)).astype(np.float32)
ret, results,neighbours,dist = knn.findNearest(newcomer, 3)
# 结果包含10个标签附加资源
- NPTEL关于模式识别的注释,第11章
练习
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/
OpenCV中文官方文档:
http://woshicver.com/
OpenCV-Python 理解K近邻 | 五十三的更多相关文章
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 用python实现k近邻算法
用python写程序真的好舒服. code: import numpy as np def read_data(filename): '''读取文本数据,格式:特征1 特征2 -- 类别''' f=o ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- Python机器学习基础教程-第2章-监督学习之K近邻
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- K近邻分类算法实现 in Python
K近邻(KNN):分类算法 * KNN是non-parametric分类器(不做分布形式的假设,直接从数据估计概率密度),是memory-based learning. * KNN不适用于高维数据(c ...
- K近邻 Python实现 机器学习实战(Machine Learning in Action)
算法原理 K近邻是机器学习中常见的分类方法之间,也是相对最简单的一种分类方法,属于监督学习范畴.其实K近邻并没有显式的学习过程,它的学习过程就是测试过程.K近邻思想很简单:先给你一个训练数据集D,包括 ...
- 机器学习之路: python k近邻分类器 KNeighborsClassifier 鸢尾花分类预测
使用python语言 学习k近邻分类器的api 欢迎来到我的git查看源代码: https://github.com/linyi0604/MachineLearning from sklearn.da ...
- kd树 求k近邻 python 代码
之前两篇随笔介绍了kd树的原理,并用python实现了kd树的构建和搜索,具体可以参考 kd树的原理 python kd树 搜索 代码 kd树常与knn算法联系在一起,knn算法通常要搜索k近邻, ...
随机推荐
- Koa 学习
中间件引擎 1234567891011121314151617181920212223242526272829303132333435363738 const Koa = require('koa') ...
- Flutter Widgets 之 ListWheelScrollView
注意:无特殊说明,Flutter版本及Dart版本如下: Flutter版本: 1.12.13+hotfix.5 Dart版本: 2.7.0 基础用法 在展示大量数据的时候我们第一会想到使用ListV ...
- [Statistics] Comparison of Three Correlation Coefficient: Pearson, Kendall, Spearman
There are three popular metrics to measure the correlation between two random variables: Pearson's c ...
- MyBatis配置文件中config与mapper的约束
本文链接:https://blog.csdn.net/gaoxin_gx/article/details/100183455 Config的约束: <?xml version="1.0 ...
- SQLyog试用到期的解决方法(仅供个人学习使用,禁止转载或用于商业盈利)
作者:EzrealYi 本章链接:https://www.cnblogs.com/ezrealyi/p/12434105.html win+r->输入regedit->进入注册表 在计算机 ...
- Windows安装python包出现PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问的问题解决方案
在python中安装sqlalchemy时,总是提示(当安装依赖有vs的python包时,可能会出现以下错误:) PermissionError: [WinError 32] 另一个程序正在使用此文件 ...
- SpringBoot图文教程12—SpringData Jpa的基本使用
有天上飞的概念,就要有落地的实现 概念十遍不如代码一遍,朋友,希望你把文中所有的代码案例都敲一遍 先赞后看,养成习惯 SpringBoot 图文教程系列文章目录 SpringBoot图文教程1「概念+ ...
- Feign 在 SpringCloud 中的使用 四
此处就单纯写一个消费者服务,通过Feign来调用生产者中的接口,生产者中的接口可以自己随便定义一个,前面博客中也有代码 1.导入springcloud Feign的jar包 <parent> ...
- 有关vue中用element ui 中的from表单提交json格式总是有冒号的问题解决办法
因为后台要求要传递JSON格式的数据给他,然后我转了之后总是多了冒号,后来又看了自己的报错,原来是报了404错误,说明路径找不到, 数据格式 后来发现怎么都不行了,然后突然查看了报错报的是404,说明 ...
- 《即时消息技术剖析与实战》学习笔记12——IM系统如何提升图片、音视频消息发送、浏览的体验
IM系统如何提升用户发送.浏览图片和音视频消息的体验呢?一是保证图片.音视频消息发送得又快又稳,二是保证用户浏览播放图片.音视频消息时流畅不卡顿. 一.提升用户发送图片.音视频的体验 1. 多上传接入 ...