伙伴算法与slab算法
伙伴算法:
1.将空闲页面分为m个组,第1组存储2^0个单位的内存块,,第2组存储2^1个单位的内存块,第3组存储2^2个单位的内存块,第4组存储2^3个单位的内存块,以此类推.直到m组.
2.每个组是一个链表,用于连接同等大小的内存块.
3.伙伴块的大小是相等的,并且第1块和第2块是伙伴,第三块和第四块是伙伴.以此类推.
伙伴算法分配内存:
若申请的内存大小为n则将n向上取整为2的幂,设次数为s,则需要分配s大小的内存块,定位到相应数组,
1.如果该数组有剩余内存块,则分配出去.
2.若没有剩余内存块就沿数组向上查找,然后再将该内存块分割出来s并将剩余的内存块放入相应大小的数组中.
例如分配5大小的内存块
----------->定位到大小为8的链表中 -------->若该链表中之中没有空余元素,则定位到16的链表中,16中有剩余元素,则取出该元素,并分割出大小为8的内存块供用户使用,然后将剩余的8连接到大小为8的数组中
伙伴算法的内存合并:
当用户用完内存后会归还,然后根据该内存块实际大小(向上取整为2的幂)归入链表中,在归入之前,
1.我们还要检测他的伙伴内存块是否空闲,
2.如果空闲就合并在一起,合并后转到1,继续执行.
3.若果不是空闲的就直接归入链表中.
一般来说,伙伴算法实现中会用位图记录内存块是否被使用,用于伙伴内存的合并.
伙伴算法的特点:
显而易见,伙伴算法会浪费大量的内存,(如果需要大小为9的内存块必须分配大小为16的内存块).而优点也是明显的,分配和合并算法都很简单易行.但是,当分配和回收较快的时候,例如分配大小为9的内存块,此时分配16,然后又回收,即合并伙伴内存块,这样会造成不必要的cpu浪费,应该设置链表中内存块的低潮个数,即当链表中内存块个数小于某个值的时候,并不合并伙伴内存块,只要当高于低潮个数的时候才合并.
slab算法:
一般来说,伙伴算法的改进算法用于操作系统分配和回收内存,而且内存块的单位较大,利于Linux使用的伙伴算法以页为单位.对于小块内存的分配和回收,伙伴算法就显得有些得不偿失了.对于小块内存,一般采用slab算法,或者叫做slab机制.
linux 所使用的 slab 分配器的基础是 Jeff Bonwick 为SunOS 操作系统首次引入的一种算法。Jeff的分配器是围绕对象缓存进行的。在内核中,会为有限的对象集(例如文件描述符和其他常见结构)分配大量内存。Jeff发现对内核中普通对象进行初始化所需的时间超过了对其进行分配和释放所需的时间。因此他的结论是不应该将内存释放回一个全局的内存池,而是将内存保持为针对特定目而初始化的状态。例如,如果内存被分配给了一个互斥锁,那么只需在为互斥锁首次分配内存时执行一次互斥锁初始化函数(mutex_init)即可。后续的内存分配不需要执行这个初始化函数,因为从上次释放和调用析构之后,它已经处于所需的状态中了。
slab层主要起到了两个方面的作用:
1. slab可以对小对象进行分配,这样就不用为每个小对象分配一个页框,节省了空间。
2. 内核中的一些小对象创建析构很频繁,slab对这些小对象做了缓存,可以重复利用一些相同的对象,减少内存分配次数。
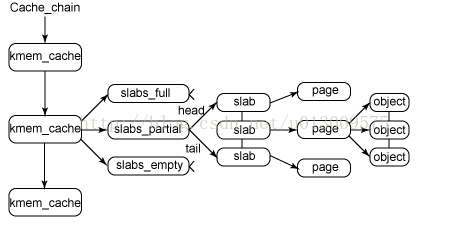
图中给出了 slab结构的高层组织结构。在最高层是 cache_chain,这是一个 slab 缓存的链接列表。cache_chain 的每个元素都是一个 kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。
