数据准备<2>:数据质量检查-实战篇
上一篇文章:《数据质量检查-理论篇》主要介绍了数据质量检查的基本思路与方法,本文作为补充,从实战角度出发,总结一套基于Python的数据质量检查模板。
承接上文,仍然从重复值检查、缺失值检查、数据倾斜检查、异常值检查四方面进行描述。
1.环境介绍
版本:python2.7
工具:Spyder
开发人:hbsygfz
2.数据集介绍
数据集:dataset.xlsx
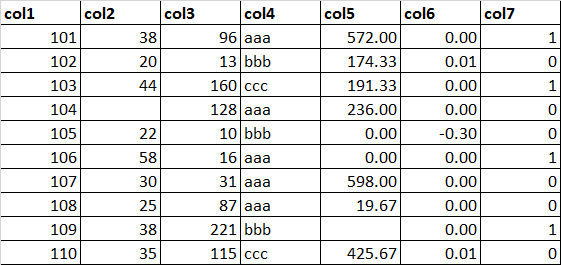
3.代码实现
3.1 导入相关库
import pandas as pd
###3.2 读取数据集
dataset = pd.read_excel("/labcenter/python/dataset.xlsx")
discColList = ['col4','col7']
contColList = ['col1','col2','col3','col5','col6']
###3.3 重复值检查
主要统计指标:重复记录数、字段唯一值数。
### (1)重复记录数
def dupRowsCheck(df):
dupRows = df.duplicated().sum()
return dupRows
### (2)字段唯一值数
def uiqColValCheck(df):
# 记录数,变量数
m,n = df.shape
uiqDf = pd.DataFrame(index=df.columns,columns=['rows','uiqCnt'])
uiqDf['rows'] = m
for j in range(n):
ser = df.iloc[:,j]
name = df.columns[j]
uiqCnt = len(ser.unique())
uiqDf.loc[name,'uiqCnt'] = uiqCnt
return uiqDf
执行与结果:
dupRowsCheck(dataset)
Out[95]: 0
uiqColValCheck(dataset)
Out[96]:
rows uiqCnt
col1 10 10
col2 10 9
col3 10 10
col4 10 3
col5 10 9
col6 10 5
col7 10 2
###3.4 缺失值检查
主要统计指标:字段空值记录数。
def missingCheck(df):
# 记录数,变量数
m,n = df.shape
rowsSer = pd.Series(index=df.columns)
rowsSer.name = 'rows'
# 空值记录数
nullCntSer = df.isnull().sum()
nullCntSer.name = 'nullCnt'
# 合并结果
missDf = pd.concat([rowsSer,nullCntSer],axis=1)
missDf['rows'] = m
return missDf
执行与结果:
missingCheck(dataset)
Out[97]:
rows nullCnt
col1 10 0
col2 10 1
col3 10 0
col4 10 0
col5 10 1
col6 10 0
col7 10 0
###3.5 数据倾斜检查
主要统计指标:记录数、类别个数、最大类别记录数、最大类别记录数占比。
def skewCheck(df,discList,contList,bins):
# 离散型变量类别统计
new_df1 = df[discList]
skewDf1 = pd.DataFrame(index=discList,columns=['rows','classCnt','mostClassCnt','mostClassRio'])
m1,n1 = new_df1.shape
for j in range(n1):
ser = new_df1.iloc[:,j]
name = new_df1.columns[j]
freqSer = pd.value_counts(ser)
skewDf1.loc[name,'rows'] = m1
skewDf1.loc[name,'classCnt'] = len(freqSer)
skewDf1.loc[name,'mostClassCnt'] = freqSer[0]
skewDf1.loc[name,'mostClassRio'] = freqSer[0] * 1.00 / m1
# 连续型变量分箱统计
new_df2 = df[contList]
skewDf2 = pd.DataFrame(index=contList,columns=['rows','classCnt','mostClassCnt','mostClassRio'])
m2,n2 = new_df2.shape
for j in range(n2):
ser = new_df2.iloc[:,j]
name = new_df2.columns[j]
freqSer = pd.value_counts(pd.cut(ser,bins))
skewDf2.loc[name,'rows'] = m2
skewDf2.loc[name,'classCnt'] = len(freqSer)
skewDf2.loc[name,'mostClassCnt'] = freqSer[0]
skewDf2.loc[name,'mostClassRio'] = freqSer[0] * 1.00 / m2
# 合并结果
skewDf = pd.concat([skewDf1,skewDf2],axis=0)
return skewDf
执行与结果:
skewCheck(dataset,discColList,contColList,4)
Out[98]:
rows classCnt mostClassCnt mostClassRio
col4 10 3 5 0.5
