python爬虫之处理验证码
云打码实现处理验证码
处理验证码,我们需要借助第三方平台来帮我们处理,个人认为云打码处理验证码的准确度还是可以的
首先第一步,我们得先注册一个云打码的账号,普通用户和开发者用户都需要注册一下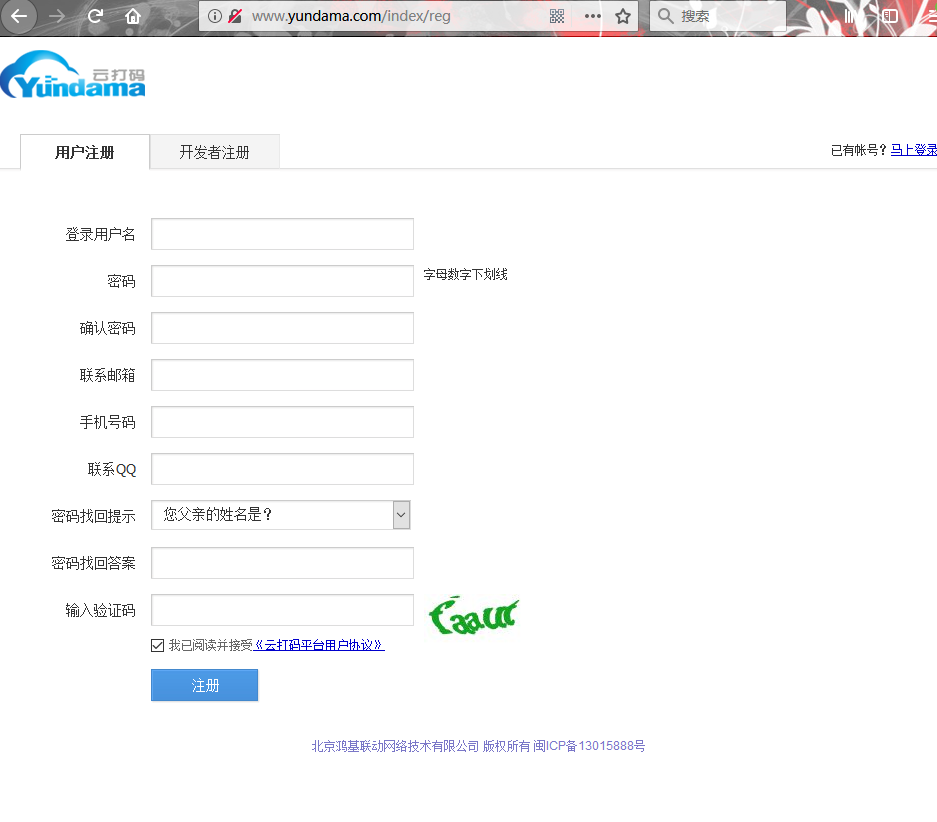
然后登陆普通用户,登陆之后的界面是这样的,
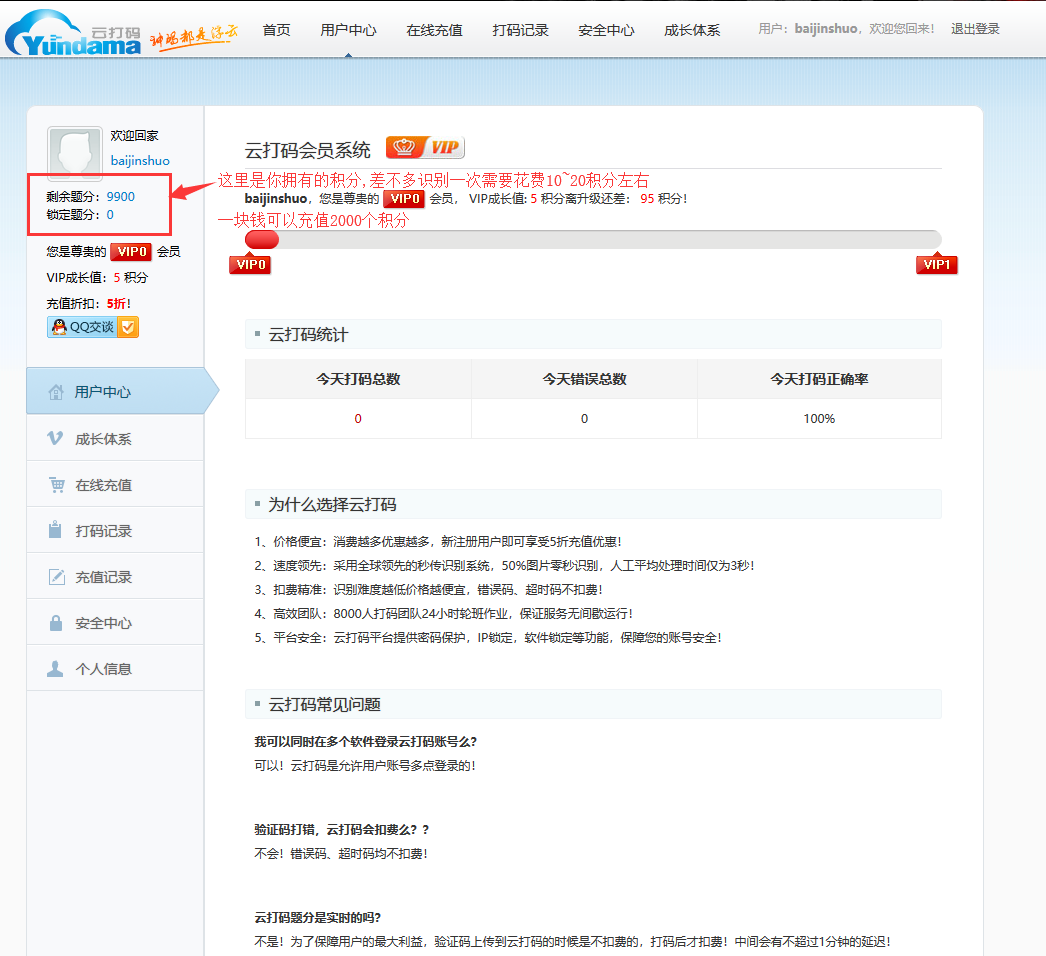
你需要有几分才可以使用它.
第二步登陆开发者用户:
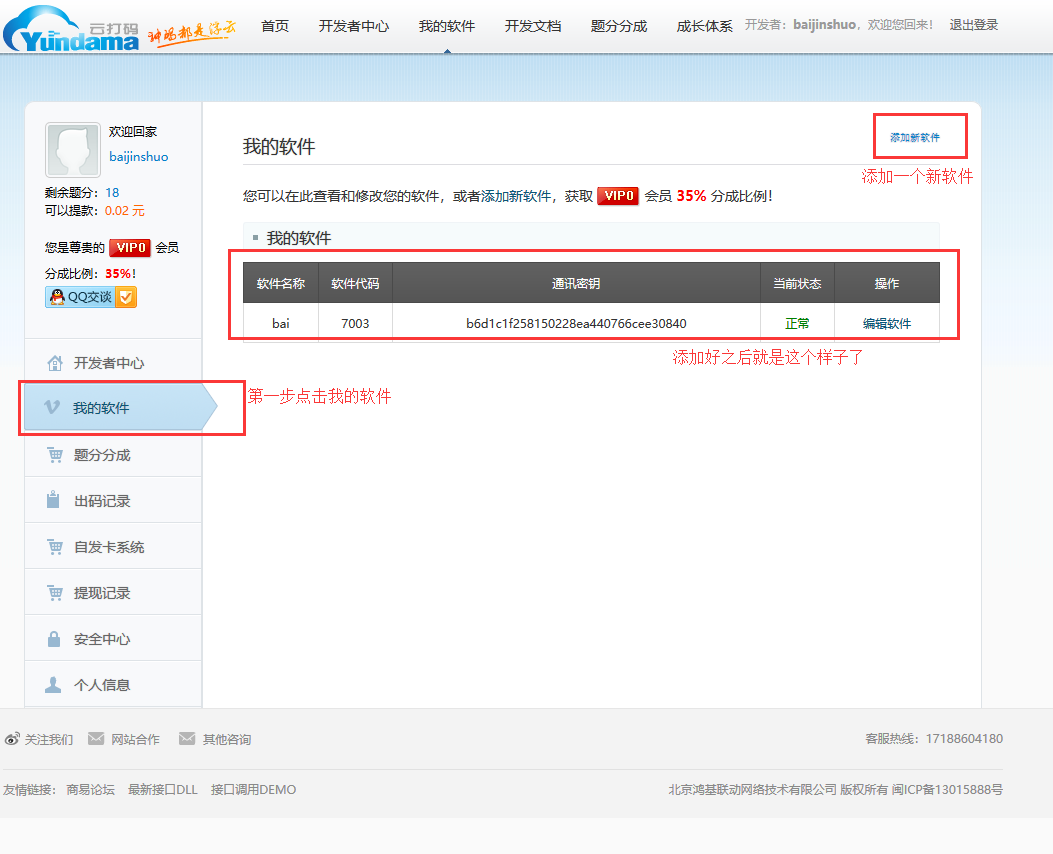
然后点击开发文档
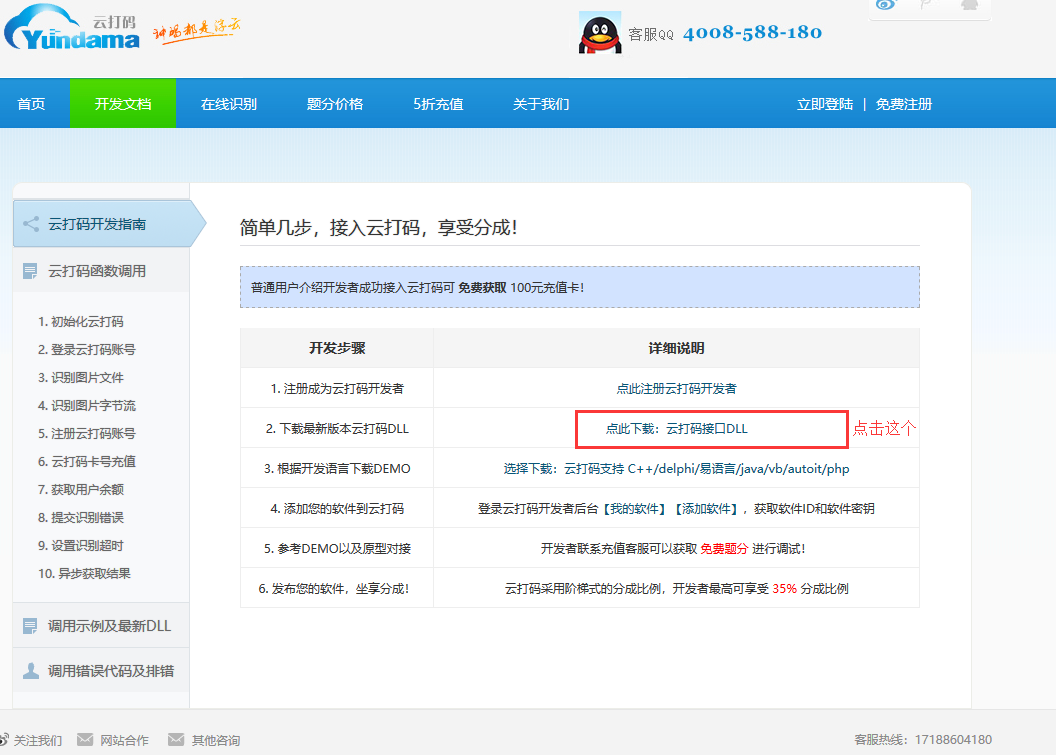
进入之后点击下载python相关的模块
下载之后我们解压之后发现是里面有三个文件:
这里以python3的代码为例:
import http.client, mimetypes, urllib, json, time, requests
######################################################################
class YDMHttp:
apiurl = 'http://api.yundama.com/api.php'
username = ''
password = ''
appid = ''
appkey = ''
def __init__(self, username, password, appid, appkey):
self.username = username
self.password = password
self.appid = str(appid)
self.appkey = appkey
def request(self, fields, files=[]):
response = self.post_url(self.apiurl, fields, files)
response = json.loads(response)
return response
def balance(self):
data = {'method': 'balance', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['balance']
else:
return -9001
def login(self):
data = {'method': 'login', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey}
response = self.request(data)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['uid']
else:
return -9001
def upload(self, filename, codetype, timeout):
data = {'method': 'upload', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'codetype': str(codetype), 'timeout': str(timeout)}