每个缓存都包含了一个 slabs 列表,这是一段连续的内存块(通常都是页面)。存在3 种 slab:
slabs_full:完全分配的slab
slabs_partial:部分分配的slab
slabs_empty:空slab,或者没有对象被分配
slab 列表中的每个 slab都是一个连续的内存块(一个或多个连续页),它们被划分成一个个对象。这些对象是从特定缓存中进行分配和释放的基本元素。注意 slab 是 slab分配器进行操作的最小分配单位,因此如果需要对 slab 进行扩展,这也就是所扩展的最小值。通常来说,每个 slab 被分配为多个对象。
由于对象是从 slab 中进行分配和释放的,因此单个 slab 可以在 slab列表之间进行移动。例如,当一个 slab中的所有对象都被使用完时,就从slabs_partial 列表中移动到 slabs_full 列表中。当一个 slab完全被分配并且有对象被释放后,就从 slabs_full 列表中移动到slabs_partial 列表中。当所有对象都被释放之后,就从 slabs_partial 列表移动到 slabs_empty 列表中。
slab背后的动机
与传统的内存管理模式相比, slab缓存分配器提供了很多优点。首先,内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab缓存分配器通过对类似大小的对象进行缓存而提供这种功能,从而避免了常见的碎片问题。slab分配器还支持通用对象的初始化,从而避免了为同一目而对一个对象重复进行初始化。最后,slab分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。
slab描述符

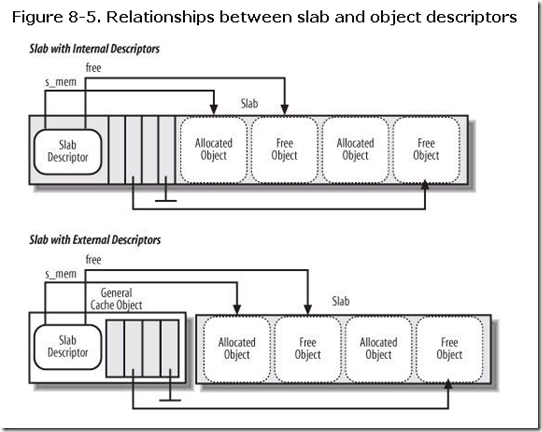
既然是对对象进行管理,那么就有一个内存的指针指向它所管理的对象:void* s_mem。并且它还需要记录哪些对象被使用了,哪些是空闲的。这时就需要有一个数组记录这个东西,这就是free变量。你可能会奇怪它的类型是一个unsigned int:

它是如何记录这个数组的呢?事实上是记录在slab描述符后面的数组中,这个数组中的每一个元素记录着下一个空闲的内存对象的位置。而free记录的就是第一个空闲的对象。这样就可以从free开始遍历所有空闲的对象。
下图显示了slab对象的内存分布,这里需要解释一下的是slab descriptor会根据情况被存放在当前slab的内存中或者存放在通用的高速缓存中。
参考:
http://www.cnblogs.com/xuczhang/archive/2010/04/02/1703363.html
http://blog.chinaunix.net/uid-9863638-id-1996388.html
伙伴算法与slab算法的更多相关文章
- Linux内存管理6---伙伴算法与slab
1.前言 本文所述关于内存管理的系列文章主要是对陈莉君老师所讲述的内存管理知识讲座的整理. 本讲座主要分三个主题展开对内存管理进行讲解:内存管理的硬件基础.虚拟地址空间的管理.物理地址空间的管理. 本 ...
- Machine Learning读书会,面试&算法讲座,算法公开课,创业活动,算法班集锦
Machine Learning读书会,面试&算法讲座,算法公开课,创业活动,算法班集锦 近期活动: 2014年9月3日,第8次西安面试&算法讲座视频 + PPT 的下载地址:http ...