col7 10 2 6 0.6
col1 10 4 3 0.3
col2 10 4 3 0.3
col3 10 4 4 0.4
col5 10 4 3 0.3
col6 10 4 1 0.1
###3.6 异常值检查
主要统计指标:最大值、最小值、平均值、标准差、变异系数、大于平均值+3倍标准差的记录数、小于平均值-3倍标准差记录数、大于上四分位+1.5倍的四分位间距记录数、小于下四分位-1.5倍的四分位间距记录数、正值记录数、零值记录数、负值记录数。
### (1)异常值统计
def outCheck(df,contList):
new_df = df[contList]
resDf = new_df.describe()
resDf.loc['cov'] = resDf.loc['std'] / resDf.loc['mean'] #计算变异系数
resDf.loc['mean+3std'] = resDf.loc['mean'] + 3 * resDf.loc['std'] #计算平均值+3倍标准差
resDf.loc['mean-3std'] = resDf.loc['mean'] - 3 * resDf.loc['std'] #计算平均值-3倍标准差
resDf.loc['75%+1.5dist'] = resDf.loc['75%'] + 1.5 * (resDf.loc['75%'] - resDf.loc['25%']) #计算上四分位+1.5倍的四分位间距
resDf.loc['25%-1.5dist'] = resDf.loc['25%'] - 1.5 * (resDf.loc['75%'] - resDf.loc['25%']) #计算下四分位-1.5倍的四分位间距
# 3segma检查
segmaSer1 = new_df[new_df > resDf.loc['mean+3std']].count() #平均值+3倍标准差
segmaSer1.name = 'above3SegmaCnt'
segmaSer2 = new_df[new_df < resDf.loc['mean-3std']].count() #平均值-3倍标准差
segmaSer2.name = 'below3SegmaCnt'
# 箱线图检查
boxSer1 = new_df[new_df > resDf.loc['75%+1.5dist']].count() #上四分位+1.5倍的四分位间距
boxSer1.name = 'aboveBoxCnt'
boxSer2 = new_df[new_df < resDf.loc['25%-1.5dist']].count() #下四分位-1.5倍的四分位间距
boxSer2.name = 'belowBoxCnt'
# 合并结果
outTmpDf1 = pd.concat([segmaSer1,segmaSer2,boxSer1,boxSer2],axis=1)
outTmpDf2 = resDf.loc[['max','min','mean','std','cov']]
outDf = pd.concat([outTmpDf2.T,outTmpDf1],axis=1)
return outDf
### (2)正负分布检查
def distCheck(df,contList):
new_df = df[contList]
distDf = pd.DataFrame(index=contList,columns=['rows','posCnt','zeroCnt','negCnt'])
m,n = new_df.shape
for j in range(n):
ser = new_df.iloc[:,j]
name = new_df.columns[j]
posCnt = ser[ser>0].count()
zeroCnt = ser[ser==0].count()
negCnt = ser[ser<0].count()
distDf.loc[name,'rows'] = m
distDf.loc[name,'posCnt'] = posCnt
distDf.loc[name,'zeroCnt'] = zeroCnt
distDf.loc[name,'negCnt'] = negCnt
return distDf
执行与结果:
outCheck(dataset,contColList)
Out[101]:
max min mean std cov above3SegmaCnt below3SegmaCnt aboveBoxCnt belowBoxCnt
col1 110.0000 101.0 105.500000 3.027650 0.028698 0 0 0 0
col2 58.0000 20.0 34.444444 11.959422 0.347209 0 0 1 0
col3 221.0000 10.0 87.700000 71.030588 0.809927 0 0 0 0
col5 598.0000 0.0 246.333333 235.303647 0.955225 0 0 0 0
col6 0.0115 -0.3 -0.027740 0.095759 -3.452026 0 0 2 1
distCheck(dataset,contColList)
Out[102]:
rows posCnt zeroCnt negCnt
col1 10 10 0 0
col2 10 9 0 0
col3 10 10 0 0
col5 10 7 2 0
col6 10 3 6 1
数据准备<2>:数据质量检查-实战篇的更多相关文章
- 数据准备<5>:变量筛选-实战篇
在上一篇文章<数据准备<4>:变量筛选-理论篇>中,我们介绍了变量筛选的三种方法:基于经验的方法.基于统计的方法和基于机器学习的方法,本文将介绍后两种方法在Python(skl ...
