Java集合框架要点概括(Core Knowledge of Java Collection)
本文主要参考:
- 《疯狂Java讲义精简版》-李刚
- HashMap实现原理分析
有哪些集合类
- 一图终结

Set,Queue和List都是继承了Collection,即大多数集合类的根接口。而Map则是单独的另一个接口发散出来。
Set类
HashSet:用哈希算法存储集合中的元素,因此存取和查找性能很好。但不是同步的,在有两个以上线程同时操作HashSet时,需要用代码保证其同步。集合元素值可以是null。当HastSet存入一个元素时,会调用该对象的HashCode()方法获取其哈希值,然后用哈希值决定该对象在HashSet中的存储位置。如果两个元素通过equals方法比较返回true,但它们的HashCode方法返回值不相等,HashSet会把它们存储在不同位置。所以,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,且HashCode方法的返回值也相等。(因此,重写一个类的equals方法时,也应该重写其HashCode方法,规则是:如果两个对象equals返回true,则两个对象的HashCode值也应该相同。如果不这样做,导致equals返回true,而HashCode相同,则HashSet会把这两个对象保存在Hash表的不用位置,从而使两个对象都添加成功,违背了Set集合的规则。)
LinkedHashSet:HashSet的子类,和HashSet不同的是利用链表维护元素的次序,使得元素看起来是以插入的顺序保存的。因为需要维护元素的插入顺序,因此性能略低于HashSet的性能。
TreeSet:SortedSet接口的实现类。保证元素的有序排列。支持两种排序方法,一是自然排序,二是定制排序。自然排序是TreeSet调用元素的compareTo方法比较元素大小,而这就要求元素对应的类必须实现了Comparable接口并实现了CompareTo(Object obj)方法。Java的一些常用类如BigDecimal,BigInteger,所有数值型包装类,Character,Boolean,String,Date,Time等都实现了Comparable接口。而定制排序,则是利用在构建TreeSet时,传入Comparator匿名对象并实现其CompareTo方法。
Queue类
模拟队列这种数据结构。队列是“先进先出”(FIFO)型的容器,尾部进元素,头部出元素。
ArrayQueue:Deque接口的实现类,Deque接口是Queue接口的子接口,代表了一个双端队列,定义了一些双端队列的方法,这些方法允许从两端来操作队列的元素。ArrayDeque从名字来看,就知道是使用数组来实现的双端队列。(和ArrayList类似,底层都使用了一个动态的,可重新分配的Object[]数组来存储集合元素,当集合元素超出了该数组的容量时,系统会在底层重新分配一个Object数组来存储集合元素。)。而ArrayDeque因为具有push和pop方法,因此可以当栈使用。
PriorityQueue:一个比较标准的队列实现类,但是其保存队列元素的顺序不是按加入队列的顺序,而是按队列元素的大小进行重新排序。因此当调用peek方法或者poll方法取出队列中的元素时,并不一定是取出最先进入队列的元素,从这一点看,PriorityQueue已经违反了队列的FIFO基本规则。
List类
线性表接口。
ArrayList:内部用数组形式来保存集合元素。线程不安全的。
Vector:也是用数组形式来保存集合元素,但是因为实现了线程同步功能,而实现机制却不好,所以各方面性能比较差。
Stack:Vector的子类,模拟栈结构。同样是线程安全,性能较差,所以应该尽量少使用。如果需要使用“栈”这种结构,可以考虑用ArrayDeQue。
固定长度的List:工具类Arrays里提供了一个方法asList可以将以额数组或者制定个数的对象转换成一个List集合,这个集合不是ArrayList或Vector实现类的实例,而是Arrays内部类ArrayList的实例,是一个固定长度的List集合,程序只能遍历访问集合里的元素,不可增加或删除集合里的元素。
LinkedList:一个比较特殊的集合类,既实现了Deque接口,也实现了List接口(可以根据索引来访问元素),所以可以当队列和栈用。内部用链表形式来保存集合元素,因此随机访问集合元素时性能较差,但在插入、删除元素时性能比较出色。
如果多个线程需要同时访问List集合中的元素,可以考虑使用Collections工具类将集合包装成线程
安全的集合。
Map类
key-value型存储方式。
Map和Set联系非常紧密,若将Map里的value都当成key的附庸,那么就可以像看待Set一样看待Map了。而从Java源码来看,也确实是先实现了Map,再包装一个value都为null的Map来实现的Set集合。
Hashtable:从名字上来看,就知道是一个古老的类,因为没有遵守类名每个单词首字母大写的规则。
HashMap:Hashtable和HashMap都是Map的典型实现类,关系类似于ArrayList和Vector。前者是一个古老的Map实现类,并且是线程安全的,所以性能差于后者。并且Hashtable不允许null作为键或者值(会抛出空指针异常),而HashMap可以。与HashSet类似,用作key的对象必须实现HashCode方法和equals方法,而判断两个value相等的方法则相对简单,只要两个对象通过equals方法比较返回true即可。
LinkedHashMap:HashMap的子类,用双向链表维护了key-value对的次序,因此性能略低于HashMap。
Properties: Hashtable的子类,是一种key和value都为String类的map。如名字所述,该对象在处理属性文件时特别方便,可以把Map中的key-value对写入属性文件中,也可以把属性文件中的“属性名=属性值”加载到Map对象中。