- 算法:KMP算法
算法:KMP排序 算法分析 KMP算法是一种快速的模式匹配算法.KMP是三位大师:D.E.Knuth.J.H.Morris和V.R.Pratt同时发现的,所以取首字母组成KMP. 少部分图片来自孤~影 ...
- BF算法与KMP算法
BF(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符:若不相等,则比较S的 ...
- Levenshtein Distance算法(编辑距离算法)
编辑距离 编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数.许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符, ...
- javascript数据结构与算法--高级排序算法
javascript数据结构与算法--高级排序算法 高级排序算法是处理大型数据集的最高效排序算法,它是处理的数据集可以达到上百万个元素,而不仅仅是几百个或者几千个.现在我们来学习下2种高级排序算法-- ...
- ISAP算法对 Dinic算法的改进
ISAP算法对 Dinic算法的改进: 在刘汝佳图论的开头引言里面,就指出了,算法的本身细节优化,是比较复杂的,这些高质量的图论算法是无数优秀算法设计师的智慧结晶. 如果一时半会理解不清楚,也是正常的 ...
- 文本比较算法Ⅱ——Needleman/Wunsch算法
在"文本比较算法Ⅰ--LD算法"中介绍了基于编辑距离的文本比较算法--LD算法. 本文介绍基于最长公共子串的文本比较算法--Needleman/Wunsch算法. 还是以实例说明: ...
- 文本比较算法三——SUNDAY 算法
SUNDAY 算法描述: 字符串查找算法中,最著名的两个是KMP算法(Knuth-Morris-Pratt)和BM算法(Boyer-Moore).两个算法在最坏情况下均具有线性的查找时间.但是在实用上 ...
随机推荐
- layer的iframe层的传参和回参
从父窗口传参给iframe,参考://https://yq.aliyun.com/ziliao/133150 从iframe回参给父窗口,参考:https://www.cnblogs.com/jiqi ...
- (18)zabbix值映射Value mapping
1. 介绍 zabbix为了显示更人性化的数据,在使用过程中,我们可以将获取到得数据映射为一个字符串. 比如,我们写脚本监控MySQL是否在运行中, 一般返回0表示数据库挂了,1表示数据库正常,还有各 ...
- Perl学习之四:语句(续)
循环控制:1.last 退出标签的语句块2.next 3.redo不推荐,循环次数不可控 4.goto不推荐.***************************************标签: 先 ...
- 【git】不检查特定文件的更改情况
.gitignore只能忽略那些原来没有被track的文件,如果某些文件已经被纳入了版本管理中,则修改.gitignore是无效的.正确的做法是在每个clone下来的仓库中手动设置不要检查特定文件的更 ...
- LeetCode(102) Binary Tree Level Order Traversal
题目 Given a binary tree, return the level order traversal of its nodes' values. (ie, from left to rig ...
- ZOJ 2058 The Archaeologist's Trouble II(贪心+模拟)
[题目大意] 一个n高的塔,由@ * ?三种字符组成.每行相邻两个字符不能相邻. '?' 表示未确定是 '@' 还是 '*' . 求'@' 可能出现的最多和最少次数. [分析] 在可以填的情况下 先填 ...
- visual studio 的生成、重新生成、清理功能的说明
生成 生成当前选中的项目,依赖的项目如果已经生成dll,则不生成,直接拷贝过来 重新生成 生成当前选中的项目,依赖的项目也会生成 清理 清除掉生成的dll和相关文件
- Java-获取一个类的父类
如何使用代码获取一个类的父类 package com.tj; public class MyClass implements Cloneable { public static void main(S ...
- python-selenium使用send_keys()方法写中文报错的解决方法
问题描述: 自动化操作页面,输入中文姓名: # coding=utf-8 url = "http://dealer.bitauto.com/50002218/zuidijia/" ...
- C/C++复杂类型声明
曾经碰到过让你迷惑不解.类似于int * (* (*fp1) (int) ) [10];这样的变量声明吗?本文将由易到难,一步一步教会你如何理解这种复杂的C/C++声明. 我们将从每天都能碰到的较 ...