file = {'file': filename}
response = self.request(data, file)
if (response):
if (response['ret'] and response['ret'] < 0):
return response['ret']
else:
return response['cid']
else:
return -9001
def result(self, cid):
data = {'method': 'result', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'cid': str(cid)}
response = self.request(data)
return response and response['text'] or ''
def decode(self, filename, codetype, timeout):
cid = self.upload(filename, codetype, timeout)
if (cid > 0):
for i in range(0, timeout):
result = self.result(cid)
if (result != ''):
return cid, result
else:
time.sleep(1)
return -3003, ''
else:
return cid, ''
def report(self, cid):
data = {'method': 'report', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'cid': str(cid), 'flag': ''}
response = self.request(data)
if (response):
return response['ret']
else:
return -9001
def post_url(self, url, fields, files=[]):
for key in files:
files[key] = open(files[key], 'rb');
res = requests.post(url, files=files, data=fields)
return res.text
######################################################################
# 用户名
username = 'username'
# 密码
password = 'password'
# 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得!
appid = 1
# 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得!
appkey = '22cc5376925e9387a23cf797cb9ba745'
# 图片文件
filename = 'getimage.jpg'
# 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html
codetype = 1004
# 超时时间,秒
timeout = 60
# 检查
if (username == 'username'):
print('请设置好相关参数再测试')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey)
# 登陆云打码
uid = yundama.login();
print('uid: %s' % uid)
# 查询余额
balance = yundama.balance();
print('balance: %s' % balance)
# 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(filename, codetype, timeout);
print('cid: %s, result: %s' % (cid, result))
######################################################################
原装代码
使用示例代码中的源码文件中的代码进行修改,让其识别验证码图片中的数据值
#该函数就调用了打码平台的相关的接口对指定的验证码图片进行识别,返回图片上的数据值
def getCode(codeImg):
# 云打码平台普通用户的用户名
username = 'baijinshuo' # 云打码平台普通用户的密码
password = 'bjs146531' # 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得!
appid = 6003 # 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得!
appkey = '1f4b564483ae5c907a1d34f8e2f2776c' # 验证码图片文件
filename = codeImg # 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html
codetype = 3000 # 超时时间,秒
timeout = 20 # 检查
if (username == 'username'):
print('请设置好相关参数再测试')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey) # 登陆云打码
uid = yundama.login();
print('uid: %s' % uid) # 查询余额
balance = yundama.balance();
print('balance: %s' % balance) # 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(filename, codetype, timeout);
print('cid: %s, result: %s' % (cid, result)) return result