TreeMap:SortedMap接口的实现类。本身是一个红黑树数据结构,每个kv对作为红黑树的一个节点,存储键值对时根据key对节点进行排序。同样分为自然排序和定制排序两种方式。
HashMap的实现原理,是否线程安全,如何使其做到线程安全
HashMap的实现原理
本部分来自HashMap实现原理分析
HashMap的数据结构
数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。
数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
哈希表
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
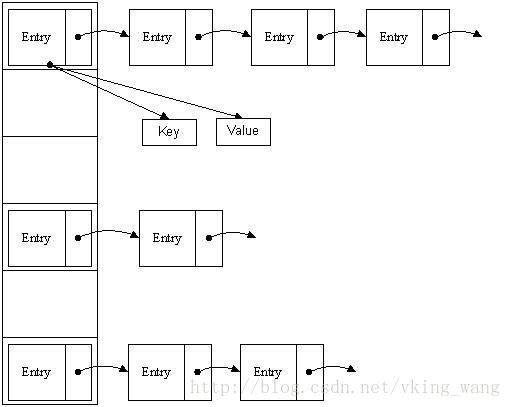
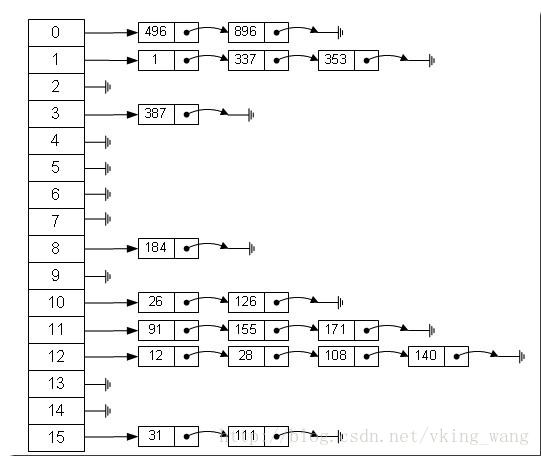
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
1)put
疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //参数e, 是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
}
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因子,随着map的size越来越大,Entry[]会以一定的规则加长长度。
2)get
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
3)null key的存取
null key总是存放在Entry[]数组的第一个元素。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
4)确定数组index:hashcode % table.length取模
HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标;算法如下:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
按位取并,作用上相当于取模mod或者取余%。(位运算的巧妙运用:由于位运算不需要将数转换为十进制,因此速度较快,而x mod/% n = x & (n-1),故此处用按位与运算代替取模操作)
这意味着数组下标相同,并不表示hashCode相同。
5)table初始大小
public HashMap(int initialCapacity, float loadFactor) {
.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!!!!
————为什么这么设计呢?——
解决hash冲突的办法
开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
再哈希法
链地址法
建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
简单总结
对于HashSet及其子类而言,它们采用hash算法来决定集合中元素的存储位置,并通过hash算法来控制集合的大小;对于HashMap、Hahstable及其子类而言,它们采用hash算法来决定Map中key的存储,并通过hash算法来增加key集合的大小。
hash表里可以存储元素的位置被称为桶(bucket),通常情况下,每个桶里存储一个元素,此时有最好的性能,hash算法可以根据hashCode值计算出桶的存储位置,接着从桶中取出元素。但hash表的状态是open的:在发生hash冲突的情况下,单个桶会存储多个元素,这些元素以链表形式存储,必须按顺序搜索。
HashSet和HashMap的hash表都包含如下属性:
- 容量capacity:hash表中通的数量
- 初始化容量initial capacity:创建hash表时桶的数量。
- 尺寸size:当前hash表中记录的数量
- 负载因子load factor:负载因子=size/capacity,是一个0-1数值。负载因子为0时表示空的hash表,0.5表示半满的hash表,因此,轻负载的hash表具有冲突少,适宜插入与查询的特点。
除此之外,hash表里有一个负载极限值,当负载因子达到这个值时,hash表会自动成倍增加容量,并将原有的对象重新分配,放入新的桶内,称为再哈希Rehashing。
HashMap的线程安全问题
HashMap本身不是线程安全的(HashSet,TreeSet,ArrayList,ArrayDeque,LinkedList也都不是线程安全的),可以用Collections提供的类方法将它们包装成线程同步的集合。
Collection c=Collections,synchronizedCollection(new ArrayList());
List list=Collections.synchronizedList(new ArrayList());
Set s=Collections.synchronizedSet(new HashSet());
Map m=Collections,synchronizedMap(new HashMap());
Java集合框架要点概括(Core Knowledge of Java Collection)的更多相关文章
- 【java集合框架源码剖析系列】java源码剖析之TreeSet
本博客将从源码的角度带领大家学习TreeSet相关的知识. 一TreeSet类的定义: public class TreeSet<E> extends AbstractSet<E&g ...