- 数据准备<4>:变量筛选-理论篇
在上一篇文章<数据准备<3>:数据预处理>中,我们提到降维主要包括两种方式:基于特征选择的降维和基于维度转换的降维,其中基于特征选择的降维通俗的讲就是特征筛选或者变量筛选,是指 ...
- 数据准备<1>:数据质量检查-理论篇
数据行业有一句很经典的话--"垃圾进,垃圾出"(Garbage in, Garbage out, GIGO),意思就是,如果使用的基础数据有问题,那基于这些数据得到的任何产出都是没 ...
- Scrapy实战篇(五)之爬取历史天气数据
本篇文章我们以抓取历史天气数据为例,简单说明数据抓取的两种方式: 1.一般简单或者较小量的数据需求,我们以requests(selenum)+beautiful的方式抓取数据 2.当我们需要的数据量较 ...
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- Wireshark数据抓包分析——网络协议篇
Wireshark数据抓包分析--网络协议篇 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvZGF4dWViYQ==/ ...
- Python数据抓取技术与实战 pdf
Python数据抓取技术与实战 目录 D11章Python基础1.1Python安装1.2安装pip1.3如何查看帮助1.4D1一个实例1.5文件操作1.6循环1.7异常1.8元组1.9列表1.10字 ...
- 第六篇:R语言数据可视化之数据分布图(直方图、密度曲线、箱线图、等高线、2D密度图)
数据分布图简介 中医上讲看病四诊法为:望闻问切.而数据分析师分析数据的过程也有点相似,我们需要望:看看数据长什么样:闻:仔细分析数据是否合理:问:针对前两步工作搜集到的问题与业务方交流:切:结合业务方 ...
随机推荐
- 剑指Offer——网易校招内推笔试题+模拟题知识点总结
剑指Offer--网易校招内推笔试题+模拟题知识点总结 前言 2016.8.2 19:00网易校招内推笔试开始进行.前天晚上利用大约1小时时间完成了测评(这个必须做,关切到你能否参与面试).上午利用2 ...
- 【Unity Shaders】游戏性和画面特效——创建一个夜视效果的画面特效
本系列主要参考<Unity Shaders and Effects Cookbook>一书(感谢原书作者),同时会加上一点个人理解或拓展. 这里是本书所有的插图.这里是本书所需的代码和资源 ...
- Android 中与 so 有关的一个大坑
Android 应用开发中不可避免的会引入第三方的代码.如果是开源项目风险相对可控,如果引入商用的 SDK 那就要谨慎了,难免会有这样或那样的问题.比如我们今天要说的这一个. 对集成过第三方 SDK ...
- 欢迎进入我的个人博客 anzhan.me
CSDN的博客依旧会更新,但是还是专注于技术. 个人的博客 http://anzhan.me 不单单会同步csdn的技术文章,还会有个人的更多私人的分享,包括旅行日记.欢迎各位朋友经常去看看,大家有私 ...
- 多进程log4cxx区分日志
多进程log4cxx区分日志 (金庆的专栏) 网游客户端一般会多开,多个进程会写同一个日志文件.log4cxx看来会对文件加锁,防止多进程写同一文件写乱,截止目前还没发现错乱的日志. log4cxx有 ...
- (四十九)Quartz2D自定义控件
利用Quartz2D来自定义UIImageView: 模仿UIImageView: 设置frame,设置图片. 注意一个细节,自定义的imageView,应该通过重写set方法来设置图片并且重绘,否则 ...
- 第三方Charts绘制图表四种形式:饼状图,雷达图,柱状图,直线图
对于第三方框架Charts(Swift版本,在OC项目中需要添加桥接头文件),首先要解决在项目中集成的问题,集成步骤: 一.下载Charts框架 下载地址:https://github.com/dan ...
- 运行React-Native项目
首先需要配置好环境.集体配置安装Homebrew,Node.js,React Native; 命令行开启RN项目 (如要cd 进入到当前项目的跟目录下) 1. npm install 2. react ...
- Gradle实现的两种简单的多渠道打包方法
本来计划今天发Android的官方技术文档的翻译--<Gradle插件用户指南>的第五章的,不过由于昨天晚上没译完,还差几段落,所以只好推后了. 今天就说一下使用Gradle进行类似友盟这 ...
- javascript 实战总结
JavaScript的简单的知识前面已经总结 欢迎交流学习,学习靠的是理论+实践, 通过姜昊老师的JavaScript专题训练,加深了对理论知识的理解,学习新的语言越来越发现熟悉的背景,基础内容是 ...