java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析
- LinkedList数据结构简介
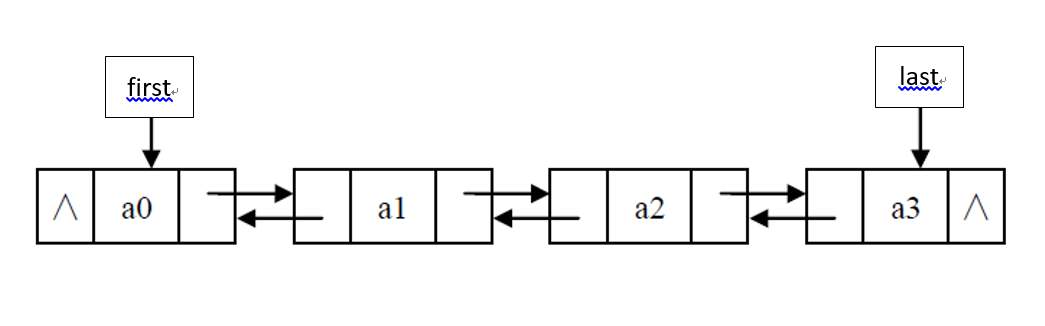
LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含该节点的数据和分别指向前一个前一个和后一个节点的引用。LinkedList内部维护两个成员变量first和last,分别指向链表的头节点和尾节点(接下来的成员变量介绍中会提到)。由于LinkedList基于链表,因此查询速度慢,增删速度快,又因为链表为双端双向,因此可进行双向遍历。
其实对LinkedList的各种操作其实是对链表的各种操作!!!
/**
*节点类
*
*/
private static class Node<E> {
E item;//节点数据
Node<E> next;//指向前一个节点的引用
Node<E> prev;//指向后一个节点的引用 Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
- LinkedList成员变量
//链表节点数量,即集合包含的元素数量
transient int size = 0; //链表的头节点
transient Node<E> first; //链表的尾节点
transient Node<E> last;
另外还有一个从父类继承的modCount成员变量,关于modCount的介绍已经在本人的ArrayList源码分析一文中进行过介绍(https://www.cnblogs.com/gdy1993/p/9246250.html),因此此文简单带过,不再详述。
protected transient int modCount = 0;
- LinkedList构造方法
LinkedList有两个构造方法,一个空参,一个传入一个Collection集合,然后调用addAll(c)方法
/**
* 空参构造:并未对链表进行初始化
*/
public LinkedList() { } /**
* 传入一个Collection集合
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
/**
* 往链表尾部添加元素,内部调用了addAll(int index, Collection<? extends E> c),传入的是索引为size,即一个元素添加的索引
*/
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
} /**
* 往指定索引处添加元素
* 1. 首先判断该索引是否越界,必须保证index >= 0 && index <= size
* 2. 将Collection集合转变成为数组
* 3. 如果数组长度为 0 ,直接返回false
* 4. 根据index是否为最后,对下一个元素的前节点(pred)和后节点(succ)进行设置
* 5. 把数组中的元素依次从index位置向后插入
* 6. 设置last节点
* 7. 修改size和modCount
*/
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);// Object[] a = c.toArray();//
int numNew = a.length;
if (numNew == 0)//
return false; Node<E> pred, succ;//
if (index == size) {//如果要添加元素至链表最后
succ = null;//下一个节点为null
pred = last;//上一个节点为当前链表的last节点
} else {//如果添加元素不在链表最后
succ = node(index);//获得第index个节点,并赋值给succ
pred = succ.prev;//
} for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)//如果之前链表为空
first = newNode;
else
pred.next = newNode;
pred = newNode;//将新添加的节点置为下一个要添加元素的前一个节点
} //
if (succ == null) {//如果index == size
last = pred;//最后添加的节点就是last节点
} else {//如果不是,双向关联Collection集合中的最后一个节点和原来链表的第index个节点
pred.next = succ;
succ.prev = pred;
}
//7.
size += numNew;
modCount++;
return true;
} //检查索引是否越界
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
} private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
- LinkedList添加元素
/**
* 从集合头部添加元素
*/
public void addFirst(E e) {
linkFirst(e);
} /**
*从集合尾部添加元素
*/
public void addLast(E e) {
linkLast(e);
} /**
* 往链表头部添加元素
* 1. 保存原来的first节点
* 2. 创建新节点,并将first指向该新节点
* 3. 如果原链表为空,将最后一个节点指向新节点
* 4. 若不为空,将原来的first节点(以保存)的前一个节点设置为新节点
* 5. 修改size和modCount
*/
private void linkFirst(E e) {
final Node<E> f = first;//
final Node<E> newNode = new Node<>(null, e, f);//
first = newNode;//
if (f == null)//
last = newNode;
else//
f.prev = newNode;
size++;
modCount++;
} /**
* 往链表尾部添加元素:其原理与linkFirst()基本相同,不再介绍
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* 从指定位置处添加元素:
* 1. 检查索引是否越界 index >= 0 && index <= size
* 2. 如果要添加的索引为链表最后一个节点的下一个节点,即往链表末端追加节点
* 3. 如果不是往链表末端添加节点.将该节点插入到原链表的第index个节点前边
*/
public void add(int index, E element) {
checkPositionIndex(index);//1. if (index == size)
linkLast(element);//2.
else
linkBefore(element, node(index));//3.