import requests
from lxml import etree
import json
import time
import re
#1.对携带验证码的页面数据进行抓取
url = 'https://www.douban.com/accounts/login?source=movie'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Mobile Safari/537.36'
}
page_text = requests.get(url=url,headers=headers).text #2.可以将页面数据中验证码进行解析,验证码图片下载到本地
tree = etree.HTML(page_text)
codeImg_url = tree.xpath('//*[@id="captcha_image"]/@src')[0]
#获取了验证码图片对应的二进制数据值
code_img = requests.get(url=codeImg_url,headers=headers).content #获取capture_id
'<img id="captcha_image" src="https://www.douban.com/misc/captcha?id=AdC4WXGyiRuVJrP9q15mqIrt:en&size=s" alt="captcha" class="captcha_image">'
c_id = re.findall('<img id="captcha_image".*?id=(.*?)&.*?>',page_text,re.S)[0]
with open('./code.png','wb') as fp:
fp.write(code_img) #获得了验证码图片上面的数据值
codeText = getCode('./code.png')
print(codeText)
#进行登录操作
post = 'https://accounts.douban.com/login'
data = {
"source": "movie",
"redir": "https://movie.douban.com/",
"form_email": "",
"form_password": "bobo@15027900535",
"captcha-solution":codeText,
"captcha-id":c_id,
"login": "登录",
}
print(c_id)
login_text = requests.post(url=post,data=data,headers=headers).text
with open('./login.html','w',encoding='utf-8') as fp:
fp.write(login_text)
python爬虫之处理验证码的更多相关文章
- python爬虫中图形验证码的处理
使用python爬虫自动登录时,遇到需要输入图形验证码的情况,一个比较简单的处理方法是使用打码平台识别验证码. 使用过两个打码平台,打码兔和若快,若快的价格更便宜,识别率相当.若快需要注册两个帐号:开 ...