- 【java集合框架源码剖析系列】java源码剖析之HashSet
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于HashSet的知识. 一HashSet的定义: public class HashSet&l ...
- 【java集合框架源码剖析系列】java源码剖析之HashMap
前言:之所以打算写java集合框架源码剖析系列博客是因为自己反思了一下阿里内推一面的失败(估计没过,因为写此博客已距阿里巴巴一面一个星期),当时面试完之后感觉自己回答的挺好的,而且据面试官最后说的这几 ...
- 【java集合框架源码剖析系列】java源码剖析之java集合中的折半插入排序算法
注:关于排序算法,博主写过[数据结构排序算法系列]数据结构八大排序算法,基本上把所有的排序算法都详细的讲解过,而之所以单独将java集合中的排序算法拿出来讲解,是因为在阿里巴巴内推面试的时候面试官问过 ...
- 【java集合框架源码剖析系列】java源码剖析之TreeMap
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于TreeMap的知识. 一TreeMap的定义: public class TreeMap&l ...
- 【java集合框架源码剖析系列】java源码剖析之ArrayList
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本. 本博客将从源码角度带领大家学习关于ArrayList的知识. 一ArrayList类的定义: public class Arr ...
- 【java集合框架源码剖析系列】java源码剖析之LinkedList
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本. 在实际项目中LinkedList也是使用频率非常高的一种集合,本博客将从源码角度带领大家学习关于LinkedList的知识. ...
- 浅入深出之Java集合框架(下)
Java中的集合框架(下) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,哈哈这篇其实也还是基础,惊不惊喜意不意外 ̄▽ ̄ 写文真的好累,懒得写了.. ...
- Java集合框架(一)—— Collection、Iterator和Foreach的用法
1.Java集合概述 在编程中,常常需要集中存放多个数据.当然我们可以使用数组来保存多个对象.但数组长度不可变化,一旦在初始化时指定了数组长度,则这个数组长度是不可变的,如果需要保存个数变化的数据,数 ...
随机推荐
- bzoj1603: [Usaco2008 Oct]打谷机 (纱布题)
Description Input Output Sample Input Sample Output Time Limit: 5 Sec Memory Limit: 64 MB Submit: 7 ...
- 使用Python生成自己的特色二维码
二维码又称二维条码,常见的二维码为QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据 ...
- Python——8函数式编程①
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- 全网最详细的一篇Flutter 尺寸限制类容器总结
Flutter中尺寸限制类容器组件包括ConstrainedBox.UnconstrainedBox.SizedBox.AspectRatio.FractionallySizedBox.Limited ...
- D3.js实现拓扑图
最近写项目需要画出应用程序调用链的网路拓扑图,完全自己写需要花费些时间,那么首先想到的是echarts,但echarts的自定义写法写起来非常麻烦,而且它的文档都是基于配置说明的,对于自定义开发不太方 ...
- .NET异步程序设计之async&await
目录 0.背景引入 1.async和await基本语法 2.异步方法的执行顺序 3.取消一个异步操作 4.同步和异步等待任务 5.异步操作中的异常处理 6.多线程和异步的区分 7. 在 .NET MV ...
- Object-Oriented Programming Summary Ⅰ
Part 0: 前言 令人闻风丧胆的OO还是来了.并没有像名字的外表一样可爱,简直就是恶魔. 疯狂压榨OS的时间,周末无法休息,互测狼人机制 虽然网上骂声很多,就算改进到9012年还是有很多不足的地方 ...
- 阿里云上docker部署nginx实现反向代理
简介 需要从镜像仓库找到所需要的nginx版本pull下来.(地址:https://hub.docker.com/) 1.docker pull nginx 1.挂载目录 1.1 获取nginx. ...
- Android开发进阶 -- 通用适配器 CommonAdapter
在Android开发中,我们经常会用到ListView 这个组件,为了将ListView 的内容展示出来,我们会去实现一个Adapter来适配,将Layout中的布局以列表的形式展现到组件中. ...
- Linux环境下安装MySQL 5.7.28
先进入MySQL官网: www.mysql.com 去下载安装包 进入DOWNLOADS选项,点击MySQL Community (GPL) Downloads. 点击进入MySQL Communit ...