} /**
* 将节点插入到succ节点前边
*/
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;//保留succ的前一个节点
final Node<E> newNode = new Node<>(pred, e, succ);//创建新节点,并将新节点的前一个节点指向pred,后一个节点指向succ
succ.prev = newNode;//将succ的前一个节点指向新节点
if (pred == null)//判断新节点是否在链表顶端
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
addAll()方法已经在构造方法中介绍过。
- LinkedList删除方法
/**
* 删除头结点
* 如果头结点为空,即集合为空,抛出NoSuchElementException
* 否则调用unlinkFirst()删除
*/
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
} /**
* 删除头结点,并将其数据设为null,以help GC
*/
private E unlinkFirst(Node<E> f) {
final E element = f.item;//获取头结点数据
final Node<E> next = f.next;//获得头结点的下一个节点
f.item = null;//help GC
f.next = null; // help GC
first = next;//将头结点的下一个节点设为新的头结点
if (next == null)//如果原来链表只有一个节点,删除后现在链表为空,则将last指向null
last = null;
else//否则,将现在头节点的前一个节点指向null
next.prev = null;
size--;
modCount++;
return element;
}
/**
* 删除尾节点,如果集合为空,则抛出NoSuchElementException
* 否则调用unlinkLast()方法删除
*/
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
} /**
* 基本原理与unlinkedFirst相同,不再介绍
*/
private E unlinkLast(Node<E> l) {
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
/**
*删除指定索引处的元素:
* 首先检查索引是否越界
* 调用unlink()删除
*/
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
} /**
* 删除指定节点
*/
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev; if (prev == null) {//如果删除的是头结点
first = next;//将next设置为新的头结点
} else {//否则
prev.next = next;//将删除节点的前一个节点指向其后一个节点
x.prev = null;//将删除节点的前一个节点置为null,help GC
} if (next == null) {//如果删除节点的后一个节点为null,表明删除节点为last节点
last = prev;//将删除节点的前一个节点设为last节点
} else {//否则
next.prev = prev;//将删除节点的后一个节点的前一个节点设为删除节点的前一个节点(有点绕)
x.next = null;//help GC
} x.item = null;//help GC
size--;
modCount++;
return element;//返回删除元素
}
- LinkedList查询
/**
* 获取头结点的数据
*/
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
} /**
* 获取尾节点的数据
*/
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
/**
* 获取指定索引处的元素,首先检查索引是否越界,然后调用node()方法
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
} /**
* 其实链表是不能通过索引进行访问的,正式这个方法使得LinkedList可通过索引访问
*/
Node<E> node(int index) {
//如果索引小于链表长度的一半,则从first节点从前往后找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {//如果索引大于链表长度的一半,则从后往前找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
/**
* 从前向后遍历查找指定元素,如果o==null,则用==判断,否则,使用equals判断
*/
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
} /**
* 从后向前遍历查找指定元素,如果o==null,则用==判断,否则,使用equals判断
*/
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
- 补充
1. LinkedList实现类Deque<E>接口,Deque<E>继承自Queue,因此它具备一些队列的特有方法,而且是双端队列,不过这些方法都是基于以上增删查方法实现的,不再做详细解释;另外也可以实现栈的相关方法
/**
* 返回first的数据,如果链表为空,返回null
*/
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
} /**
* 返回first的数据,如果链表为空抛出NoSuchElementException
*/
public E element() {
return getFirst();
} /**
*删除并返回头节点的数据,如果头结点为null,返回null
*/
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
} /**
* 删除头结点的元素,如果链表为空,抛出NoSuchElementException
*/
public E remove() {
return removeFirst();
} /**
* 添加元素,添加到链表最后
*/
public boolean offer(E e) {
return add(e);
} // Deque operations
/**
* 添加头结点
*/
public boolean offerFirst(E e) {
addFirst(e);
return true;
} /**
* 添加尾节点
*/
public boolean offerLast(E e) {
addLast(e);
return true;
} /**
* 返回头结点
*/
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
} /**
* 返回尾节点
*/
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
} /**
* 返回并删除头结点
*/
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
} /**
* 返回并删除尾节点
*/
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
} /**
* 压栈
*/
public void push(E e) {
addFirst(e);
} /**
*弹栈
*/
public E pop() {
return removeFirst();
}
- LinkedList集合的遍历
关于对LinkedList的迭代遍历的并发修改问题的实现与ArrayList的原理基本相同,可参见(https://www.cnblogs.com/gdy1993/p/9246250.html),不再这里介绍了。
java集合系列之LinkedList源码分析的更多相关文章
- Java集合系列[2]----LinkedList源码分析
上篇我们分析了ArrayList的底层实现,知道了ArrayList底层是基于数组实现的,因此具有查找修改快而插入删除慢的特点.本篇介绍的LinkedList是List接口的另一种实现,它的底层是基于 ...