- python爬虫之浅析验证码
一.什么是验证码? 验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”( ...
- python爬虫模拟登录验证码解决方案
[前言]几天研究验证码解决方案有三种吧.第一.手工输入,即保存图片后然后我们手工输入:第二.使用cookie,必须输入密码一次,获取cookie:第三.图像处理+深度学习方案,研究生也做相关课题,就用 ...
- Python爬虫教程:验证码的爬取和识别详解
今天要给大家介绍的是验证码的爬取和识别,不过只涉及到最简单的图形验证码,也是现在比较常见的一种类型. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻 ...
- python爬虫之获取验证码登陆
#--coding:utf-8#author:wuhao##这里我演示的就是本人所在学校的教务系统#import urllib.requestimport urllib.parseimport rei ...
- python爬虫点触验证码的识别思路(图片版)
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫入门教程 60-100 python识别验证码,阿里、腾讯、百度、聚合数据等大公司都这么干
常见验证码 之前的博客中已经解决了一些常见验证码的问题,但是验证码是层出不穷的,目前解决验证码除了通过常规手段解决以外,还可以通过人工智能领域的深度学习去解决 深度学习?! 无疑对爬虫coder提高了 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
随机推荐
- Django-Rest framework中文翻译-generic-views
通用视图 Django的通用视图......被开发为常见用法模式的快捷方式......它们采用视图开发中的某些常见习语和模式并对其进行抽象,以便您可以快速编写数据的常用视图,而无需重复自己. - Dj ...
- foreach获取访问元素的下标
今天在用foreach循环的时候,要同时根据访问下标获取另一个list对象数据,之前想的方法是加一个变量i,然后每次i++,但是感觉这样不是很好!,后来发现这样也可以!举个简单的例子! foreach ...
- Tclientdate的排序
CDS_common.IndexDefs.Clear; CDS_common.AddIndex('JSPH','JSPH',[],'JSPH'); CDS_common.A ...
- The Balance POJ 2142 扩展欧几里得
Description Ms. Iyo Kiffa-Australis has a balance and only two kinds of weights to measure a dose of ...
- Hibernate插入错误:GenericJDBCException: could not insert:
数据库中一般不能建立user(表名为User)表,将User类改名,又一次建立映射,问题就能够解决 当然,还有还有一种情况.就是类中id类型错误.要设置为Integer型才干够设置自己主动增长,否则也 ...
- C++对象模型——"无继承"情况下的对象构造(第五章)
5.1 "无继承"情况下的对象构造 考虑以下这个程序片段: 1 Point global; 2 3 Point foobar() 4 { 5 Point local; 6 Poin ...
- 【Cocos2dx游戏开发】Cocos2d-x简介
一.简介 最近在做一个Android下的卡牌游戏--<九州幻想>开发项目,而我们使用的引擎是Cocos2dx,所以想要写写笔记来记录一下项目中的收获.当然首先稍微介绍一下Cocos2d-x ...
- VS中多项目联合开发技巧
1. 新建目录,将它设定为 本次project的工作目录,新建一个Code Files目录 2. 在Code Files目录里.新建一个Win32控制台程序(总控程序),再新建其他的项目比方项目A ...
- Apache Kafka-0.8.1.1源代码编译
作者:过往记忆 | 新浪微博:左手牵右手TEL | 能够转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明博客地址:http://www.iteblog.com/文章标题:<Apac ...
- 适合国内网速的CDH5安装
0.集群规划 说明:因为CDH能够方便的动态加入删除主机,动态改变主机上的服务,所以后面再对各机器上跑得服务进行分配. 共三台机器 操作系统: centos6.5 机器名:work01.work02. ...