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
- java集合系列之ArrayList源码分析
java集合系列之ArrayList源码分析(基于jdk1.8) ArrayList简介 ArrayList时List接口的一个非常重要的实现子类,它的底层是通过动态数组实现的,因此它具备查询速度快, ...
- Java集合系列:-----------03ArrayList源码分析
上一章,我们学习了Collection的架构.这一章开始,我们对Collection的具体实现类进行讲解:首先,讲解List,而List中ArrayList又最为常用.因此,本章我们讲解ArrayLi ...
- Java集合系列[3]----HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在 ...
- Java集合系列[1]----ArrayList源码分析
本篇分析ArrayList的源码,在分析之前先跟大家谈一谈数组.数组可能是我们最早接触到的数据结构之一,它是在内存中划分出一块连续的地址空间用来进行元素的存储,由于它直接操作内存,所以数组的性能要比集 ...
- java多线程系列(九)---ArrayBlockingQueue源码分析
java多线程系列(九)---ArrayBlockingQueue源码分析 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 j ...
- Java并发系列[2]----AbstractQueuedSynchronizer源码分析之独占模式
在上一篇<Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析>中我们介绍了AbstractQueuedSynchronizer基本的一些概 ...
- Java并发系列[3]----AbstractQueuedSynchronizer源码分析之共享模式
通过上一篇的分析,我们知道了独占模式获取锁有三种方式,分别是不响应线程中断获取,响应线程中断获取,设置超时时间获取.在共享模式下获取锁的方式也是这三种,而且基本上都是大同小异,我们搞清楚了一种就能很快 ...
随机推荐
- shell脚本,提取ip地址和子网掩码,和查外网ip地址信息。
#提取IP地址和子网掩码 [root@localhost ~]# ifconfig eth0|grep 'inet addr'|awk -F'[ :]+' '{print $4"/& ...
- ios之UITabelViewCell的自定义(代码实现)
在用到UITableVIew的时候,经常会自定义每行的Cell 在IOS控件UITableView详解中的下面代码修改部分代码就可以实现自定义的Cell了 [cpp] view plaincopy - ...
- 任务十一:移动Web页面布局实践
面向人群: 有一定HTML及CSS基础,想要尝试移动开发 难度: 中 重要说明 百度前端技术学院的课程任务是由百度前端工程师专为对前端不同掌握程度的同学设计.我们尽力保证课程内容的质量以及学习难度的合 ...
- CSS盒模型总结(一)
一.基本概念 盒子模型是css中一个重要的概念,理解了盒子模型才能更好的排版,盒模型的组成:content padding border margin 二.盒模型的分类 盒子模型有两种,分别是 ie ...
- Linux中文件压缩与解压
压缩与解压 compress 文件名 1 -v //详细信息 2 3 -d //等于 uncompress 默认只识别 .Z 如果使用别的后缀,会导致不识别,解压缩失败.也可以使用 -d -c 压缩包 ...
- 剑指Offer(书):链表的倒数第K个节点
题目:输入一个链表,输出该链表中倒数第k个结点. 分析:要注意三点:链表为空:链表个数小于k:k的值<=0; public ListNode FindKthToTail(ListNode hea ...
- ios开发中遇到的文件和字符的问题大总结
我今天遇到的NSString问题 今天遇到一个字符串空指针问题,让我明白了许多 其实我们定义一个NSString * string,其实是定义了一个字符串指针,现在string没有指向任何地方,我们必 ...
- adb shell am/pm 常用命令详解与使用
一.adb shell am 使用此命令可以从cmd控制台启动 activity, services:发送 broadcast等等 1.am start <packageName/.classN ...
- js 秒杀
秒杀活动页面 <!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" ...
- css 标题
纯CSS制作的复古风格的大标题 .vintage{ background: #EEE url(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAQAAAA ...